Overview
Introduction
When talking about modern workloads deployed on platforms like OpenShift, at some point we inevitably will need to discuss autoscaling. Why? Workloads should be able to flexibly react to increased or decreased load to prevent any outages, latency issues or expensive and wasteful resource management.
There are two steps to achieve this elasticity: Application autoscaling and Cluster autoscaling. If we focus on the Application autoscaling part, on OpenShift we can use the Vertical Pod Autoscaler to scale pods vertically (change the resource allocation for a pod) or we can use the Horizontal Pod Autoscaler to scale pods horizontally (change the number of pods). These components can scale workloads based on resource utilization metrics, ie. CPU and memory usage.
Unfortunately, scaling based only on CPU and Memory consumption might not always be the best fit for our use case, especially in workloads that leverage event driven architecture. Maybe we would like to scale our applications based on events or metrics happening in some external system. We then need to take into account indirect metrics that don't reflect the actual CPU or memory consumption. For example, imagine an application that consumes messages from some queue-based system that needs to scale out the application based on the number of unprocessed messages in the queue. How can we achieve this?
The Custom Metrics Autoscaler
I am happy to share that with the release of OpenShift 4.11 the new Custom Metrics Autoscaler operator is available as a technology preview. It enables horizontal autoscaling not limited to CPU and memory metrics, and also enables scaling to zero, something that can’t be accomplished with a standard Horizontal Pod Autoscaler.
The Custom Metrics Autoscaler operator is based on the upstream project KEDA. KEDA is an incubating CNCF project, and Red Hat is one of its co-founders, and is an active contributor.
The main goal of this autoscaler is to enable autoscaling based on events and custom metrics in a user friendly way. It acts as a thin layer on top of the existing Horizontal Pod Autoscaler, it provides it with external metrics and also manages scaling down to zero.
The Custom Metrics Autoscaler consists of two main components:
- Operator - activates and deactivates scalable workloads (Deployments, Stateful Sets,...) by scaling them from and to zero replicas. Operator also manages Custom Resources such as Scaled Objects that define the metadata needed for scaling.
- Metrics Server - acts as an adapter to OpenShift API server and provides external metrics to Horizontal Pod Autoscaler Controller which drives autoscaling under the hood.
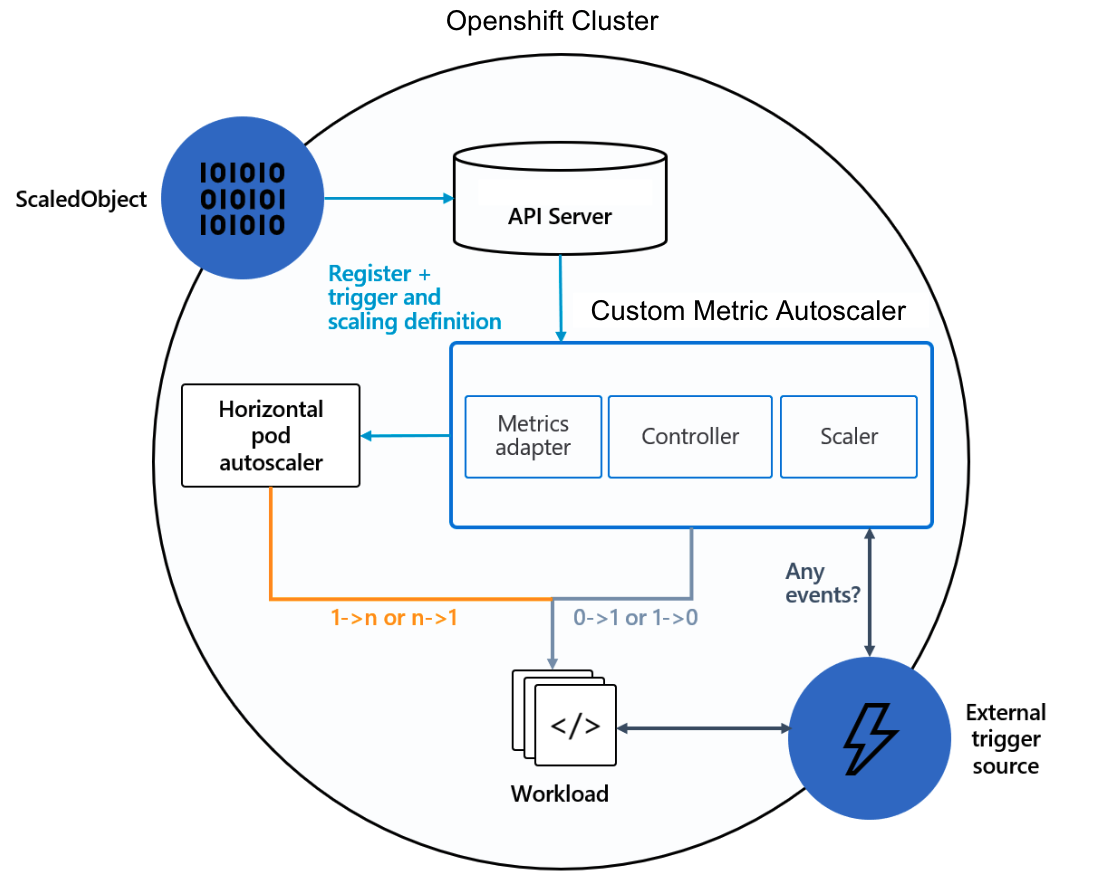
How to define autoscaling
We use a Custom Resources named Scaled Object to define autoscaling of Deployments, StatefulSets or any Custom Resources that are scalable (ie. define /scale subresource). In case we need to process long running tasks, we define a Custom Resource named ScaledJob, which the autoscaler uses to create Kubernetes Jobs based on the custom metrics.
Let’s take a look at the example of a ScaledObject (ScaledJob is very similar):
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: my-scaledobject
spec:
scaleTargetRef:
name: my-workload
minReplicaCount: 0
maxReplicaCount: 100
triggers:
- type: prometheus
metadata:
serverAddress: http://<prometheus-host>:9090
metricName: my-metric
query: <my-query>
threshold: ‘20’
authenticationRef:
name: trigger-auth-prometheus
In the spec section, there are 3 important parts:
scaleTargetRefpoints to the workload that we would like to scale (in this case a Deployment namedmy-workload)minReplicaCountandmaxReplicaCountwhere we define the scaling boundstriggerssection, which consist of:typemeans that we we would like to read metrics from Prometheusmetadatawhich tells us where should we get the metrics, query and what is the threshold for scalingauthenticationRefis an optional field with points to namespaced resourceTriggerAuthenticationor cluster wide resourceClusterTriggerAuthenticationwhich holds reference to Secrets or Vaults which store authentication information.
Just this ScaledObject together with optional TriggerAuthentication resource is needed to enable autoscaling based on metrics from Prometheus of a workload defined in Deployment my-workload.
Please note that only the Prometheus trigger is supported in the initial release of the Custom Metrics Autoscaler operator on OpenShift. More coming soon!
Installation
It’s fairly easy to install the Custom Metrics Autoscaler operator on OpenShift 4.11, we just need to locate the operator in OperatorHub and install it to openshift-keda namespace.
Please note that if you have an installation of a KEDA Community operator on the same cluster, you need to uninstall this community operator first.
To complete the installation we need to create CustomResource KedaController in openshift-keda namespace, see the following image.
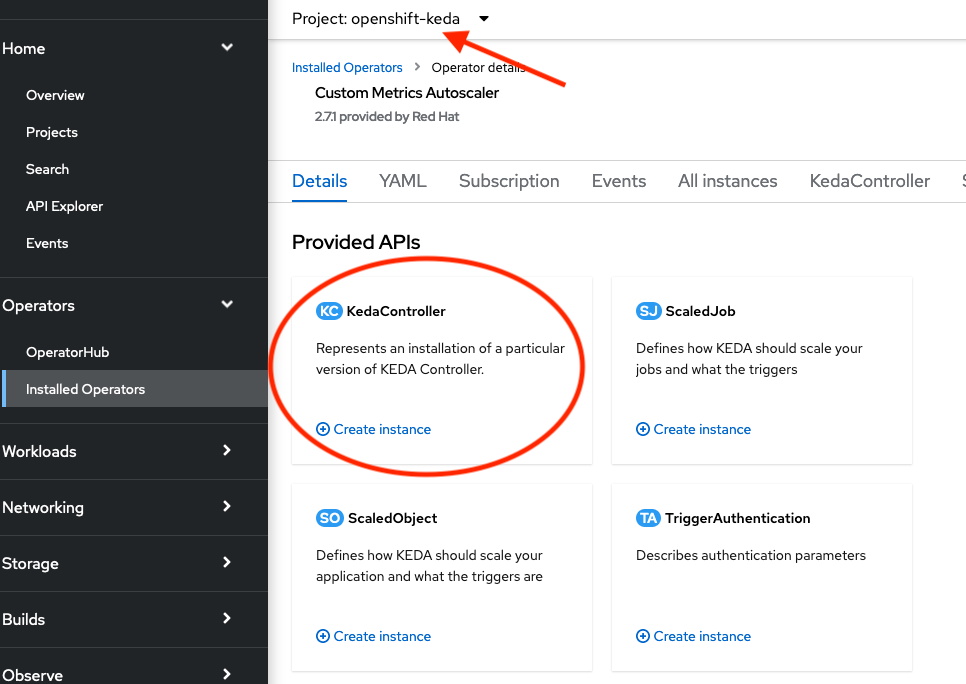
We can keep the logging levels for both Operator and Metrics Server or we can keep the defaults. We just need to use the correct namespace and correct resource name:

After a couple of seconds the installation should be completed, we can verify the installation by checking pods in openshift-keda namespace, there should be 3 ready Deployments:
$ oc get deployment -n openshift-keda
NAME READY UP-TO-DATE AVAILABLE AGE
custom-metrics-autoscaler-operator 1/1 1 1 3m11s
keda-metrics-apiserver 1/1 1 1 4m36s
keda-operator 1/1 1 1 4m36s
Guide on autoscaling based on metrics from Red Hat OpenShift Monitoring
The following guide describes how an application can be autoscaled by the Custom Metrics Autoscaler on Openshift. The application is being scaled based on the incoming HTTP requests collected by OpenShift Monitoring. If there isn't any traffic the application is autoscaled to 1 replicas, if there's some load the number of replicas is being scaled up to 10 replicas.
Autoscaling to 0 replicas can't work for this type of application, because metrics (incoming requests) are collected directly from the application instance. So if there isn't an application deployed, the Custom Metrics Autoscaler doesn't have any way to collect metrics. If you need more flexible HTTP requests based autoscaling you should check Knative Serving autoscaler which is part of OpenShift Serverless.
Prometheus scaler is being used for this setup, because Red Hat OpenShift Monitoring exposes Prometheus metrics through Thanos.
Source code of this example application can be found on GitHub.
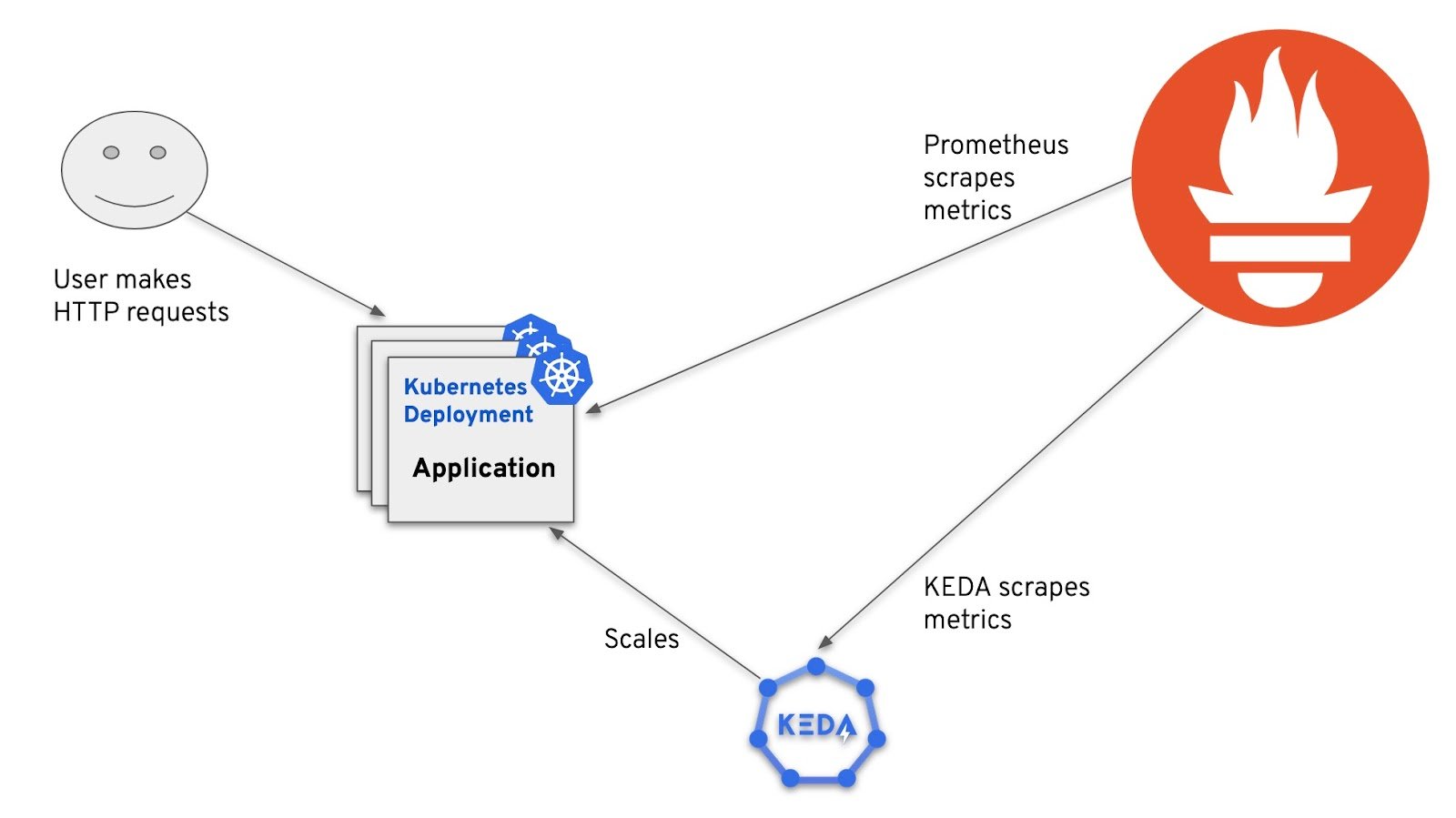
Architecture
Following diagram describes the architecture of our solution. Our application is deployed as Kubernetes Deployment and it exposes Prometheus metrics about incoming HTTP requests. These metrics are collected by Red Hat OpenShift Monitoring. We use KEDA, which is part of the Custom Metrics Autoscaler, to fetch metrics from OpenShift Monitoring and scale our application based on that.
Prerequisites
- The Custom Metrics Autoscaler operator is install
- We need to enable Red Hat OpenShift Monitoring for user-defined projects.In the documentation we can see that we need to create following Config Map:
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
enableUserWorkload: true
Deploy application that exposes Prometheus metrics
Now we can deploy our application, it is a very simple Go application that server HTTP traffic and exposes Prometheus metrics, see the snippet below.
var httpRequestsTotal = prometheus.NewCounter(
prometheus.CounterOpts{
Name: "http_requests_total",
Help: "Total number of http requests.",
},
)
func handler(w http.ResponseWriter, r *http.Request) {
httpRequestsTotal.Inc()
msg := "Received a request"
fmt.Fprint(w, msg)
fmt.Println(msg)
}
func main() {
port := "8080"
prometheus.MustRegister(httpRequestsTotal)
http.HandleFunc("/", handler)
http.Handle("/metrics", promhttp.Handler())
log.Printf("Server started on port %v", port)
log.Fatal(http.ListenAndServe(fmt.Sprintf(":%v", port), nil))
}
Let’s containerize this application and deploy it as a Kubernetes Deployment.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: test-app
name: test-app
spec:
replicas: 1
selector:
matchLabels:
app: test-app
template:
metadata:
labels:
app: test-app
type: keda-testing
spec:
…
We need to also create Kubernetes Service and ServiceMonitor resource to expose metrics, see the snippet of the ServiceMonitor:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
name: keda-testing-sm
spec:
endpoints:
- scheme: http
port: http
namespaceSelector: {}
selector:
matchLabels:
app: test-app
Let’s create a namespace demo, deploy all resources and check that our application is up and running:
$ oc logs deployment.apps/test-app
2022/07/30 16:31:59 Server started on port 8080
Configure authentication to Red Hat OpenShift Monitoring
Red Hat OpenShift Monitoring exposes Prometheus metrics through Thanos. Because it is not generally a good idea to expose all metrics to everyone, Thanos requires authentication to scrape metrics from a particular namespace. Our application is deployed to the namespace demo, so we need to instruct Thanos to allow the Custom Metrics Autoscaler to scrape metrics from this namespace.
First we need a Service Account to authenticate with Thanos instance, we can reuse existing or create a new one, let’s create a new Service Account named thanos:
$ oc create serviceaccount thanos
serviceaccount/thanos created
let’s locate a token assigned to the thanos Service Account:
$ oc describe serviceaccount thanos
Name: thanos
Namespace: demo
Labels: <none>
Annotations: <none>
Image pull secrets: thanos-dockercfg-kmqds
Mountable secrets: thanos-dockercfg-kmqds
Tokens: thanos-token-6tnt6
Events: <none>
As we mentioned earlier, we can use TriggerAuthentication custom resource to refer credentials, secrets or any sensitive information in ScaledObject. Let’s create a new TriggerAuthentication resource with a reference to the token thanos-token-6tnt6 mentioned in the previous step:
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-trigger-auth-prometheus
spec:
secretTargetRef:
- parameter: bearerToken
name: thanos-token-6tnt6
key: token
- parameter: ca
name: thanos-token-6tnt6
key: ca.crt
Now we need to instruct Red Hat OpenShift Monitoring to allow reading metrics in the namespace demo for the Service Account thanos . We shall create a role that will permit that:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: thanos-metrics-reader
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
Once we create this role, we need to bind it to the Service Account thanos, if everything is configured correctly, you should see similar output:
$ oc adm policy add-role-to-user thanos-metrics-reader -z thanos --role-namespace=demo
role.rbac.authorization.k8s.io/thanos-metrics-reader added: "thanos"
At this point we have a deployment of an application that exposes Prometheus metrics. The Custom Metrics Autoscaler has a reference to credentials to authenticate with Thanos to scrape those metrics. One thing is missing though, autoscaling of this application!
Deploy ScaledObject to enable application autoscaling
Enabling autoscaling for our application is very easy, we just need to create a ScaledObject that will reference our application, Red Hat OpenShift Monitoring instance and will have the correct credentials. Let’s see the following ScaledObject named prometheus-scaledobject:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
spec:
scaleTargetRef:
name: test-app
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9092
namespace: demo
authModes: "bearer"
metricName: http_requests_total
threshold: '5'
query: sum(rate(http_requests_total{job="test-app"}[2m]))
authenticationRef:
name: trigger-auth-prometheus
We have defined that we would like to scale Deployment named test-app, if we would like to target another resource, we can specify optional apiVersion and kind properties under scaleTargetRef.
We have specified that we would like to scale out our application between 1 and 10 replicas and we would like to do that based on metrics returned by query specified in the prometheus trigger in metadata.query. This query returns a number of HTTP requests to our application in the last 2 minutes. The threshold value used for scaling is 5, ie. 5 requests per replica.
The last part is authentication, we have selected bearer authentication mode and added a reference to the TriggerAuthentication resource trigger-auth-prometheus created in previous steps.
Once we deploy the ScaledObject defined above, we can check that it is deployed correctly. The correctness is reflected in ScaledObject status, in a property Ready:
$ oc get scaledobject prometheus-scaledobject -o 'jsonpath={..status.conditions[?(@.type=="Ready")].status}'
True
We are all set! Now we can generate some load to see autoscaling in action. To generate the load we can use a very convenient tool called hey, which is a very easy to use HTTP load generator. I have containerized this tool, so I can deploy a Kuberentes Job to actually create the load, see the snippet below:
apiVersion: batch/v1
kind: Job
metadata:
generateName: generate-requests-
spec:
template:
spec:
containers:
- image: quay.io/zroubalik/hey
name: test
command: ["/bin/sh"]
args: ["-c", "for i in $(seq 1 30);do echo $i;/hey -c 5 -n 100 http://test-app.demo.svc;sleep 1;done"]
…
So let’s create the job to generate the load:
$ oc create -f load.yaml
job.batch/generate-requests-m49gm created
We should see an increased number of replicas of the application until all sent requests are processed. And the application will be again autoscaled to one replica. You can check the changing number of replicas by running the following command:
$ watch oc get deployment.apps/test-app
The output should be similar:
Every 2,0s: oc get deployment.apps/test-app
NAME READY UP-TO-DATE AVAILABLE AGE
test-app 10/10 10 10 3m17s
After some time the application should be autoscaled back to 1:
Every 2,0s: oc get deployment.apps/test-app
NAME READY UP-TO-DATE AVAILABLE AGE
test-app 1/1 10 10 3m17s
Autoscaling in action!
Conclusion
With the Custom Metrics Autoscaler coming in OpenShift 4.11 we have new ways how we can autoscale workloads. We have the flexibility to leverage different type of metrics and can really change the way how we can look on autoscaling as a whole.
This solution together with existing ones: Horizontal Pod Autoscaler, Vertical Pod Autoscaler and OpenShift Serverless gives us a full spectrum of tools to cover all our needs for application autoscaling.
This Autoscaler is released in Technical Preview, should you have any questions or feedback, please contact your Red Hat representative.
About the author

More like this
AI in telco – the catalyst for scaling digital business
Introducing OpenShift Service Mesh 3.2 with Istio’s ambient mode
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds