
Introducing EUS-to-EUS Updates
Beginning with the update between 4.8 and 4.10, OpenShift now offers customers the option to update between two Extended Update Support versions with only a single restart of non-Control-Plane nodes. This reduces total update duration and workload restarts while adhering to Kubernetes Version Skew Policies, which require serialized updates of all components other than the Kubelet.
Benefits of EUS-to-EUS Updates
The Kubernetes and OpenShift communities move pretty fast, historically releasing a new minor version every three months and only recently moved to a four month release cadence. This pace of innovation coupled with the requirement that all Kubernetes minor version updates are serialized has led some customers to fall behind. Once customers fall behind, they will need to dedicate time and effort to catch up to the latest version.
By allowing administrators to update their clusters between EUS versions with reduced workload disruption and overall update duration, we’re cutting in half the minimum number of maintenance events required to maintain a supported long lived cluster.
Note: Because all nodes are Control Plane nodes in either Single-Node OpenShift (SNO) or Compact Clusters, EUS-to-EUS upgrades are not available to those cluster topologies.
Performing an EUS-to-EUS Update
Performing an EUS-to-EUS update is relatively straightforward. Prior to upgrading from 4.8 to 4.9, you would need to pause non-Control-Plane MachineConfigPools (MCPs), update the cluster from 4.8 to 4.9, update again from 4.9 to 4.10, then finally unpause any MCPs you paused at the beginning of this process.
The following table illustrates which portions of the cluster are updated at each of the major steps along the 4.8 to 4.10 EUS-to-EUS update path. It’s very important to understand that the cluster control plane will run OpenShift 4.9 and the CVO managed containers on the worker nodes will run 4.9 as an intermediate step, but the RHCOS version on the worker nodes stays on 4.8 until the reboot to 4.10.
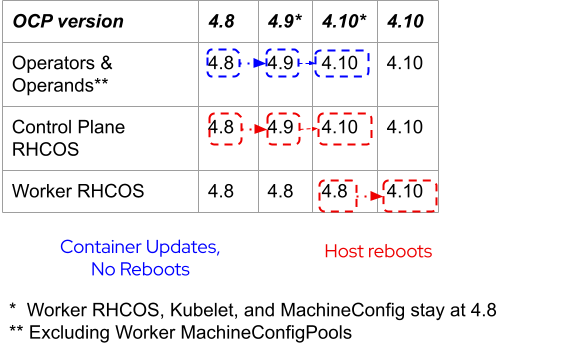
Refer to the EUS-to-EUS update documentation for the full procedure including prerequisites.
The Results

Workloads are only restarted once during the last step when worker nodes are updated from RHCOS 4.8 to 4.10.
Compared with a full update from 4.8 to 4.9 to 4.10, the overall duration of an EUS-to-EUS update can be reduced by up to 70 minutes in a 20 node cluster (in our testing), where it takes only 5 minutes to drain and update each worker. In many customer environments, the time to drain and reboot nodes is considerably longer due to workload or infrastructure characteristics such as bare metal hosts which may take 10-15 minutes just to reboot. For clusters with several nodes, reducing the number of reboots will help reduce time and enable customers to stay within their allotted maintenance windows.
Introducing Guard Rails
With the introduction of EUS-to-EUS updates, we wanted to make sure that the product protected you from upgrading too fast or potentially violating compatibility matrices.
To that end, we made changes to be sure nodes do not violate version skew policies. For example, you’ll see a warning whenever your workers must catch up before starting the next minor version update.

In Operator Lifecycle Manager (OLM) operators, we added MaxOpenShiftVersion to prevent users from upgrading their OCP cluster before upgrading the installed operator version to any distribution which the operator is compatible with. This new capability is used extensively to identify OLM Operators, which depend on APIs which were removed in Kubernetes 1.22 and OpenShift 4.9. For example, a warning in the admin console is presented when the operator is incompatible with the OpenShift version:

Faster OpenShift Updates
Beyond EUS-to-EUS updates improvements, we made some significant overall update improvements particularly for multi-node OpenShift clusters. We reduced the non-worker update duration of a 250 nodes cluster from 7.5 hours to 1.5 hours. Since an EUS-to-EUS update still performs two updates of non-worker nodes, the impact of these changes is doubled, thus saving an extra 12 hours for a 250 nodes cluster update.
Update Aware Scheduling
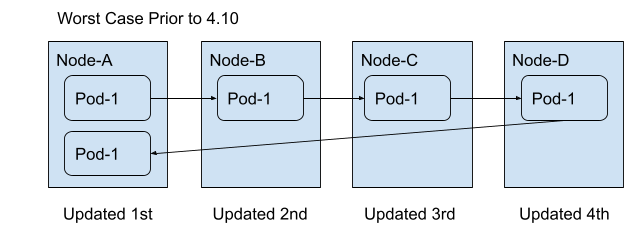
Beginning in OpenShift 4.10, the Machine Config Operator and Scheduler collaborate to prefer rescheduling pods toward nodes which have already been updated. Prior to this change in 4.10, if Pod-1 was originally scheduled to Node-A it could potentially be rescheduled to Node-B, then Node-C, then Node-D, and finally back to Node-A, in the worst case scenario. That equates to a total of 4 pod restarts as depicted in the following diagram:
With the changes introduced in 4.10, this is now much less likely to happen. Assuming sufficient capacity, the worst case now results in Pod-1 being rescheduled from Node-A to Node-B, then back to Node-A. In the best case, Pod-2 is rescheduled from Node-D to Node-C.
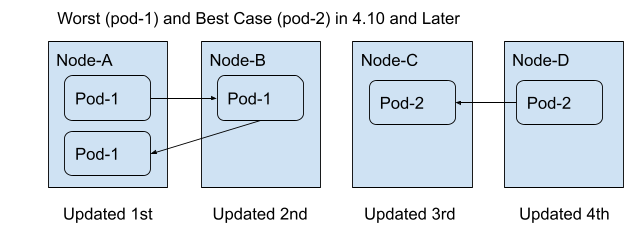
All existing scheduling constraints are still enforced, such as zone affinity or anti-affinity, volume attachment limits. Those constraints may limit the effectiveness of these improvements based on your workload design.
Try It Yourself
The full EUS-to-EUS Update experience will not be available in the EUS channels until Red Hat has promoted Updates from 4.9 to 4.10 into the Stable and EUS channels. However, you can test this Update pattern today by following the same procedure, the only change you’ll need to make is that rather than changing from eus-4.8 to eus-4.10 channel you will need to switch from stable-4.8 to stable-4.9 channel prior to upgrading to 4.9, then prior to upgrading to 4.10 you will switch to the fast-4.10 channel.
Please see Understanding Update Channels and Releases for more information on channel support status.
If you’d like to provide any feedback feel free to leave a comment on the EUS-to-EUS Updates JIRA.
About the author
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
How Red Hat OpenShift 4.22 impacts enterprise AI’s bottom line
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds