
Manually doing any task is not the most efficient nor consistent approach; the same is true when creating many virtual machines (VMs) in Red Hat Virtualization. The larger your virtualization deployment is, the more critical an automated process becomes. Ansible is a great solution for precisely this scenario.
In the first article of this series, I discuss the design and prerequisites for this automated VM deployment project. The third article provides two sample Ansible playbooks you can use to jump-start your deployments.
In this article, I cover the use of templates and comma-separated value (CSV) files to manage variables. Be sure to read part one first, and don't forget part three when you finish this article.
Automation
Template
Ansible playbooks can deploy VMs from ISO images. However, one of the goals of automation is to speed up the deployment process, and using templates is indeed faster. If you have existing VMs, you can create templates from them. You can also deploy a barebones installation and use it as the basis for your template.
Use the following steps to create a template from a basic virtual machine.
- Deploy a VM by installing the operating system manually from an ISO image or downloading a qcow2 image from a trusted source. Using an ISO image allows you to configure the VM with thick disk provisioning.
- Power on the VM.
- Install the cloud-init package.
- Seal the VM to prepare it for deployment as a template.
- Power off the VM.
- Create a template (I cover templates in more detail below).
Design
Ansible uses a declarative language to describe a desired system configuration. Before we start coding and writing the playbook, we must define the final state we need to reach and how we can reach it.
In this article, I want to achieve the following goals:
- The VMs are created based on CSV configuration files, which are easily edited and modified.
- The CSV configuration files are defined in a way that is appropriate for VMs with different use cases.
- VMs are deployed by using templates.
- Proper privileges are assigned for the newly-created VMs. Often, the infrastructure team creating the VM is different from the team managing the VM and the hosted application, so the correct privileges must be set.
- Manage any additional configuration of the VMs after they are deployed (i.e., installing packages, creating accounts, managing services, etc.).
These goals can be met with three plays:
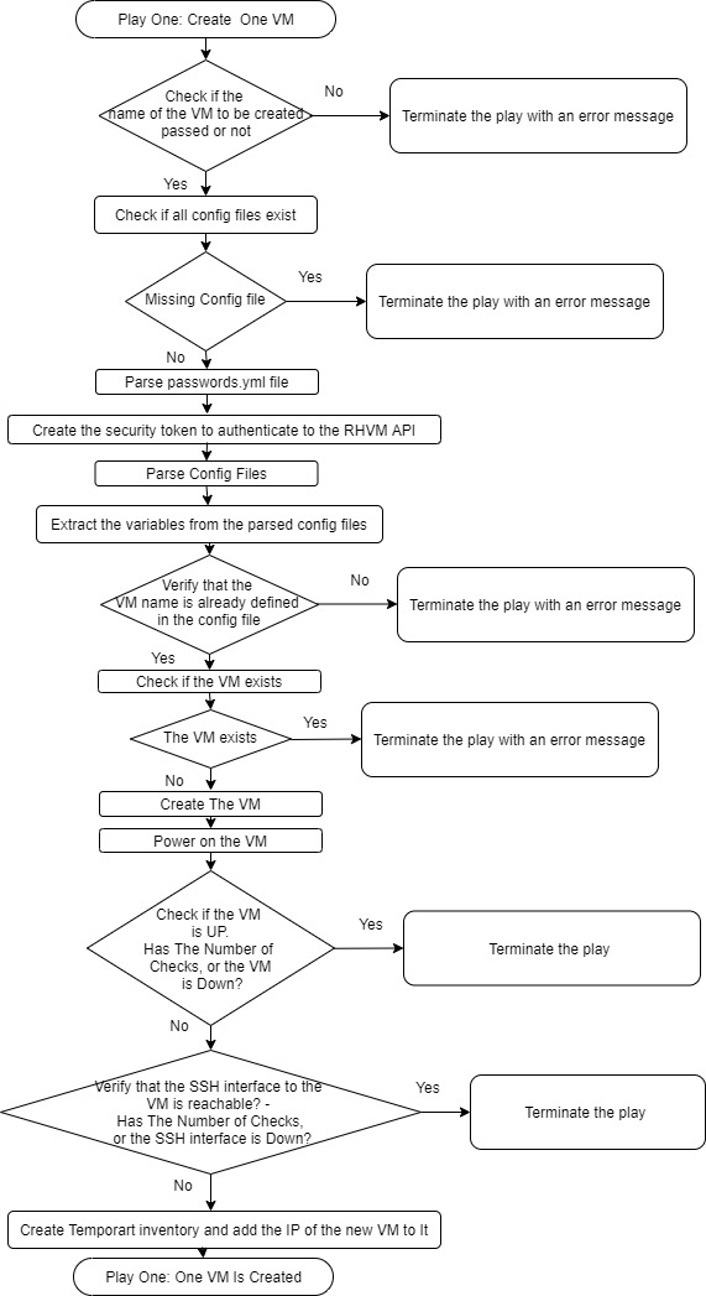
- Play to create one VM and power it on by using the RHVM API.
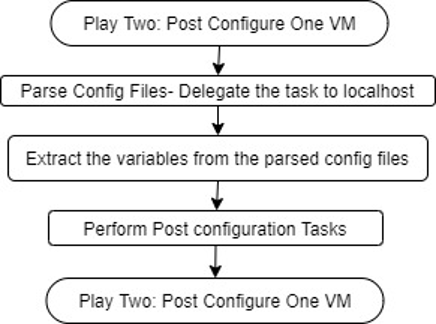
- Play to perform post configuration of one VM by using SSH.
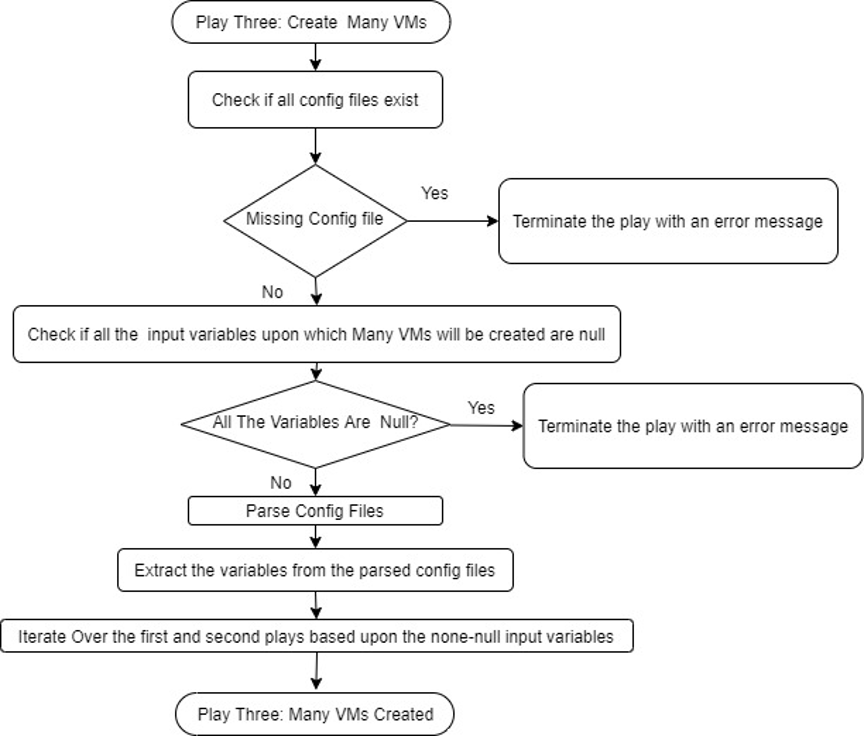
- Play to iterate over both plays to create multiple VMs if needed.
The first and the second plays manage the same VM, so they are placed in the same playbook. The third play iterates over this playbook.
The following flowcharts follow the steps to achieve the goals for a single-VM deployment.
Play 1:
Play 2:
The following flowchart displays the steps to achieve the goals for many VMs.
Play 3:
Variable files
There are two types of variable files used in this article:
- Password variables.
- VM-related variables.
Let's examine both types of variables in more detail.
Password variables
Sensitive information is often needed during automation to execute some tasks. Passwords are an example of this kind of information. Passwords must be saved in a secure way to avoid being compromised. In the case of Ansible, Ansible Vault is used.
In this article, the following sensitive information is needed:
- User and password created for the RHVM in our earlier example. That account was ansible-user and the password was redhat.
- The username and password that will be set by a
cloud-initscript while the VM boots.
Create an Ansible Vault file
Create an Ansible Vault file to secure the user and password information.
First, create a new Ansible Vault file, and enter a password used to encrypt and decrypt this file. Use the ansible-vault command to accomplish this.
$ ansible-vault create passwords.yml
New Vault password:
Confirm New Vault password:
Next, enter the following variables (in YAML format).
username: ansible-user@internal
password: redhat
cloud_init_username: root
cloud_init_password: redhat
The playbook that uses the file created by ansible-vault decrypts it during execution, so the password used to encrypt the file is required. There are different methods to provide the password. The easiest ways are:
Method 1: Prompt for a password.
# ansible-playbook --ask-vault-pass playbook.yml
Method 2: Store the password in a text file. Place the file in a safe directory with relevant permissions to secure it. Ask the playbook to use this file during the execution.
# ansible-playbook --vault-password-file /path/to/my/vault-password-file playbook.yml
Refer to this link for more information regarding ansible-vault password management.
Virtual machine-related variables
Many of the variables needed for the deployment are provided from teams other than the infrastructure team. Ansible offers different ways to store the variables that are called during the playbook execution. CSV variable files are an easy way to manage the variables.
CSV files are:
- Interoperable across different operating systems.
- Edited with different editors without issues.
- Extended horizontally to include new variables if needed.
All of the variables can be included in a single CSV file. However, to make the variables easy to manage, create smaller CSV files that each cover specific aspects of the configuration. In this article, I have four main CSV files.
Let's break down each of the four CSV files.
The vms.csv file has the following header:
name,vmflavour,type,site,cluster,class,os,nic,ip,gw,mask,system,fqdn,dns1,dns2,dns_domain
vm01,medium_vm,generic,first,Cluster01,server,rhel_8x64,eth0,10.10.10.10, 10.10.10.1,255.255.255.0,webserver,vm01.example.com,10.10.10.2, 10.10.10.2,example.com
Where:
- name - the VM name.
- vmflavour - the vmflavour to be used.
- type - VM type, which can be generic, development, production, or whatever.
- site - in case your RHVM is managing different data centers.
- cluster - RHV cluster name hosting the VM.
- class - VM class (server or desktop).
- os - OS of the template.
- nic - the nic that the
cloud-initwill configure. In this case, it is eth0. - ip - IP address to be assigned to eth0.
- gw - gateway to be assigned eth0.
- mask - netmask to be assigned to eth0.
- system - the application hosted on this VM, which in this case is webserver.
- fqdn - FQDN for the VM.
- dns1 - first DNS server to be used by the VM.
- dns2 - second DNS server to be used by the VM.
- dns_domain - DNS search zone.
The vmflavours.csv file uses the following header:
name,memorysize,guaranteedmemory,cpusockets,cputhreads,cpucores
medium_vm,16,16,1,1,8
Where:
- name - name of the flavour.
- memorysize - memory size of the VM.
- guaranteedmemory - size of the guaranteed memory of the VM.
- cpusockets - number of CPU sockets.
- cputhreads - number of CPU threads.
- cpucores - number of CPU cores.
The vmtemplates.csv file has the following header:
name,version,site,system
webserver-image-2206,1,first,webserver
Where:
- name - name of the template as it is created in RHVM.
- version - version of the template, if you have multiple versions.
- site - data center where the VM and the template are hosted.
- system - application hosted on the VM.
Note: The template and VM sizing could be placed in the vms.csv. However, for the sake of decoupling the activities of the application team and infrastructure team, this information is stored in different files.
The permissions.csv file uses the following header:
user,domain,role,system
newuser,internal,UserVmManager,webserver
Where:
- user - username that is granted particular roles on this type of application. The user is already created in RHVM.
- domain - user's domain, which in this case is internal, because it is a local user.
- role - role to be assigned to the user.
- system - name of the application which will be hosted on the VM.
Customize these CSV files for your own environment.
Directory structure
It is useful to visualize how the files and playbooks are organized. The following is the directory structure for the playbooks and the variable files:

Wrap up
As you can see, automation begins with a firm foundation in design and templates. It also includes the flexibility to reflect your organization's management requirements (infrastructure team versus system management team, for example). Variables to set the configurations can be stored in CSV files. Each CSV file manages a discreet group of settings.
In part three, I pull everything together by providing two sample Ansible playbooks based on the settings discussed here. I also provide debugging and troubleshooting tips.
Continue with this series
Automate VM deployment with Ansible: Design (Part 1)
Automate VM deployment with Ansible: The playbooks (Part 3)
References
Documentation for Red Hat Virtualization 4.3
[ Need more on Ansible? Take a free technical overview course from Red Hat. Ansible Essentials: Simplicity in Automation Technical Overview. ]
About the author
I am Ashraf Hassan, originally from Egypt, but currently, I am living in the Netherlands
I started my career in 1998 in the telecom industry, specifically the value-added services.
Although my official studies were in the area of telecommunications, I was always attracted to system administration and scripting. I started to sharpen these skills in 2008, during my free time, I like to test new tips and tricks using my home lab.
Working as a senior designer enriched my skills further.
In 2016 I decided to start the journey to be an “RHCA” which I accomplished in 2019, but as IT is a fast-changing domain, I need to keep studying, testing and learning.
In 2019 I joined Red Hat Accelerators once they expanded the program to include Europe; being a member of highly skilled technical experts helped me further.
Please feel free to contact me (info@free-snippets.com) regarding my posts or questions that can pop up related to any of Red Hat Products.
More like this
Red Hat Ansible All-Stars: Driving the future of network and infrastructure automation
Achieve high scalability using Red Hat Satellite Capsule Server
Untangling Networks | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds