Introduction
Monitoring is an important aspect to understand and gain insight into your environment. Red Hat Advanced Cluster Management for Kubernetes (RHACM) is a great tool to get that visibility into all your clusters. By using the RHACM observability service, you can get critical metrics from all your clusters out-of-the-box without any additional effort.
When a cluster is imported in RHACM, also known as the hub cluster, and the observability service is enabled, RHACM deploys agents on the managed cluster that collects all the metrics and delivers it to the hub cluster. These metrics can be viewed in Grafana and you can create custom dashboards for it, or query it with an API.
In this blog, I explore the expansion of this use case to add custom metrics for third-party Infrastructure components, or even applications that expose these metrics. As well as how to enable these custom metrics that RHACM is not aware about and query it by using an API.
Prerequisites
You must have RHACM installed on your Red Hat OpenShift Container Platform 4 cluster and enable the observability service. Additionally, import one cluster into your hub cluster.
Enabling custom metrics in Red Hat Advanced Cluster Management
Grafana is a great tool to use to view metrics, and even build dashboards based on these metrics. Not everyone is familiar with the metrics available; this is where you can use the explore feature in Grafana to build your own Prometheus queries to be able to view the metrics.
After you log in to RHACM, launch the Grafana instance by clicking the Grafana link from the Clusters page. You are directed to the Grafana dashboard:

From the Grafana dashboard, use the explore feature to build your Prometheus queries. View the following image:

From the Explore tab and after the Metrics Browser, notice some of the queries that RHACM provides out-of-the-box. Let’s explore one that gives you the total sum of CPU cores available for a cluster. Enter the following query: cluster:cpu_cores:sum. Select cluster-1 from the cluster list, which is a cluster I imported into my RHACM cluster:
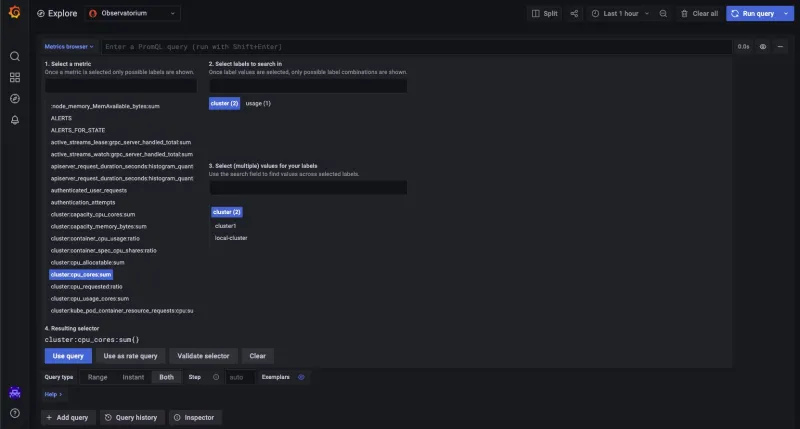
Once this cluster is selected, I can use the query to see the total number of cores in one of my managed/remote clusters. In the following image, notice that my remote cluster has a total of 60 cores:

These out-of-the-box queries are great, but sometimes there comes the need to use custom queries, which are not already available out-of-the-box.
RHACM has a list of allowable queries that can be found in a ConfigMap called observability-metrics-allowlist in the open-cluster-management-observability namespace.
By default, OpenShift Container Platform 4 adds in Prometheus and various exporters, which enable us to query these metrics. RHACM does not discover all of these by default. However, you can create a new ConfigMap with custom metrics to be discovered, let’s learn how.
OpenShift Container Platform 4 installs kube-state-metrics, an open source project that listens to the Kubernetes API server and generates metrics about the state of the objects. One of the metrics that it exposes is kube_pod_start_time, which returns the unix timestamp creation of a pod. Let’s try to find this metric in Grafana:

As displayed in the previous image, the metric is unavailable in Grafana. However, if I log in to my remote cluster and search for these metrics from the Observe tab, I see this metric is available. View the following screen capture:

To enable these metrics in RHACM and to display them in Grafana, a custom-allowlist needs to be created to discover these metrics. To do this you need to create a ConfigMap in the open-cluster-management-observability namespace called observability-metrics-custom-allowlist.yaml, and add in the kube_pod_start_time metric. Your ConfigMap might resemble the following image:

Once this is created, you can now discover the metric from the Grafana console and build a Prometheus query of it. You may need to refresh the Grafana web console:

Voila! You can now query any pod in any cluster managed by RHACM to get the pod creation timestamp. This is a unix epoch timestamp format that can be converted to a human-readable format.
Enabling third-party custom metrics in RHACM
Enabling metrics that are already available in the remote clusters is great, but what if you want to query metrics of a component that is not being monitored by default? Let’s say you have a deployed application that exposes certain metrics. By default, Prometheus of OpenShift Container Platform does not monitor this application. The best way to monitor this application is to enable the user-workload-monitoring service. However, at the time of writing this blog, RHACM version 2.6 and earlier do not pull metrics from any other Prometheus instances. It is best for the application to be monitored from the Prometheus platform.
I have a sample Go application that exposes HTTP metrics and counts the number of HTTP requests it has received. Apart from the application manifests, you need a service that monitors the metrics endpoint of the pods and a ServiceMonitor. The manifests for this application are available in my git repository here. To let your application be monitored by the Prometheus platform, you need to create the Role and RoleBinding, which defines that the prometheus-k8s service account in the openshift-monitoring namespace monitors your application metrics. Additionally, you need to deploy your service monitor in the openshift-monitoring namespace.
You can simply apply all the manifests available in the git repository. Now that the app is deployed, you can query the metric from the pod. View the following image:

From the Metrics page, notice that the Prometheus platform is now monitoring your namespace and scraping the metrics from the pods exposing these metrics. View the following screen capture:

As shown in the previous screen capture, the metrics are available on the local cluster. However, if the metrics are not allowed by RHACM in the observability-metrics-allowlist ConfigMap, you need to add the metrics in the custom-allowlist as described earlier. Once you have added the custom metric in the ConfigMap, the metrics are automatically shipped to RHACM. You should now see the metric in Grafana on the RHACM hub cluster, and be able to run Prometheus queries against it. View the following image:

Querying metrics using an API
There are now custom metrics of this test application and many other platform metrics. Let’s go over how you can query the metrics using an API. RHACM exposes a route that you can use to run Prometheus queries. This route also takes into account your RBAC access to RHACM. This route can be obtained by running the following command:
oc get route rbac-query-proxy -n open-cluster-management-observability
You need an authentication token to query against this route, which can be obtained from the CLI after you log in to the cluster as a cluster-admin. Run the following command:
oc whoami -t
You can also build the queries in Grafana Explorer, as mentioned earlier in this blog, and use the same query to pass to the proxy route URL. Use the following commands:
$ curl -H "Authorization: Bearer {TOKEN}" https://{PROXY_ROUTE_URL}/api/v1/query -d ‘query={QUERY_EXPRESSION}’
$ curl -H "Authorization: {TOKEN}" https://{PROXY_ROUTE_URL}/api/v1/query -d 'query=http_requests_total{namespace="my-namespace", pod="test-app-f6c687ff6-ph4zg"}'
{"status":"success","data":{"resultType":"vector","result":[{"metric":{"__name__":"http_requests_total","cluster":"cluster-1","clusterID":"8a12a38f-435d-4c87-8c67-b07a3b661605","endpoint":"http","instance":"10.128.2.36:8080","job":"test-app","namespace":"my-namespace","pod":"test-app-f6c687ff6-ph4zg","receive":"true","service":"test-app","tenant_id":"e4912c5f-5da3-4ecd-86c9-c94fed121394"},"value":[1664853315.762,"6"]}]}}
Specify the query more with jq filtering:
$ curl -H "{TOKEN}" https://{PROXY_ROUTE_URL}/api/v1/query -d 'query=http_requests_total{namespace="my-namespace", pod="test-app-f6c687ff6-ph4zg"}' | jq '.data.result[0].value[1]'
"6”
You can query this API to get more queries. Let's say you want to know when your pods started using the custom metric that was added earlier. Run the following command:
$ curl -H "{TOKEN}" https://{PROXY_ROUTE_URL}/api/v1/query -d 'query=kube_pod_start_time{cluster="cluster-1",namespace="my-namespace"}’
Another well known query is searching for the CPU consumption of pods over the last 15 minutes. Run the following command:
$ curl -H "{TOKEN}" https://{PROXY_ROUTE_URL}/api/v1/query -d 'query=sum(rate(container_cpu_usage_seconds_total{cluster="cluster-1",namespace="my-namespace",container!=""}[15m]))' | jq
{
"status": "success",
"data": {
"resultType": "vector",
"result": [
{
"metric": {},
"value": [
1664854512.906,
"0.00023315520027097773"
]
}
]
}
}
Summary
With this combination of building queries from Grafana and querying it with the API, it enables you to do complex queries and build custom queries. These queries can be powerful to get a lot of critical information about your clusters, as well as information from third-party components running on the clusters that are being managed by RHACM. The API used in this blog can also be called from a Jupyter notebook to allow a data scientist to run analytics on this data to uncover patterns and detect anomalies.
About the author

More like this
Looking ahead to 2026: Red Hat’s view across the hybrid cloud
Red Hat to acquire Chatterbox Labs: Frequently Asked Questions
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds