In the virtualization and high-performance computing landscape, SR-IOV (Single Root I/O Virtualization) devices and NUMA (Non-Uniform Memory Access) node scheduling are pushing forward the state of hardware resource utilization and performance optimization.
The current implementation of NUMA-aware pod scheduling can present pod deployment issues in some scenarios when combined with SR-IOV node network policies. For example, some containers are unnecessarily scheduled on the NUMA node hosting the virtual functions (VFs). This may leave no space for containers that actually need to be on that NUMA node.
This blog post explores how you can tweak SriovNetworkNodePolicies resources to make NUMA-aware scheduling more flexible.
Context
NUMA architecture
NUMA stands for Non-Uniform Memory Access and refers to multi-processor systems whose memory is divided into multiple memory nodes.
Modern CPUs operate considerably faster than the main memory they use, so CPUs increasingly find themselves starving for data.
Multi-processor systems only make the problem worse. Now, a system can have multiple processors starving for data simultaneously because only one can access the computer's memory at a time. In NUMA architecture CPUs, memory and I/O devices are separated into independent modules called NUMA zones, NUMA cells, or NUMA nodes. Each CPU can access the system's memory and devices because all NUMA nodes are interconnected. However, accessing memory or devices allocated in another NUMA node is considerably slower and could impact performance. Low latency is a critical requirement in some use cases, such as the telecommunications industry, and any performance impact caused by data transfer between NUMA nodes must be minimized.
NUMA-aware scheduling
In Kubernetes, the default pod-scheduler scheduling logic considers the entire compute node's available resources (CPU, memory, devices, etc.). However, kubelet does not consider NUMA zone locality to reserve resources unless Topology Manager is enabled, which could lead to performance problems for some workloads.
NUMA-aware resource managers, such as NUMA-aware Memory Manager and Topology Manager, were introduced in kubelet to allow alignment of resource reservation to NUMA nodes.
Each NUMA-aware resource manager implements the HintProvider interface and informs TopologyManager about the NUMA nodes where each resource request can be satisfied. Topology Manager merges all the hints from the different providers and, using the configured policy, it decides the resource reservation that better aligns with the NUMA node availability, if any.
NUMA-aware scheduling also considers NUMA node resource information to schedule the pods to worker nodes that can satisfy such requirements and minimize scheduling errors.
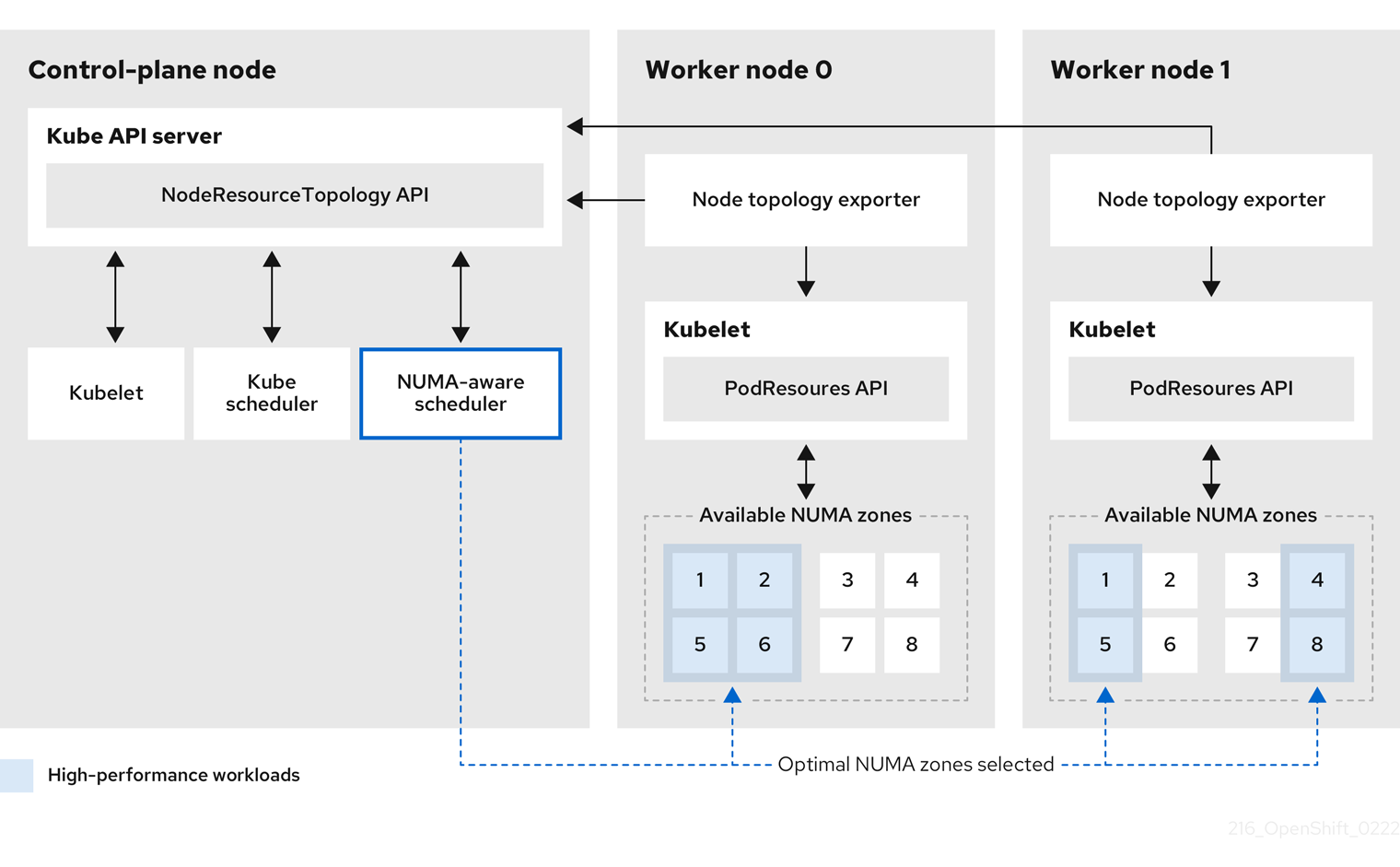
Current state
As I showed, Topology Manager merges all the hints from the different providers and decides the best resource reservation. A topology policy drives this decision. Four different policies are currently supported.
- none This is the default policy. Topology Manager does not perform any NUMA alignment
- best-effort With this policy, Topology Manager would try to align resources as much as possible, but it would let the pod start even if the resources cannot be allocated from the same NUMA node.
- restricted This policy is similar best-effort but pod admission will fail if the resources cannot be properly aligned. This policy would allow resource allocation from different NUMA nodes only if there would never be any other way to satisfy that allocation request. Example: Two different devices were requested, and the only two devices in the system are in different NUMA nodes.
- single-numa-node This is the most restrictive policy as it will only allow the allocation of resources aligned in one NUMA node.
Topology Policy is applied to all pods on a node globally. There is no way to select different policies for different pods or containers. Also, the Topology Policy is applied to all the different resources that the Topology Manager is aware of, any resource with a HintProvider, without distinction. Topology Manager does not handle CPU and memory alignment differently from device alignment.
Limitations
Applying the same topology policies to the resources requested by all the pods in the same node could fit some use cases where the weight of the alignment of the resources in the performance impact is the same. For example, this might occur in a telco Radio Access Network (RAN) application, where a dual-NUMA system with two network cards is often used (one per NUMA zone). One of those network cards is high-end and would be used for workloads that usually require low latency. However, only a subset of those workloads would need access to the management network interface, so all the workloads require memory and CPU alignment, and only a subset also requires network device alignment.
Example 1: A scientific research application using NVIDIA GPUDirect to achieve high data throughput. In this case, GPU, network adapter, and storage alignment are key, but CPU and memory could be in any other NUMA node without harming performance noticeably.
Example 2: A 3D rendering server. For this scenario, CPU, GPU, and memory alignment must have good performance, but network card alignment is not so critical as it only serves the results to clients.
One of these scenarios occurs when a workload needs CPU and memory NUMA alignment, but the network device could be on any other NUMA node. A single-numa-node policy should be used to provide CPU and memory alignment, but the workload could not be scheduled if the only network device is on a different NUMA node.
Here is the problem in more detail.
Problem with SR-IOV devices
SR-IOV devices can be consumed by workload pods using the OpenShift SR-IOV Network Operator. In its simplest form, a network device can be configured by a SriovNetworkNodePolicy:
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: test-network-policy
namespace: openshift-sriov-network-operator
spec:
deviceType: netdevice
nicSelector:
deviceID: "158b"
rootDevices:
- 0000:3b:00.0
vendor: "8086"
nodeSelector:
kubernetes.io/hostname: worker1
numVfs: 32
resourceName: testSriovResource
The example above configures a network device selected by the nicSelector field to have 32 Virtual Functions. Notice that the 0000:3b:00.0 device is an Intel XXV710 Ethernet Controller installed on NUMA node 0:
$ oc debug node/worker1 -- lspci -v
...
3b:00.0 Ethernet controller: Intel Corporation Ethernet Controller XXV710 for 25GbE SFP28 (rev 02)
Subsystem: Intel Corporation Ethernet 25G 2P XXV710 Adapter
Flags: bus master, fast devsel, latency 0, IRQ 160, NUMA node 0, IOMMU group 63
...
The node has two NUMA nodes with 52 CPUs each:
$ oc debug node/worker1 -- lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 104
On-line CPU(s) list: 0-103
Thread(s) per core: 2
Core(s) per socket: 26
Socket(s): 2
NUMA node(s): 2
…
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54,56,58,60,62,64,66,68,70,72,74,76,78,80,82,84,86,88,90,92,94,96,98,100,102
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63,65,67,69,71,73,75,77,79,81,83,85,87,89,91,93,95,97,99,101,103
In this example, the kubelet on the node has been configured with TopologyManger set to single-numa-node:
$ oc debug node/worker1 -- chroot /host journalctl -b
...
I0824 11:13:35.893045 6899 topology_manager.go:136] "Creating topology manager with policy per scope" topologyPolicyName="single-numa-node" topologyScopeName="container"
The network device resource can be referred to as testSriovResource when creating a SriovNetwork:
apiVersion: v1
kind: Namespace
metadata:
name: test-sriov-exclude-topology
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: test-sriov-network
namespace: openshift-sriov-network-operator
spec:
capabilities: '{"mac": true, "ips": true}'
ipam: '{ "type": "host-local", "subnet": "192.0.2.0/24" }'
networkNamespace: test-sriov-exclude-topology
resourceName: testSriovResource
Consider creating four pods consuming 16 CPUs and one Virtual Function each for this scenario.
# pod.yaml
apiVersion: v1
kind: Pod
metadata:
namespace: test-sriov-exclude-topology
generateName: pod-16cpu-
labels:
app: test
annotations:
k8s.v1.cni.cncf.io/networks: "test-sriov-network"
spec:
containers:
- name: test
image: registry.fedoraproject.org/fedora
command:
- bash
- -xc
- |
while true; do
cat /proc/self/status | grep Cpus
cat /sys/class/net/net1/device/numa_node
sleep 10
done
resources:
limits:
cpu: 16
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
capabilities:
drop:
- ALL
$ for i in {0..3}; do
oc create -f pod.yaml
done
$ oc get pod
NAME READY STATUS RESTARTS AGE
pod-16cpu-4ld4s 1/1 Running 0 33s
pod-16cpu-pxvzd 1/1 Running 0 34s
pod-16cpu-xnp54 1/1 Running 0 34s
pod-16cpu-7zf66 0/1 ContainerStatusUnknown 0 32s
The latest pod created pod-16cpu-7zf66 cannot be scheduled due to a topology error, as the NUMA node 0 has only 52 cores, while 64 were needed in total (16 cpus x 4 pods).
$ oc describe pod/pod-16cpu-7zf66
…
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 3m23s default-scheduler Successfully assigned test-sriov-exclude-topology/pod-16cpu-7zf66 to worker1
Warning TopologyAffinityError 3m23s kubelet Resources cannot be allocated with Topology locality
While the other pods run on NUMA node 0 CPUs:
---- pod-16cpu-4ld4s ----
+ cat /proc/self/status
Cpus_allowed: 15,55400000,00015554,00000000
Cpus_allowed_list: 34,36,38,40,42,44,46,48,86,88,90,92,94,96,98,100
+ cat /sys/class/net/net1/device/numa_node
0
---- pod-16cpu-pxvzd ----
+ cat /proc/self/status
Cpus_allowed: 00,00155540,00000001,55540000
Cpus_allowed_list: 18,20,22,24,26,28,30,32,70,72,74,76,78,80,82,84
+ cat /sys/class/net/net1/device/numa_node
0
---- pod-16cpu-xnp54 ----
+ cat /proc/self/status
Cpus_allowed: 00,00000015,55400000,00015554
Cpus_allowed_list: 2,4,6,8,10,12,14,16,54,56,58,60,62,64,66,68
+ cat /sys/class/net/net1/device/numa_node
0
A network device in a different NUMA node does not produce a significant performance drop in some scenarios.
ExcludeTopology solution
To overcome the topology limitation, the SR-IOV network operator lets you create policies that don't advertise the NUMA node topology of the network device. This way, a pod can be scheduled on CPUs on a different NUMA node than the network Virtual Function while having all other resources (CPU, memory, etc.) still NUMA aligned. The SriovNetworkNodePolicy.Spec.ExcludeTopology field must be set to true to complete the scenario.
$ oc patch -n openshift-sriov-network-operator sriovnetworknodepolicy/test-network-policy \
--type='json' -p='[{"op": "replace", "path": "/spec/excludeTopology", "value":true }]'
sriovnetworknodepolicy.sriovnetwork.openshift.io/test-network-policy patched
$ oc create -f pod.yaml
pod/pod-16cpu-9qv77 created
$ oc logs pod-16cpu-9qv77
+ cat /proc/self/status
Cpus_allowed: 00,0000000a,aaa00000,0000aaaa
Cpus_allowed_list: 1,3,5,7,9,11,13,15,53,55,57,59,61,63,65,67
+ cat /sys/class/net/net1/device/numa_node
0
Pod pod-16cpu-9qv77 runs on NUMA 1 CPUs while having access to a NUMA node 0 Virtual Function.
The feature has been available since release 4.13.12 and should be considered a short-term choice, while more robust, long-term solutions are under active development.
Possible ways forward
Flexible NUMA
The above discussion examines the current situation, but what about the future? I'll explore what's coming. Red Hat is currently working on making NUMA-aware scheduling even more flexible.
Multiple efforts are currently in different phases of design and development. They seek to improve NUMA-aware scheduling in various areas like:
- Allow pods/containers to ask for less strict alignment policies.
- Eviction and pod de-scheduling based not just on QoS but also on the alignment requirements.
- Allowing pods/containers to ask for different alignment policies for various resources.
The first two elements would help to improve node density and reduce the impact of a common use case where pods with lax alignment requirements are scheduled before pods requiring a stricter alignment, preventing the latter from being admitted when there could be resources for both.
The last one is the most relevant for this scenario. By being able to specify different alignment policies for each of the required resources, workloads could explicitly state the relative importance of the resources so users could tailor workload alignment requirements to avoid scenarios where network cards or other similar devices could prevent them from being scheduled properly.
About the authors

More like this
The agentic paradox and the case for hybrid AI
Context-aware advisor recommendations in Red Hat Lightspeed
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds