This blog was written in partnership with Intel, and co-written by William Crowe, Global Solution Development Manager at Intel, and Maithili Bapat, Solution Architect at Intel.
Red Hat OpenShift on AWS (ROSA)
Red Hat OpenShift Service on AWS (ROSA) is a fully-managed turnkey application platform that allows you to focus on what matters most, delivering value to your customers by building and deploying applications. Red Hat and AWS SRE experts manage the underlying platform so you don’t have to worry about the complexity of infrastructure management. ROSA provides seamless integration with a wide range of AWS compute, database, analytics, machine learning, networking, mobile, and other services to further accelerate the building and delivering of differentiating experiences to your customers.
The latest version of ROSA now has support for 3rd Generation Intel® Xeon® Scalable Processor instances (m6i and c6i instance types). Amazon EC2 C6i instances, which offer up to 15% better price performance compared to C5 instances for a wide variety of workloads. C6i instances feature a 2:1 ratio of memory to vCPU, just like C5 instances and support up to 128 vCPUs per instance, which is 33% more than C5 instances. These instances feature twice the networking bandwidth of C5 instances and are an ideal fit for compute-intensive workloads such as batch processing, distributed analytics, high performance computing (HPC), ad serving, highly scalable multiplayer gaming, and video encoding. C6i are also available with local NVMe-based SSD block-level storage (C6id instances) for applications that need high-speed, low-latency local storage. Compared to previous generation C5d instances, C6id instances offer up to 138% higher TB storage per vCPU and 56% lower cost per TB.
Monte Carlo Simulation
Vertical industries, such as the Financial Services Industry (FSI) have many use cases that demand this type of leading edge compute performance and capabilities. The Monte Carlo simulation is an application commonly used to evaluate the risk and uncertainty that would affect the outcome of different decision options. Monte Carlo methods are used in corporate finance and mathematical finance to value and analyze complex instruments, portfolios and investments by simulating the various sources of uncertainty affecting their value, and then determining the distribution of their value over the range of resultant outcomes.
These algorithms can be used to calculate the value of an option with multiple sources of uncertainties and random features, for example variations in exchange rates, stock prices etc. Monte Carlo European Options is a numerical method that uses statistical sampling techniques to approximate solutions to quantitative problems. This is a compute bound, double precision workload and benefits from Intel Turbo Boost Technology.
Intel Advanced Vector Extensions 512 (Intel® AVX-512)
Intel® Advanced Vector Extensions 512 (Intel® AVX-512) is a set of instructions that can accelerate performance for workloads and usages such as scientific simulations, financial analytics, artificial intelligence (AI)/deep learning, 3D modeling and analysis, image and audio/video processing, cryptography and data compression With ultra-wide 512-bit vector operations capabilities, Intel® AVX-512 can handle your most demanding computational tasks.
Applications can pack 32 double precision and 64 single precision floating point operations per clock cycle within the 512-bit vectors, as well as eight 64-bit and sixteen 32-bit integers, with up to two 512-bit fused-multiply add (FMA) units, thus doubling the width of data registers, doubling the number of registers, and, doubling the width of FMA units, compared to Intel® Advanced Vector Extensions 2 (Intel® AVX2)
The Experiment and test setup
The experiment deploys the Monte Carlo simulation on ROSA, with 3rd Generation Intel® Xeon® Scalable Processors, and showcases how it benefits from the Intel CPU acceleration Intel® AVX-512.
As a baseline for this work, it was assumed that the simulation run needs to be completed under a certain time that has variation.
The Red Hat monitoring stack (which is part of Red Hat OpenShift) was used to monitor the user application and capture the elapsed time to complete the simulation on both AVX2 and AVX512 configurations. For more information on the RedHat “Monitoring stack”, please refer to the Red Hat OpenShift release notes and documentation.
Results: The experimentation shows the elapsed time, when the application is using Intel® AVX-512 it completes the simulation in approximately 50% of the time taken on AVX2, this is in-line with expectations and consistent with the impact of doubling the width of the vector instructions used.
Pre-requisites:
You will need the following resources:
- An AWS account
- An IAM user with appropriate permissions to create and access ROSA cluster
- A ROSA cluster created
- Access to Red Hat OpenShift web console
Walkthrough: 4 steps to complete
- Install a ROSA cluster with 3rd Generation Intel® Xeon® Scalable Processors instances.
- Install the Node Feature Discovery (NFD) Operator
- Run the MonteCarlo-AVX512 demo on ROSA
- Access the Grafana dashboard to observe the results
Let’s go ahead and execute each of the above mentioned steps.
1: Install a ROSA cluster with 3rd Generation Intel® Xeon® Scalable Processor instance
Let's begin by listing all the 3rd Generation Intel® Xeon® Scalable Processors instance types that are supported with ROSA
rosa list instance-types | grep 6i
m6i.xlarge general_purpose 4 16.0 GiB
r6i.xlarge memory_optimized 4 32.0 GiB
c6i.xlarge compute_optimized 4 8.0 GiB
m6i.2xlarge general_purpose 8 32.0 GiB
c6i.2xlarge compute_optimized 8 16.0 GiB
r6i.2xlarge memory_optimized 8 64.0 GiB
c6i.4xlarge compute_optimized 16 32.0 GiB
m6i.4xlarge general_purpose 16 64.0 GiB
r6i.4xlarge memory_optimized 16 128.0 GiB
c6i.8xlarge compute_optimized 32 64.0 GiB
m6i.8xlarge general_purpose 32 128.0 GiB
r6i.8xlarge memory_optimized 32 256.0 GiB
c6i.12xlarge compute_optimized 48 96.0 GiB
m6i.12xlarge general_purpose 48 192.0 GiB
r6i.12xlarge memory_optimized 48 384.0 GiB
m6i.16xlarge general_purpose 64 256.0 GiB
r6i.16xlarge memory_optimized 64 512.0 GiB
c6i.16xlarge compute_optimized 64 128.0 GiB
m6i.24xlarge general_purpose 96 384.0 GiB
r6i.24xlarge memory_optimized 96 768.0 GiB
c6i.24xlarge compute_optimized 96 192.0 GiB
r6i.32xlarge memory_optimized 128 1.0 TiB
m6i.32xlarge general_purpose 128 512.0 GiB
m6i.metal general_purpose 128 512.0 GiB
c6i.metal compute_optimized 128 256.0 GiB
c6i.32xlarge compute_optimized 128 256.0 GiB
r6i.metal memory_optimized 128 1.0 TiB
Next, let's create account roles, this is run once per AWS account, per y-stream OpenShift version:
rosa create account-roles --mode auto --yes
We are now ready to deploy the ROSA cluster. We will do this using the ROSA CLI with the following command. The command creates a highly available cluster, with STS enabled in the us-west-2 region using c6i.4xlarge instance types for the worker nodes.
rosa create cluster --cluster-name my-rosa-cluster --sts --mode auto --yes --multi-az --region us-west-2 --version 4.10.9 --compute-nodes 3 --compute-machine-type c6i.4xlarge --machine-cidr 10.0.0.0/16 --service-cidr 172.30.0.0/16 --pod-cidr 10.128.0.0/14 --host-prefix 23
2: Install the Node Feature Discovery Operator
Node Feature Discovery (NFD) is an OpenShift add-on that detects and advertises hardware and software capabilities of a platform that can, in turn, be used to facilitate intelligent scheduling of a workload.
In a standard deployment, Kubernetes reveals very few details about the underlying platform to the user. This may be a good strategy for general data center use, but, in many cases a workload behavior or its performance, may improve by leveraging the platform (hardware and/or software) features. Node Feature Discovery detects these features and advertises them through a Kubernetes concept called “node labels” which, in turn, can be used to control workload placement in a Kubernetes cluster. NFD runs as a separate container on each individual node of the cluster, discovers capabilities of the node, and finally publishes these as node labels using the Kubernetes API.
To enable the Node Feature Discovery Operator on Openshift, refer to https://access.redhat.com/solutions/4734811
Check the available labels for the worker node, prior to installation of the NFD Operator
% oc get nodes ip-10-0-154-108.us-west-2.compute.internal -o yaml
(...)
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/instance-type: c6i.4xlarge
beta.kubernetes.io/os: linux
failure-domain.beta.kubernetes.io/region: us-west-2
failure-domain.beta.kubernetes.io/zone: us-west-2a
kubernetes.io/arch: amd64
kubernetes.io/hostname: ip-10-0-154-108.us-west-2.compute.internal
kubernetes.io/os: linux
node-role.kubernetes.io/worker: ""
node.kubernetes.io/instance-type: c6i.4xlarge
node.openshift.io/os_id: rhcos
topology.ebs.csi.aws.com/zone: us-west-2a
topology.kubernetes.io/region: us-west-2
topology.kubernetes.io/zone: us-west-2a
(...)
Next, connect to the OpenShift console to install the NFD Operator:
-
-
Go to Operators -> Operator Hub. Search for nfd and click on the Node Feature Discovery operator:
-
Select Install:
-
Select stable, All namespaces on the cluster, Automatic. Click Install
-
Wait until the operator shows up and displays Installed operator - ready for use
-
Go to Installed Operators, and click on the line with the Node Feature Discovery operator to select it and go to the Node Feature Discovery tab. The, click Create Node Feature Discovery:
At the next step, click Create:
-
After the installation of the NDF Operator, you will see additional labels listed for the worker nodes. From these logs, its possible to observe that the instances supports several of the Intel software acceleration capabilities and instructions, these include :
- Intel® AES-NI - Intel® Advanced Encryption Standard (AES) New Instructions
- Intel® AVX-512 - Intel® Advanced Vector Instructions 512
- Intel® VNNI - Intel® Vector Neural Network Instructions
% oc get nodes ip-10-0-154-108.us-west-2.compute.internal -o yaml
(...)
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/instance-type: c6i.4xlarge
beta.kubernetes.io/os: linux
failure-domain.beta.kubernetes.io/region: us-west-2
failure-domain.beta.kubernetes.io/zone: us-west-2a
feature.node.kubernetes.io/cpu-cpuid.ADX: "true"
feature.node.kubernetes.io/cpu-cpuid.AESNI: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX2: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX512BITALG: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX512BW: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX512CD: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX512DQ: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX512F: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX512IFMA: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX512VBMI: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX512VBMI2: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX512VL: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX512VNNI: "true"
feature.node.kubernetes.io/cpu-cpuid.AVX512VPOPCNTDQ: "true"
feature.node.kubernetes.io/cpu-cpuid.FMA3: "true"
feature.node.kubernetes.io/cpu-cpuid.GFNI: "true"
feature.node.kubernetes.io/cpu-cpuid.HYPERVISOR: "true"
feature.node.kubernetes.io/cpu-cpuid.IBPB: "true"
feature.node.kubernetes.io/cpu-cpuid.SHA: "true"
feature.node.kubernetes.io/cpu-cpuid.STIBP: "true"
feature.node.kubernetes.io/cpu-cpuid.VAES: "true"
feature.node.kubernetes.io/cpu-cpuid.VPCLMULQDQ: "true"
feature.node.kubernetes.io/cpu-cpuid.WBNOINVD: "true"
feature.node.kubernetes.io/cpu-hardware_multithreading: "true"
feature.node.kubernetes.io/cpu-pstate.status: passive
feature.node.kubernetes.io/cpu-pstate.turbo: "true"
feature.node.kubernetes.io/kernel-config.NO_HZ: "true"
feature.node.kubernetes.io/kernel-config.NO_HZ_FULL: "true"
feature.node.kubernetes.io/kernel-selinux.enabled: "true"
feature.node.kubernetes.io/kernel-version.full: 4.18.0-372.19.1.el8_6.x86_64
feature.node.kubernetes.io/kernel-version.major: "4"
feature.node.kubernetes.io/kernel-version.minor: "18"
feature.node.kubernetes.io/kernel-version.revision: "0"
feature.node.kubernetes.io/pci-1d0f.present: "true"
feature.node.kubernetes.io/storage-nonrotationaldisk: "true"
feature.node.kubernetes.io/system-os_release.ID: rhcos
feature.node.kubernetes.io/system-os_release.OPENSHIFT_VERSION: "4.11"
feature.node.kubernetes.io/system-os_release.OSTREE_VERSION: 411.86.202208031059-0
feature.node.kubernetes.io/system-os_release.RHEL_VERSION: "8.6"
feature.node.kubernetes.io/system-os_release.VERSION_ID: "4.11"
feature.node.kubernetes.io/system-os_release.VERSION_ID.major: "4"
feature.node.kubernetes.io/system-os_release.VERSION_ID.minor: "11"
kubernetes.io/arch: amd64
kubernetes.io/hostname: ip-10-0-154-108.us-west-2.compute.internal
kubernetes.io/os: linux
node-role.kubernetes.io/worker: ""
node.kubernetes.io/instance-type: c6i.4xlarge
node.openshift.io/os_id: rhcos
topology.ebs.csi.aws.com/zone: us-west-2a
topology.kubernetes.io/region: us-west-2
topology.kubernetes.io/zone: us-west-2a
(...)
3: Run the MonteCarlo-AVX512 demo on ROSA
You can access the Monte-Carlo-AVX512 simulation demo code from the following GitHub :
To run the simulation, clone the workspace, and then run the “deploy.sh” script
The script will execute the following :
- Create a new dedicate project called “Monte-Carlo”
- Deploy two versions of the container image, one with Intel® AVX-512 enabled, and one where Intel® AVX-512 is disabled (uses Intel® AVX2 only), using the NFD-applied labels for scheduling.
- Install the Grafana community operator (v4.6) and create a Grafana instance for the dashboard
- Install the Prometheus Pushgateway container image - enable the end point to export metrics into the Prometheus gateway
- Create the service monitor and specify the intervals to capture the metrics
- Configure the Red Hat Monitoring stack such that it can capture the necessary metrics and display the results in the Grafana dashboard
- Export the Grafana dashboard route to the user
# Create new project and switch to it
oc new-project monte-carlo
oc project monte-carlo
# Enable user-workload monitoring
oc apply -f user-workloads.yaml
# Deploy avx512 and avx2 workloads
# services, pushgw, and service monitors
oc apply -f 01-avx512.yaml
oc apply -f 02-avx2.yaml
# Deploy Grafana Operator and Instance
oc apply -f grafana-operator.yaml
until oc get deployment grafana-operator-controller-manager 2>/dev/null; do
echo "Waiting for Grafana operator deployment to be created"
sleep 1
done
oc wait deployment grafana-operator-controller-manager --for condition=Available
oc apply -f grafana-instance.yaml
until oc get deployment grafana-deployment 2>/dev/null; do
echo "Waiting for Grafana instance deployment to be created"
sleep 1
done
oc wait deployment grafana-deployment --for condition=Available
# Sleep whilst Grafana comes up
sleep 30
# Add service account to pull Prometheus data and add datasource
oc adm policy add-cluster-role-to-user cluster-monitoring-view -z grafana-serviceaccount
export BEARER_TOKEN=$(oc serviceaccounts get-token grafana-serviceaccount -n monte-carlo)
envsubst < grafana-datasource.yaml | oc apply -f -
# Deploy Grafana dashboard
oc apply -f grafana-dashboard.yaml
# Sleep and wait for route
sleep 20
export GRAFANA_ROUTE=$(oc get route/grafana-route -n monte-carlo | awk '/grafana/ {print $2;}')
echo "Grafana exposed at: https://$GRAFANA_ROUTE/d/qCiDx4mVl/intel-avx512-red-hat-openshift?orgId=1 (admin=redhat/redhat)"
On accessing the Grafana route you can see the benchmark results displayed in the graph. The orange line is the elapsed cycle time of the container image using Intel® AVX-512. The green line is the elapsed time for the image running Intel® AVX2. It can be observed that the orange line is showing a near 50% reduction in time. Note that it may take a few minutes for data to start feeding in.
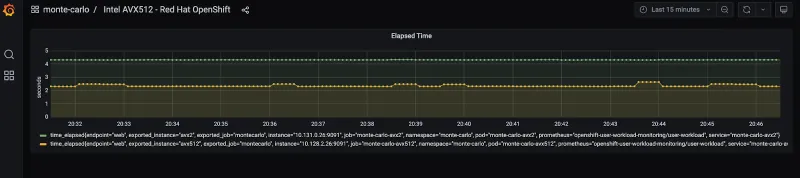
Conclusion
In this blog we discussed the benefits of Red Hat OpenShift on AWS (ROSA), when deployed on 3rd Generation Intel® Xeon® Scalable Processor c6i instances. Furthermore, we have shown that many of the advanced acceleration capabilities & instructions, can directly benefit the workload application. In this specific example, we have shown the performance benefits to a computationally intensive workload such as the Monte Carlo simulation, which resulted in a 50% reduction in time taken to complete the simulation. In other words, application performance doubles running with AVX512 compared to AVX2. Both the performance benefit and the reduction in completion time can be translated into energy savings and thus can contribute to the sustainability agenda.
About the authors

Mayur Shetty is a Principal Solution Architect with Red Hat’s Global Partners and Alliances (GPA) organization, working closely with cloud and system partners. He has been with Red Hat for more than five years and was part of the OpenStack Tiger Team.

More like this
F5 BIG-IP Virtual Edition is now validated for Red Hat OpenShift Virtualization
Looking ahead to 2026: Red Hat’s view across the hybrid cloud
Challenges In Solutions Engineering | Code Comments
Transforming Your Timelines | Code Comments
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds