Overview
Cluster landing zones provide a framework in which common organizational challenges with respect to network segmentation, failure domains, team ownership and data sovereignty when designing cluster deployment topologies for hybrid and multi-cloud architectures can be addressed. This is augmented with an operating model that provides tools and practical guidance on how to deal with day-to-day operational issues related to cluster lifecycling, application rollout, governance, observability and disaster recovery. This article treats primarily with the former set of concerns and touches on best practices for the latter as and when needed. There are also many other excellent blog articles that provide more detailed guidance and should be consulted. Whilst the nature of this blog is architectural it is underpinned with a specific set of tooling in mind that provides multi-cluster management and GitOps capabilities, namely Red Hat Advanced Cluster Management for Kubernetes (RHACM) and OpenShift GitOps (ArgoCD). Part 2 of this blog is available here.
Designing for Hybrid and Multi-cloud Architectures
Let's dig a little deeper into what common design challenges enterprises face when migrating to cloud and deploying clusters at scale. Other than the obvious application-level concerns, the next layer down deals with more challenging aspects of organisational context that manifest themselves as design demarcation points or trust boundaries. These typically inform the Enterprise architect of how the cluster landing zone should be segmented and shaped to the needs of the organization. A list of common boundaries include any of the following:
- network zone
- operational environment mode
- infrastructure provider
- geography
- business unit
- application team
From an operational perspective the purpose of trust boundaries are to establish an administrative span of control within the enterprise and are often based on well-established enterprise architecture principles such as separation of concerns and least privilege amongst others such as data sovereignty. These boundaries and principles need to be reflected in the design of a cluster landing zone and are major contributing factor to how many hubs and clusters are present in the final design.
Modern computing architectures based around hybrid cloud (defined here as a logical coalescing of infrastructure from one or more cloud providers) and multi-cloud (defined here as disparate infrastructure from one or more cloud providers) are within the context of OpenShift abstracted into cloud-agnostic platforms for the purpose of running container workloads reliably and seamlessly.
What both hybrid and multi-cloud architectures have in common is the segregation of the control plane from the data plane. The control plane (referred to as the hub in RHACM) centralizes all of the cluster lifecycle management functions and governance controls. It also facilitates distribution of user workloads down to the data plane (referred to as managed clusters in RHACM). The distinction between the two models ends there as hybrid cloud architecture coalesce managed clusters hosted on multiple cloud providers into a logical unit (referred to as a managed clusterset in RHACM) and manages these with a single hub that has visibility across all cloud providers. Managed cluster sets are also present in a multi-cloud architecture but only contain managed clusters hosted on one cloud provider as typically the boundary of the hub is the cloud provider itself, as per the diagrams below. Note that in a multi-cloud architecture there might be a top-level hub (hub-of-hubs) to provide some level of cross-cloud consistency and governance, but this is optional. The multi-cloud model does have more flexibility in terms of support for more complex organizational structures such as when dealing with multiple legal entities or mergers, or in shops where decentralized IT ownership is still practiced. On the other hand the hybrid cloud model better supports new Kubernetes features such as the multi-cluster services API that enables load-balancing of services across multiple clusters in a managed cluster set and thus across cloud providers, providing even higher levels of resiliency.
 Diagram 1. Cluster landing zone for a hybrid cloud architecture
Diagram 1. Cluster landing zone for a hybrid cloud architecture
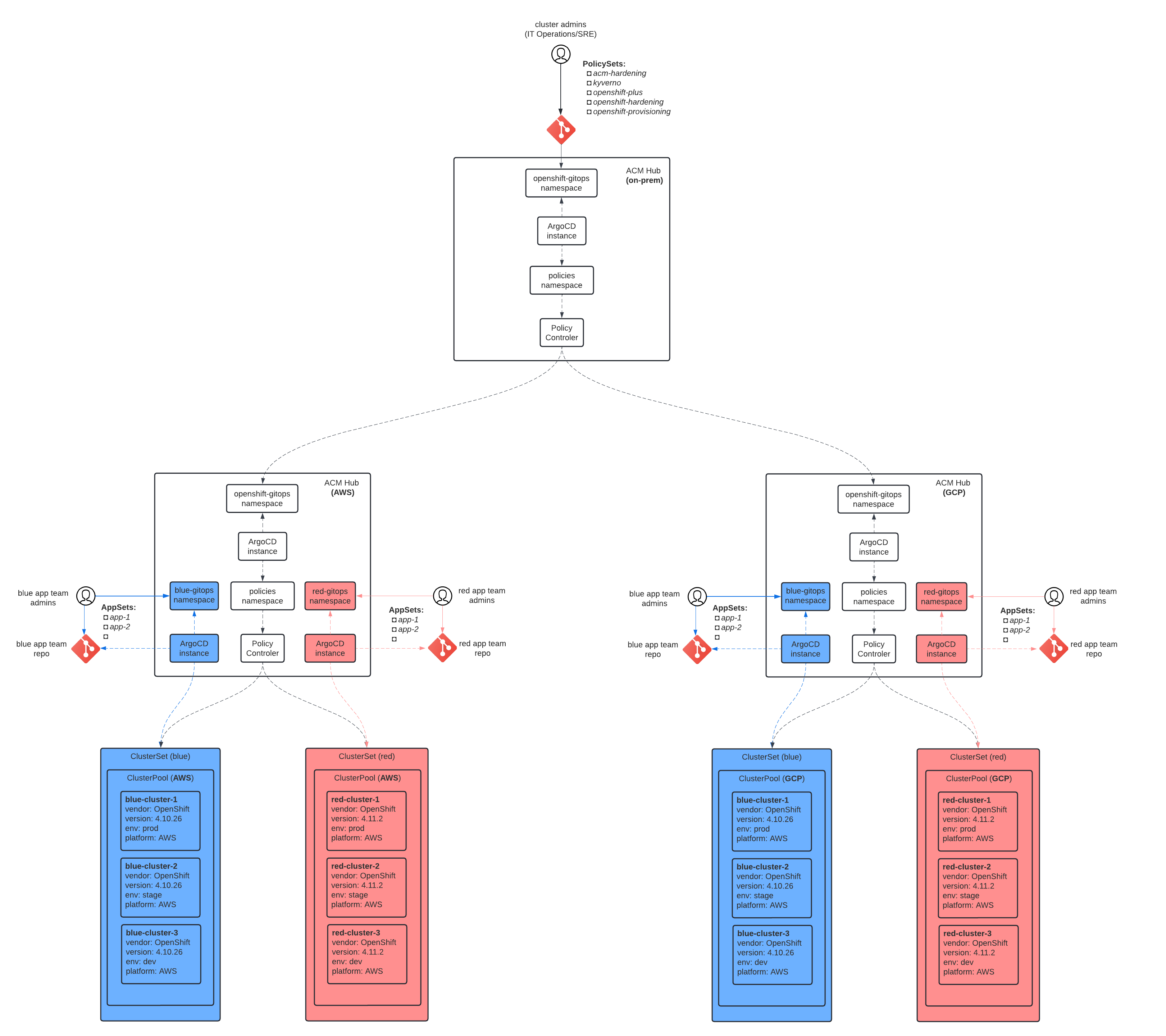 Diagram 2. Cluster landing zone for a multi-cloud architecture
Diagram 2. Cluster landing zone for a multi-cloud architecture
From an operational perspective the diagrams show that all provisioning activities including cluster hardening and configuration are performed by the IT Operations/SRE team via a policy-driven/GitOps approach from the hub itself. This is described in greater detail in other blogs on this site. In addition to that (but not mandatory) is the possibility of leveraging the hub for multi-tenanted application delivery.
For each application team a set of managed clusters is provisioned by the SRE which are bound to a team-specific namespace that hosts the GitOps engine (ArgoCD). The namespace is bound to the managed cluster set thus limiting the scope of what is visible to ArogCD. This ensures that even if the application team misconfigures their workflow and accidentally target clusters belonging to another team, the net effect of this would be nil as only operations against the bound managed cluster set are possible via this scope control. As an aside, if the application team wishes to further segregate the responsibilities for deploying applications to specific clusters between team members this can be achieved using ArgoCD projects.
Placements and application sets are the main APIs that the application will need to understand to manage their deployment workflow. An example is shown below. Let's say that the red team wish to deploy their application to production only. Here are the resources they would need to define to achieve this.
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: placement-red-clusters-prod
namespace: red-gitops
spec:
predicates:
- requiredClusterSelector:
labelSelector:
matchExpressions:
- {key: env, operator: In, values: ["prod"]}
---
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: my-app
namespace: red-gitops
spec:
generators:
- clusterDecisionResource:
configMapRef: acm-placement
labelSelector:
matchLabels:
cluster.open-cluster-management.io/placement: placement-red-clusters-prod
requeueAfterSeconds: 180
template:
metadata:
name: 'my-app-{{name}}'
spec:
project: default
source:
repoURL: # valid URL
targetRevision: main
path: # valid path
destination:
namespace: my-app
server: '{{server}}'
syncPolicy:
syncOptions:
- CreateNamespace=true
- PruneLast=true
automated:
prune: true
selfHeal: true
And that is everything. Behind the scenes controllers work to evaluate the placement into a valid list of clusters based on the managed cluster set that is bound to the ArgoCD instance. This list will then be handed over to ArgoCD to generate one application per cluster. Based on this code and assuming it is applied to the hybrid cloud architecture above the net result is two applications deployed: one to the production cluster in AWS and the other to the production cluster in GCP.
A more complex placement example leveraging both labels and cluster claims that select the red team's non-production cluster in AWS only is as follows:
apiVersion: cluster.open-cluster-management.io/v1beta1
kind: Placement
metadata:
name: placement-red-clusters-nonprod
namespace: red-gitops
spec:
predicates:
- requiredClusterSelector:
labelSelector:
matchExpressions:
- {key: env, operator: NotIn, values: ["prod"]}
claimSelector:
matchExpressions:
- {key: platform.open-cluster-management.io, operator: In, values: ["AWS"]}
The net result of this (assuming the same application set was updated the new placement name) would be that there are two applications deployed, one to the staging cluster and the other to the development cluster, both in AWS only.
Unlike labels which are typically user-defined and should be specified at provisioning time (they can be changed later), cluster claims are auto-generated by RHACM and provide a rich set of semantics that can be used to distinguish clusters and cloud providers. The upshot is that at no time does the application team need to specify the cluster name which is important when using a dynamic cluster provisioning strategy which was described in this prior blog.
As an side, some advantages of this architecture is that it facilitates a "cluster-per-team" approach which has some inherent benefits such as reduced blast radius, decoupled maintenance windows, ad hoc restart along with bespoke scaling and cluster version/configuration. The downsides include increased infrastructure cost which can be mitigated via solutions such as HyperShift. The centralized control plane model in which all administrative and application activity is initiated from the hub has been long established in IT and removes the need to integrate managed clusters with identity systems and track user activity. RHACM search capabilities also support this hands-off model as all objects can be searched for from the hub UI.
Conclusion
Cluster landing zones are a useful model for understanding and implementing hybrid and multi-cloud topologies based on well-defined trust boundaries and architectural principles. With a carefully considered multi-tenancy model and using integrated tooling such as ArgoCD the hub can also serve the needs of application teams. Using the various multi-cluster lifecycle, governance, and observability tools shipped with RHACM enables the SRE to fully implement and operate a cluster landing zone tailored to the needs of adaptive enterprise that is able to better evolve as new technologies and practices emerge.
About the author

More like this
A decade of open innovation: Red Hat continues to scale the open hybrid cloud with Microsoft
Stop managing the past and start building IT’s future
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds