

Introduction
This document describes a conceptual reference design for performing Machine Learning Operations (MLOps). MLOps is defined as the set of practices, organizational processes, and technical capabilities to enact the full operational lifecycle of a machine learning model in an application.
Studies have shown that best practices are necessary for organizations to successfully scale and implement machine learning. In a global study conducted by McKinsey on artificial intelligence, it was shown that high AI performers more frequently implemented best practices such as utilizing standard frameworks, using automated tools to produce models, and refreshing models based on well defined criteria. Algorithmia 2020 state of machine learning emphasizes the importance of deployment speed, arguing that even 10 days can be too late for a machine learning insight to be useful.
Speed, repeatability, and standardization are some of the key elements in MLOps. To elucidate these concepts, this reference design illustrates the workflow for an end-to-end operational lifecycle of a machine learning application using MLOps. In addition, the reference design provides deployment strategies that leverage this workflow.
A core advantage of this reference design is its flexibility. You can implement the design using tools of your choice. Open Data Hub is a community project that provides an ecosystem of open source tools that can be leveraged to build using this design. Red Hat also offers a cloud managed service that combines ISV technology with open source tools to build and deploy models using a MLOps workflow.
Overview
Machine learning is a subset of the larger field called artificial intelligence and employs the use of computer algorithms to learn from historical data in order to make future predictions. In a typical workflow, a data scientist will train a machine learning model and then deploy the model for inferencing. During training, a computer algorithm is applied to a training data set that produces a machine learning model. During inferencing, a model returns predicted results when given live input data.
The two most common machine learning approaches are supervised and unsupervised learning. With supervised learning, organizations can tackle use cases such as computer vision, natural language processing, and predictive analytics. With unsupervised learning, organizations can tackle use cases such as clustering and categorization problems.
The process to take an experimental model and put it into a production system can be a significant challenge for organizations. Without a standardized approach, machine learning models may not make it into production and create tangible results, or models may underperform while running in production, producing inaccurate or misleading results.
Machine Learning Operations (MLOps) was created to tackle this challenge. DevOps and GitOps are a collection of philosophies, practices, and tools used to help deliver high-quality applications and services in the IT world. MLOps seeks to apply the learnings from DevOps and GitOps to machine learning development processes to efficiently and effectively deliver machine learning models into a production system.
DevOps is a practice that pushes organizations to eliminate barriers between teams, improve collaboration, deliver new features more frequently, and improve reliability and observability of production systems. Organizations successful in leveraging DevOps often form a delivery team with all of the necessary skills to deliver a solution.
GitOps is an additional set of philosophies built on top of the DevOps practice of delivering solutions as code that makes Git a central source of truth for all resources the team controls. Git becomes the central hub for any configurations of infrastructure, application source code, application configuration, and pipeline configuration across all environments. One major difference between DevOps and GitOps is a strong preference for declarative resource management, in which developers define the end state goal of an object, versus imperative tools in which developers define specific instructions on how something is done.
MLOps attempts to incorporate the philosophies of DevOps and GitOps to improve the lifecycle management of a ML application or service. MLOps teams should have the following characteristics:
- Collaboration - Teams should be constructed of individuals with a variety of skill sets beyond just data science and should actively collaborate on the problem across domain
- Repeatability and Automation - Teams should leverage CI/CD pipelines to allow for easy retraining, testing, and deployment of components of the ML applications
- Single Source of Truth - Teams should leverage Git as a central source of truth for all code and configuration for all parts of the ML process, including data ingestion and processing metadata, model development and training, the model serving microservice, and pipelines
- Observability - Applications should capture metrics across the entire lifecycle of the application, and teams should leverage that data to inform decision making
- Security - Teams should incorporate security best practices at all levels of the development process, including specialized security considerations unique to ML training and deployment
Reference Design
Figure 1 below shows the end-to-end reference design for MLOps. It is important to emphasize that the MLOps lifecycle is an iterative, not linear, process. In DevOps, the conditions for reverting back to an earlier stage may include a failing test or error in compilation. MLOps inherits DevOps conditions and adds more that are unique to machine learning such as offline model validation and model drift.
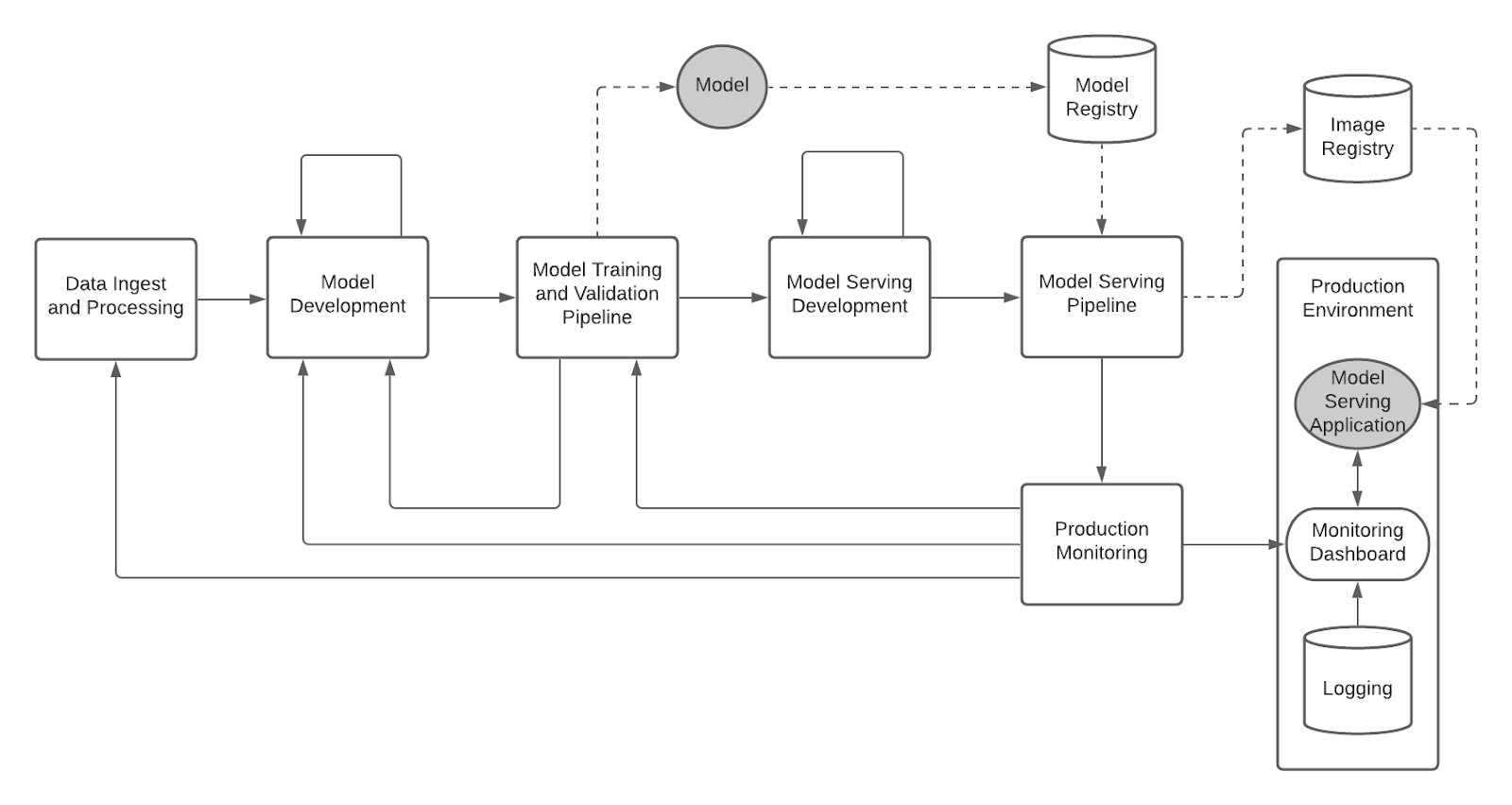
Figure 1: Enterprise MLOps Reference Design
The reference design begins with Data Ingest and Processing in which the data engineer prepares historical or streaming data for machine learning by using techniques such as data labeling and feature engineering. The Data Ingest and Processing is also covered in a larger separate practice called DataOps. Note that the data steps included here are a subset of the larger capabilities in DataOps. The reference design focuses on the fundamental DataOps integration points in a MLOps strategy. Reference Design Details - Data Ingest and Processing provides a detailed view of the data engineering steps involved with ingest and processing.
In Model Development, the data scientist tests various machine learning algorithms and hyperparameters against the dataset until a candidate model is selected. (This is visually illustrated by the loopback line in the reference design). Reference Design Details - Model Development provides a detailed view of the specific steps involved with model development.
The model is then created in a Model Training and Validation Pipeline that uses the configurations and machine learning code produced in Model Development. Note that if the pipeline fails for compilation, validation, or any other issues, then the process reverts back to Model Development in which the configurations and/or machine learning code must be corrected. (See the loopback line from Model Training and Validation Pipeline to Model Development in the reference design.) Reference Design Details - Model Training and Validation provides a detailed view of the specific steps inside of a model training and validation pipeline and the triggers that can execute the pipeline.
At this point in the MLOps lifecycle, the model is ready to be served to make inferences on future data. In Model Serving Development, the application developer or data scientist writes the code to serve the model (illustrated as an iterative process similar to Model Development). The Model Serving Pipeline uses configurations and model serving code to compile a container image that is stored in an image registry and deployed as a model serving microservice in production. Reference Design Details - Model Serving provides a detailed view of the specific steps inside of a serving pipeline and the triggers that can execute the pipeline.
Lastly, the model serving microservice is monitored with real input data in Production Monitoring for drift detection. Depending on the results, the model may need to be updated by updating the data preparation process, re-developing the model, or triggering a new model training and validation pipeline. Reference Design Details - Production Monitoring provides a detailed view of what model information is monitored and how the production data is evaluated.
Roles and Responsibilities
In MLOps, it is important to define the roles and responsibilities that are involved with the creation, deployment, and maintenance of machine learning models. It is recommended to build cross-functional teams so that team members are able to easily communicate with one another, align on common goals, and work as one unit to deliver a product or capability. Note that it is possible for an individual to take on multiple roles (for example, an individual may act as both the data engineer and data scientist). What is more important is that these role functions are covered and not missed.
Figure 2 below shows MLOps roles and how they overlay the reference design.
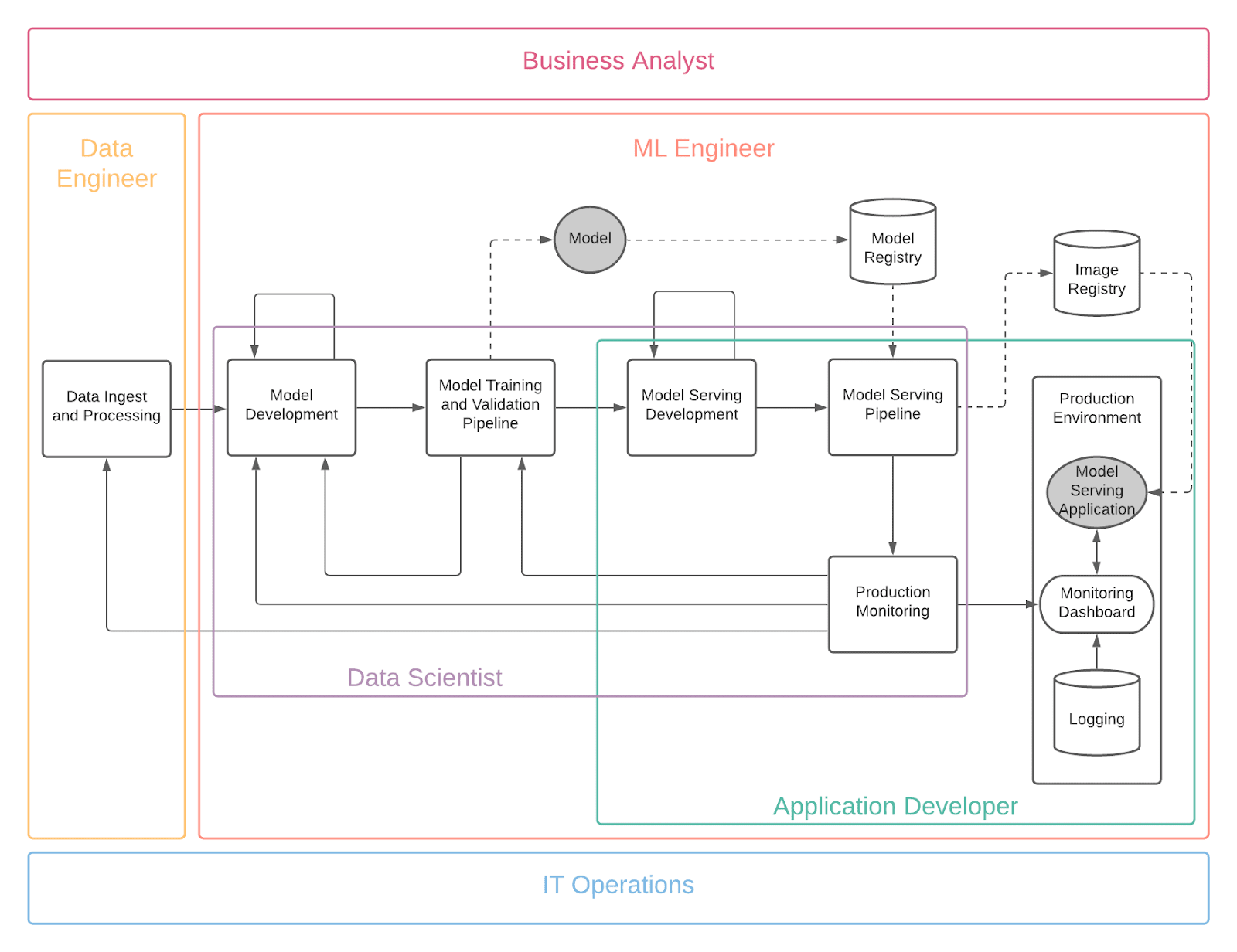
Figure 2: Roles for MLOps Reference Design
The roles and requirements are as follows:
- Business Analyst
- The role of the business analyst is to define the use case and business requirements for the AI/ML project. Business analysts are also responsible for tracking the ROI during the lifetime of the AI/ML project and conveying results to leadership in terms of value achieved and dollars captured. The business analyst must ensure the machine learning capability supports the overall solution.
- Data Engineer
- The role of the data engineer is to take in raw data and curate (clean, prepare and organize) it for the data scientist to consume. Data engineers therefore need the ability to produce and reproduce data pipelines on demand. They need services that will be able to automate the tasks of pulling in raw data and curating it. Note the data engineers have to be able to monitor the raw and curated data to make certain it is of high quality. And it is imperative that they detect and fix any issues with the data before the data scientist receives and starts work on it. Additionally, the data engineer should be the point of contact for data security and access control for audit purposes and ensuring that no unknown data sources are used.
- Data Scientist
- The role of a data scientist is to analyze a data science problem and through repeatable experiments produce an analysis using algorithms and models along with a variety of programming languages (such as Python or R) and their associated libraries. Common tools include using PyCharm, Anaconda or JupyterLab Integrated Development Environments (IDEs) with Jupyter notebooks for experimentation, and having a reproducible and shareable work environment to deliver their solutions on. Data scientists should not be overly concerned with underlying infrastructure, code repositories, and model deployment and delivery methods. Instead, their focus should be on experimenting and generating high quality models for the use case.
- Application Developer
- The focus of the application developer is to run the model serving microservice and possibly other applications that use the model serving microservice in a production environment. They spend a great deal of effort in building and maintaining the serving pipelines which automate the model rollout process into production. This step is crucial as it takes the model from the data scientist and developer workspace to a code repository and then ensures a secure and smooth delivery (usually via containerization) into the production environment. In some cases, application developers may not have the machine learning know-how to streamline the delivery of a model and can get help from the data scientist or ML Engineer.
- ML Engineer
- Machine learning engineers are experts at operationalizing machine learning models: taking models out of experiments and making them run in a production environment. They work very closely with application developers to streamline the delivery of the model via the serving pipeline and also manage the monitoring of those models. In some cases, ML Engineers may step in as the data scientist to experiment and generate models; however, their focus is less on experimentation and more on the delivery of models into an application.
- IT Operations
- IT operations is concerned with the overall usability of the platform. They are also responsible for infrastructure monitoring (that is, compute, networking and storage), platform maintenance (for example, Kubernetes), platform security, and hardware acceleration (for example, Nvidia GPUs). It is vital that the other roles work with IT Operations to ensure that anything nonstandard in the environment is vetted before use.
Reference Design Details
Data Ingest and Processing
A data engineer has to prepare data before it is usable for machine learning. Figure 3 shows the detailed view of data ingest and processing:
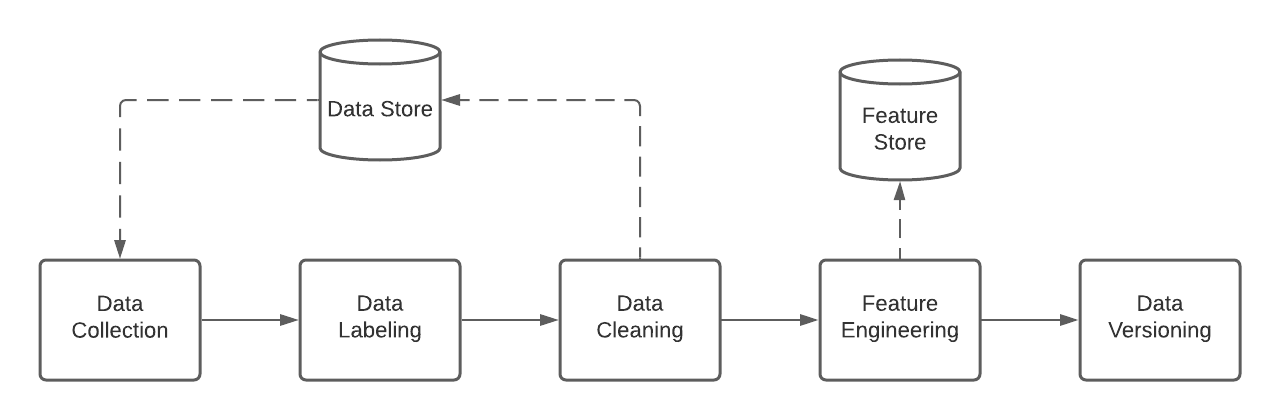
Figure 3: Detailed view of Data Ingest and Processing
The first step is data collection in which the source data is loaded from or queried against a database or data lake (for example, a SQL database or HDFS/S3). Note data collection may require joining multiple sources together to present a cohesive dataset. If possible, the data is labeled with tags that are relevant to the use case for supervised learning algorithms. (for example, image tags for classification or sentiment tags for analysis). Data is cleaned using normalization or deduplication.
Data engineers, in collaboration with data scientists, can additionally extract or generate features from the data set that can be used for machine learning. The data engineering jobs that are used to create feature vectors, and the feature vectors themselves, are stored in a feature store. During later model development activities, additional features may be developed for a specific model, which can then be abstracted back to the feature store for later reuse in other models.
Finally, subsets of data and features can be tagged or versioned for later reusability and the ability to reproduce training results.
Model Development
In model development, a data scientist writes, edits, and executes code to produce machine learning models. Figure 4 shows the detailed view of model development:

Figure 4: Detailed view of Model Development
Model development begins with experimentation: The data scientist reviews the dataset, experiments with various algorithms and tunes hyperparameters to produce different models. During this step, it can be common to have experimental instructions such as viewing a subset of the dataset in human readable format, testing multiple algorithms manually or using automated tools, and reviewing results as either charts or as a confusion matrix. Experimentation is complete once the data scientist selects a candidate model for deployment into the production environment. At the experimentation stage, it is critical that special consideration is given to the legal and ethical implications of the model’s use case and the data being leveraged to train the model.
Note the data scientist can leverage a hardware accelerator for model experimentation if necessary. In addition, the data scientist can leverage local development environments (for example, a workstation) or containerized development environments that run on a container platform. The main advantage of a containerized development environment is that the model code is able to reach other services running on the same container platform.
It is recommended to keep the experimentation code separate from production training code with the use of notebook folders or Git branches. In the production training code, experimental instructions that are not pertinent to building the model should be removed. Examples include viewing datasets in certain ways for human readability or looking at graphs to better understand results.
In addition to the training code, the data scientist creates a training pipeline configuration for their experiment. This configuration is persisted into a pipeline Git repository and includes the version, data sources, model training source code, and model registry location. The model training code is then committed into a Git repository, kicking off the next phase for model training.
Model Training and Validation
In model training and validation, a series of instructions are executed to build, validate, and produce a machine learning model in an automated and repeatable way. This stage is an iterative and repeatable process in which pipelines are run and re-run depending on certain triggers. Figure 5 shows the detailed view of model training:

Figure 5: Detailed view of Model Training and Validation
The actual work that produces a machine learning model is the training pipeline. The data scientist codifies a model experiment using a pipeline and provides configuration data about the pipeline to distinguish it from others. A training pipeline’s configuration includes the version, data sources, model training source code, and registry location. This configuration is created and persisted in a configuration store during model development.
To trigger a pipeline that creates a model, a trigger handler should be established. The most basic trigger is an update to the training code. A data scientist updates training code for various reasons such as model improvements, updates to software libraries, or bug fixes. When a data scientist merges these changes into the Git repository, the pipeline should be executed to generate an updated model.
The trigger handler should also be flexible to accept custom triggers required by the machine learning use case. For example, the model training process may trigger based off updates to the training code in a Git repository, new data being made available to the training data source, or a scheduled based job. In addition, the Production Monitoring should be able to provide feedback to the performance of the current production model as well as trigger training processes based on current performance metrics.
Within a pipeline, the first step is to clone the data scientist’s training code to the pipeline’s runtime execution environment. The features to build the model are loaded from the feature store, and the pipeline executes the training code, supplying the pipeline configuration for machine training to begin. The configuration specifies the machine learning algorithm and hyperparameters to use for training. The training code itself can leverage a CPU or hardware accelerator, and the pipeline should be able to support different types of machine learning algorithms such as supervised and unsupervised learning algorithms. The execution of training code produces a machine learning model.
The next step is offline model validation, which evaluates the performance of the model based on a corresponding metric. (For example, mean absolute error or mean squared error for regression algorithms, and accuracy, precision, or F1-Score for classification algorithms.) Typically, the dataset is split into training, test, and validation sets to assess if the model is underfitting or overfitting on the training data.
Once the model is created, it is persisted into a registry. The model registry serves as a persistent layer for storing models and model metadata. To distinguish between different versions of a model, training pipelines should store model metadata including, at minimum, the version identifier, offline validation metrics, data lineage and versioning information, and a link to the code commit that generated that version.
The last step is policy evaluation. A model is rejected from proceeding to deployment if it does not meet a policy requirement. Policies can be technical (for example, the model must meet or exceed a specific accuracy threshold) or nontechnical (for example, the model does not negatively target a specific population or does not use facial recognition at the individual level). The enforcement of the policy can be manual (that is, human authorized) or automated, depending on the maturity of the pipeline. In the manual case, the policy evaluation is completed using peer or group reviews. In the automated case, the policy evaluation is completed using programmatic tests such as performance metric tests or ethical standards tests.
Model Serving
In model serving, a model is served for use in a production environment. The model is served so that it can return inferences on input data, delivering value to the end use case. Figure 6 shows the detailed view of the model serving pipeline:
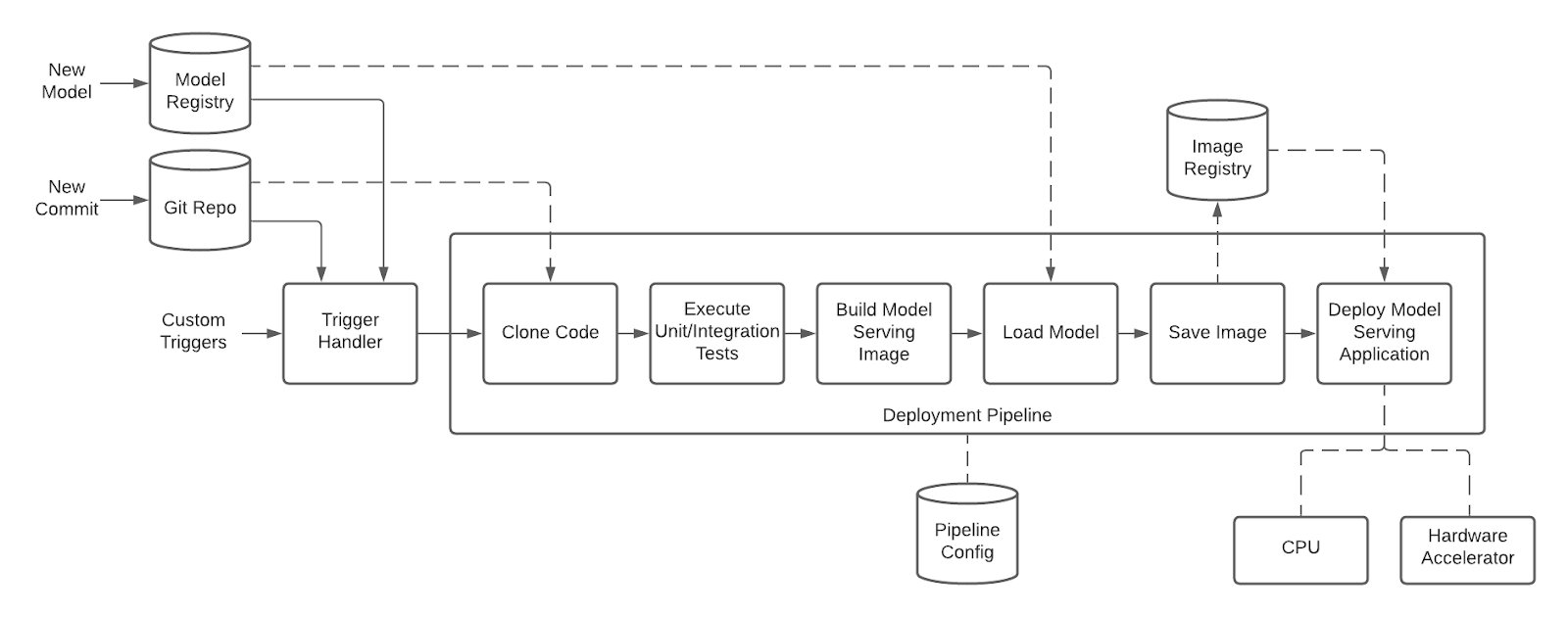
Figure 6: Detailed view of Model Serving
The model serving pipeline shares many similarities with traditional microservice application pipelines with additional integration points to the Model Registry. Within a serving pipeline, code is loaded and tested, and the pipeline generates a container image of the serving application that runs the model. Typically, the serving application either exposes the model with a REST or RPC framework (for example, gRPC) or deploys the model as a component of an embedded application (for example, for on-device inferencing). The container image is loaded in an image registry, scanned, and deployed to the production environment.
The model serving pipeline may be triggered by changes to the model serving microservice code where the developer may introduce new features, bug fixes, updates to upstream libraries, or updates to base images. Additionally, the pipeline should handle triggers where a new “best” model has been identified, allowing the latest version of the best model to be deployed.
The model serving microservice code should be managed with a separate lifecycle from the model training code, and an update to one does not necessarily require an update to the other (for example, a new feature or metric may be added to the model serving microservice without the need to retrain a new version of the model).
Production Monitoring
Production monitoring collects and stores data about model behavior for data scientists so they can learn how models behave with real production data. With this information, data scientists can evaluate models and take appropriate actions. Figure 7 shows the detailed view of production model monitoring:
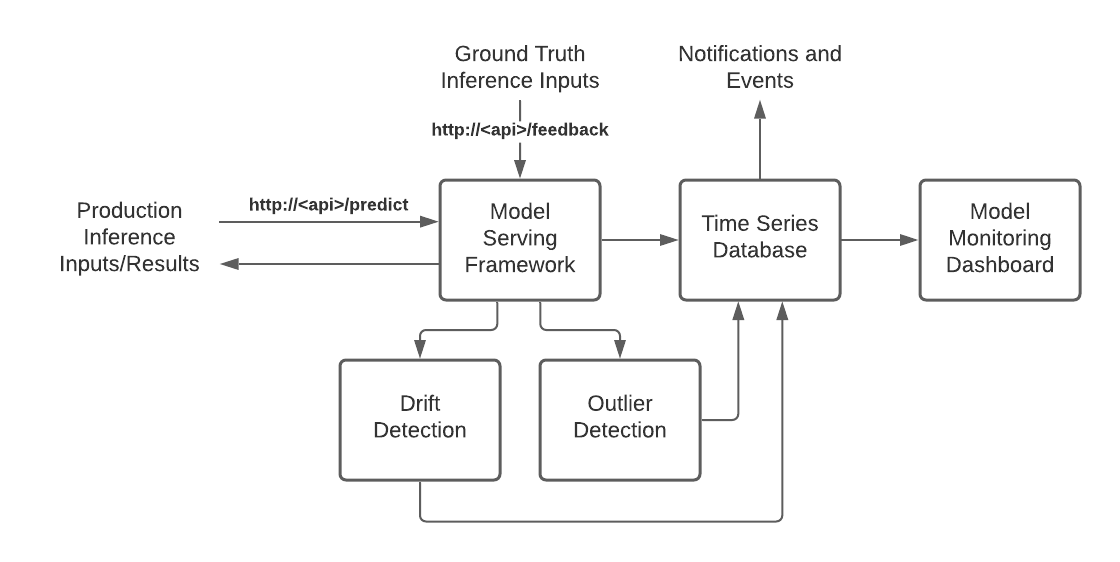
Figure 7: Detailed view of Production Monitoring
In this architecture inference inputs are provided to the model serving api’s /predict route as either a batch or streamed input. The model serving framework processes the input using the machine learning model and returns the result of the prediction.
Within the model serving framework, metrics, including custom metrics, can be collected and recorded to the time series database. Additionally the model serving framework can pass the inputs to separate drift and outlier detection frameworks to record additional metrics to the time series database.
In some cases where a ground truth, or a known value of a predicted item, can be measured at a later point in a process, that ground truth value may be provided back to the model serving framework as process feedback. One example where ground truth values may be available is in a manufacturing process where the model is attempting to predict a yield volume of a product based on variables that may be adjusted in the process. Once the process has completed a real world yield volume can be measured and provided back to the model serving framework in the form of feedback. When providing feedback, the model serving framework is provided with the inputs that were used in the original prediction along with the ground truth value. The model serving framework completes the prediction using the inputs and records the results along with the ground truth value as additional metrics.
The time series database provides the capabilities to create notifications or trigger other events based on specific conditions, such as a large number of outliers or input drift which may trigger an event to either retrain the model based on newer production data (by triggering a Model Training and Validation pipeline) or notify the data scientist to update the model characteristics in Model Development. On the other hand, if the drift is due to a skew in the schema or data, then an event can be triggered to notify the data engineer to update the data preparation code accordingly.
The model monitoring dashboard provides an end user a visual representation of various metrics that are collected by the time series database in order to give an overview of the performance of the production applications.
Deployment Strategies
Risk Profiling and Production Testing Strategies
Another area where special consideration should be given to deploying a machine learning model is the production testing strategy when releasing new versions of the model and new versions of the model serving microservice. Updates to the model or model serving framework may be handled using different strategies depending on the risk profile of the use case.
The primary risk evaluation of updates to the model serving microservice should consider the integration with other components of the microservice architecture and any internal processing changes within the application. Changes to the API structure or data structure may be considered a high risk change compared to a simple bug fix and the strategy for handling those two types of changes may differ.
By contrast to traditional application code changes, the model produced from the training process is probabilistic and not deterministic, meaning that any updates to the model design, training data, or training process will impact the model performance in potentially unknown ways. While an updated model may score better in the training process, there is still a risk that inferences from the updated model may not provide correct results as observed by the previous model version. Each use case should consider the risk of an incorrect prediction and implement a production model testing strategy that fits the risk appetite of the use case. For example, if a model is being leveraged to control industrial equipment where an incorrect inference could lead to loss of life, the production testing of the model should be more rigorous when compared to a model that is being leveraged as a recommendation engine.
The maturity of a training data set may also impact the risk profile of a model change, and as a training/test data set matures, a higher confidence level in the performance of the model in production can be assumed and lower the risk profile.
The following table includes several types of changes and a baseline evaluation of their risk level:
|
Change Type |
Description |
Risk Level |
|
Model Serving Microservice - Bug Fixes |
Minor changes to code |
Low |
|
Model Serving Microservice - Library updates |
Updates to third- party libraries |
Low |
|
Model Serving Microservice - Base Image Update |
Updates to the underlying base image the application is built on |
Low |
|
Model Serving Microservice - Feature Enhancements |
Changes to introduce new features such as additional metrics |
Medium |
|
Model Serving Framework - API Change |
Changes to API and integration points with external applications |
Medium |
|
Model - Minor Training Dataset Change |
Small additions to the training data set to cover specific cases or introduce updated production data |
Low |
|
Model - Major Training Dataset Change |
Major changes to the dataset which include restructuring data, changing labels, or replacing a large portion of the dataset |
Medium |
|
Model - Hyperparameter Tuning |
Changes to hyperparameters such as training epochs, learning rate, or any other hyperparameters that may impact model accuracy or potentially introduce over/under fit issues |
Medium |
|
Model - Architecture or Model Type Change |
Changes to the model type (for example,. moving from Random Forest to Gradient Boosting) or changes within the model architecture (for example, adding additional layers) |
High |
Three main production testing patterns exist that allow for mitigating risk in new deployments: shadow test pattern, A/B test pattern, and canary test pattern.
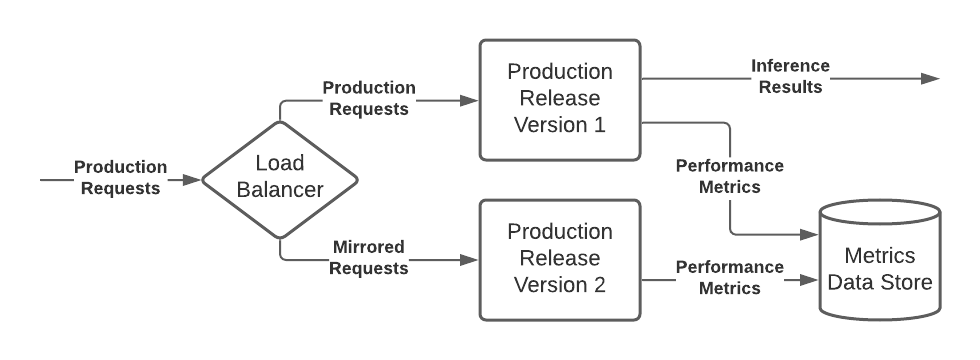
Figure 8: Shadow Testing Pattern
Shadow test patterns provide the most risk averse testing option and should be leveraged in the case where there is a low tolerance for unpredictability in models. A shadow test pattern allows the production requests to be mirrored to a second deployment of the model, and all requests are processed by both versions of the model, and metrics are recorded for each model. However, only the original model’s inference results are returned to client applications.
The shadow testing pattern allows the new model to process all production data and compare the results to ensure no abnormal behavior without the risk of impacting production processes.

Figure 9: A/B Testing Pattern
A/B testing pattern routes a random subset of production requests to a secondary model for inference and records the results to the metrics data store. Generally, the traffic is split so that only a small subset of the data is sent to the secondary model to gather a statistically significant amount of data from the results.
The A/B testing pattern is helpful for allowing a subset of production data to be processed using the secondary model, while ensuring that if the results in production are poor, only a subset of the results are impacted. A/B testing is especially useful when the end goal of a model is not simply an accurate prediction and instead hopes to influence the results of a process or decision downstream of the prediction. A/B testing is an important step in determining that the model impacts the desired result (causality) and that the model is not simply finding a correlation to the desired outcome.
Canary testing follows a simplified rollout strategy that allows for the new version of the production application to be rolled out alongside the current production model, a simple validation that the new version of the production application is working as expected, and the hold version is removed. Canary testing provides the lowest level of production validation.
Next Steps
There are unique challenges in the machine learning process that can inhibit an organization’s ability to deploy models into production. To overcome these challenges, the MLOps reference design explains in detail how to actuate the entire lifecycle of a machine learning model and its serving application. It illustrates the overall lifecycle, the organizational roles required to enact that lifecycle, and the technical steps involved at every stage in the machine learning process.
To learn more about best practices and successful use cases for deploying AI/ML in production, read our e-books: Top considerations for building a production-ready AI/ML environment and Advance your business with AI and ML. To kickstart your MLOps journey, reach out to Red Hat Consulting Services using this form.
About the authors
John Hurlocker is a Senior Principal Architect in the Global Services AI Practice. Since joining Red Hat in 2004, he has a long history of empowering clients with the Red Hat portfolio, specializing in business automation and middleware. For the past 5 years, he has partnered with clients to build and scale their foundational AI platforms and MLOps practices.
More like this
From automatic CI/CD to autonomous agentic workflows: Continuous AI with Red Hat OpenShift
Accelerate and upskill with Red Hat AI training and certification
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds