

Many developers and organizations are shifting to containerized applications and serverless infrastructure, but there is still huge interest in developing and maintaining applications running as VMs. Red Hat OpenShift Virtualization provides that ability and allows organizations to bring VMs into containerized workflows inside clusters.
Additionally, GPUs in workstations are becoming increasingly popular. GPUs are powerful devices designed to deal with compute-heavy workloads like processing large amounts of data, such as AI/ML, in addition to graphics-intensive tasks. They provide notorious acceleration benefits and drastically improve the performance that we can obtain by just relying on the central processing unit CPU itself. OpenShift allows the use of PCI passthrough to access and use GPU hardware inside a VM.
Nevertheless, depending on the case, the entire GPU is not always needed. Typically, associating a PCI device to a VM means that the entire device will be dedicated to processes in that VM. This way, when a workload is being processed there, no other VM can use that PCI device. Utilizing technologies from various GPU vendors and the Linux kernel, OpenShift offers the ability to pass and set up a “slice”, or part of a GPU as a virtual GPU (vGPU) inside the VM. This means that resources are available and can be shared between multiple consumers at the same time. It is worth mentioning that OpenShift Virtualization 4.10 supports vGPU as a tech preview feature.
The objective of this blog is to dive into the process of setting up a cluster using a Single Node OpenShift instance on bare metal, and to configure and pass an NVIDIA GPU card as a vGPU (i.e. just a slice of the overall card) into a Fedora VM. Then, we’re going to test the performance by running different applications that make use of that vGPU. To finish off, we’ll compare the previous results with the ones obtained when the vGPU is not used, where we’ll simply rely on the CPU instead.
Node specifications
As mentioned previously, we’re going to deploy a Single Node OpenShift instance using the Assisted Installer for OpenShift 4.9.19 on a bare metal host. In this particular case, we’re going to use a single machine, but this blog can be followed for other topologies, like full-scale production clusters and compact clusters (three nodes). The node used in our example has the following specifications:
- 2x Intel Xeon Silver 4116, 2.1G, 12C/24T
- 4x 480GB SSD SATA (RAID 10)
- 128GB Memory
- NVIDIA Tesla M60 GPU Card w/2 GPUs 16GB Memory
Install Single Node OpenShift
Single Node OpenShift offers both control and worker capabilities in a single node, reducing the footprint and allowing it to run in more constrained environments. We’ll use the Assisted Installer which simplifies the deployment of OpenShift on bare metal hardware. Let’s start with the configuration from scratch.
Firstly, we need to navigate to the Assisted Installer page via the OpenShift Cluster Manager console and login with our Red Hat account. After logging in, click the Create button. Then, choose the Datacenter tab as target, and select Create Cluster.
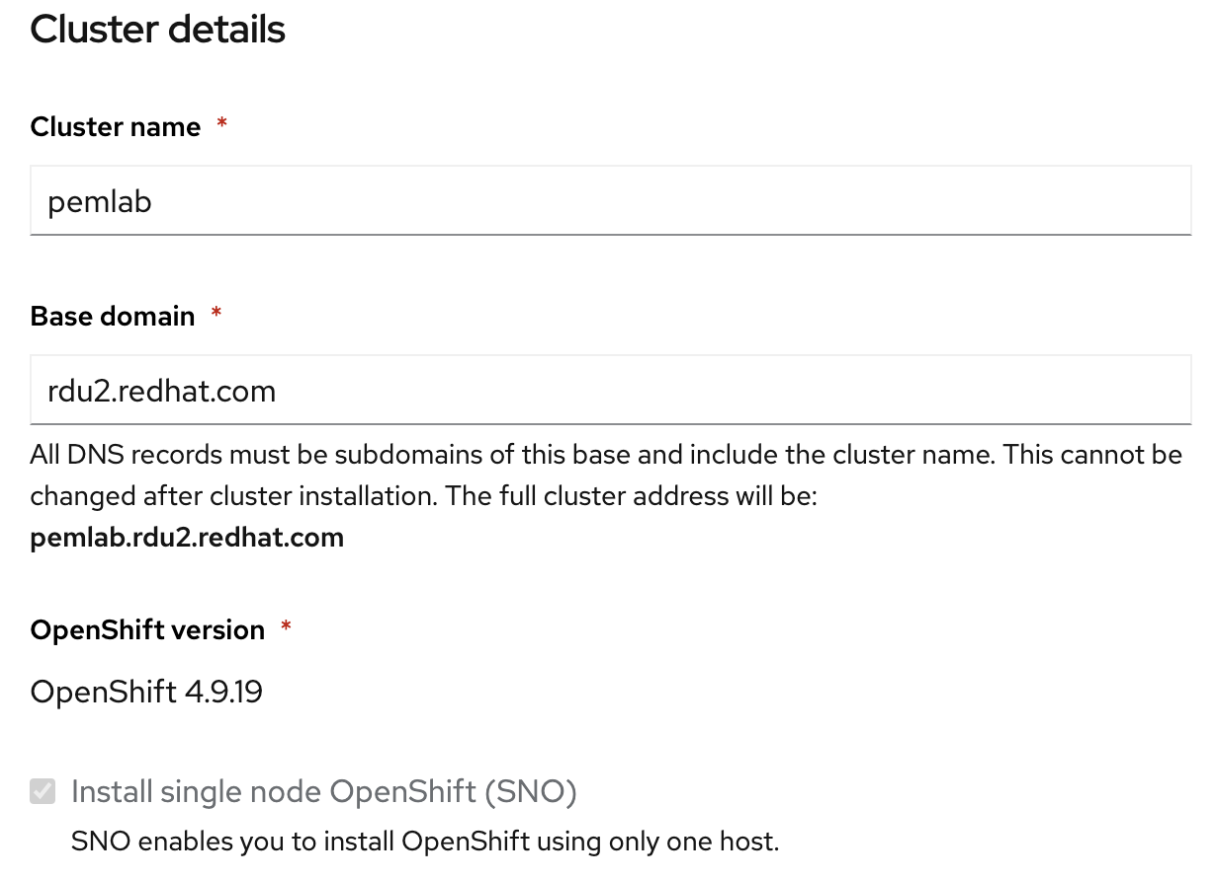
The first part of the wizard will ask you for cluster details. Complete the following fields:
- Cluster name: preferred cluster name.
- Base domain: subdomain to match DNS. Please, refer to the OpenShift networking documentation to pre-configure your cluster’s networking, including:
- DHCP or static IP Addresses.
- Network ports.
- DNS.
- OpenShift version: in this case, OpenShift 4.9.19, the latest at time of writing.
- Check the box Install Single Node OpenShift (SNO).
When finished, we can jump into the host discovery section by clicking Next. There, be sure to check the Install OpenShift Virtualization box (although this can be enabled post-installation if desired) and then click the Add hosts button.
The purpose of this step is to generate a discovery ISO to boot the node and install OpenShift there. There are two different options. If you want to boot the host from a USB drive or PXE, select Full image file. Otherwise, to boot using virtual media select Minimal image file (note that your node will require internet access). We’ll use the second option.
Finally, paste your SSH public key, which is used to ssh to deployed nodes. It is typically stored in the .ssh folder of your home directory and ends in .pub. In this case the corresponding file would be: ~/.ssh/id_rsa.pub. You can get the key by running this command in your terminal:
$ cat ~/.ssh/id_rsa.pub
Then, click Generate Discovery ISO to get the URL and the command to download the image:

Open a new terminal in the host machine and download the image by running the provided command. Once downloaded, mount the ISO image as virtual media (there are vendor specific options for this, so please seek the documentation for your respective hardware vendor) and set the host to automatically boot from that image. Then, power the system up.
Back on the Assisted Installer UI, the node will appear automatically. It may take a couple of minutes before it’s ready. Once it appears, you can change the node name if necessary. To continue with the installation, click Next.
In the Networking section, fill the Select subnet field by choosing the subnet you want to use; the available subnets should be automatically detected. Before proceeding, check that the Use the same host discovery SSH key box is selected. Then, click Next, review all the settings and finally select Install Cluster.
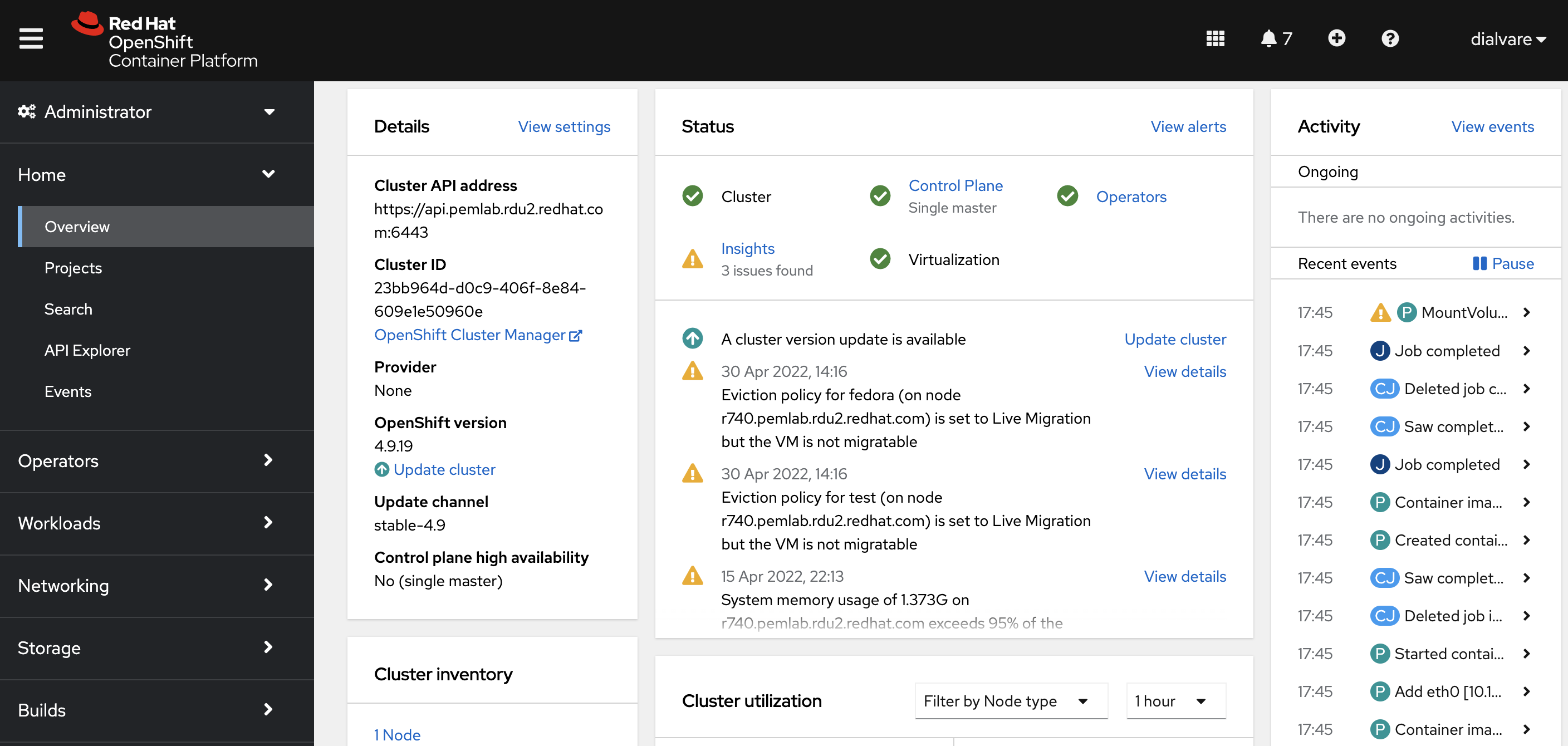
Single Node OpenShift installation can be monitored with the progress bar displayed. Once completed, you can spread out the installation section. There, you’ll find the Web Console URL, the admin user kubeadmin and the password. Access the web console by clicking on the URL and log in with the provided credentials. The web console Interface looks like this:
Install Operators
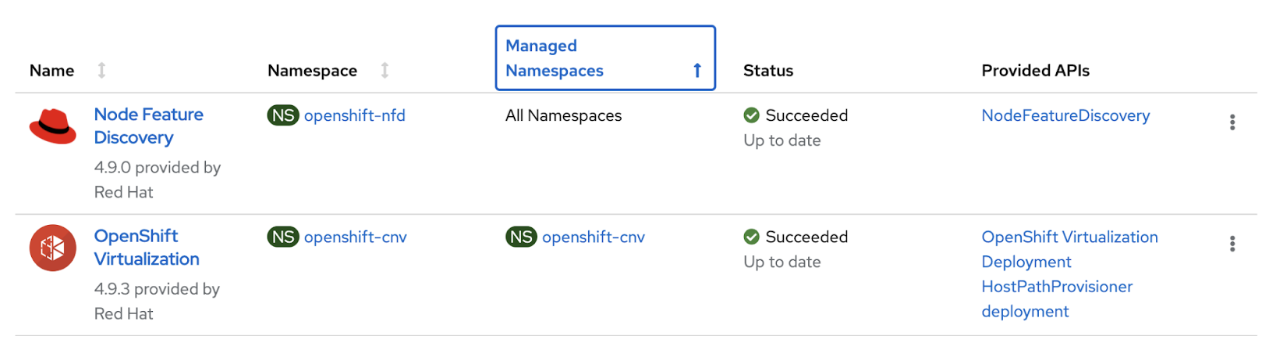
To proceed with the configuration, two Operators from the OperatorHub in OpenShift are needed: OpenShift Virtualization and Node Feature Discovery (NFD).
On the left side of the web console, open the Operators tab and click OperatorHub. There, we can search both operators filtering by name:
- OpenShift Virtualization: This operator is installed during SNO deployment when checking the Install OpenShift Virtualization box. The status should be Succeed. If not, click Install.
- Node Feature Discovery (NFD): click Install and use the default configuration provided. Once installed, select the NFD Operator and click on Create Instance. There, we’ll find different parameters we can configure. In this case, we are going to keep it by default, so click Create.
Verify the installation finished correctly by checking the Installed Operators section under Operators. You’ll see something like this:
Enable IOMMU
An input–output memory management unit (IOMMU) can be used in guest systems, such as VMs to use hardware that is not specifically made for virtualization. Graphic cards use direct memory access (DMA) to manage memory directly. In a virtual environment, all memory addresses are re-mapped by the virtual machine software, which causes DMA devices to fail. The IOMMU handles this re-mapping, allowing the guest operating system to use the native device drivers installed.
To connect with the OpenShift cluster, navigate to the upper-right corner of the web console and click on kube:admin. Choose the option Copy login command. In the new browser tab, select Display Token and paste the Log in with this token command in your terminal:
$ oc login --token=<sha256_token> --server=<server_url>
Once connected, the first step is enabling the IOMMU driver on the worker nodes with a GPU card. In this case, we have a single node:
$ oc get nodes
NAME STATUS ROLES AGE VERSION
r740.pemlab.rdu2.redhat.com Ready master,worker 16d v1.22.3+2cb6068
Now, we can create the MachineConfig object to identify the kernel argument and enable the IOMMU driver. Apply a new label to indicate that this node has GPU by running the following command. We’ll tell the MachineConfig to look for nodes with this label:
$ oc label nodes r740.pemlab.rdu2.redhat.com hasGpu=true
node/r740.pemlab.rdu2.redhat.com labeled
Now, apply the MachineConfig object which will only be applied in the node with GPU, labeled previously:
$ cat << EOF > ~/100-master-kernel-arg-iommu.yaml
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels: hasGpu
machineconfiguration.openshift.io/role: master
name: 100-master-iommu
spec:
config:
ignition:
version: 3.2.0
kernelArguments:
- intel_iommu=on
EOF
If you’re using AMD hardware, note that you’ll need to change the intel_iommu=on statement to amd_iommu=on.
The last step to complete the IOMMU configuration is to apply the MachineConfig to the cluster. This action will reboot the node labeled before:
$ oc create -f ~/100-master-kernel-arg-iommu.yaml
machineconfig.machineconfiguration.openshift.io/100-master-iommu created
Wait for the node where the MachineConfig is applied to reboot. Then, we can continue onto the next step.
Create Hostpath Provisioning
Pods and containers are ephemeral by nature and therefore, by default, so is their storage. Nevertheless, OpenShift provides different options in case persistent storage is needed. In this blog, we are going to use HostPath provisioning local storage. Following these steps, we can configure and use local storage in virtual machines.
Firstly, we need to generate the MachineConfig object to set up our worker node in the cluster. A new unit file will be deployed in the worker node. This will create the new directory where the data will be stored:
$ cat << EOF | oc apply -f -
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
name: 50-set-selinux-for-hostpath-provisioner-worker
labels:
machineconfiguration.openshift.io/role: worker
spec:
config:
ignition:
version: 2.2.0
systemd:
units:
- contents: |
[Unit]
Description=Set SELinux chcon for hostpath provisioner
Before=kubelet.service
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStartPre=-mkdir -p /var/hpvolumes
ExecStart=/usr/bin/chcon -Rt container_file_t /var/hpvolumes
[Install]
WantedBy=multi-user.target
enabled: true
name: hostpath-provisioner.service
EOF
You should verify that the MachineConfig was created correctly:
$ oc get machineconfig 50-set-selinux-for-hostpath-provisioner-worker
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE
50-set-selinux-for-hostpath-provisioner-worker 2.2.0 7d5h
And it is also important to check that the MachineConfig has been applied in the worker node after rebooting automatically. When the node comes back and the API is available again, run the command until True is shown:
$ oc get machineconfigpool worker -o=jsonpath="{.status.conditions[?(@.type=='Updated')].status}{\"\n\"}"
True
After making sure our worker node is properly configured, we can set up the HostPathProvisioner object. The following lines indicate the path that is going to be used for storage:
$ cat << EOF | oc apply -f -
apiVersion: hostpathprovisioner.kubevirt.io/v1beta1
kind: HostPathProvisioner
metadata:
name: hostpath-provisioner
spec:
imagePullPolicy: IfNotPresent
pathConfig:
path: "/var/hpvolumes"
useNamingPrefix: false
EOF
Then, we create a new StorageClass to be used by the host path provisioner. This StorageClass has a provisioner, so persistent volumes are going to be created dynamically:
$ cat << EOF | oc apply -f -
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: hostpath-provisioner
provisioner: kubevirt.io/hostpath-provisioner
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
EOF
Lastly, before moving on to the next steps, we should confirm that the StorageClass was created correctly:
$ oc get sc hostpath-provisioner
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
hostpath-provisioner kubevirt.io/hostpath-provisioner Delete WaitForFirstConsumer false 6d
Apply the NVIDIA driver
At this point, the cluster is configured and ready, so we can go ahead and focus on setting up the node to detect the NVIDIA GPU. The first task we have to do is to download the drivers needed for our GPU card from the NVIDIA official page. For this blogpost, I’m going to use the NVIDIA-Linux-x86_64-510.47.03-vgpu-kvm.run driver. These vGPU-KVM drivers are supplied via the NVIDIA customer portal and are not supplied by Red Hat.
We create a new folder where all the files will be placed:
$ mkdir vgpu && cd vgpu
Before continuing, we also need to obtain the driver-toolkit image that our cluster is currently using. The Driver Toolkit is a base image on which you can build drivers and contains the kernel packages commonly required as dependencies to build or install kernel modules on the host. We can check it by running this command:
$ oc adm release info --image-for=driver-toolkit
quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:ee885e4cfef83fc2d3c34fe04afb4986b957f740fb4dc13bf0358daab57e12ba
In order to load the NVIDIA drivers into the kernel, the first step would be to create the Podman Containerfile for building the image, specifying the drivers file downloaded and the driver-toolkit image name previously obtained:
$ cat << EOF > ~/vgpu/Containerfile
FROM quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:ee885e4cfef83fc2d3c34fe04afb4986b957f740fb4dc13bf0358daab57e12ba
ARG NVIDIA_INSTALLER_BINARY
ENV NVIDIA_INSTALLER_BINARY=${NVIDIA_INSTALLER_BINARY:-NVIDIA-Linux-x86_64-510.47.03-vgpu-kvm.run}
RUN dnf -y install git make sudo gcc && dnf clean all && rm -rf /var/cache/dnf
RUN mkdir -p /root/nvidia
WORKDIR /root/nvidia
ADD ${NVIDIA_INSTALLER_BINARY} .
RUN chmod +x /root/nvidia/${NVIDIA_INSTALLER_BINARY}
ADD entrypoint.sh .
RUN chmod +x /root/nvidia/entrypoint.sh
RUN mkdir -p /root/tmp
EOF
The other file required for building the driver image is the entrypoint. By running this command, the file is created and placed in the vgpu directory:
$ cat << EOF > ~/vgpu/entrypoint.sh
#!/bin/sh
/usr/sbin/rmmod nvidia
/root/nvidia/${NVIDIA_INSTALLER_BINARY} --kernel-source-path=/usr/src/kernels/$(uname -r) --kernel-install-path=/lib/modules/$(uname -r)/kernel/drivers/video/ --silent --tmpdir /root/tmp/ --no-systemd
/usr/bin/nvidia-vgpud &
/usr/bin/nvidia-vgpu-mgr &
while true; do sleep 15 ; /usr/bin/pgrep nvidia-vgpu-mgr ; if [ 0 -ne 0 ] ; then echo "nvidia-vgpu-mgr is not running" && exit 1; fi; done
EOF
When done with the previous steps, confirm that you have all the necessary files, as seen below, in the vgpu folder:
$ ls
Containerfile entrypoint.sh NVIDIA-Linux-x86_64-510.47.03-vgpu-kvm.run
Now that we have all the files, we can build the driver container image by running:
$ podman build --build-arg NVIDIA_INSTALLER_BINARY=NVIDIA-Linux-x86_64-510.47.03-vgpu-kvm.run -t ocp-nvidia-vgpu-installer .
STEP 1/11: FROM quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:ee885e4cfef83fc2d3c34fe04afb4986b957f740fb4dc13bf0358daab57e12ba
STEP 2/11: ARG NVIDIA_INSTALLER_BINARY
--> Using cache 13aa17a1fd44bb7afea0a1b884b7005aaa51091e47dfe14987b572db9efab1f2
--> 13aa17a1fd4
STEP 3/11: ENV NVIDIA_INSTALLER_BINARY=${NVIDIA_INSTALLER_BINARY:-NVIDIA-Linux-x86_64-510.47.03-vgpu-kvm.run}
--> Using cache e818b281ad40c0e78ef4c01a71d73b45b509392100262fddbf542c457d697255
--> e818b281ad4
STEP 4/11: RUN dnf -y install git make sudo gcc && dnf clean all && rm -rf /var/cache/dnf
--> Using cache d6f3687a545589cf096353ad792fb464a6961ff204c49234ced26d996da9f1c8
--> d6f3687a545
STEP 5/11: RUN mkdir -p /root/nvidia
--> Using cache 708b464de69de2443edb5609623478945af6f9498d73bf4d47c577e29811a414
--> 708b464de69
STEP 6/11: WORKDIR /root/nvidia
--> Using cache 6cb724eeb99d21a30f50a3c25954426d4719af84ef43bda7ab0aeab6e7da81a8
--> 6cb724eeb99
STEP 7/11: ADD ${NVIDIA_INSTALLER_BINARY} .
--> Using cache 71dd0491be7e3c20a742cd50efe26f54a5e2f61d4aa8846cd5d7ccd82f27ab45
--> 71dd0491be7
STEP 8/11: RUN chmod +x /root/nvidia/${NVIDIA_INSTALLER_BINARY}
--> Using cache 85d64dc8b702936412fa121aaab3733a60f880aa211e0197f1c8853ddbb617b5
--> 85d64dc8b70
STEP 9/11: ADD entrypoint.sh .
--> Using cache 9d49c87387f926ec39162c5e1c2a7866c1494c1ab8f3912c53ea6eaefe0be254
--> 9d49c87387f
STEP 10/11: RUN chmod +x /root/nvidia/entrypoint.sh
--> Using cache 79d682f8471fc97a60b6507d2cff164b3b9283a1e078d4ddb9f8138741c033b5
--> 79d682f8471
STEP 11/11: RUN mkdir -p /root/tmp
--> Using cache bcbb311e35999cb6c55987049033c5d278ee93d76a97fe9203ce68257a9f8ebd
COMMIT ocp-nvidia-vgpu-installer
--> bcbb311e359
Successfully tagged localhost/ocp-nvidia-vgpu-installer:latest
Before uploading the image to a private repository, we need to tag the image with the target repository format:
$ podman tag localhost/ocp-nvidia-vgpu-installer:latest quay.io/dialvare/ocp-nvidia-installer:latest
Then, we can push the image onto the repository. Note that the driver image cannot be freely shared as a result of NVIDIA licensing restrictions, so it should be pushed to a private repository (substitute this URL for your private repository):
$ podman push quay.io/dialvare/ocp-nvidia-vgpu-installer:latest
Getting image source signatures
Copying blob 525ed45dbdb1 done
Copying blob 6525ed03fe32 done
Copying blob b5d4fbbf4202 done
Copying blob ff6baa4a3711 done
Copying blob c86614e705e2 done
Copying blob fbf4e5b05377 done
Copying blob b0d33348dc7e done
Copying blob 5bc03dec6239 done
Copying blob 86adb27b3715 done
Copying blob 14e0f5c015a0 done
Copying blob 520e9ec8322e done
Copying blob 1340136c8008 done
Copying config dcbac678b6 done
Writing manifest to image destination
Storing signatures
To load the driver image into the kernel, we’re going to create a set of resources that will use and apply the image to the node, which will load the necessary NVIDIA drivers into the host kernel and provide the additional tools to be able to utilize vGPU devices. This instance will run as a DaemonSet across the cluster. Be sure to specify the correct image path to your private repository:
$ cat << EOF > ~/1000-drivercontainer.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: simple-kmod-driver-container
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: simple-kmod-driver-container
rules:
- apiGroups:
- security.openshift.io
resources:
- securitycontextconstraints
verbs:
- use
resourceNames:
- privileged
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: simple-kmod-driver-container
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: simple-kmod-driver-container
subjects:
- kind: ServiceAccount
name: simple-kmod-driver-container
userNames:
- system:serviceaccount:simple-kmod-demo:simple-kmod-driver-container
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: simple-kmod-driver-container
spec:
selector:
matchLabels:
app: simple-kmod-driver-container
template:
metadata:
labels:
app: simple-kmod-driver-container
spec:
serviceAccount: simple-kmod-driver-container
serviceAccountName: simple-kmod-driver-container
hostPID: true
hostIPC: true
containers:
- image: quay.io/dialvare/ocp-nvidia-vgpu-installer:latest
name: simple-kmod-driver-container
imagePullPolicy: Always
command: ["/root/nvidia/entrypoint.sh"]
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "systemctl stop kmods-via-containers@simple-kmod"]
securityContext:
privileged: true
allowedCapabilities:
- '*'
capabilities:
add: ["SYS_ADMIN"]
volumeMounts:
- mountPath: /dev/vfio/
name: vfio
- mountPath: /sys/fs/cgroup
name: cgroup
volumes:
- hostPath:
path: /sys/fs/cgroup
type: Directory
name: cgroup
- hostPath:
path: /dev/vfio/
type: Directory
name: vfio
nodeSelector:
hasGpu: "true"
EOF
Apply the CustomResources to the cluster:
$ oc create -f 1000-drivercontainer.yaml
serviceaccount/simple-kmod-driver-container created
role.rbac.authorization.k8s.io/simple-kmod-driver-container created
rolebinding.rbac.authorization.k8s.io/simple-kmod-driver-container created
daemonset.apps/simple-kmod-driver-container created
Verify that the DaemonSet was applied and is running correctly:
$ oc get daemonset simple-kmod-driver-container -n openshift-nfd
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
simple-kmod-driver-container 1 1 1 1 1 hasGpu=true 5d20h
To verify that everything was configured properly, we must see the drivers loaded in the kernel. Run the following commands:
$ oc debug node/r740.pemlab.rdu2.redhat.com
# chroot /host
# lsmod | grep nvidia
nvidia_vgpu_vfio 65536 0
nvidia 39067648 11
mdev 20480 2 vfio_mdev,nvidia_vgpu_vfio
vfio 36864 3 vfio_mdev,nvidia_vgpu_vfio,vfio_iommu_type1
drm 569344 4 drm_kms_helper,nvidia,mgag200
At this point, the kernel has the NVIDIA drivers loaded. The next step is choosing the configuration for the GPU card. Running the following command allows us to list different ways for carving up the GPU cards as vGPU into the virtual machine:
# for device in /sys/class/mdev_bus/*; do for mdev_type in "$device"/mdev_supported_types/*; do MDEV_TYPE=$(basename $mdev_type); DESCRIPTION=$(cat $mdev_type/description); NAME=$(cat $mdev_type/name); echo "mdev_type: $MDEV_TYPE --- description: $DESCRIPTION --- name: $NAME"; done; done | sort | uniq
mdev_type: nvidia-11 --- description: num_heads=2, frl_config=45, framebuffer=512M, max_resolution=2560x1600, max_instance=16 --- name: GRID M60-0B
mdev_type: nvidia-12 --- description: num_heads=2, frl_config=60, framebuffer=512M, max_resolution=2560x1600, max_instance=16 --- name: GRID M60-0Q
mdev_type: nvidia-13 --- description: num_heads=1, frl_config=60, framebuffer=1024M, max_resolution=1280x1024, max_instance=8 --- name: GRID M60-1A
mdev_type: nvidia-14 --- description: num_heads=4, frl_config=45, framebuffer=1024M, max_resolution=5120x2880, max_instance=8 --- name: GRID M60-1B
mdev_type: nvidia-15 --- description: num_heads=4, frl_config=60, framebuffer=1024M, max_resolution=5120x2880, max_instance=8 --- name: GRID M60-1Q
mdev_type: nvidia-16 --- description: num_heads=1, frl_config=60, framebuffer=2048M, max_resolution=1280x1024, max_instance=4 --- name: GRID M60-2A
mdev_type: nvidia-17 --- description: num_heads=4, frl_config=45, framebuffer=2048M, max_resolution=5120x2880, max_instance=4 --- name: GRID M60-2B
mdev_type: nvidia-18 --- description: num_heads=4, frl_config=60, framebuffer=2048M, max_resolution=5120x2880, max_instance=4 --- name: GRID M60-2Q
mdev_type: nvidia-19 --- description: num_heads=1, frl_config=60, framebuffer=4096M, max_resolution=1280x1024, max_instance=2 --- name: GRID M60-4A
mdev_type: nvidia-20 --- description: num_heads=4, frl_config=60, framebuffer=4096M, max_resolution=5120x2880, max_instance=2 --- name: GRID M60-4Q
mdev_type: nvidia-210 --- description: num_heads=4, frl_config=45, framebuffer=2048M, max_resolution=5120x2880, max_instance=4 --- name: GRID M60-2B4
mdev_type: nvidia-21 --- description: num_heads=1, frl_config=60, framebuffer=8192M, max_resolution=1280x1024, max_instance=1 --- name: GRID M60-8A
mdev_type: nvidia-22 --- description: num_heads=4, frl_config=60, framebuffer=8192M, max_resolution=5120x2880, max_instance=1 --- name: GRID M60-8Q
mdev_type: nvidia-238 --- description: num_heads=4, frl_config=45, framebuffer=1024M, max_resolution=5120x2880, max_instance=8 --- name: GRID M60-1B4
For this demonstration, we’re going to use the nvidia-22 option, so we’ll have a vGPU per physical GPU. In this case, our node has two physical GPUs, so we need to pass a unique uuid number to specify their respective paths by running the following command twice:
# echo `uuidgen` > /sys/class/mdev_bus/0000:3e:00.0/mdev_supported_types/nvidia-22/create
# echo `uuidgen` > /sys/class/mdev_bus/0000:3d:00.0/mdev_supported_types/nvidia-22/create
Now that the vGPU devices are created, we can expose those vGPUs devices to OpenShift Virtualization, by modifying the Hyperconverged object. We first need to create the following file:
$ cat << EOF > ~/kubevirt-hyperconverged-patch.yaml
spec:
permittedHostDevices:
mediatedDevices:
- mdevNameSelector: "GRID M60-8Q"
resourceName: "nvidia.com/GRID_M60_8Q"
EOF
Next, we can merge the code with the existing kubevirt-hyperconverged configuration:
$ oc patch hyperconverged kubevirt-hyperconverged -n openshift-cnv --patch "$(cat ~/kubevirt-hyperconverged-patch.yaml)" --type=merge
hyperconverged.hco.kubevirt.io/kubevirt-hyperconverged patched
Applying this configuration in the node may take some time. Run the following command until the GPU statement is shown. In this case, we have two physical GPU cards, so two devices are shown next to the vGPU name:
$ oc describe node| sed '/Capacity/,/System/!d;/System/d'
Capacity:
cpu: 24
devices.kubevirt.io/kvm: 1k
devices.kubevirt.io/tun: 1k
devices.kubevirt.io/vhost-net: 1k
ephemeral-storage: 936104940Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 131561680Ki
nvidia.com/GRID_M60_8Q: 2
pods: 250
Allocatable:
cpu: 23500m
devices.kubevirt.io/kvm: 1k
devices.kubevirt.io/tun: 1k
devices.kubevirt.io/vhost-net: 1k
ephemeral-storage: 862714311276
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 130410704Ki
nvidia.com/GRID_M60_8Q: 2
pods: 250
Create virtual machine
At this point, the cluster configuration is complete and the node is ready to recognize and use the GPU. Therefore, we can deploy the virtual machine that is going to use the vGPU resource. As stated in the beginning of this blog, we are going to deploy a Fedora 35 VM using the wizard provided by the web console.
Navigate again to the web console and select the Workloads section on the left side of the page. There, select the Virtualization option. Then, you’ll see different tabs. Click on Virtual Machines and select Create Virtual Machine. Different operating systems will be shown. In this case, select Fedora 33+ VM and then click Next.
In the boot source section, at the bottom, select Customize Virtual Machine. Complete the following fields and then advance to the next sections by clicking Next:
- Name: write your preferred name for the virtual machine.
- Boot Source: select Import via URL (creates PVC).
- URL: paste the URL of a qcow2 image that is accessible from the node. For example: https://download.fedoraproject.org/pub/fedora/linux/releases/35/Cloud/x…
- Flavor: choose the option Custom. Indicate 32 GiB of memory and 12 CPU cores.
- Workload Type: keep the default option Server.
- User: complete the field with your preferred user name.
- Password: complete the field with the password we’ll be using to log into the VM.
- Hostname: write a hostname for the virtual machine.
- Authorized SSH key: paste the SSH key stored in the ~/.ssh/id_rsa.pub file.
- SSH access: make sure the Expose SSH access to this virtual machine box is checked.
- Uncheck the Start virtual machine on creation box.
Check if everything is properly configured and then click Create Virtual Machine. The VM provisioning will start. Select See virtual machine details to follow the VM deployment. Wait a few minutes until you see Status: Running:

Before accessing the VM we need to add the statements needed for passing the vGPU configured. Click on the VM name (in my case fedora) and you’ll see some information and graphics about the virtual machine status. Navigate to the YAML tab and add the following commands in the devices resource:
devices:
gpus:
- deviceName: nvidia.com/GRID_M60_8Q
name: GRID_M60_8Q
When added, click the Save button and then Reload. To apply the new device configuration, in the upper-right corner, deploy the Actions section and select Start Virtual Machine.
Now, we can access the virtual machine from the OpenShift web console or from our terminal using ssh. We’re going to use this second option. Navigate to the Details tab. Scroll down to the User Credentials part and you’ll find something similar to this:
Copy the ssh command provided, paste it into your terminal window, and you’ll be connected to the fedora virtual machine; this relies on simple nodeport access:
$ ssh fedora@api.pemlab.rdu2.redhat.com -p 32142
Last login: Wed Mar 30 04:08:20 2022 from 10.128.0.1
To complete the configuration, as root user, check that the vGPU passed into the VM is listed there:
$ sudo bash
# lspci | grep NVIDIA
06:00.0 VGA compatible controller: NVIDIA Corporation GM204GL [Tesla M60] (rev a1)
Install drivers and applications in the VM
Now, we can install the NVIDIA drivers in the virtual machine. An important point that we need to keep in mind is that, for the host we installed the vGPU drivers, but now, we need to download the GRID version for the guest.
Navigate to the official page of NVIDIA and download the proper GRID driver version in the virtual machine. In this case, we’ll use the NVIDIA-Linux-x86_64-510.47.03-grid.run file. Before running it, we also need to install all prerequisites to ensure the driver compilation and installation won’t fail:
$ sudo -i
# dnf groupinstall “Development Tools”
# dnf install elfutils-libelf-devel libglvnd-devel
Once installed all needed libraries, disable the nouveau driver permanently, modifying the GRUB menu and then, reboot the node:
# grub2-editenv - set “$(grub2-editenv - list | grep kernelopts) nouveau.modeset=0”
# reboot
Access to the VM again and run the following command to stop the Xorg server (if it was running) and switch to text mode:
$ sudo -i
# systemctl isolate multi-user.target
Now, we can start with the driver installation. Run the GRID driver file:
# bash NVIDIA-Linux-x86_64-510.47.03-grid.run
The installation screen will be shown, asking to register the kernel with DKMS. Select Yes:

When the DKMS kernel module installation finishes, we’ll see the next screen. Select Yes too:

The installation process will continue. When finished, select No when asked about allowing automatic Xorg backup. We’re not going to use it for this demo. Once the installation is complete, select OK to proceed. Then, reboot the virtual machine again to apply the changes:
# reboot
Now, we can install the NVIDIA CUDA Toolkit, which provides some graphical examples to test the vGPU. Firstly, we need to check the Toolkit version compatible with our driver version here. For the driver we installed, we need to download the NVIDIA CUDA Toolkit 11.6.2 here. Access the virtual machine and paste the download command provided:
Run the file to install it:
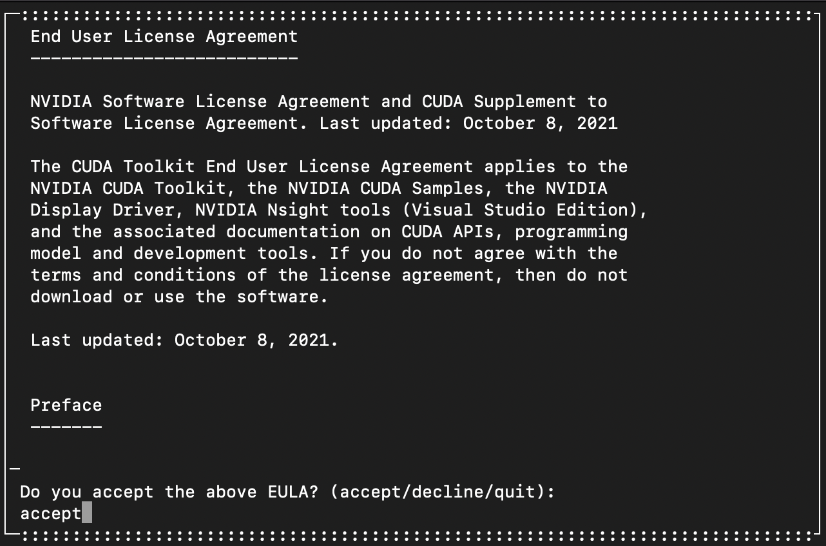
$ sudo sh cuda_11.6.2_510.47.03_linux.run
You will see the Toolkit License Agreement window. Write accept:
Important: The CUDA installation will automatically opt to install the NVIDIA driver, but this will be the non-GRID driver, which is not what we need, and will likely break the installation if we proceed with it. In a previous step we installed the correct GRID driver and therefore it’s already installed and loaded, so we need to uncheck the Driver box. Then navigate to the Install option:
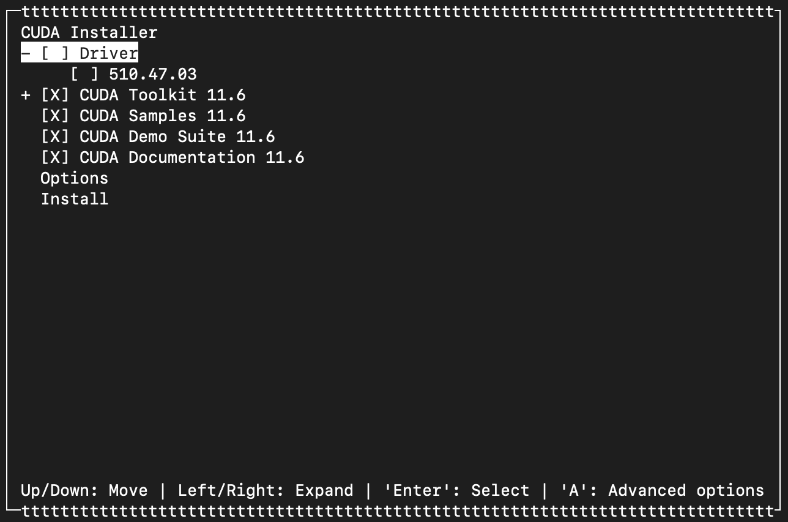
When finished, make sure that the variables $PATH includes /usr/local/cuda-11.6/bin and $LD_LIBRARY_PATH includes /usr/local/cuda-11.6/lib64. Run the following commands:
$ echo $PATH
/home/cloud-user/.local/bin:/home/cloud-user/bin:/usr/local/cuda-11.6/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/var/lib/snapd/snap/bin
$ echo $LD_LIBRARY_PATH
/usr/local/cuda-11.6/lib64
Once the installation is complete, we can check the configuration by running the following command. Make sure you don’t see any N/A value in the header:
$ nvidia-smi
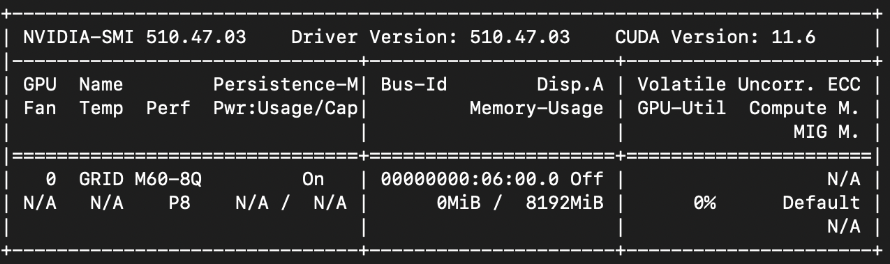
At this point, we’re seeing that everything is configured correctly. Now we can fire up our preferred applications to test the vGPU acceleration. CUDA Toolkit also provides some examples to test the GPU card. Download the Samples from the official GitHub repository here. Run the next command:
$ git clone https://github.com/NVIDIA/cuda-samples.git
Before launching the applications we’re going to install some dependencies and libraries:
$ dnf install gcc-c++ mesa-libGLU-devel libX11-devel libXi-devel libXmu-devel freeglut freeglut-devel -y
Validation
We can validate the installation by running some CUDA samples. One of the most basic samples we can use to verify the use of the vGPU is deviceQuery. Navigate to the path where the app is stored:
$ cd cuda-samples/Samples/1_Utilities/deviceQuery
Now, we can create the executable file:
$ make
Run the application and, if everything is working fine, you’ll see something similar to this:
$ ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GRID M60-8Q"
CUDA Driver Version / Runtime Version 11.6 / 11.6
CUDA Capability Major/Minor version number: 5.2
Total amount of global memory: 8192 MBytes (8589934592 bytes)
(016) Multiprocessors, (128) CUDA Cores/MP: 2048 CUDA Cores
GPU Max Clock rate: 1178 MHz (1.18 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 2097152 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 98304 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: No
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 6 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.6, CUDA Runtime Version = 11.6, NumDevs = 1
Result = PASS
Looks great! The GPU is working fine and everything seems to be well configured so we can move ahead and try a more powerful software to test the GPU acceleration.
HashCat is an open source project meant to be one of the fastest and most advanced password recovery utilities. This software also supports CPU and GPU acceleration, which is perfect for the purpose of this blog. We can download the software from the official page.
Once downloaded, navigate to the folder created during the installation. We are going to use the benchmark option (-b) to test our hardware. We’re going to run the app twice: the first one, using the CPU and the second one, using the vGPU device. We’ll leave all other parameters by default to make the test as fair as possible.
Let’s start by listing our devices by running the following command:
$ ./hashcat.bin -I
hashcat (v6.2.5) starting in backend information mode
CUDA Info:
==========
CUDA.Version.: 11.6
Backend Device ID #1 (Alias: #3)
Name.............: GRID M60-8Q
Processor(s).....: 16
Clock............: 1177
Memory.Total.....: 8192 MB
Memory.Free......: 7592 MB
PCI.Addr.BDFe....: 0000:06:00.0
OpenCL Info:
============
OpenCL Platform ID #1
Vendor...: The pocl project
Name.....: Portable Computing Language
Version..: OpenCL 2.0 pocl 1.7, RelWithDebInfo, LLVM 12.0.1, RELOC, SLEEF, DISTRO, POCL_DEBUG
Backend Device ID #2
Type.................: CPU
Vendor.ID............: 128
Vendor...............: GenuineIntel
Name.................: pthread-Intel Xeon Processor (Skylake, IBRS)
Version..............: OpenCL 1.2 pocl HSTR: pthread-x86_64-unknown-linux-gnu-skylake-avx512
Processor(s).........: 24
Clock................: 2095
Memory.Total.........: 30042 MB (limited to 4096 MB allocatable in one block)
Memory.Free..........: 14989 MB
OpenCL.Version.......: OpenCL C 1.2 pocl
Driver.Version.......: 1.7
OpenCL Platform ID #2
Vendor....: NVIDIA Corporation
Name......: NVIDIA CUDA
Version...: OpenCL 3.0 CUDA 11.6.99
Backend Device ID #3 (Alias: #1)
Type................: GPU
Vendor.ID...........: 32
Vendor..............: NVIDIA Corporation
Name................: GRID M60-8Q
Version.............: OpenCL 3.0 CUDA
Processor(s)........: 16
Clock...............: 1177
Memory.Total........: 8192 MB (limited to 2048 MB allocatable in one block)
Memory.Free.........: 7552 MB
OpenCL.Version......: OpenCL C 1.2
Driver.Version......: 510.47.03
PCI.Addr.BDF........: 06:00.0
Results using CPU:
If we look inside the OpenCl Info section, we can identify our CPU with Platform ID #1 and Backend Device ID #2. We can test the performance using the CPU by running the following command:
$ ./hashcat.bin -b -D 1 -d 2
hashcat (v6.2.5) starting in benchmark mode
CUDA API (CUDA 11.6)
====================
* Device #1: GRID M60-8Q, skipped
OpenCL API (OpenCL 2.0 pocl 1.7, RelWithDebInfo, LLVM 12.0.1, RELOC, SLEEF, DISTRO, POCL_DEBUG) - Platform #1 [The pocl project]
==============================================================================
* Device #2: pthread-Intel Xeon Processor (Skylake, IBRS), 14989/30042 MB (4096 MB allocatable), 24MCU
OpenCL API (OpenCL 3.0 CUDA 11.6.99) - Platform #2 [NVIDIA Corporation]
=======================================================================
* Device #3: GRID M60-8Q, skipped
Benchmark relevant options:
===========================
* --backend-devices=2
* --opencl-device-types=1
* --optimized-kernel-enable
-------------------
* Hash-Mode 0 (MD5)
-------------------
Speed.#2.........: 1401.7 MH/s (16.74ms) @ Accel:1024 Loops:1024 Thr:1 Vec:16
----------------------
* Hash-Mode 100 (SHA1)
----------------------
Speed.#2.........: 1066.0 MH/s (22.91ms) @ Accel:1024 Loops:1024 Thr:1 Vec:16
---------------------------
* Hash-Mode 1400 (SHA2-256)
---------------------------
Speed.#2.........: 495.1 MH/s (24.76ms) @ Accel:1024 Loops:512 Thr:1 Vec:16
Note that the GPU device is skipped and the HashCat software is only using the Intel Xeon CPU device. As expected, the ‘hashes per second’ rate decreases as the complexity of the algorithm used increases. The interesting part here is comparing the MH/s rates under the same Hash-Mode, with the ones we’re going to obtain by running it using the vGPU device.
Results using vGPU:
We can identity the Tesla M60 vGPU in the OpenCl Info section with Platform ID #2 and Backend Device ID #3. We can test the performance using the GPU by running the following command:
$ /hashcat.bin -b -D 2 -d 3
hashcat (v6.2.5) starting in benchmark mode
CUDA API (CUDA 11.6)
====================
* Device #1: GRID M60-8Q, skipped
OpenCL API (OpenCL 2.0 pocl 1.7, RelWithDebInfo, LLVM 12.0.1, RELOC, SLEEF, DISTRO, POCL_DEBUG) - Platform #1 [The pocl project]
==============================================================================
* Device #2: pthread-Intel Xeon Processor (Skylake, IBRS), skipped
OpenCL API (OpenCL 3.0 CUDA 11.6.99) - Platform #2 [NVIDIA Corporation]
=======================================================================
* Device #3: GRID M60-8Q, 7592/8192 MB, 16MCU
Benchmark relevant options:
===========================
* --backend-devices=3
* --opencl-device-types=2
* --optimized-kernel-enable
-------------------
* Hash-Mode 0 (MD5)
-------------------
Speed.#1.........: 10094.1 MH/s (50.65ms) @ Accel:1024 Loops:128 Thr:256 Vec:1
----------------------
* Hash-Mode 100 (SHA1)
----------------------
Speed.#1.........: 4110.3 MH/s (63.83ms) @ Accel:64 Loops:512 Thr:512 Vec:1
---------------------------
* Hash-Mode 1400 (SHA2-256)
---------------------------
Speed.#1.........: 1445.4 MH/s (90.64ms) @ Accel:128 Loops:64 Thr:1024 Vec:1
This time, we can see that the skipped device is the CPU and the hardware used is the GRID M60-8Q vGPU. As seen before, the MH/s rate decreases according to the Hash-Mode. The parts to be highlighted here are the rates obtained compared with the previous attempt using CPU hardware. Let’s sort them out according to the algorithm used to see it clearly:
| Algorithm | CPU | GPU | GPU acceleration |
|---|---|---|---|
| MD5 | 1401.7 MH/s | 10094.1 MH/s | 720.13 % |
| SHA1 | 1066.0 MH/s | 4110.3 MH/s | 358.58 % |
| SHA2-256 | 495.1 MH/s | 1445.4 MH/s | 291.94 % |
Depending on the CPU processor and the GPU card you’re using, the rates obtained can be different from mine, but we should always see a huge acceleration improvement when using the GPU. Also, it should be mentioned that the MH/s rate obtained depends on many parameters and may differ for each attempt we make. However, the values obtained should be fairly similar for each try.
As we can see in the table above, we are considerably multiplying the number of iterations performed when we make use of the Tesla M60 GPU card. We tested the vGPU with a password cracker software, but this feature could be used in many other scenarios: AI/ML workloads, computation, high-resolution images or video processing, etc. So, there are countless possibilities where we can use vGPU acceleration in virtual machines.
What’s next?
As mentioned at the beginning of the blog, although we have deployed a Single Node OpenShift instance on bare metal, the process followed is completely valid for many other topologies. OpenShift can be deployed on our own existing infrastructure or on different Cloud platforms such as AWS, Azure, IBM Cloud, etc...
Ready to learn more? Check out all supported platforms for OpenShift clusters, by visiting the Installation section.
Depending on the GPU device we’re using, we’ll need to download the corresponding drivers and CUDA Toolkit version. If you have any concerns about the installation, make sure to check the official NVIDIA documentation. Finally, to test our vGPU performance, CUDA Toolkit provides numerous graphical samples you can try out. Go to the official GitHub repository and find the one that suits you best!
About the author
More like this
Can't patch fast enough? Zero trust as a last line of defense
Increasing hardware costs? Get more from your VM estate with Red Hat OpenShift Virtualization
Infrastructure At The Edge | Compiler
Open Curiosity | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds