




In this article we will describe how Microsoft and Red Hat are collaborating in the open source community to show how Red Hat OpenShift can be deployed on Azure Confidential Computing for providing confidential container capabilities to its users. For this purpose, OpenShift uses the OpenShift sandboxed containers (OSC) feature in combination with multiple building blocks from the Confidential Containers project and Azure built-in tools to deliver a holistic solution.
The work described here is targeted to be presented in Kubecon EU April 2023 and will later be formally released as part of upcoming OpenShift deployment options on Azure cloud.
In the following sections we will explain what the Confidential Containers project is, go through multiple use cases demonstrating the value confidential containers provide, cover the different building blocks used for deploying it in Azure cloud and show how everything comes together.
If you are interested in getting more details about enabling OpenShift confidential containers in Azure, fill out the following form.
What is the Confidential Containers project?
This development work our team has done is based on integrating Confidential Containers (CoCo), a CNCF sandbox project enabling cloud-native confidential computing, by taking advantage of a variety of hardware platforms and technologies. Per Confidential Computing Consortium, confidential computing protects data in use by performing computation in a hardware-based, attested Trusted Execution Environment (TEE). These secure and isolated environments prevent unauthorized access or modification of applications and data while in use, thereby increasing the security assurances for organizations that manage sensitive and regulated data.
The goal of the CoCo project is to standardize confidential computing at the container level and simplify its consumption in Kubernetes. This enables Kubernetes users to deploy confidential container workloads using familiar workflows and tools without extensive knowledge of underlying confidential computing technologies.
Using CoCo, you are able to deploy your workload on infrastructure owned by someone else, which can significantly reduce the risk of an unauthorized entity accessing your workload data and extracting your secrets. The infrastructure we focus on in this blog is the Azure cloud. On the technical side, the confidentiality capabilities are achieved by encrypting the computer’s memory and protecting other low-level resources your workload requires at the hardware level. Azure offers confidential VMs with AMD SEV-SNP to protect data in use.
Confidential VMs on Azure provide a strong, hardware-enforced boundary to help meet your IT security needs. You can use confidential VMs for cloud migrations without making changes to your code, with the platform protecting your VM's state from being read or modified. Cryptography-based proofs (referred as remote attestation) help validate that no one has tampered with your workload, loaded software you did not want, read or modified the memory used by your workload, or injected a malicious CPU state to attempt to derail your initialized state. In short, CoCo helps confirm that your software runs without tampering, else it fails to run and you will know about it.
The CoCo threat model aims to protect the container environment and data generated/stored in the pod at runtime. It looks at a number of potential threats:
- The infrastructure provider tampers with container runtime environments data and code in memory.
- The infrastructure provider tampers with or reads the Kubernetes pod memory while in use.
- The infrastructure provider tampers with or reads data stored (ephemerally or not) by the Kubernetes pod.
The CoCo project is built on top of the Kata Containers project which runs pods inside VMs and provides two key capabilities:
- Isolating the host from pod workload meaning that the workload can’t attack the host.
- Isolating the pod workload from other pod workloads meaning that other workloads can’t attack your workloads.
As mentioned CoCo adds the third capability for a full isolation model:
- Isolating the pod workload and its data from the host.
For more information on the CoCo project we recommend reading What is the Confidential Containers project?
If you're interested in trying out the CoCo stack even without confidential computing hardware, such as AMD SEV-SNP or Intel TDX, we recommend reading How to use Confidential Containers without confidential hardware
What do we need for deploying confidential containers on the Azure public cloud?
A crash course on Kata Containers
Kata Containers is an open source project working to build a more secure container runtime with lightweight virtual machines (VMs) that are exposed as pods and that can run regular container workloads. This approach aims to provide stronger workload isolation using hardware virtualization technology.
OpenShift sandboxed containers, based on Kata Containers, provide an Open Container Initiative (OCI)-compliant container runtime using lightweight VMs running your workloads in their own isolated kernel. This contributes an additional layer of isolation to Red Hat’s defense-in-depth strategy.
The following diagram shows the major components involved in a Kata solution:
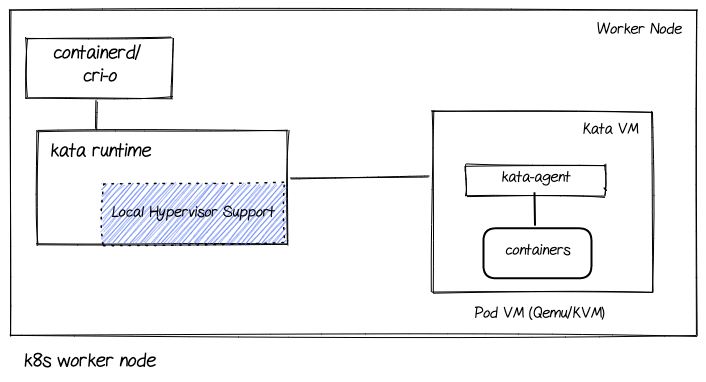
Let’s go over the main components used in the Kata Containers (and OpenShift sandboxed containers) solution.
- cri-o/containerd: cri-o implements the Kubelet Container Runtime Interface and provides an integration path between OCI runtimes and the Kubelet. cri-o (also marked as CRIO) is the default in OpenShift
- Kata runtime: This is the Kata containers runtime which spins up a VM for each Kubernetes pod, and dispatches containers to this virtual machine. The containers are therefore “sandboxed” inside the VM
- Local hypervisor support: A component within the Kata runtime and responsible for interacting with a hypervisor to spin up a VM
- Pod VM: The Kata Containers support a variety of hypervisors. In the case of OpenShift sandboxed containers, it uses QEMU/KVM for bare-metal deployments and, as will be described in later sections, peer-pods for Azure deployments
- Kata agent: The kata-agent is a process running inside the VM as a supervisor for managing containers and processes running within those containers
The following diagram shows the flow for creating a pod using Kata runtime:

Let’s go over the steps:
- A new pod creation request is received by the Kubelet
- Kubelet calls CRIO (in the case of OpenShift sandboxed containers)
- CRIO calls the kata-runtime
- The kata-runtime spins up a new VM using the local hypervisor - KVM/Qemu
- The VM starts the kata-agent process
- The kata-runtime sends container creation request to the kata-agent process running inside the VM
- The kata-agent spins up the containers comprising the pod inside the VM
Confidential Containers architecture and its building blocks
Now that we covered the Kata project we can proceed to describing the CoCo project which is built on top of it.
The following diagram provides a high-level view of the main components that the CoCo solution consists of and interacts with (note how additional blocks are added to the Kata containers previous solution):
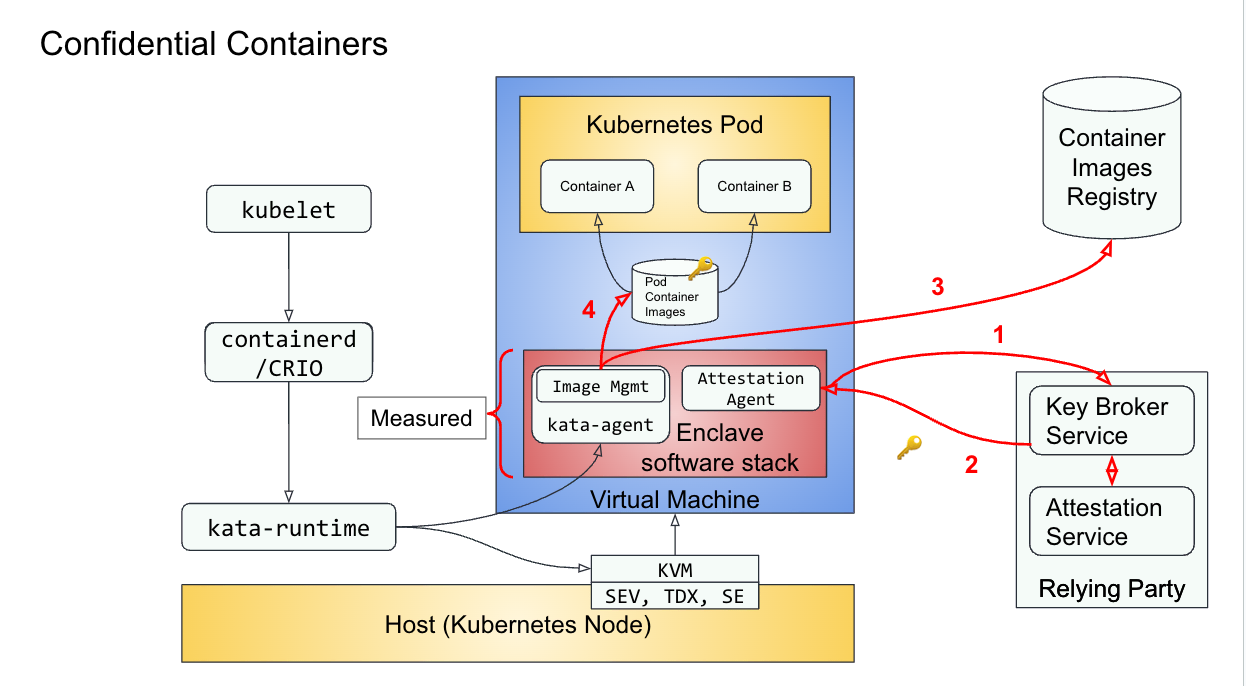
The CoCo stack runs a Kubernetes pod inside a VM together with the Enclave software stack which comprises the kata-agent, attestation-agent, VM root filesystem, etc. There is a one-to-one mapping between a Kubernetes pod and a VM-based TEE (or enclave). The container images are kept inside the enclave and can be either signed or encrypted. Note that the TEE is created leveraging hardware capabilities such as AMD SEV-SNP or Intel TDX.
The enclave software stack is measured, which means that a trusted cryptographic algorithm is used to attest its content. It contains the attestation agent which is responsible for initiating attestation and fetching of the secrets from the key broker service. The kata-agent is responsible for downloading the container images, decrypting or verifying the signatures, and creating and running the containers.
Supporting components for the solution are the container image registry and the relying party, which combines the attestation service and key broker service.
Ideally, the container image registry is responsible for storing and delivering encrypted container images. A container image typically contains multiple layers, and each layer is encrypted separately. At least one layer needs to be encrypted for the workload to be efficiently protected.
The attestation service is responsible for checking the measurement of the enclave software stack against a list of approved measurements, and authorize or deny the delivery of keys.
The key broker service is the remote attestation entry point. It works with the attestation service to verify the trustworthiness of the attester (the VM) and on success, releases the required decryption keys.
After the VM has been launched, we can then summarize the CoCo flow in the following four steps (colored in red in the diagram above):
- The attestation agent sends a request to the key broker service. The key broker service responds with a cryptographic challenge for the agent to prove the workload’s identity using the measurement of the enclave. The key broker service verifies the response and the evidence with the attestation service.
- If the workload is authorized to run, the key broker service finds the secrets based on a TEE attestation evidence report policy and sends them to the agent. Among the necessary secrets are the decryption keys for the disks being used.
- The image management service (inside the kata-agent) downloads container images from the container images registry, verifies it and decrypts it locally to encrypted storage. At that point, the container images become usable by the enclave.
- The enclave software stack creates a pod and containers inside the virtual machine and starts running the containers (all containers within the pod are isolated).
For more information on this flow we recommend reading Understanding the Confidential Containers Attestation Flow.
Peer-pods as a platform for running confidential containers
We covered the Kata project and the CoCo’s main components and can now shift our attention to tools enabling us to run workloads on the Microsoft Azure public cloud.
As described in the crash course Kata section, the existing solution used in OSC is based on QEMU and KVM as the means to launch VMs on bare metal servers out of Azure cloud environments. The implication is that this solution only supports bare metal servers where OSC can access the host. These bare metal servers are the OpenShift worker nodes, and OSC will use QEMU/KVM to spin up VMs on those servers. This is as opposed to a more typical deployment of OpenShift where the controller/worker nodes are deployed as VMs on top of the bare metal servers (for example in public cloud deployments).
To extend this consistent experience across edge and multiple clouds, supporting OSC deployments on VMs makes the offering much more attractive. This model also removes the need for cloud providers to support a native isolation model (e.g nested virtualization)
This is achieved by using peer-pods, also known as the Kata remote hypervisor (note that this repository is in the Confidential Containers Github and not in Kata Github; we will get back to this point later on).
The peer-pods solution enables the creation of Kata VMs on any environment without requiring bare metal servers or nested virtualization support (yep, it’s magic). It does this by extending Kata containers runtime to handle VM lifecycle management using cloud provider APIs (e.g. Microsoft Azure).
The following diagram shows the major components involved in the peer-pods solution (extending the Kata architecture previously described):
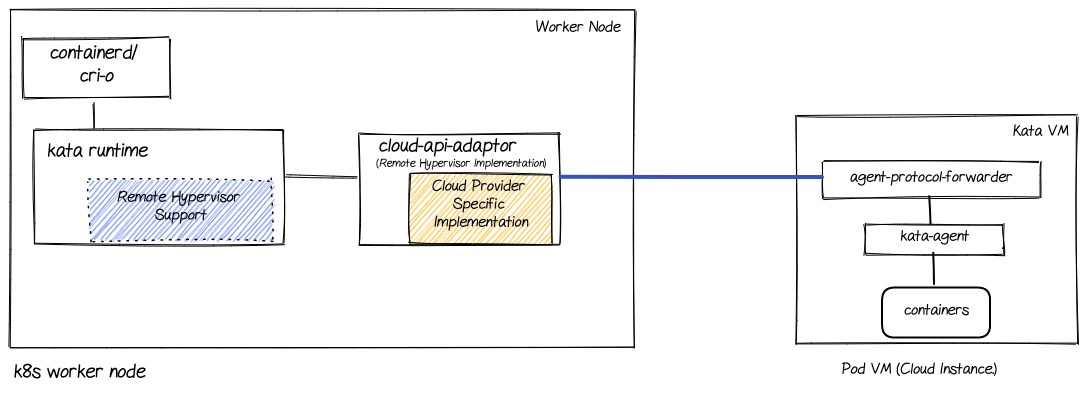
Let’s go over the different components mentioned in this diagram (on top of the ones previously mentioned in the Kata architecture section):
- Remote hypervisor support: Enhancing the shim layer to interact with the cloud-api-adapter instead of directly calling a hypervisor as previously done
- cloud-api-adaptor: Enables the use of the OpenShift sandboxed containers in a cloud environment and on third-party hypervisors by invoking the relevant APIs
- agent-protocol-forwarder: Enables kata-agent to communicate with the worker node over TCP
The following diagram zooms into the cloud-api-adaptor showing the different platforms supported:
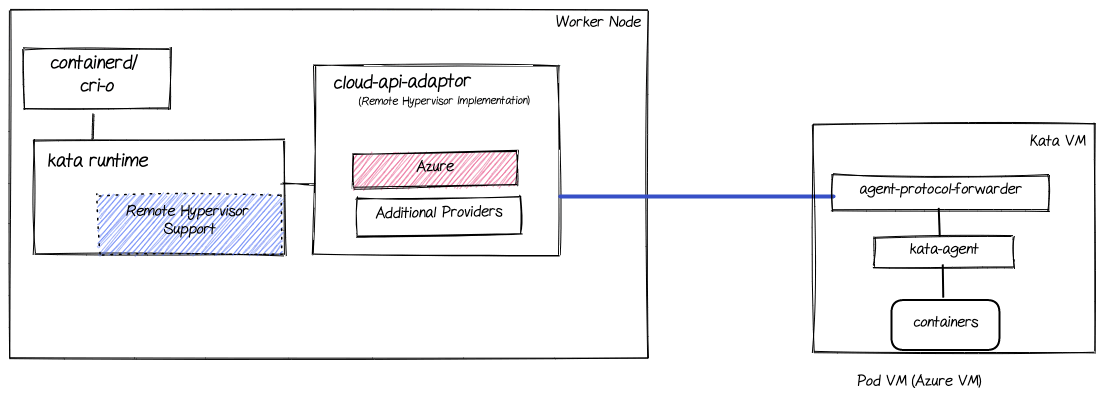
As shown, the cloud-api-adaptor can support multiple platforms while maintaining the same end-to-end flow.
For more information on peer-pods we recommend reading our previous blogs Peer-pods solution overview, Peer-pods technical deep dive and Peer-pods hands-on.
Confidential containers building blocks when deployed on Azure cloud
Let’s shift our attention now to deploying CoCo with OSC and peer-pods on Azure cloud.
The following diagram shows the components used for this solution:
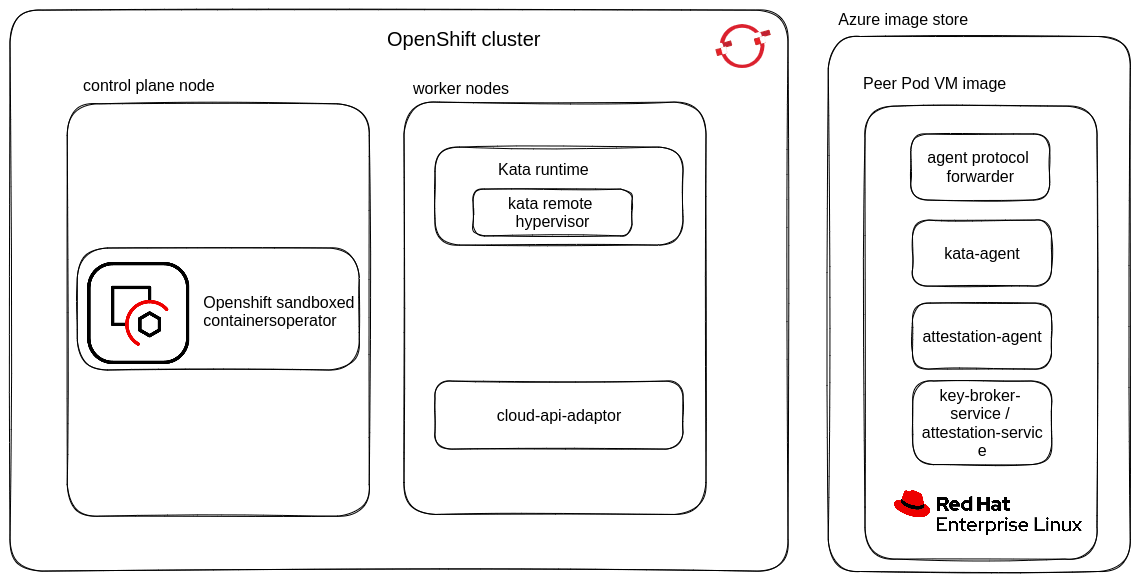
Note the following points:
- An OpenShift cluster is running on Azure with the OSC Operator installed on the control plane nodes. This operator simplifies the deployment and management of Kata Containers, ensuring a seamless integration of confidential containers within the cluster.
- The worker nodes are equipped with the Kata-runtime having remote hypervisor support, and work in conjunction with cloud-api-adaptor to create peer-pods running as confidential Virtual Machines (DCasv5, ECasv5 Azure VM’s). These peer-pods provide a security-focused environment for running confidential containers.
- The peer-pod VM image, stored in the Azure Blob Store, contains essential components such as the attestation-agent, agent-protocol-forwarder, and kata-agent.
- By working together, these components enable confidential containers to run more securely within the Azure environment, allowing developers to focus on application development and deployment while benefiting from the built-in monitoring and observability features provided by the OpenShift Sandboxed Containers Operator.
Use cases for confidential containers in public cloud
In this section we will describe two common use cases which show the value of deploying workloads using confidential containers in the public cloud.
CoCo project aims to integrate Trusted Execution Environment (TEE) infrastructure with the cloud-native world. A TEE is at the heart of a confidential computing solution. TEEs are isolated environments with enhanced security, provided by confidential computing (CC) capable hardware that prevents unauthorized access or modification of applications and data while in use. You’ll also hear the terms “enclaves”, “trusted enclaves” or “secure enclaves.” In the context of confidential containers, these terms are used interchangeably.
Privacy preserving analytics – Data Clean Rooms
Privacy preserving analytics refers to a set of techniques that allow organizations to analyze data without compromising the privacy of individuals whose data is being analyzed. For example, detecting bank fraud, money laundering and digital ads ID matching often require multiple organizations to come together and gain insights, thus data leaving the secure boundaries demand a secure trusted environment.
In order to secure and protect the privacy of these large datasets a trusted locked down environment is required, that can run at cloud scale, confidential containers allow organizations to analyze data in a way that keeps PII confidential. Prior to confidential computing, this was achieved by data masking and differential privacy, and now with confidential computing privacy assurances enable running unmasked data sets in the TEE.
Confidential containers provide a secured memory-encrypted environment to build data clean rooms where multiple parties can come together and join the data sets to gain cross-organizational insights but still maintain data privacy. Features within confidential containers like remote cryptographic verification of the initialized environment (attestation), Secure Key Release where the data decryption key or access key is only released to a TEE. Meanwhile, immutable policies help achieve building a locked down secure environment.

Privacy preserving ML inferencing
Machine Learning (ML) frameworks are optimized to build a container as an output for real time or batch inferencing of the data. ML container models that process company sensitive information or PII data often require a zero trust container environment where the inferencing happens. Confidential containers provide a set of capabilities that help achieve these data security goals. For example, healthcare providers inferencing on the MRI Scan/X Rays and using an anomaly detection model as described here: Healthcare platform confidential computing - Azure Example Scenarios | Microsoft Learn.
These scenarios often require that the inferencing hosting environment is locked down and puts all operators and admins out of trust boundary in order to achieve highest data security goals.
Confidential big data analytics with Apache Spark example
One of the common workloads with confidential computing is running Apache Spark for ML training or ID matching scenarios. Apache Spark is a popular open source software used by data scientists to perform data cleansing and matching. Spark runs distributed jobs as pods with Kubernetes and has the ability to scale up and down based on the size of the data. Confidential containers bring remote attestation and "secure key release” capabilities that can be extended to Apache Spark jobs to process a dataset encrypted with a key that is only authorized to be released in a TEE. Doing so will keep the data sets always encrypted from its original trusted source into the cloud environment and processing in a TEE.
Here we will focus on executing Apache Spark with OpenShift Peer Pods running Spark executors. This example showcases processing sensitive regulated data in cloud with a continually encrypted data set using the following flow:
- Confidential data in storage is always encrypted with customer key
- Customer key is only released to a remotely attested TEE
- Spark master cluster only schedules the Spark jobs to an attested TEE
- Encrypted data is decrypted and is available in the clear within a TEE
Deployment details
To this point, we have discussed the technology needed for deploying CoCo on Azure.
We will now shift our focus to detailing how we use these building blocks to bring to life the confidential big data analytics with the Apache Spark use case previously described.
Mapping the use case to the confidential containers building blocks
The following diagram shows how an Apache Spark workload is run on OpenShift as a CoCo workload:

Let's take a closer look at how all these building blocks work together to achieve confidential big data analytics with Apache Spark. The process involves seven steps, some of which are performed for both the Spark driver and executor as both require access to the decrypted data:
- A user submits a Spark job. This triggers the creation of the Spark driver which in turn creates the Spark executor pod(s). Pod templates for both driver and executors use a modified pod template to set the runtimeClassName to kata-remote-cc for peer-pod creation using a CVM in Azure and adds an initContainer for remote attestation and key retrieval.
- The Kata remote hypervisor calls into the cloud-api-adaptor to create the pod VM with the pod VM image containing the essential components for peer-pod operation.
- The cloud-api-adaptor creates the pod VM and initializes it.
- The agent-protocol-forwarder handles communication between the kata shim on the worker node and the kata-agent in the Peer Pod VM.
- The init container talks to the attestation-agent which initiates the attestation process with an external Key Broker Service (KBS) to retrieve the decryption key. On successful attestation, the key is received by the init container and placed in a shared ephemeral (memory backed) volume that is accessible to the application container when decrypting and processing the data.
- The Spark executor and driver container have access to the decryption key provided by the respective init containers.The encrypted data is downloaded, decrypted and subsequently analyzed.
- After performing the analysis, the Spark executor container could encrypt the results with the same key and store them in the blob storage.
This approach enables the secure processing of sensitive regulated data in the cloud while maintaining encryption at all times, leveraging the benefits of confidential containers and TEEs.
Demoing the use case
Summary
As described in this article, there are a number of technologies that need to come together in order to provide the cloud user with a working confidential container workload. We covered Kata Containers which is the building block for connecting a VM and a Kubernetes pod. We’ve covered the CoCo project which extends the Kata project to support confidential container workloads. We’ve covered the peer-pods solution which enables those workloads to run over any cloud. Lastly, we’ve covered Azure confidential VMs with AMD SEV-SNP specific building blocks to show how a user is able to deploy and run it.
We welcome you to join the Confidential Containers community through our weekly meetings and Slack channel (#confidential-containers channel).
As we work through a product offering with Red Hat OpenShift and Azure, if you are interested to get more details on this solution feel free to fill out this form.
Join us on our mission to define security boundaries, work to secure these boundaries, and to build and mature the Confidential Containers project.
About the authors
Jens Freimann is a Software Engineering Manager at Red Hat with a focus on OpenShift sandboxed containers and Confidential Containers. He has been with Red Hat for more than six years, during which he has made contributions to low-level virtualization features in QEMU, KVM and virtio(-net). Freimann is passionate about Confidential Computing and has a keen interest in helping organizations implement the technology. Freimann has over 15 years of experience in the tech industry and has held various technical roles throughout his career.
Suraj Deshmukh is working on the Confidential Containers open source project for Microsoft. He has been working with Kubernetes since version 1.2. He is currently focused on integrating Kubernetes and Confidential Containers on Azure.
Amar Gowda is a principal product manager in Azure Confidential Computing (ACC) team leading the confidential container program portfolio and cloud-native investments and strategy for ACC. Gowda has been part of Microsoft for five years and has over a decade of customer engineering and consulting experience. Gowda also actively contributes to Azure Samples, How to Videos and community open source projects while enjoying DIY home renovations, beer brewing and cooking as hobbies.
Pradipta is working in the area of confidential containers to enhance the privacy and security of container workloads running in the public cloud. He is one of the project maintainers of the CNCF confidential containers project.
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
The new currency of enterprise velocity
Container Roundup | Compiler
Collaboration In Product Security | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds