While the potential for Artificial Intelligence (AI) and Machine Learning (ML) is abound, organizations face challenges scaling AI. The major challenges are:
- Sharing and Collaboration: Unable to easily share and collaborate, iteratively and rapidly
- Data access: Access to data is bespoke, manual and time consuming
- On-demand: No on-demand access to ML tools and frameworks and compute infrastructure
- Production: Models are remaining prototypes and not going into production
- Tracking and Explaining AI: Reproducing, tracking and explaining results of AI/ML is hard
Unaddressed, these challenges impact the speed, efficiency and productivity of the highly valuable data science teams. This leads to frustration, lack of job satisfaction and ultimately the promise of AI/ML to the business is not redeemed.
IT departments are being challenged to address the above. IT has to deliver a cloud-like experience to data scientists. That means a platform that offers freedom of choice, is easy to access, is fast and agile, scales on-demand and is resilient. The use of open source technologies will prevent lockin, and maintain long term strategic leverage over cost.
In many ways, a similar dynamic has played out in the world of application development in the past few years that has led to microservices, the hybrid cloud and automation and agile processes. And IT has addressed this with containers, kubernetes and open hybrid cloud.
So how does IT address this challenge in the world of AI - by learning from their own experiences in the world of application development and applying to the world of AI/ML. IT addresses the challenge by building an AI platform that is container based, that helps build AI/ML services with agile process that accelerates innovation and is built with the hybrid cloud in mind.
To do this, we start with Red Hat OpenShift, the industry leading container and Kubernetes platform for hybrid cloud, with over 1300 customers worldwide, and fast growing ML software and hardware ecosystem (e.g. NVIDIA, H2O.ai, Starburst, PerceptiLabs, etc.). Several customers (e.g. HCA Healthcare, ExxonMobil, BMW Group, etc.) have deployed containerized ML tool chain and DevOps processes on OpenShift and our ecosystem partners to operationalize their preferred ML architecture, and accelerate workflows for data scientists.
We have also initiated Open Data Hub project, an example architecture with several upstream open source technologies, to show how the entire ML lifecycle can be demonstrated on top of OpenShift
The Open Data Hub Project
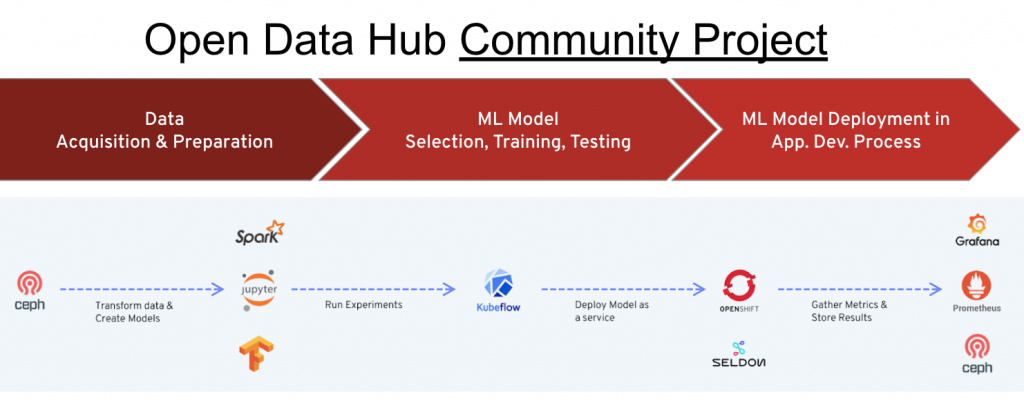
So what is Open Data Hub project? Open Data Hub is an open source community project that implements end-2-end workflows from data ingestion, to transformation to model training and serving for AI and ML with containers on Kubernetes on OpenShift. It is a reference implementation on how to build an open AI/ML-as-a-service solution based on OpenShift with open source tools e.g. Tensorflow, JupyterHub, Spark, etc.. Red Hat IT has operationalized Open Data Hub project to provide AI and ML services within Red Hat. In addition, OpenShift also integrates with key ML software and hardware ISVs such as NVIDIA, Seldon, Starbust and others in this space to help operationalize your ML architecture.
Open Data Hub project addresses the following use cases:
- As a Data Scientist, I want a “self-service cloud like” experience for my Machine Learning projects.
- As a Data Scientist, I want the freedom of choice to access a variety of cutting edge open source frameworks and tools for AI/ML.
- As a Data Scientist, I want access to data sources needed for my model training.
- As a Data Scientist, I want access to computational resources such as CPU, Memory and GPUs.
- As a Data Scientist, I want to collaborate with my colleagues and share with them my work, obtain feedback improve and iterate rapidly.
- As a Data Scientist, I want to work with developers (and devops) to deliver my ML models and work into production
- As a data engineer, I want to provide data scientists with access to various data sources with appropriate data controls and governance.
- As an IT admin/operator, I want to easily control the life cycle (install, configure and updates) of the open source components and technologies. And I want to have appropriate controls and quotas in place.
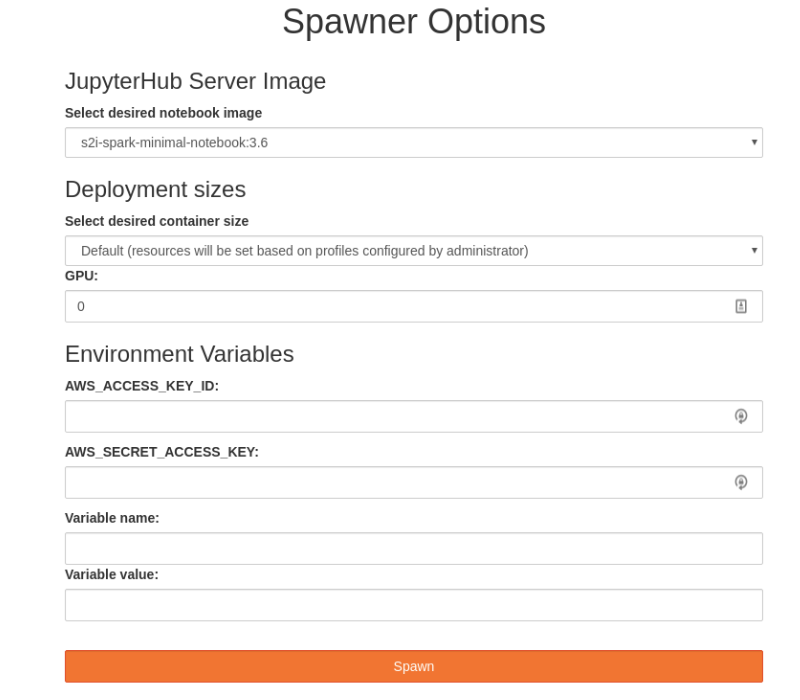
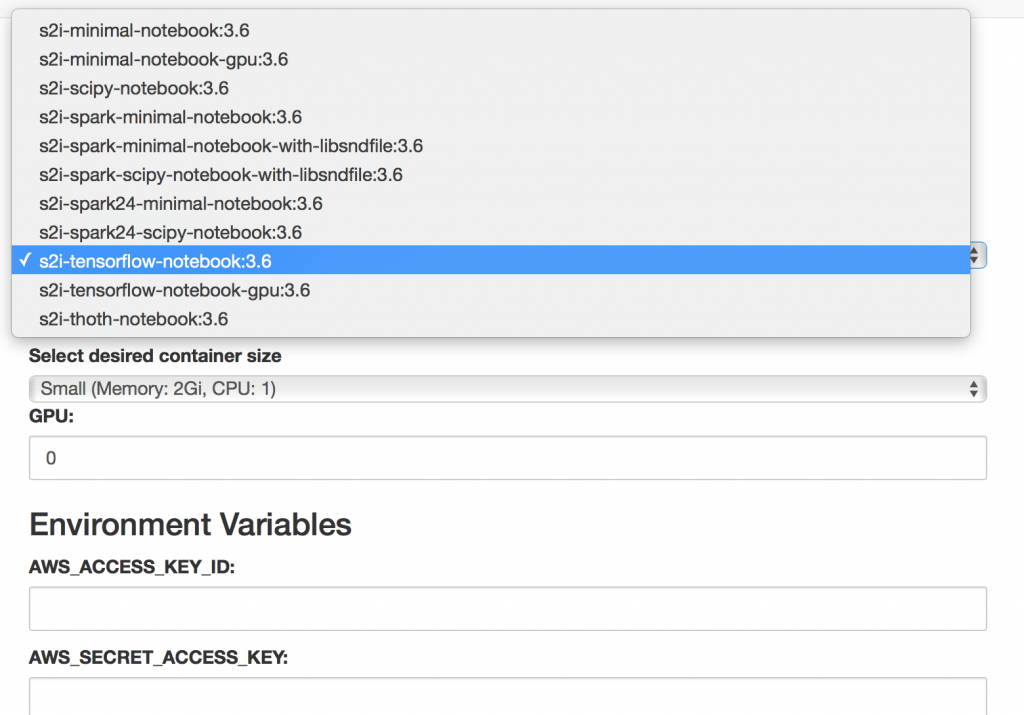
The Open Data Hub project integrates a number of open source tools to enable an end to end AI/ML workflow. Jupyter notebook ecosystem is provided as the primary interface and experience to the data scientist. And the main reason for that is that Jupyter is widely popular amongst data scientists today. Data scientists can create and manage their Jupyter notebooks workspaces with an embedded JupyterHub. While they can create or import new notebooks, Open Data Hub project also includes a number of pre-existing notebooks called the “AI Library”. This AI Library is an open source collection of AI components machine learning algorithms and solutions to common use cases to allow rapid prototyping. JupyterHub integerates with OpenShift RBAC (Role Based Access Control) and therefore users only need to use their existing OpenShift platform credentials and sign on only once (single sign on). JupyterHub has a convenient user interface (called spawner) that allows the user to conveniently chose the notebooks from a drop down menu and specify the amount of compute resources (like number of CPU cores, memory and GPUs) needed to run their notebooks. Once the data scientists spawns the notebook, the Kubernetes scheduler (that is part of OpenShift) takes care of appropriately scheduling the notebooks. Users can perform their experiments and save and share their work. In addition, expert users can access the OpenShift CLI shell directly from their notebooks to make use of Kubernetes primitives such as Job or OpenShift capabilities such as Tekton or Knative. Or they can access these from the convenient Graphical User Interface (GUI) OpenShift called the OpenShift web console.
Next, Open Data Hub project provides capabilities to manage data pipelines. Ceph object is provided as the S3 compatible Object store for data. Apache Spark is provided to stream data from external sources or the embedded Ceph S3 store and also for manipulating data. Apache Kafka is also provided for advanced control of the data pipeline (where there can be multiple data ingest, transformation, analysis and store steps).
The data scientist has accessed data and built a model. Now what. The data scientist may want to share her or his work as a service with others such as fellow data scientists or application developers or analysts. Inference servers can make this happen. Open Data Hub project provides Seldon as the inferencing server so that models can be exposed as a RESTful service.
At this point, there are one or more models being served by Seldon inference server. To monitor the performance of the model serving, Open Data Hub project also provides metrics collection and reporting with Prometheus and Grafana. They are very popular open source monitoring tools. This provides for the necessary feedback loop to monitor the health of the AI model particularly in production.
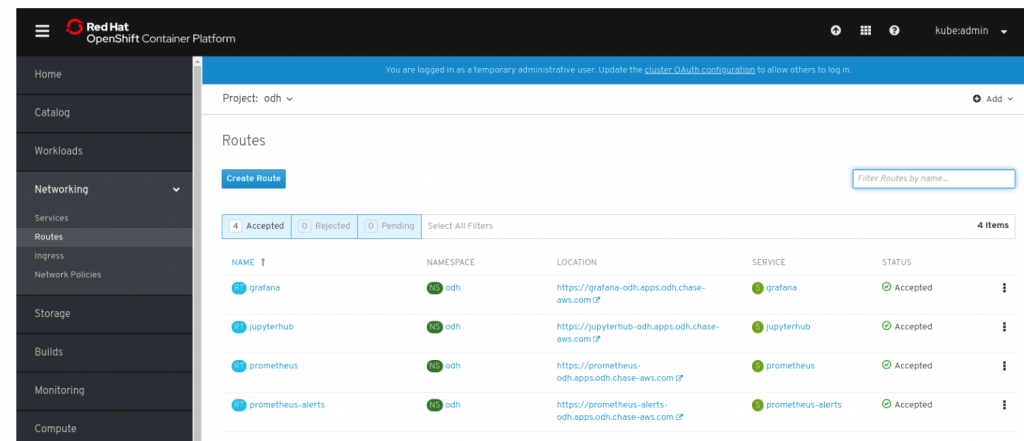
As you can see Open Data Hub project thus enables a cloud-like experience for an end-2-end workflow from data access and manipulation, through to model training and finally model serving.
Putting it all Together
As an OpenShift administrator how do I make all this happen. We introduce the Open Data Hub project Operator!
 The Open Data Hub project Operator manages the install, configuration and lifecycle of the Open Data Hub project. This includes the deployment of aformentoned tools such as JupyterHub, Ceph, Spark, Kafka, Seldon, Prometheus and Grafana. The Open Data Hub project can be found in the OpenShift web console (as a community operator). OpenShift admins can therefore chose to make Open Data Hub project to specific OpenShift projects. This is done once. After that, data scientists log into their project spaces on OpenShift web console and find the Open Data Hub project operator installed and available in their projects. They can then choose to instantiate the Open Data Hub project for their project with a simple click and start accessing the tools (described above) right away. And this setup can be configured to be highly available and resilient.
The Open Data Hub project Operator manages the install, configuration and lifecycle of the Open Data Hub project. This includes the deployment of aformentoned tools such as JupyterHub, Ceph, Spark, Kafka, Seldon, Prometheus and Grafana. The Open Data Hub project can be found in the OpenShift web console (as a community operator). OpenShift admins can therefore chose to make Open Data Hub project to specific OpenShift projects. This is done once. After that, data scientists log into their project spaces on OpenShift web console and find the Open Data Hub project operator installed and available in their projects. They can then choose to instantiate the Open Data Hub project for their project with a simple click and start accessing the tools (described above) right away. And this setup can be configured to be highly available and resilient.
To get started on Open Data Hub project, try it out by simply following the install and basic tutorial instructions. Architecture details about the Open Data Hub project can be found here. Looking forward, we are excited about the roadmap. Among the highlights are additional integrations with Kubeflow, focus on data governance and security and integrations with rules based system - especially open source tools - Drools and Optaplanner. As a community project, you can have a say in all this by joining the Open Data Hub project community.
In summary, there are serious challenges to scaling AI/ML within an enterprise to realize the full potential. Red Hat OpenShift has a track record of addressing similar challenges in the software world. The Open Data Hub is a community project and reference architecture that provides a cloud-like experience for end to end AI/ML workflows on a hybrid cloud platform with OpenShift. We have an exciting and robust roadmap in service of this basic mission. Our vision is to encourage a robust and thriving open source community for AI on OpenShift.
About the author

More like this
Designing multitenant GPU infrastructure: Isolation across virtualization and Kubernetes platforms
Unlocking sovereign AI and protected collaboration with confidential computing
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds