About Chaos Engineering
Chaos Engineering is a mechanism for injecting failures into software systems to test their resilience.
Chaos testing simulates different failure scenarios to check if the applications or the infrastructure will react accordingly in case real faults occur.
In the cloud native world, this concept is even more important because the systems are very dynamic (infrastructure and applications often scale; code changes often occur), and we need to ensure that these systems remain resilient.
Examples of chaos testing scenarios in a cloud-native environment include: filling up filesystem space on the cluster node where the application runs, simulating high memory or CPU usage on the pod or node, simulating network corruption or latency, restarting pods, ungracefully killing the application process or the container.
LitmusChaos
LitmusChaos is one of the CNCF projects for emulating different chaos scenarios that integrates very well with OpenShift.
It uses the Operator pattern and relies on Custom Resource Definitions (CRDs) to define experiments. On top of that, LitmusChaos provides a UI, called Litmus ChaosCenter Dashboard (formerly Litmus Portal), where one can orchestrate and visualize the results and metrics of the conducted chaos testing scenarios.
Another important point about LitmusChaos is that it supports running container experiments using CRI-O runtime, making it compatible with OpenShift 4.
In this blog, I will focus on Litmus 2.
Operator
As mentioned earlier, LitmusChaos uses the Operator pattern to run its Chaos scenarios. Operators usually rely on CRDs to perform certain actions, and LitmusChaos operator watches for the following CRDs:
ChaosExperiment - defining the type of the experiment and low-level execution details. It serves as a blueprint that later can be bound to specific applications.
ChaosEngine - user-facing chaos resource to link ChaosExperiment(s) with specific applications. The application is identified by namespace, label, and type. Parameters in ChaosExperiment can be overridden at this layer. The chaos scenario will start executing when the spec.engineState is active.
ChaosResult - stores the results of the experiments and are updated by the ChaosEngines.
ChaosSchedule - used for scheduling ChaosEngines.
Workflow - set of experiments chained together embedding both ChaosEngines and ChaosExperiments. It is a core component for Litmus ChaosCenter and can be easily generated through the UI.
Security considerations
Some of the LitmusChaos experiments require elevated privileges on the cluster. Some examples of the elevated privileges required are: NET_ADMIN and SYS_ADMIN capabilities, hostPID, hostPath, running privileged container. To be able to run those experiments, a Security Context Constraint (SCC) will be required to be created and assigned to the Service Account which runs the experiments.
More details about why specific chaos scenarios require elevated privileges will be explained later in this blog post.
An example of SCC that works for most of the experiments can be found here:
https://raw.githubusercontent.com/radudd/litmus-chaos-openshift/main/manifests/scc.yaml
IMPORTANT: Pod experiments such as pod-memory-hog-exec or pod-cpu-hog-exec which simulate high memory, or high cpu usage do not require elevated privileges granted by this SCC.
Running modes
LitmusChaos supports two running operating models:
Cluster mode: In this mode, there is one central Litmus installation in the cluster. LitmusChaos Operator will have cluster-wide privileges to run experiments against any pod or container in the cluster or against any node. For this kind of deployment, both the Litmus operator and running the Chaos test scenarios are in general the responsibility of the cluster administrators.
Namespaced mode: Using the namespace mode, Litmus Operator is deployed together with the applications against which Litmus will simulate Chaos scenarios. Litmus Operator will only have access to the applications in that namespace, and therefore experiments are limited to a subset, such as the ones executed at pod or container level.
This deployment type is preferable for a self-service model, where developers or QA teams have the permissions to run tests against their own applications. In this blog, we will be focusing on this mode of operation.
Deployment
Deployment namespaced ChaosCenter Dashboard and Litmus Operator
To install LitmusChaos, one can use the official Helm Charts. LitmusChaos version 2 is a ChaosCenter Dashboard-centric version, and the Helm chart will deploy only its components: the UI, a GraphQL server, and a MongoDB.
To deploy Litmus ChaosCenter, first create a namespace:
oc new-project litmus-namespaced
Then add Litmus repo to Helm:
helm repo add litmuschaos https://litmuschaos.github.io/litmus-helm
Afterwards, create an override file according to the needs. We said that we will be using the namespaced mode operator. Besides that, because we will be deploying to OpenShift, we will set the portal services to type ClusterIP (instead of the default NodePort) and we will create a Route.
Please feel free to adjust the configuration according to the needs.
cat <<EOF > override-openshift.yaml
portalScope: namespace
portal.server.service.type: ClusterIP
portal.frontend.service.type: ClusterIP
openshift.route.enabled: true
EOF
Let’s proceed with the installation:
helm install chaos litmuschaos/litmus --namespace=litmus -f override-openshift.yaml
Wait for this to complete and then access the UI using the litmus-portal OpenShift route. The default login credentials are admin/litmus; however, they can be customized by setting the portal.server.authServer.env.ADMIN_USERNAME, respectively:portal.server.authServer.env.ADMIN_PASSWORD variables in the override file created before.
Once logged in, we will be assigned to the default Chaos project. Also, the admin user can now create additional users for different team members.
Let’s check the ChaosAgents section, where one can define the Kubernetes clusters used as targets for the LitmusChaos experiments:

The cluster where LitmusChaos is deployed should be already configured as an agent. Wait until the status becomes Active.
Under the hood after project assignment, Litmus ChaosCenter Dashboard will create the self-agent which in turn triggers the deployment of LitmusChaos Operator and its components to our namespace:
Now LitmusChaos is ready to be used.
Chaos Experiments
LitmusChaos uses the term Chaos Experiments for the resilience tests.
Experiments architecture
Below are presented two common architecture patterns for the experiments execution.
Simplified scenarios
In this first scenario, the experiments will be executed directly by the go-runner lib pod directly. The pod-memory-hog-exec and pod-cpu-hog-exec experiments that will be presented later are using this simplified architecture.
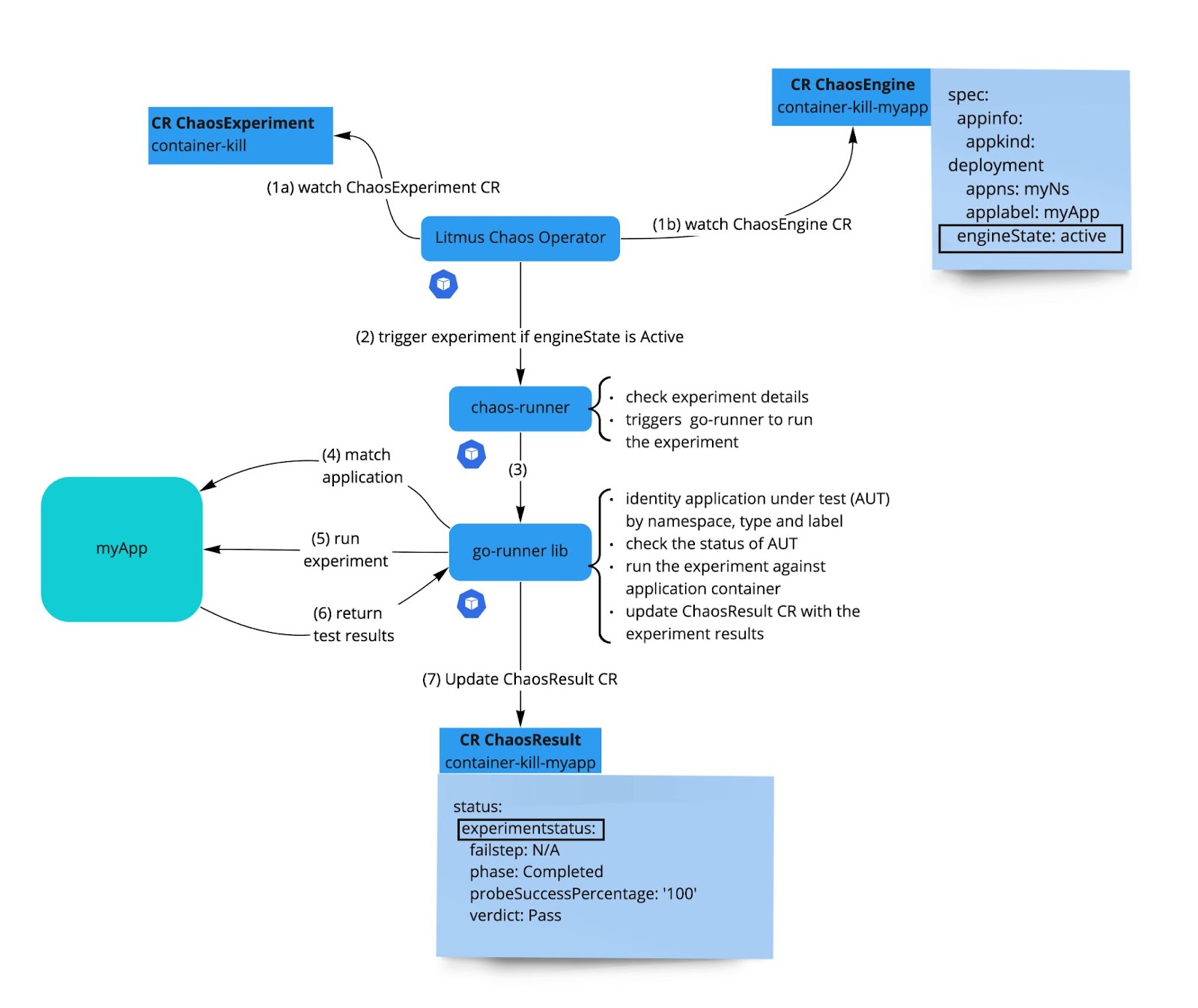
Complex scenarios
For the more complex experiments (for example, those that need to be run at the host level, like the container-kill or network experiments that will be presented later), an additional helper pod will be required.

Low-level details of few experiments
Let’s dig into the low-level details of a few popular experiments: container-kill, network Chaos experiments, and pod cpu/memory hog.
Container-kill
One of the common resilience tests for applications is to test how it behaves after it is being forcely killed, for example, when an application receives a SIGKILL. This resilience test is pretty useful as it can simulate scenarios when containers belonging to a pod may crash for various reasons (example: issues with the Container Runtime).
However, if the application is resilient, once it is restarted, it should resume its functionality smoothly.
The container-kill experiment from LitmusChaos has the ability to test this scenario by implementing the interaction with the Container Runtime (CRI-O in case of OpenShift 4) at host level and stopping the container forcefully. The command executed is the following:
crictl stop <container-id> --timeout=0
The scenario is simulated at host level because it cannot be done at Kubernetes level when the main application runs with PID 1.
Please consider the following security implications when running this experiment:
- This experiment requires elevated privileges as it needs to mount the host CRI-O socket to execute crictl commands against the containers.
- This container also needs to run privileged to execute this command (various capabilities are required).
The elevated privileges required are already defined in the SecurityContextConstraint presented above in the Security Considerations section. So to run this experiment, this SCC needs to be assigned to the respective Service Account running the pods running the Chaos testing scenarios.
One can find more details about this experiment in the official LitmusChaos documentation.
Network “Chaos” scenarios
Other common resilience test scenarios for applications are related to simulating network issues. These tests are also very useful as they can simulate network latency, network packet corruption, or loss.
LitmusChaos uses Linux Traffic Control and the netem queuing discipline on the host level to simulate network latency, loss, corruption or duplication.
To achieve this, Litmus will create a helper container with elevated privileges which will execute on the host level commands like below:
/bin/bash -c nsenter -t 12312 -n tc qdisc add dev eth0 root netem delay 2000ms
The previous command is used to introduce a network delay of 2000ms on the network egress scheduler of the eth0 network device. The helper container will execute this command by entering the network namespace (-n flag) of the target application identified by its PID (-t 12312).
The concept is the similar for emulating the other network Chaos scenarios. The only difference is the parameters netem parameters. For more details about netem, check its documentation: https://wiki.linuxfoundation.org/networking/netem.
Security consideration: these experiments require elevated privileges for running its helper container with NET_ADMIN and SYS_ADMIN capabilities as well as hostPID and privileged container permissions.
The same SCC that has been presented earlier in the blog can be assigned to the service account that runs the Chaos pods.
Details about pod network experiments can be found in the official documentation.
Experiments: Pod memory and CPU hog
These experiments are emulating high memory and CPU consumption on the pod level. This can be helpful to test and simulate how an application behaves under high memory, respectively high CPU usage.
These experiments can be run in two ways:
- using ChaosHub pod-memory-hog and pod-cpu-hog experiments that are relying on Linux CGroups and Litmus nsutil CLI for execution. However, they are available for Pumba Engine only, and Pumba supports only Docker runtime, so these are not an option for OpenShift 4.
- using ChaosHub pod-memory-hog-exec and pod-cpu-hog-exec experiments which are executing various shell commands in the container to emulate high-memory, respectively high-CPU usage.
So for the purpose of our demonstration, we will use the latter option. However, notice the following if using these “exec” experiments:
- the application under test must have a shell available
- after the execution, Litmus uses a so-called CHAOS_KILL_COMMAND, defined by an environment variable with the same name to kill the process that triggers the Chaos. By default this command is: kill $(find /proc -name exe -lname '*/dd' 2>&1 | grep -v 'Permission denied' | awk -F/ '{print $(NF-1)}' | head -n 1). However, many minimal container images do not have ps installed, and if that is the case for your application, under test the kill command will fail and the experiment will fail as well. There are two possibilities: If the image have ps installed, then it is all good, but if not, you will need to override the CHAOS_KILL_COMMAND in the pod-memory-hog-exec/pod-cpu-hog-exec ChaosEngine (part of the Workflow) with a command that will be able to kill the process that triggered the Chaos.
Memory Hog
To emulate memory consumption, the go-runner pod will execute the following command into the container application that is being tested:
dd if=/dev/zero of=/dev/null bs=<memory-consumption-in-Mb>M
The size of the memory consumption is configurable in the ChaosEngine custom resource. Details about the Pod Memory Hog experiment can be found in the official documentation.
CPU Hog
To emulate CPU consumption, the following command will be executed in the container running the application under test:
md5sum /dev/zero
The command itself is a configurable parameter in the ChaosEngine custom resource. The number of CPUs to be stressed by this experiment can be also configured.
More details about the Pod CPU Hog experiment can be found in the official documentation.
These two experiments do not require elevated privileges to be executed.
Running resilience tests
Deploying the application under test (AUT)
First, let’s deploy a test application against which the experiments will be run. Litmus calls this application Application Under Test, or AUT. We will be using a basic hello-openshift application:
oc create deployment hello-openshift --image=quay.io/rd09/python-hello-openshift
Create a Litmus workflow in ChaosCenter Dashboard
The Workflow Custom Resource is used by Litmus ChaosCenter Dashboard to orchestrate different chaos experiments. It encapsulates the ChaosEngines and ChaosExperiments together.
We will add three of the experiments mentioned above in the Workflow that will target the previously deployed application:
- Container-kill
- Network-latency
- Pod-memory-hog
Because the first two experiments require elevated privileges to run the test scenarios (see Security Considerations section from above), we will need to assign the custom Litmus SecurityContextConstraint to the service account that runs the experiments - litmus-admin.
The steps to perform this operation are described here: https://github.com/radudd/litmus-chaos-openshift/. Adjust the manifests and apply them.
oc apply -f manifests
Now, let’s walk through a basic setup containing three experiments executed against a single pod.
To create a Workflow, go to the Litmus Workflow section in ChaosCenter Dashboard and click on Schedule a workflow.
First, choose the Self-Agent corresponding to the cluster where LitmusChaos is installed:
Then choose Create a new workflow using the experiments from ChaosHub and leave LitmusChaosHub selected. The LitmusChaosHub contains already the experiments mentioned above that we would like to test:
At the next step. you should choose a name for your Litmus workflow:

Now it is time to add the experiments. Click on Add new experiment and add generic/container-kill, generic/network-latency and generic/pod-memory-hog-exec:
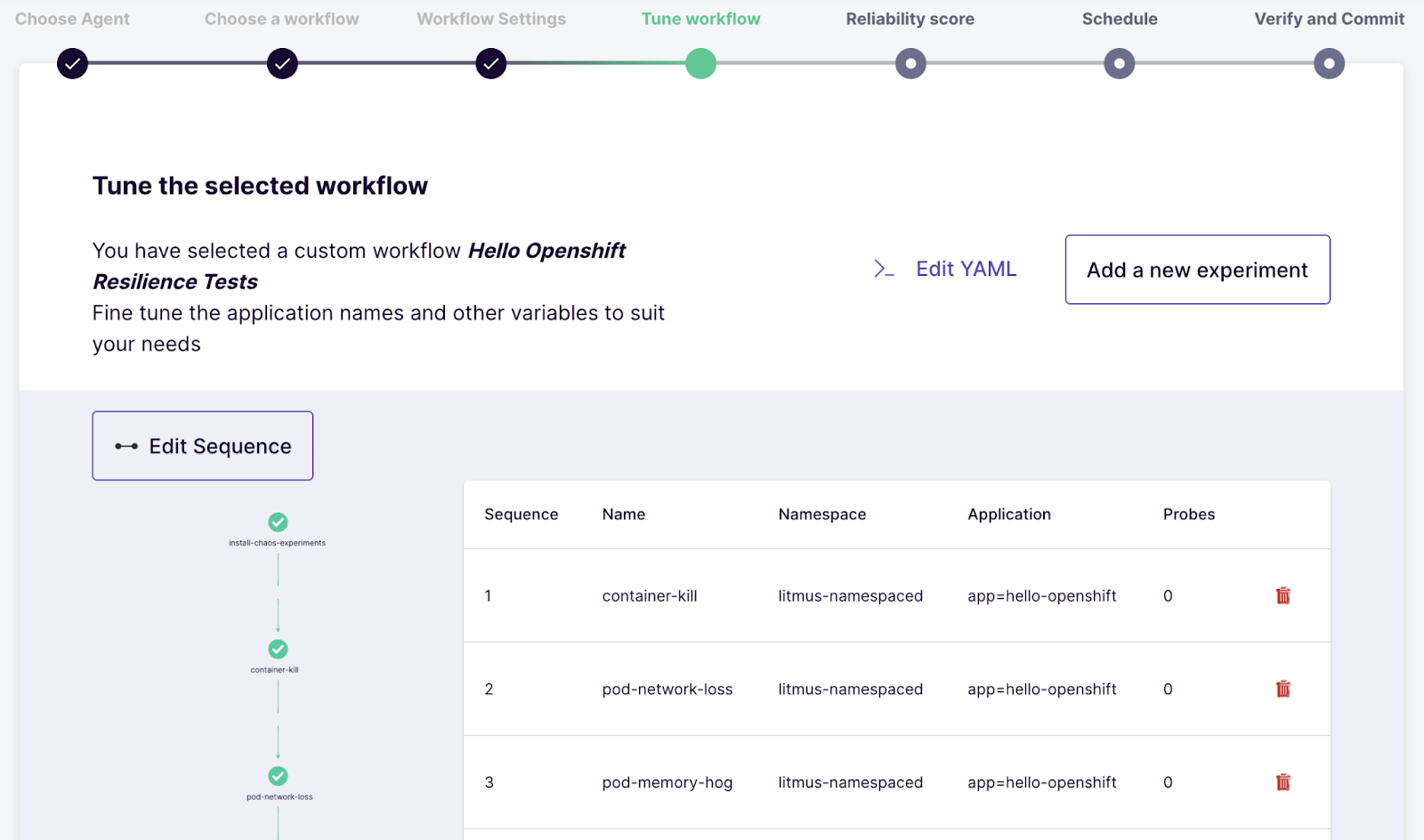
We now need to update the configuration for each of the experiments in the following way:
- change the application namespace - appns and label - applabel under Target Application to match the application we are testing against:
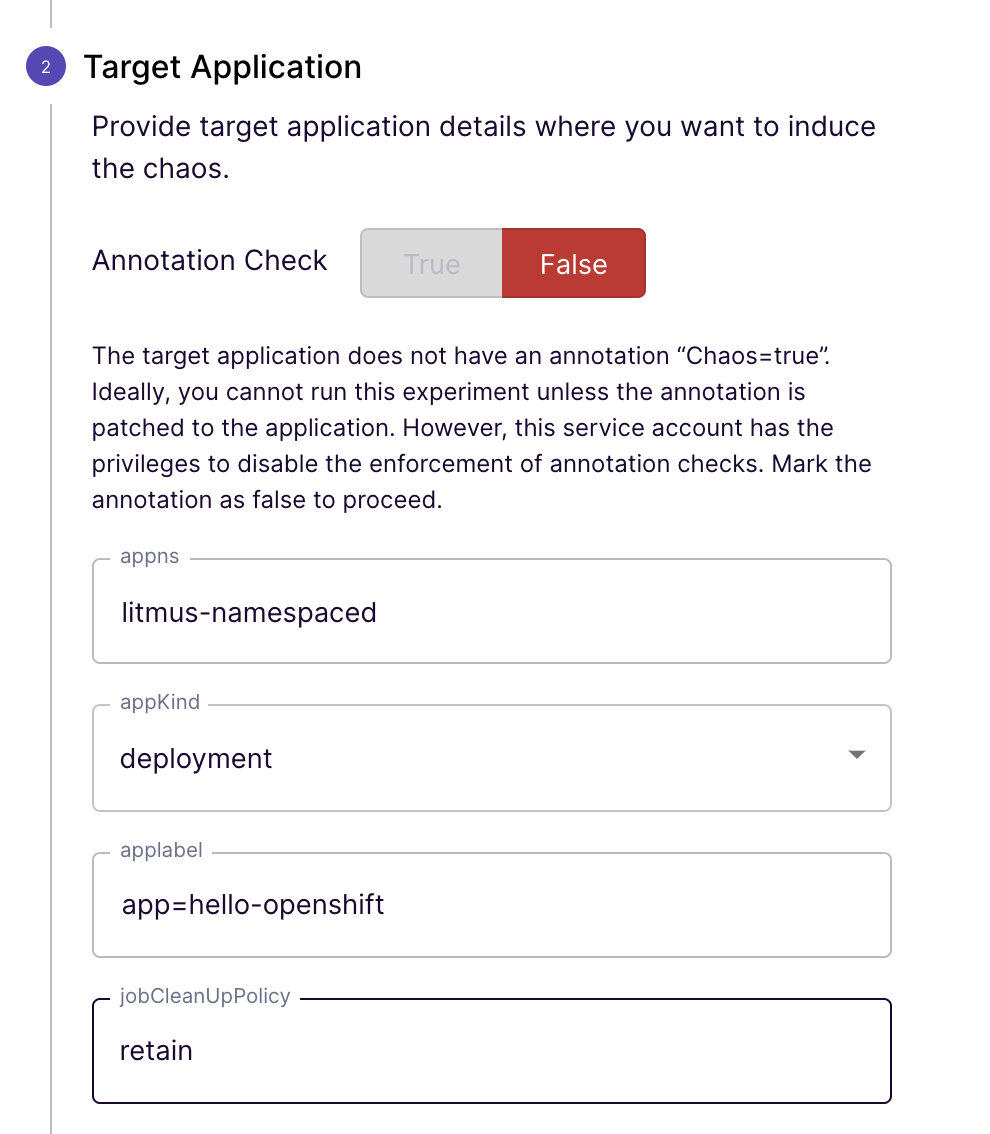
- change the Container Runtime to crio and Socket Path to /var/run/crio/crio.sock under Tune Experiment to match the OpenShift 4 container runtime:

The Workflow custom resource generated by the UI hardcodes by default a security context that requires UID 1000 to run the experiment pods. But for security reasons, OpenShift will not allow this without adding some extra privileges to the service account via SCC. However, to make the experiment pods run conform to the OpenShift secure way by using randomly generated UID, remove the securityContext section from the Workflow CR.
This can be done by editing the Workflow YAML in the UI:
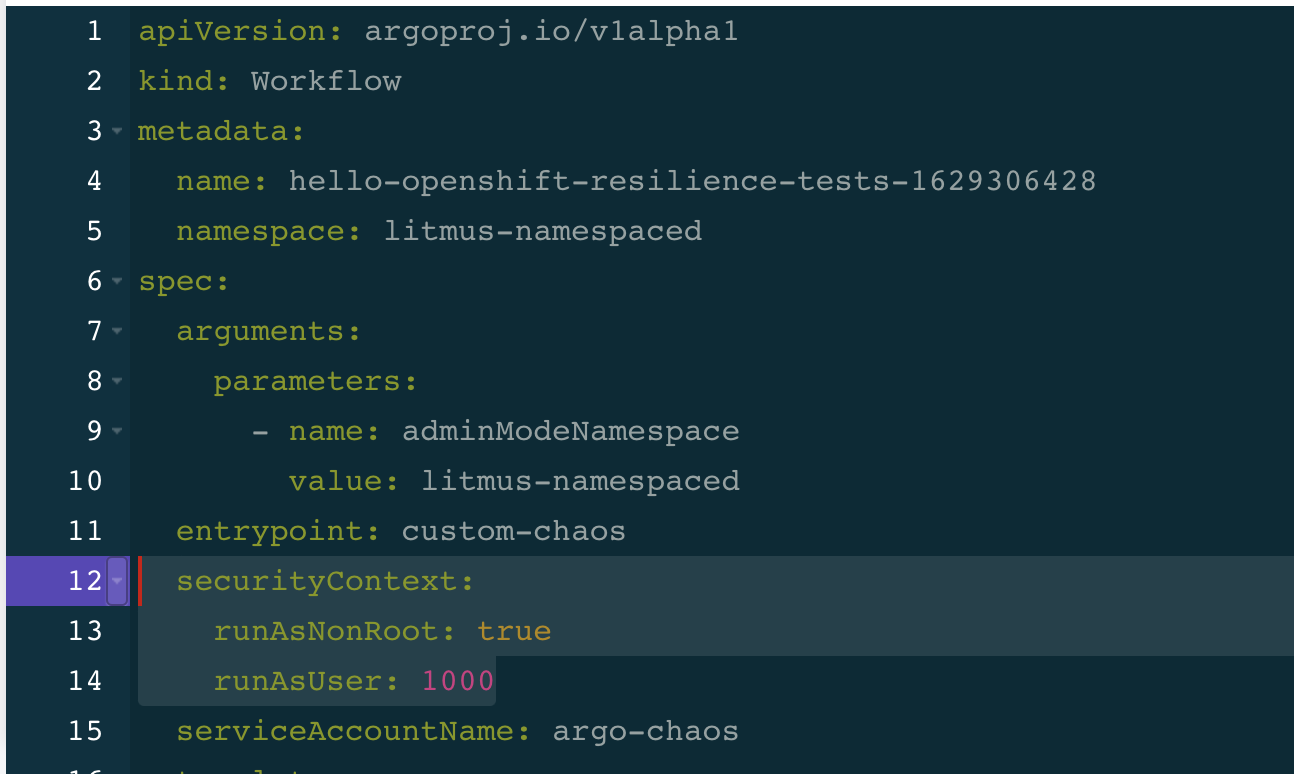
Next, click on Save and proceed with the setup until the end without updating anything else.
NOTE: For our demonstration, we will schedule the experiments now. However, the Workflow can be run on a recurring schedule. Feel free to update according to your needs.
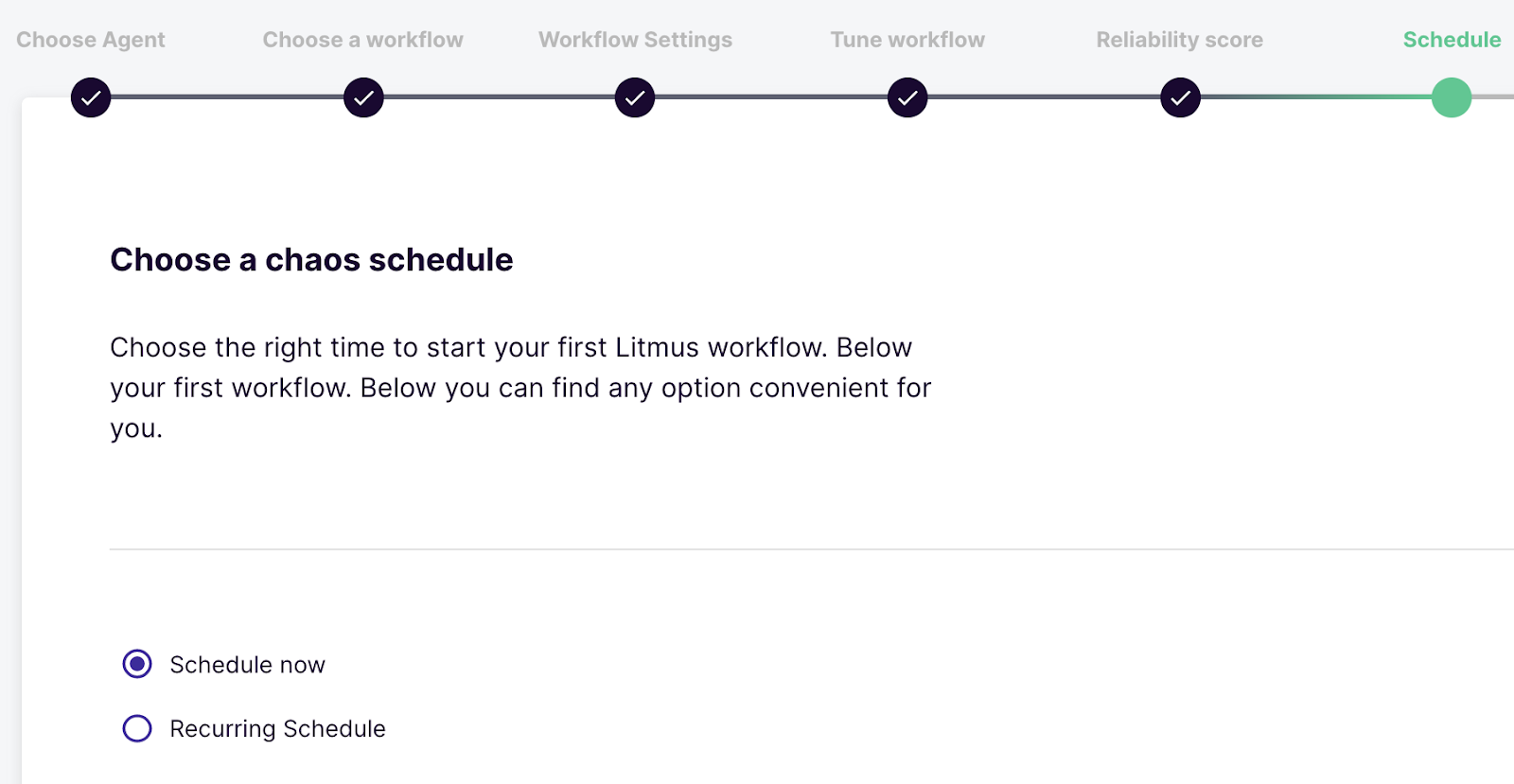
If you schedule the Workflow now, the execution will start. Before any actual experiment is run, Litmus Operator will first install the ChaosExperiments Custom Resources required by the Workflow into the OpenShift cluster. This is indicated by the install-chaos-experiments step.
Then the experiments will start executing in sequential order.
One can observe the execution and the logs of the experiments directly in the ChaosCenter console however, one can also look in the OpenShift terminal or console to the pods running the Chaos experiments for a more detailed view:
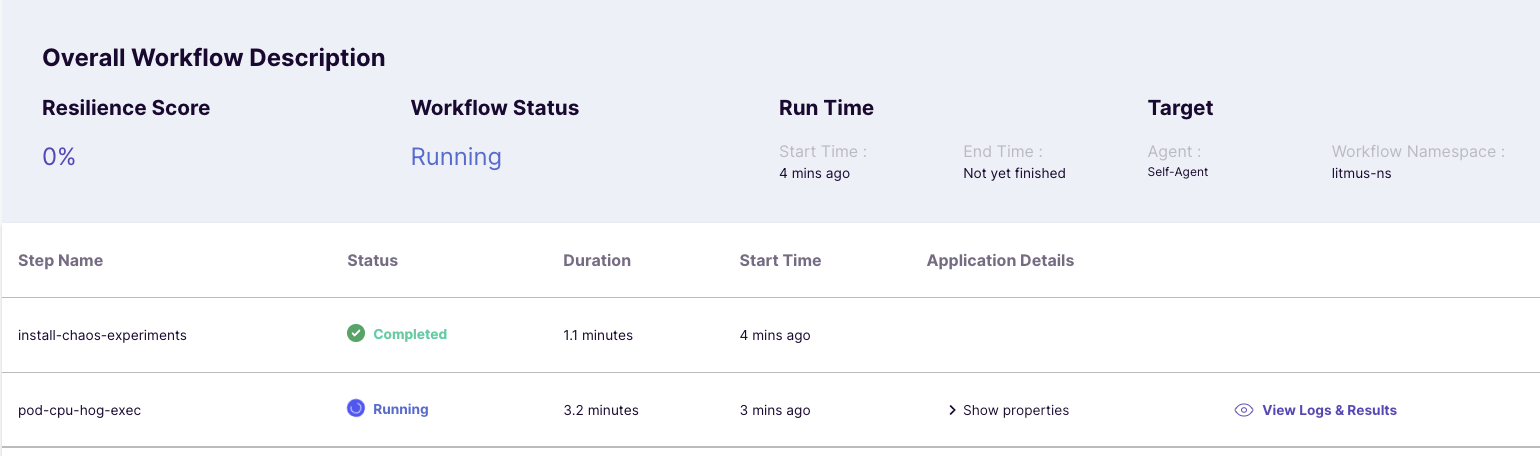
That's it. Now wait for the completion of the experiments and then check the results.
Extra details about Chaos CRDs: ChaosExperiments, ChaosEngines, and ChaosResults
We have seen above how we can execute experiments using Workflows. However, the Workflow Custom Resource leverages on two other CRDs: ChaosExperiments and ChaosEngines
Let’s see how they work on a low level. We will exemplify this using the container-kill experiment.
ChaosExperiments are blueprints for executing specific experiments, and they are installed automatically by the Workflow at the second step. In the previous LitmusChaos, one needed to manually install ChaosExperiments based on the experiments that will be executed. So we assume in this scenario that the ChaosExperiment for container-kill is installed.
The ChaosEngine CRD is used to customize the ChaosExperiment and to target specific pods or nodes against which experiments will be executed. Let’s look at the configuration of a ChaosEngine resource running container-kill experiment and targeting the hello-openshift application:
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: testapp-container-kill
namespace: litmus
spec:
annotationCheck: 'false'
jobCleanUpPolicy: 'delete'
appinfo: # (1)
appkind: deployment
applabel: deployment=testapp
appns: litmus
chaosServiceAccount: litmus-privileged # (2)
components:
runner:
image: 'litmuschaos/chaos-runner:1.13.2'
engineState: stop
experiments:
- name: container-kill
spec:
components:
env:
- name: CHAOS_INTERVAL # (3)
value: '10'
- name: TOTAL_CHAOS_DURATION # (4)
value: '20'
- name: CONTAINER_RUNTIME # (5)
value: crio
- name: SOCKET_PATH # (6)
value: /var/run/crio/crio.sock
The important configuration parts are:
- spec.appinfo - used to identify the application under test.
- spec.chaosServiceAccount - the service account used to run the experiments. For those that require elevated privileges, use a service account with the required permissions
- spec.experiments.[].spec.components.env CHAOS_INTERVAL - every time this interval is hit (measured in seconds), Litmus will check if the application is in ready status, and if so, the experiment will complete successfully. Otherwise, the helper which effectively runs the experiment will continue to run and will eventually be killed by its controlling pod (lib pod) after the maximum duration of running is hit: CHAOS_INTERVAL + TOTAL_CHAOS_INTERVAL+ 60 seconds
- spec.experiments.[].spec.components.env TOTAL_CHAOS_INTERVAL - total time in seconds to run the experiments
- spec.experiments.[].spec.components.env CONTAINER_RUNTIME: for OpenShift 4, it must be crio
- spec.experiments.[].spec.components.env SOCKET_PATH: for OpenShift 4, it must be /var/run/crio/crio.sock
IMPORTANT: CHAOS_INTERVAL >= startup time of the application
IMPORTANT: TOTAL_CHAOS_INTERVAL == CHAOS_INTERVAL if the experiment needs to be executed once. If the experiment must run multiple times, then TOTAL_CHAOS_INTERVAL should be a multiple of CHAOS_INTERVAL
To start an experiment, the spec.engineState of the ChaosEngine needs to be active.
Once the experiment starts, it will create a new chaos-runner container, in this example called test-app-runner. The experiment will be executed through a Kubernetes Job called container-kill-<uuid>. As we mentioned before, some of the experiments will require an extra helper pod that will execute the experiment effectively at the host level, for example, in this case, crictl stop <container> --timeout=0
The log of the helper container indicates the experiment was completed.
W0412 12:42:16.899526 1 client_config.go:541] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
time="2021-04-12T12:42:16Z" level=info msg="[PreReq]: Getting the ENV variables"
time="2021-04-12T12:42:17Z" level=info msg="container ID of app container under test: 7eefe34b024e9f9dc0ab8ca83725bf0469bd70e7d8e30f48fc43bb850695c973"
time="2021-04-12T12:42:17Z" level=info msg="[Info]: Details of application under chaos injection" ContainerName=testapp PodName=testapp-69d468b7f5-ksmr7 RestartCountBefore=0
time="2021-04-12T12:42:18Z" level=info msg="[Wait]: Wait for the chaos interval 10s"
time="2021-04-12T12:42:28Z" level=info msg="The running status of container are as follows" Pod=testapp-69d468b7f5-ksmr7 Status=Running container=testapp
time="2021-04-12T12:42:28Z" level=info msg="restartCount of target container after chaos injection: 1"
time="2021-04-12T12:42:28Z" level=info msg="container ID of app container under test: 26e90bd41faf7192f2c451704aa6d5236040db87ee5c5af58f6d4ef372a4c572"
time="2021-04-12T12:42:28Z" level=info msg="[Info]: Details of application under chaos injection" ContainerName=testapp PodName=testapp-69d468b7f5-ksmr7 RestartCountBefore=1
time="2021-04-12T12:42:28Z" level=info msg="[Wait]: Wait for the chaos interval 10s"
time="2021-04-12T12:42:44Z" level=info msg="The running status of container are as follows" Pod=testapp-69d468b7f5-ksmr7 Status=Running container=testapp
time="2021-04-12T12:42:44Z" level=info msg="restartCount of target container after chaos injection: 2"
time="2021-04-12T12:42:44Z" level=info msg="[Completion]: container-kill chaos has been completed"
Now checking the events of the testapp, one can notice that the container was crash-looped and then the Kubernetes controller restarted it:
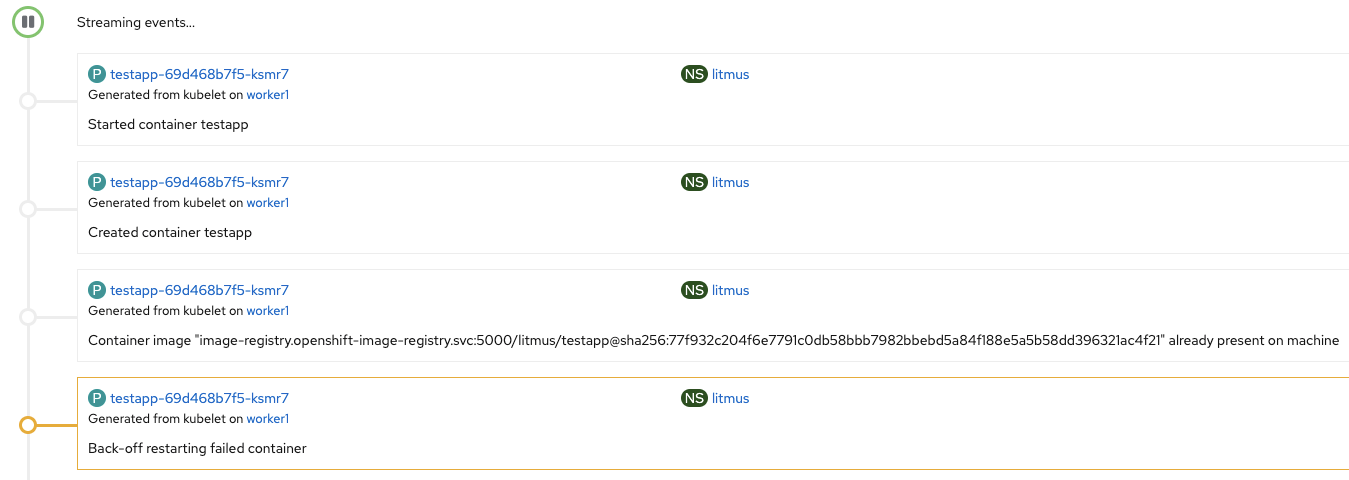
After the experiment completes, a custom resource of type ChaosResult will be created or updated (in case the experiment was run before). Let’s inspect it:
oc get chaosresult -o yaml testapp-container-kill-container-kill
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosResult
metadata:
name: testapp-container-kill-container-kill
namespace: litmus
spec:
engine: testapp-container-kill
experiment: container-kill
status:
experimentstatus:
failStep: N/A
phase: Completed
probeSuccessPercentage: "100"
verdict: Pass
history:
passedRuns: 1
As it can be observed, the experiment was successful, as verdict is Pass, while probeSuccessPercentage is 100.
Conclusion
In this blog, I provided an introduction to LitmusChaos architecture and described the tool's capabilities. I focused on the namespaced installation, as this was more suited for self-service scenarios which fit better the use-cases I had so far. However, depending on your organization, the cluster mode might be better for your needs. For example, if there is an operations team that will manage the configuration and execution of resilience tests across all applications.
I have also presented and showcased in detail how few common LitmusChaos scenarios like container-kill, pod-memory-hog-exec and pod-network-latency are working under the hood. However, LitmusChaos provides many more scenarios in the ChaosHub.
There are other exciting concepts in LitmusChaos, like GitOps and Litmus Observability. Stay tuned for the follow-up blog posts.
Addendum
Starting with version 2.0, the chaos scenarios pod-cpu-hog and pod-memory-hog (the non exec ones, which rely on Linux CGroups and Litmus nsutil CLI), as well as pod-io-stress support now also Litmus Engine (besides Pumba). Therefore, these experiments can be used with CRIO container runtime, hence they can run against OpenShift 4 workloads.
However, contrary to the pod-cpu-hog-exec and pod-memory-hog-exec, they do require elevated privileges just like the container-kill and the network chaos scenarios.
Details can be found in the experiments documentation: Pod CPU Hog, Pod Memory Hog, Pod IO Stress.
About the author

Passionate about Cloud-Native technologies and data integration, Radu possesses deep experience with Kubernetes, Red Hat OpenShift and Kafka. He is actively expanding this skill set into Generative AI to architect and deploy intelligent, forward-looking applications
More like this
AI in telco – the catalyst for scaling digital business
Introducing OpenShift Service Mesh 3.2 with Istio’s ambient mode
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds