


When dealing with large, complex systems, you often need to replicate configurations between environments or sites. Treating your configs as a form of code, called Configuration as Code (CaC or CasC), allows you to track bugs, fixes, and deployments.
[ Download Ansible for DevOps. ]
Many sites use database replication to copy data from one environment to another (for instance, importing data from one Ansible Automation Platform site to another). This approach can require a dedicated infrastructure, specialized teams to handle the process, and complex procedures for switching the active site. This design can affect consistency across multiple environments or sites.
This two-part series demonstrates configuring an Ansible automation controller in an active/passive multisite architecture using a CaC approach.
How automation controller and CaC work together
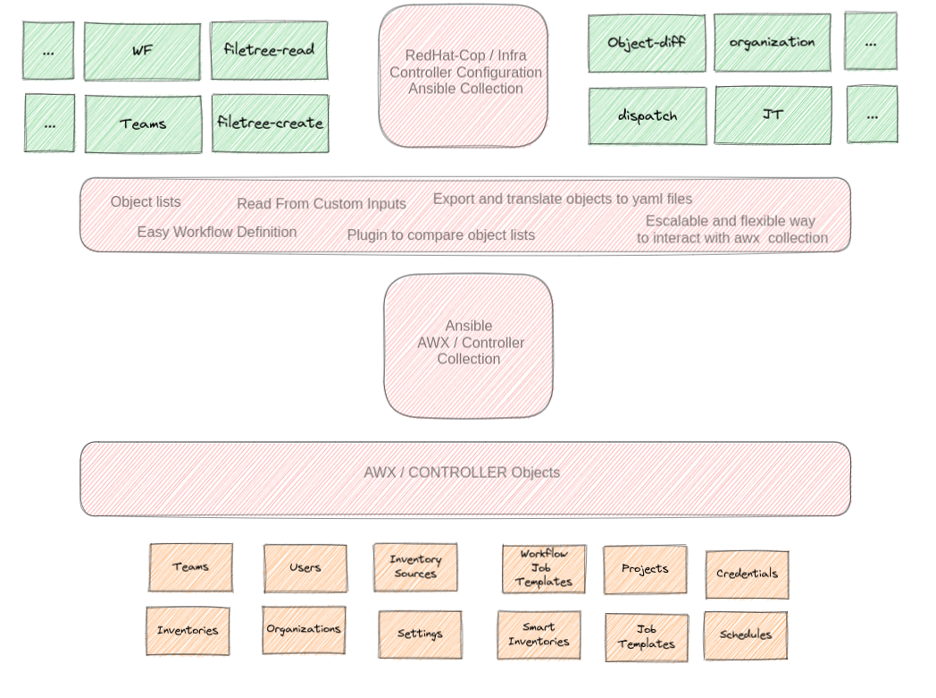
How does an automation controller fit into CaC? Some Ansible collections already have it implemented, so much of the groundwork is already complete. Here are the components:
- AWX/Ansible.Controller: This collection provides modules to connect and manage all objects of an AWX/controller. AWX is a user interface, REST API, and task engine built on Ansible.
- infra.controller_configuration: This collection builds upon AWX/Ansible.Controller, adding flexibility to work in a scalable way. This collection is Ansible-validated content distributed through the Ansible Automation Platform product subscription, shared and preinstalled in the Ansible Automation Platform (but not supported).
The Ansible roles used from this collection to create a continuous deployment flow are:
- filetree_read: This Ansible role reads variables from a hierarchical and scalable directory structure grouped based on the configuration code lifecycle. You can use it to run the filetree_read role to load variables, followed by a dispatch role to apply the configuration.
- filetree_create: The filetree_create role is intended to be the first step when you already have a running instance of either Ansible Tower or Ansible automation controller, as it's intended to export all your existing objects and configuration and generate an initial version of them as code. Although you could write your objects as code from scratch, this role's purpose is to make the task a little bit easier. One thing to consider is that the sensible information from the credentials will not be extracted.
- object_diff: This Ansible role manages the object diff of the AWX or automation controller configuration. The role leverages the controller_object_diff.py lookup plugin of the infra.controller_configuration. It compares two lists, one from the API and the other from the Git repository, and can delete objects in the AWX or automation controller that are not defined in the Git repository list.
- dispatch: This is an Ansible role to run all roles on Ansible Controller.
Define the CaC repository structure
You first need to define where the configuration is stored and how it will be retrieved. This step is important because the complete automation tool's configuration should be accessible, but you must also protect sensitive data.
- Where should it be stored? As the configuration must be versioned and immutable, a Git repository is ideal. This also permits you to leverage Git features, practices, and methodologies, which is perfect because the goal is to treat configuration as code.
- How should you structure it? A directory structure provides the flexibility and scalability to organize the configuration logically.
- How should you handle sensitive data? Ansible Vault provides an encryption layer for protecting sensitive data.
[ Related reading: How to encrypt sensitive data in playbooks with Ansible Vault ]
It's a good idea to create one Git repository for each organization. However, this solution allows you to have more than one organization in each Git repo if needed. Having just one super-admin organization for managing objects is strongly recommended. This organization contains only a subset of privileged users with the right Ansible Automation Platform expertise to handle the configuration.
You can leverage Git's branching features to handle multiple environments. Each repository must have a branch matching the environment where it belongs.

There's a rule in software development called DRY, which stands for "don't repeat yourself." Take this advice to heart, and create a directory structure to match objects by environment so that you can reuse them.
Of course, some objects are unique and must be differentiated. Because you're treating configuration as code or software, you can apply software development techniques and use variables.
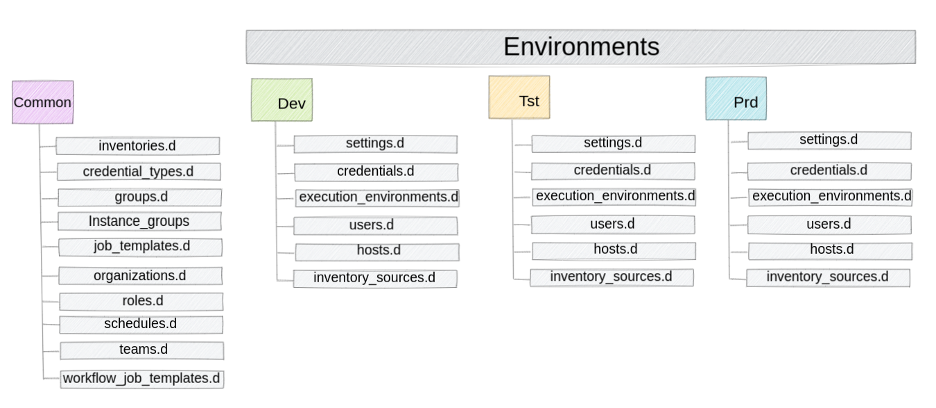
A consistent and well-defined directory structure, along with standard Git features, helps promote configuration between environments. You can branch, commit, tag, and merge configurations between branches, each of which represents a specific environment. This provides consistency across multiple Ansible automation controller deployments, allowing you to use the same configuration in all environments, even with the differences between them (such as credentials, hosts, and so on).
[ Also read: Set up GitLab CI and GitLab Runner to configure Ansible automation controller. ]
Understand the flow between the automation controller and CaC
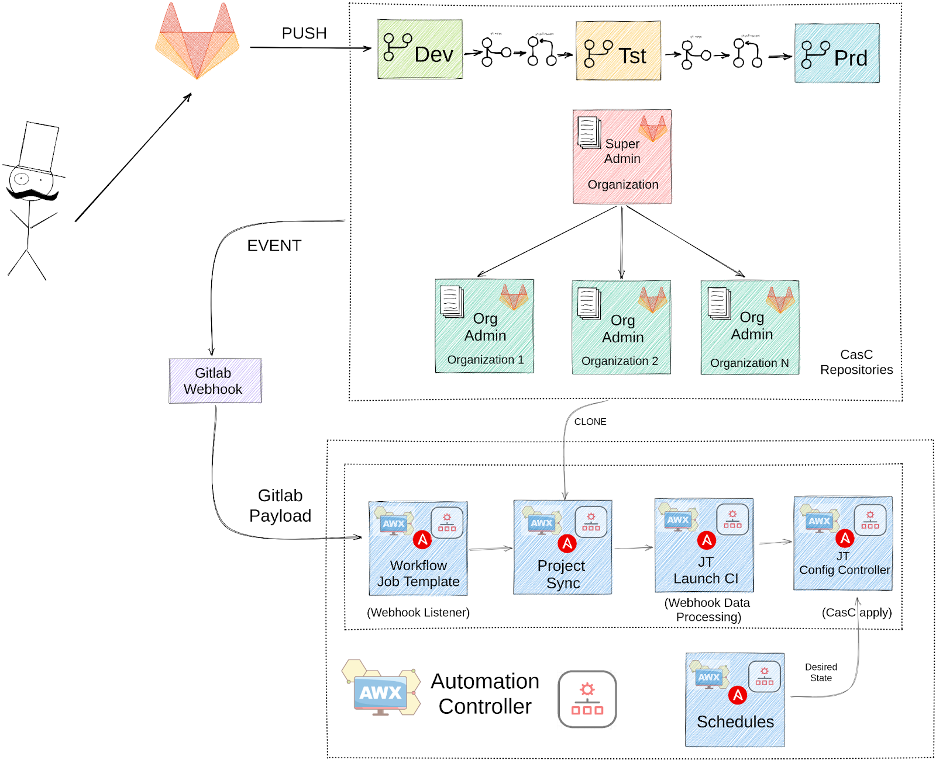
Here's the lifecycle of a configuration implementation, starting with its home in a Git repository and ending with the controller:
- The flow starts when configuration files are modified or added to an organization's Git repository in the Development branch.
- When a commit is made, an event is generated in the supply chain management (SCM), and the changes are uploaded to the Git repository.
- The Git event is sent through a Git hook payload with all the information related to the commit (what's been added, modified, or deleted, which organization made the change, and so on).
- A Workflow job template captures the data sent from the Git hook payload and triggers the execution of tasks:
- Project sync: This performs a Git clone and downloads any collections or roles it doesn't have in the execution environment.
- Processing: The data sent through the payload is processed and converted into YAML or JSON to be added as extra variables in the Job Template object.
- Action: The extra variables can perform actions on a Controller object with a Job Template object, which calls two other Job Templates containing the playbook to perform actions on the Controller objects.
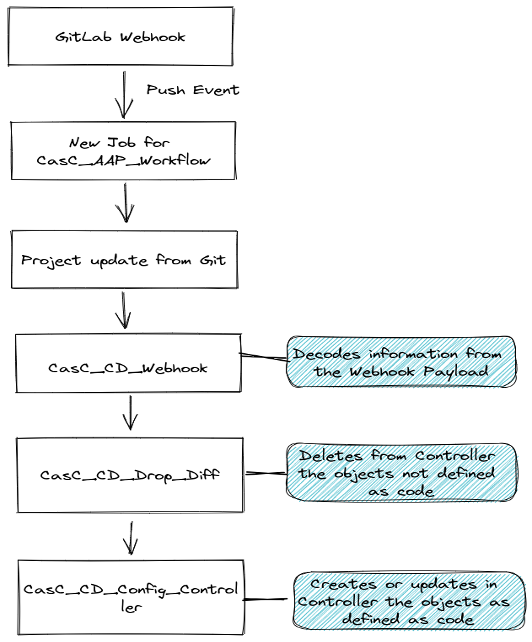
To be continuously reconciled, a scheduled object type observes the configuration state (an objects list from the API) and attempts to apply the desired configuration (an objects list from the Git repository).
Manage Ansible automation controller lifecycle configurations
Git methodologies and features are at the core of this implementation. Managing the automation controller configuration lifecycle is done through a basic Git workflow adapted for configurations.
The main idea is to always create temporary branches from the development branch to add, modify, or delete a controller's configuration. Once tested, you can promote it to other environments.
[ Ansible vs. Terraform, clarified ]
First, create a temporary branch to add the basic objects. This applies the configuration in the controller. These objects are projects, credentials, job_templates, workflow_job_templates, inventories, and hosts.
Once the configuration is applied and tested in the development environment, it can be promoted to the next environment until it reaches production.

Wrap up
This workflow's central idea is to test everything in the previous environment before applying it in a production environment. This helps avoid errors that lead to loss of service, platform instability, inconsistency, and so on.
Git has built-in features to enable a configuration rollback to a specific point in time or (in this case) a specific version release. Use Git tags to create a snapshot when a configuration is deemed safe for production. Should a failure occur in the code (configuration), you can check out the known -good Git tag.
The next article in this series explains how to use an automation controller, an active/passive architecture, and CaC.
[ Learn best practices for implementing automation across your organization. Download The automation architect's handbook. ]
About the authors
Silvio is an IT freak who loves to deploy free software and open source technologies in small home projects. He is a Cloud and Automation Architect at Red Hat.
Ivan is a fan of automation applied to everything and of sharing acquired knowledge. Serves as a consultant at Red Hat and enjoys mountain biking during free time.
Adonis is a system engineer with 10 years of experience working in different companies and projects. Technical profile focused on Linux OS-based technologies and on operation, administration, and implementation of new services on multiple platforms. Adonis is a Red Hat Certified Architect in Infrastructure and a consultant at Red Hat.
More like this
The evolution of infrastructure automation in the age of AI: 4 key takeaways from Red Hat Summit 2026
Why automated network configuration assurance matters for enterprise NetOps
Untangling Networks | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds