Picture this: you have a powerful language model in production, but it struggles to provide satisfying answers for specific, niche questions. You try retrieval-augmented generation (RAG) and carefully crafted prompt engineering, but the responses still need to be revised. The next step might seem to be full model fine tuning—updating every layer of the model to handle your specialized cases—but that demands significant time and compute resources.
What is LoRA?
Low-rank adaptation (LoRA) is a faster and less resource-intensive fine tuning technique that can shape how a large language model responds to a request by model adaptation. Model adaptation helps refine and optimize a general-purpose model to better handle specialized requirements without running a full fine tuning process. LoRA doesn’t modify the parameters of the base model but instead it adds additional parameters during the tuning process. This collection of newly trained parameters is known as an adapter. These adapters can be merged into the model or in our case written to a separate file which is loaded at runtime. Multiple adapters can be created off a base model by using different training data sets.
For example, if your model needs to answer questions on technical topics, like advanced electronics or legal terms, LoRA adapters can train it to adapt its responses to these topics without changing the entire model. This allows the model to deliver nuanced, topic-specific answers efficiently, making it easier to meet unique demands across diverse use cases. Please note that using LoRA techniques only refines the model, it doesn’t add new knowledge to the model.
By combining technologies such as vLLM, LoRA adapters and semantic routing, we can provide contextually appropriate responses for queries without having to serve independent models.
While LoRA has limitations, much like RAG, it’s important to emphasize both can work together.
High level architecture
In the following architecture, we combine large language models (LLMs), LoRA adapters, the semantic router framework and the vLLM model serving runtime, all hosted on Red Hat OpenShift AI, to build a cost-efficient, scalable and user-friendly deployment for specialized AI solutions.
LoRA allows for efficient, task-specific tuning of a model without the costs of performing a full fine tuning of the LLM, while the semantic router intelligently directs requests to the relevant LoRA adapter or base model—seamlessly and without end-user awareness. The flow looks like this:
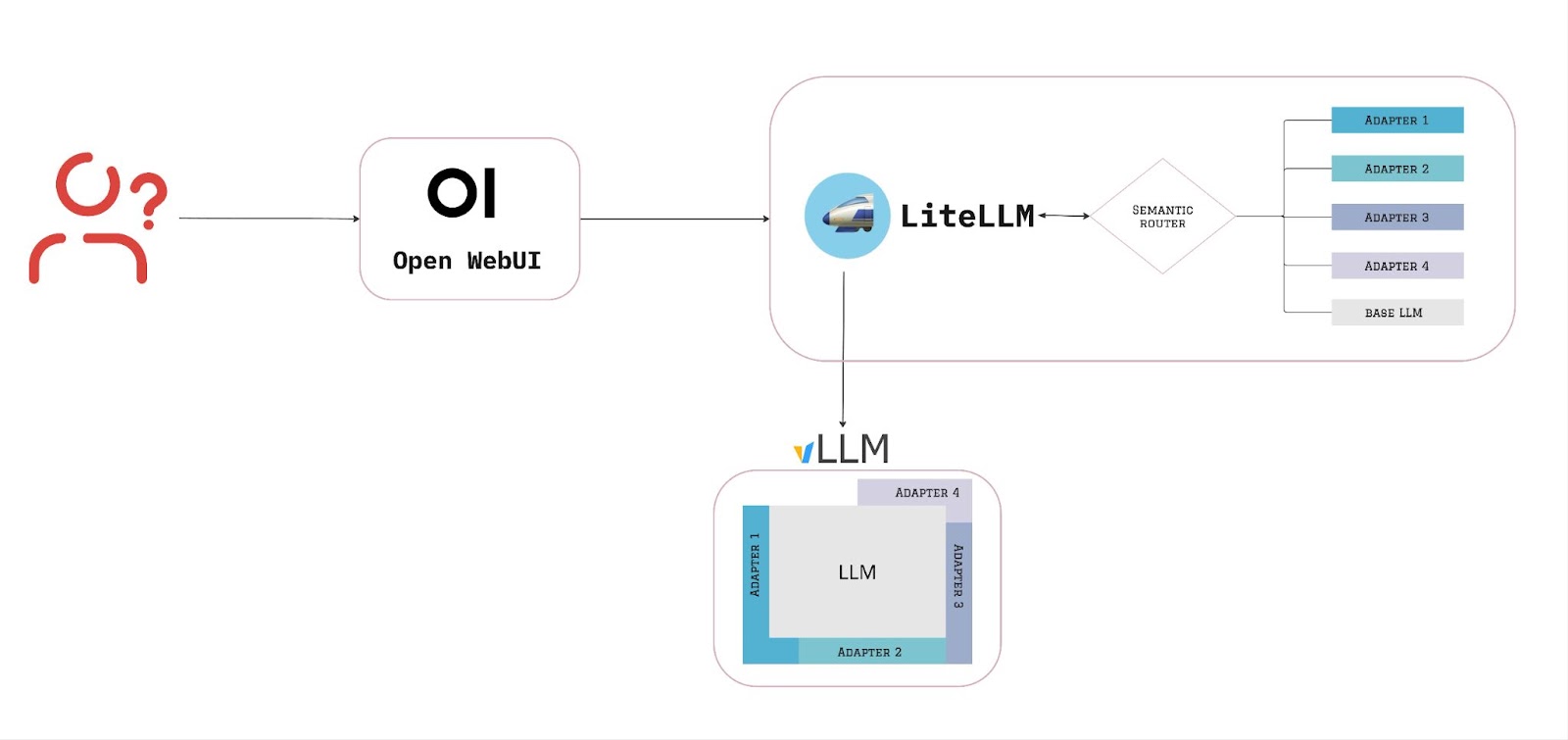
User request flow: UI -> LiteLLM + semantic router -> vLLM with LoRA adapters
The architecture integrates several components to ensure efficient request handling and accurate responses. Open WebUI provides an intuitive interface for users to interact smoothly with the system, and LiteLLM, which acts as a proxy, utilizes the semantic router to determine which is the most suitable destination—whether it’s the base model or a specialized LoRA adapter. Based on this decision, LiteLLM forwards the request to vLLM for inference.
What this architecture brings to your AI strategy
Here’s why this architecture is worth considering:
Cost efficiency
- Reduced training costs: LoRA reduces the number of parameters that are updated during training. Instead of updating all weights, it uses low-rank matrices, making fine tuning faster and less resource-intensive.
- Use of existing models: LoRA adapters can be served by the same serving runtime hosting the base model. This eliminates the need for additional serving resources.
Better end user experience
- Seamless interaction: The semantic router manages routing behind the scenes, analyzing queries and directing them to the most relevant LoRA adapter or the base model, ensuring a smooth user experience.
Ease of maintainability
- Dynamic adapter management: The semantic router provides modularity, while vLLM enables independent management of each LoRA adapter. New adapters can be added without disrupting existing ones and updates to the router configuration can be made independently.
- Integration with vLLM + Red Hat OpenShift AI: Red Hat OpenShift AI provides an integrated MLOps platform for building, training, deploying, and monitoring AI-enabled applications, predictive and foundation models at scale across hybrid cloud environments. With recent support for efficient fine-tuning using LoRA, having this architecture on OpenShift AI simplifies the deployment and management of LoRA adapters. New adapters can be tested and deployed with minimal disruption, enabling continuous improvement. Additionally, OpenShift AI’s observability tools allow teams to monitor model performance effectively, ensuring high service availability and reliability for end users.
- Everything as code & GitOps: With Red Hat OpenShift AI, all configurations are treated as code, allowing every change to be versioned, traceable, and auditable within a GitOps repository. The GitOps approach ensures updates to LoRA adapters and router configurations are consistently managed and easily repeatable.
From architecture to deployment
Let’s dive into the technical aspects of building this setup with a practical example. We are using the Phi-2 LLM as the base model, and two LoRA adapters Phi2-Doctor28e and phi-2-dcot.
This repository packages all the required components as a helm chart, which helps you deploy with one command.
$ git clonse https://github.com/noelo/vllm-router-demo
$ cd vllm-router-demo/chart
$ helm install vllm-router-demo . --set cluster_domain=<apps.clusterxyz.com> --namespace <your-namespace> --create-namespaceLet’s go through the configuration step by step:
Step 1: Running the base LLM and adapters with vLLM on Red Hat OpenShift AI
First, we must make the model and the adapters available for the runtime vLLM. We are using KServe's ModelCars feature to fetch and serve the models and adapters using an open container initiative (OCI) image. The approach allows models to be pre-packaged into a container image for easy deployment and scaling.
To build the Modelcar, we use a Containerfile. It downloads the models under the /models folder. After building the image, you’ll reference it in the InferenceService config.
If you wish to use different models and adapters, update the Containerfile with your desired models and build a custom ModelCar. In this case, make sure to adjust the vLLM runtime configuration to reference your new base model and adapters.
Step 2: Using LiteLLM to translate inputs into embeddings and use semantic router to route user queries
LiteLLM handles request routing to the correct model destination using the semantic router framework, which translates inputs into embeddings and determines the most suitable destination to handle the request based on the semantic similarity of the query to the configured examples.
The details to determine the route destinations can be found here.
Step 3: User interface setup
We use Open WebUI as our user interface. It sends the user inputs to LiteLLM and allows users to interact with either the base model or the most suitable adapter for their needs.
Step 4: Test and verify
After deployment, verify that the setup works as expected by logging into Open WebUI and sending various queries. By checking the LiteLLM logs, you can ensure that requests are correctly routed to either the base model or the relevant adapter.
For instance, in a clinical healthcare scenario, if you ask, “Is there medication for my symptoms?” the query will be routed to the phi-2-doctor adapter. You can then verify the routing by checking the LiteLLM logs, as shown below.
Please keep in mind that while the model may provide useful information, all output should be reviewed for its suitability and it is essential to consult a professional for personalized advice.
Fetching 5 files: 0%| | 0/5 [00:00<?, ?it/s]Fetching 5 files: 20%|██ | 1/5 [00:00<00:00, 8.19it/s]Fetching 5 files: 40%|████ | 2/5 [00:01<00:02, 1.07it/s]Fetching 5 files: 100%|██████████| 5/5 [00:01<00:00, 3.09it/s]
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:4000 (Press CTRL+C to quit)
LiteLLM: Proxy initialized with Config, Set models:
dcot
doctor
phi2
INFO: 10.131.2.121:60084 - "GET /models HTTP/1.1" 200 OK
INFO: 10.131.2.121:42460 - "GET /models HTTP/1.1" 200 OK
INFO: 10.131.2.121:50078 - "POST /chat/completions HTTP/1.1" 200 OK
INFO: 10.131.2.121:50690 - "GET /models HTTP/1.1" 200 OK
[RouteChoice(name='doctor', function_call=None, similarity_score=0.8541370430665768), RouteChoice(name='dcot', function_call=None, similarity_score=0.7889643558705519)]
doctor
INFO: 10.131.2.121:52628 - "POST /chat/completions HTTP/1.1" 200 OKImproving the solution
While LoRA adapters bring significant benefits, their effectiveness depends heavily on the pre-trained model's existing knowledge base. Adapters may struggle with tasks that require substantial shifts in model behavior or domain knowledge. Poorly tuned adapters run the risk of model collapse where the adapter “forgets” the knowledge that the base model was trained on.
To address this, we would leverage Red Hat Enterprise Linux AI for full fine tuning. It is a foundation model platform to consistently develop, test, and run Granite family large language models (LLMs) to power enterprise applications. It can help build a more tailored and robust base model specific to your organization’s needs, enhancing overall performance across tasks.
Combining LoRA adapters with a semantic router offers a flexible, cost effective and scalable solution for utilizing specialized AI models. This architecture allows end users to interact seamlessly with an intelligent system without explicitly serving multiple different models. With Red Hat OpenShift AI, the solution becomes even more manageable, making it easier to maintain and scale over time.
To read more about Red Hat OpenShift AI and Red Hat's KubeCon NA 2024 news, visit the Red Hat KubeCon newsroom.
About the authors

An expert in Red Hat technologies with a proven track record of delivering value quickly, creating customer success stories, and achieving tangible outcomes. Experienced in building high-performing teams across sectors such as finance, automotive, and public services, and currently helping organizations build machine learning platforms that accelerate the model lifecycle and support smart application development. A firm believer in the innovative power of Open Source, driven by a passion for creating customer-focused solutions.

Noel O'Connor is a Senior Principal Architect in Red Hat's EMEA Solutions Practice specializing in cloud-native application and integration architectures. Since 2008, he has worked with many of Red Hat's global enterprise customers in both EMEA and Asia. He's co-authored a number of books, including "DevOps with OpenShift" and "DevOps Culture and Practice with OpenShift."
More like this
Manage MCP servers on Red Hat OpenShift with the MCP lifecycle operator
4 reasons to start using image mode for Red Hat Enterprise Linux right now
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds