First things first: “Open box” and “closed box” monitoring might not be familiar terms for everyone, but here at Red Hat, we are trying to be as respectful and inclusive with our language as possible. I decided to use those terms as opposed to “black box monitoring” and “white box monitoring.”
In this blog post, we are going to talk about closed box monitoring and how OpenShift Dedicated’s SREs are using it to complement our observability stack.
Before we dive into the details, let’s take a look at what this blog post is going to contain.
We are going to:
- Define closed box monitoring.
- Compare closed box and open box monitoring.
- Demonstrate the automation of closed box probes for a fleet of OpenShift clusters.
Since there is a whole lot to talk about, let’s get started.
What Is Closed Box Monitoring?
If you attempt to search for “closed box monitoring,” you will get a variety of results depending on the environment the corresponding authors are in. The entries range from security explanations to monitoring unmanaged switches. That usually either means that it is only loosely defined or that it is universally applicable. We can safely say the latter applies in this case.
Closed box monitoring originates from an environment where you would not have a lot of insights available about a certain service or device, hence the articles about switches. In our case, closed box monitoring refers to a way of monitoring systems from the outside (for example, via artificial probes) without leveraging any additional insights into the service except the probe results.
Sound complicated? The next section about closed box versus open box monitoring.
Closed Box Versus Open Box Monitoring
In the last section, we learned what closed box monitoring is, so let’s look at open box monitoring before we compare the two.
Think about an example service. We will take this little example:
package main |
Don’t worry if you don’t understand the Go programming language. You are looking at a simple implementation of an echo server.
What’s special about it, however, is that it also exposes Prometheus-style metrics on “/metrics”.
It is not hard at all to instrument an application, but that should probably be a blog post on its own.
Now when we curl the “/metrics” endpoint, we are getting a bunch of metrics, and thereby information about our service. We use that information for monitoring that application. This is open box monitoring. We can extend the set of metrics further by instrumenting our application better. We just refrained from doing so for the simplicity of the application; however, the Prometheus Golang client library provides insights about the service. Below, you can see the metrics we get for this application out of the box with the Prometheus Golang client library:
go_gc_duration_seconds{quantile="0"} 0
|
I know what you’re thinking: “That’s not monitoring a lot about the application’s functionality. True, but this service is also not doing a lot. With a more complicated service, one should instrument it more to retrieve custom metrics about what the service does and how it performs.
We have full insights into the service, making it an “open box” for us. If all you can do is view the service from the outside, that’s what we call “closed box” monitoring. To help understand the differences between the two, you can take a look at the diagram below. In this example, we assume that all metrics are collected in a central Prometheus instance. That does not have to be the case, however
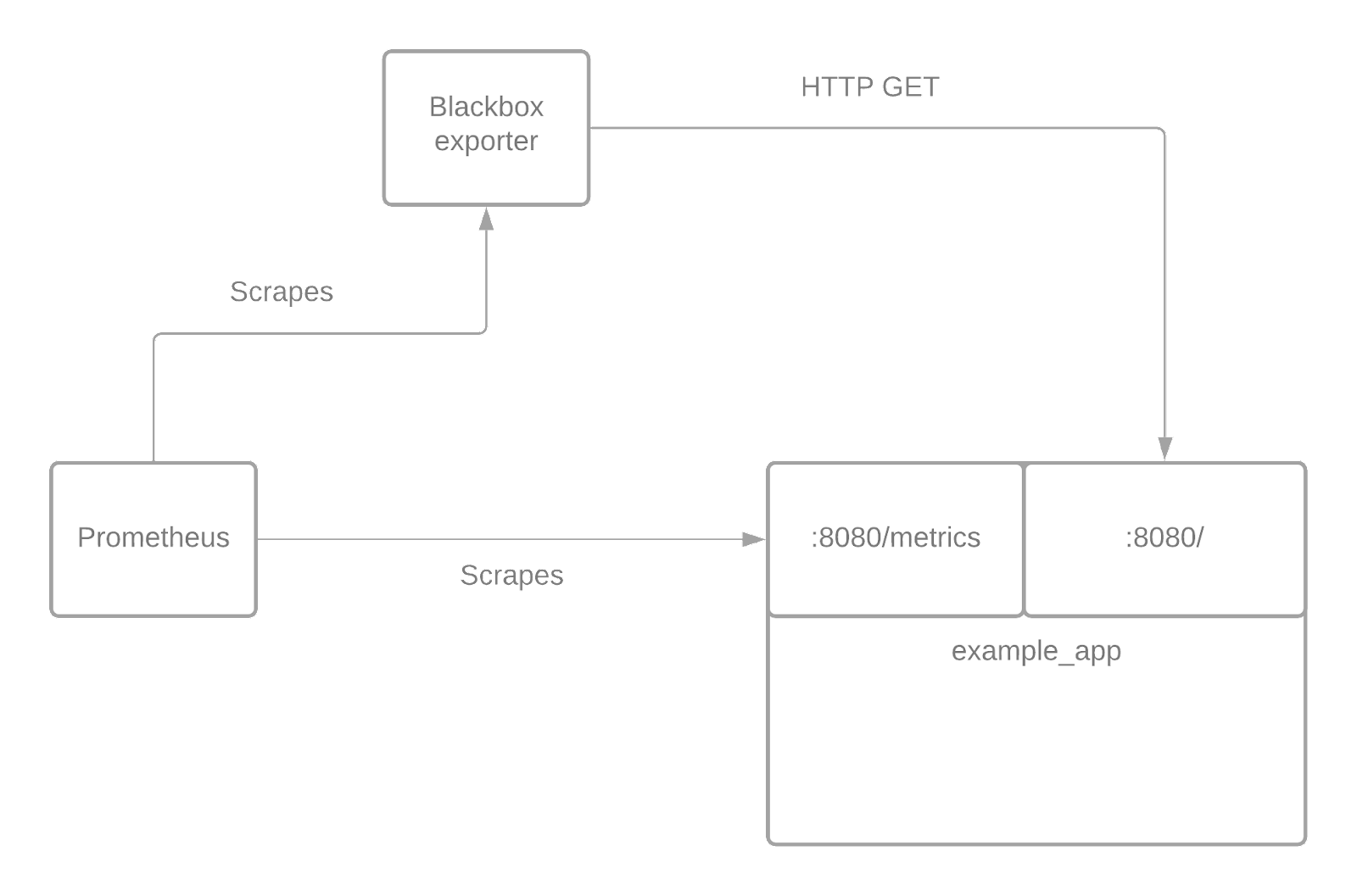
Open box and closed box monitoring are not mutually exclusive but rather complement each other. Neither one can fully replace the other and you shouldn’t attempt that.
Overall, open box monitoring gives a rich insight into the application or service you are monitoring. This is potentially great, but since that data is usually very specific to the functionality the application serves, it requires deep app knowledge to use those metrics correctly. Sometimes it requires reading code to understand what certain metrics give, so in extreme cases, only core developers can make meaningful sense out of it.
On the other hand, closed box monitoring merely adds a subset of data points about your application as perceived from an outside perspective. And you would be surprised how much information you can get! You can probe your service to measure availability. You can verify security aspects by periodically trying to authenticate unprivileged users, check TLS, and certification expiration. You can even program periodic checks with crafted requests that expect a certain response.
Closed box monitoring helps to check those things by being closer to the user experience, which helps a great deal in understanding your users and how they experience your service or application. On top of that, it allows having consistent availability, security, and functional data for heterogeneous services that might be written by different teams and in different languages.
You will learn in our next section how we automated closed box probes for a fleet of OpenShift clusters.
Automated Closed Box Probes for a Fleet of OpenShift Clusters
Closed box probes are a great way to complement existing open box monitoring systems and solutions, and deploying them is not all that hard. One of the most prominent open source solutions for this is the Blackbox exporter. The Blackbox exporter is part of the Prometheus ecosystem and as such is well maintained and well supported by a great community. You just deploy the Blackbox exporter, adjust your Prometheus configuration, and off you go, probes coming.
Now the challenges start:
- We managed a whole fleet OpenShift clusters so we cannot “just deploy.”
- OpenShift comes out of the box with Cluster Monitoring Operator installed to monitor core OpenShift components. For simplicity, let’s assume that it is kube Prometheus on steroids. What that means is that we don’t ever touch the Prometheus config by hand.
So what do we do? We are going to write an operator to solve those challenges.
Luckily, one of our team members has recently published an article on how to quickly bootstrap an operator using Operator SDK, which we could use as a starting point.
So after some time and a decent amount of work put into it by our team, we now have the Route Monitor Operator.
The Route Monitor Operator is pretty much a one-stop shop for getting closed box probes for routes on OpenShift clusters, allowing us to easily get uniform closed box probes on all our clusters.
The operator is deployed to all our clusters and does its magic from there.
You can read all about it in the readme file in the repository, so I will refrain from duplicating that here.
Now that we have those closed box probes ready, what do we actually do with them?
Alerting is a tricky thing. You do not want to miss actual problems, but you also don’t want to drown in alerts that you cannot take action on. It is all about finding the right balance.
Our scenario is admittedly special in terms of the number of clusters and how we handle them, so our way here may not apply to everyone. However, I still wanted to give a quick insight into how we do it so you can have a starting point for your own alerting and monitoring.
We have decided to probe a couple of routes that we care about, which exist on all clusters out of the box, such as the OpenShift Web Console.
For those components, we have SLOs ready, which is nice because we don’t have to think about them now and instead can get right to work and start using multi-window, multi-burn-rate alerts.
You can read more about that in the SRE Workbook, Chapter 5.
While we know that it is not 100% true since our probes don’t make 100% of the traffic and don’t cover all the time, we used our existing SLOs for our alerts on closed box probes as well.
The reason is simple: We want to see how it goes.
Everything we do is subject to constant evolution and improvements, so we just start like this and then frequently review how things are going and make adjustments as needed.
The Future
There will be changes coming to the Route Monitor Operator soon.
Since the latest Prometheus Operator release, it supports synthetic probes out of the box.
That’s great since we can simplify the Route Monitor Operator to deploy “Probes” instead of “ServiceMonitors” as soon as it is officially supported as part of Cluster Monitoring Operator.
Overall closed box monitoring has already filled a small but important gap in our observability picture as a whole, and we are excited for what’s to come with even better integrations with OpenShift.
About the author

More like this
The agentic paradox and the case for hybrid AI
Context-aware advisor recommendations in Red Hat Lightspeed
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds