
Don't you love it when life is good?
No stress, just happiness.
I mean, all the many virtual machines in the cluster are running, none are down. I know I can enjoy my morning beverage and kick back working on community projects that help others throughout the world. I am able to make a potentially global impact.
It makes me proud.
Life does not get much better than this.
But little do I know, some of the applications running in the users virtual machines are having issues. I have a group of users and managers panicking all around me because of the impact to business, a couple are even in tears. Total chaos. My peaceful happiness is no more.
If only the issues had been known earlier, maybe they could have been fixed before they became a problem. And more importantly, maybe I could have enjoyed my morning beverage in peace. Now my morning is ruined and I am no longer helping to make the world a better place. It's a horrible day and I am sad.
I know it is too late to salvage today, but maybe I can implement a way to monitor the applications within virtual machines on the cluster. Something to gather user-defined metrics on the applications would be ideal.
After a little research and reading (you have to love the OpenShift documentation) I realize the Prometheus cluster monitor can do this for me. It is fairly easy to configure and I can let the users set up monitoring of the metrics of their own applications that they deem important.
I am a GENIUS! Yes, all uppercase GENIUS because I have just pushed the responsibility of application monitoring back to the users who run the applications. It makes perfect sense, after all, they should be the experts of their application and know what is important to monitor.
This is great! I can already see myself enjoying my morning beverage tomorrow and making the world a better place! I love it!
Enabling User Workload Monitoring
By default, the cluster only monitors the cluster platform and does not monitor user-defined projects. But the monitoring of user-defined projects can be easily enabled.
As a cluster administrator I can enable the monitoring by adding the enableUserWorkload: true line to the cluster-monitoring-config ConfigMap. The ConfigMap I will use is below, but some clusters may already have this ConfigMap with other options enabled. So applying this to those clusters could remove other existing options. It is always a good idea to query the cluster to see if a ConfigMap exists and what it contains before recklessly applying a ConfigMap. But I like living on the edge and throwing caution to the wind. (But seriously, I know I don't have this ConfigMap.)
# configmap-cluster-monitoring.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
enableUserWorkload: true
I apply the ConfigMap.
$ oc apply -f configmap-cluster-monitoring.yaml
To verify it is working, I check that the prometheus-operator, prometheus-user-workload and thanos-ruler-user-workload pods are running in the openshift-user-workload-monitoring project. It might take a short while for the pods to start.
$ oc get pod -n openshift-user-workload-monitoring
NAME READY STATUS RESTARTS AGE
prometheus-operator-5bd97d66bc-jv9mc 2/2 Running 0 12d
prometheus-user-workload-0 5/5 Running 0 12d
prometheus-user-workload-1 5/5 Running 0 12d
thanos-ruler-user-workload-0 3/3 Running 0 12d
thanos-ruler-user-workload-1 3/3 Running 0 12d
Create a Cluster Service
At least one cluster Service must be created to expose the data from the virtual machines. The program I am going to use to present the data uses port 9100/tcp in the virtual machine. I am only creating one cluster Service, but multiple cluster Services could be created if desired.
I will use a label called monitor on my virtual machines' pods as a selector for the cluster Service. I need to create the cluster Service within the dynamation project namespace and is configured to look at port 9100/tcp of any virtual machines' pod that is tagged with the monitor label having a value of metrics. I also want to define a port for the Service to expose this information on. I will again use port 9100/tcp of a ClusterIP. Finally, I create a label called servicetype. This label will be used by the ServiceMonitor to match this Service.
# node-exporter-service.yaml
kind: Service
apiVersion: v1
metadata:
name: node-exporter-service
namespace: dynamation
labels:
servicetype: metrics
spec:
ports:
- name: exmet
protocol: TCP
port: 9100
targetPort: 9100
type: ClusterIP
selector:
monitor: metrics
As a cluster administrator, I create the Service.
$ oc create -f node-exporter-service.yaml
Allow Users to Monitor Services
By default, users cannot monitor user-defined projects. Granting the monitoring-edit role allows them to create, modify, and delete ServiceMonitors in a project namespace. I am wanting to allow the user rayh the ability to do this in the dynamation project namespace.
Again, as a cluster administrator, I add the monitoring-edit role to the rayh user.
$ oc policy add-role-to-user monitoring-edit rayh -n dynamation
Gathering the Application Metrics
Prometheus can easily scrape the metrics from Service endpoints that present the metrics using an HTTP endpoint ending with /metrics. This information is found in the Managing Metrics section of the OpenShift Documentation.
There is a project on GitHub called node_exporter. This project provides an executable that runs inside a virtual machine. It then exposes various metrics from inside the virtual machine to an endpoint on port 9100/tcp that can be consumed by Prometheus. It even includes a mechanism to expose custom metrics from inside the virtual machine as well.
I will use this project to expose various metrics from within the virtual machine as well as a custom metric. I already have three virtual machines created. For testing purposes, let's assume each virtual machine runs a custom application that needs to be monitored.
For simplicity, let's assume these are custom applications and we need to monitor the number of connections (network, pipes, semaphores, etc.) to each. So I cannot use a metric on the cluster to count just the network connections to the virtual machine.
Configuring the Virtual Machine
I need to download the latest version of node_exporter into the first virtual machine. I already logged into the virtual machine as the cloud-user and am using sudo to execute any commands needing escalated privileges.
I download the archive file.
I extract the executable into the /usr/bin directory.
$ sudo tar xvf node_exporter-1.3.1.linux-amd64.tar.gz \
--directory /usr/bin --strip 1 "*/node_exporter"
I create a systemd service (/etc/systemd/system/node_exporter.service) that will run the node_exporter when the system boots.
[Unit]
Description=Prometheus Metrics Exporter
After=network.target
StartLimitIntervalSec=0
[Service]
Type=simple
Restart=always
RestartSec=1
User=root
ExecStart=/usr/bin/node_exporter --collector.textfile.directory /var/tmp/metrics
[Install]
WantedBy=multi-user.target
I add the --collector.textfile.directory option to the executable so that the textfile collector will work. With this option, scripts and other programs can write files into the directory that conform to the text format of Prometheus. Any file in this directory ending in .prom will be parsed and its contents reported by node_exporter.
I enable and start the systemd service.
$ sudo systemctl enable node_exporter
$ sudo systemctl start node_exporter
I can test that node_exporter is gathering and reporting. The following lists all the enabled metrics reported by node_exporter.
$ curl http://localhost:9100/metrics
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 1.5244e-05
go_gc_duration_seconds{quantile="0.25"} 3.0449e-05
go_gc_duration_seconds{quantile="0.5"} 3.7913e-05
[ OUTPUT TRUNCATED FOR BREVITY ]
Creating a Custom Metric
Starting the node_exporter with the --collector.textfile.directory /var/tmp/metrics option enables the testfile collector and causes node_exporter to look in the /var/tmp/metrics directory for files ending in .prom. It then captures the data in the files and presents them as metrics. The data in the files must be in Prometheus text format.
Next I create a script to populate two files in the /var/tmp/metrics directory. These files will be written with random data, simulating what I would consider applications to write. In a real world scenario these files would be populated by either the application or a monitor for the application, but I am just testing.
The script I am using is below and will run until it is stopped. It will change the metrics in the two files every minute.
#! /bin/bash
# test-monitor.sh
while true
do
cat <<EOF > /var/tmp/metrics/myapp1.prom
# HELP app_connections number of connections for an app
# TYPE app_connections gauge
app_connections{app="web", name="testweb", connection_max="1024", connection_min="0"} ${RANDOM::3}
EOF
cat <<EOF > /var/tmp/metrics/myapp2.prom
# HELP app_connections number of connections for an app
# TYPE app_connections gauge
app_connections{app="db", name="testdb", connection_max="100", connection_min="0"} ${RANDOM::3}
EOF
sleep 60
done
I run this script inside the virtual machines.
$ sudo ./test-monitor.sh &
[1] 7495
Node_exporter now shows the custom metrics.
$ curl -s http://localhost:9100/metrics | grep app_connections
# HELP app_connections number of connections for an app
# TYPE app_connections gauge
app_connections{app="db",connection_max="100",connection_min="0",name="testdb"} 425
app_connections{app="web",connection_max="1024",connection_min="0",name="testweb"} 316
Exposing the Metrics to Prometheus
A cluster Service will expose the output of node_exporter to the cluster. The Service will query virtual machines based on a label selector. This selector matches a label on the pod that launches the VM. The label that specifies the virtual machines name could be used, but that is very limiting and I would need to create a Service to monitor each virtual machine. Instead, I will create a custom label that can be assigned to multiple virtual machines so that they can all be queried with a single Service.
The custom label cannot be applied directly to the pod associated with the virtual machine since a new pod is created each time the virtual machine is powered on. Setting the label in the virtual machines yaml definition under the template section will apply the label to the virtual machines pod when it is created. I will use a label called monitor with a value of metrics. This way I can have different values for different Service if desired.
spec:
template:
metadata:
labels:
monitor: metrics
I use a simple patch to add the monitor label to the templates section.
$ oc patch vm rhel8-wee-cobra --type json -p '[{"op": "add", "path": "/spec/template/metadata/labels/monitor", "value": "metrics" }]'
Now the virtual machine needs to be stopped and restarted so a new pod is created with the label applied.
$ virtctl stop rhel8-mutual-snipe
VM rhel8-mutual-snipe was scheduled to stop
$ virtctl start rhel8-mutual-snipe
VM rhel8-mutual-snipe was scheduled to start
The Service created earlier should now start gathering metrics from the virtual machine.
The Service itself can be tested using curl, but first I need the Cluster-IP address of the Service. The next few steps, used to test the Service, are done using an account with cluster administration privileges.
To start, I need the Cluster-IP of the Service.
$ oc get service -n dynamation node-exporter-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
node-exporter-service ClusterIP 172.30.226.162 <none> 9100/TCP 4d22h
The easiest way to test is to connect to a cluster node, since the node is on the same subnet as the Service, and use curl to query the Service. This needs to be done as a user with sufficient privileges.
$ oc debug node/pwk-1
Starting pod/pwk-1-debug ...
To use host binaries, run `chroot /host`
Pod IP: 10.19.3.74
If you don't see a command prompt, try pressing enter.
sh-4.4# curl http://172.30.226.162:9100/metrics
# HELP app_connections number of connections for an app
# TYPE app_connections gauge
app_connections{app="db",connection_max="100",connection_min="0",name="testdb"} 425
app_connections{app="web",connection_max="1024",connection_min="0",name="testweb"} 316
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 1.5382e-05
go_gc_duration_seconds{quantile="0.25"} 3.1163e-05
go_gc_duration_seconds{quantile="0.5"} 3.8546e-05
go_gc_duration_seconds{quantile="0.75"} 4.9139e-05
go_gc_duration_seconds{quantile="1"} 0.000189423
[ OUTPUT TRUNCATED FOR BREVITY ]
Great! Now that the Service is working I can set up a ServiceMonitor so Prometheus can gather the metrics.
The following YAML file creates a ServiceMonitor that matches against any Service with the servicetype label set to metrics. It will query the exmet port that was defined in the Service every 30 seconds.
# node-exporter-metrics-monitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: node-exporter-metrics-monitor
name: node-exporter-metrics-monitor
namespace: dynamation
spec:
endpoints:
- interval: 30s
port: exmet
scheme: http
selector:
matchLabels:
servicetype: metrics
I can create the ServiceMonitor using the rayh user.
$ oc create -f node-exporter-metrics-monitor.yaml
It could take a minute or so for Prometheus to get the first results from the ServiceMonitor.
Testing Prometheus
Using the GUI
The metrics can be easily queried using the GUI interface. I am logged in as the rayh user and viewing the dynamation project namespace. I am in the Developer view.
Under Observe, I select the Metrics tab and choose a Custom query.
I user app_connections as the query and the results show the the custom metrics I defined.
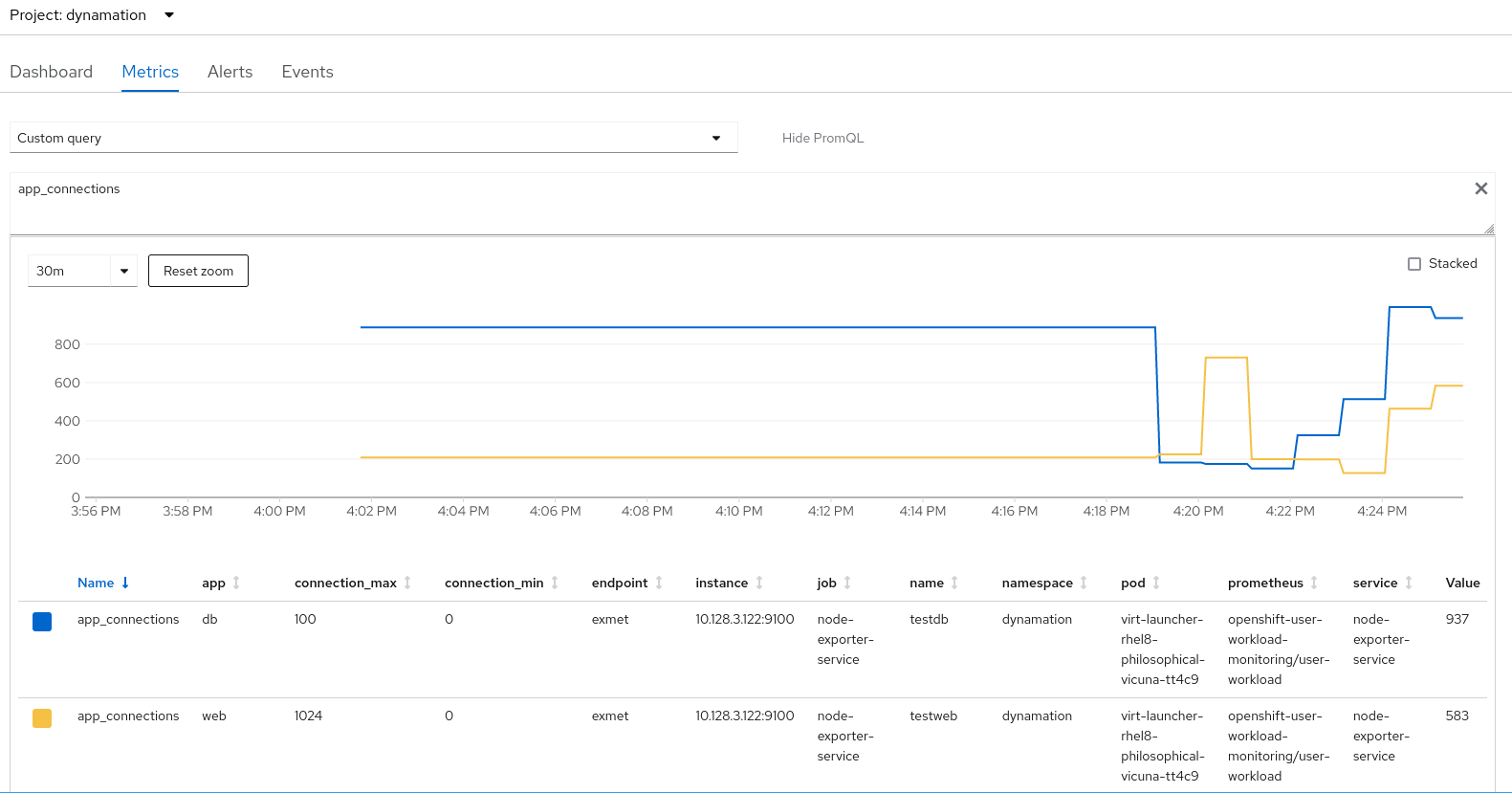
I could also query other metrics reported by node_exporter in the same way.
Using the Command Line Interface (CLI)
The metrics can also be queried using the CLI. A token and the endpoint for the Thanos querier is needed. I did not grant the user rayh with sufficient privileges to get either of these so I will get them using an account with cluster admin privileges.
First I get a token.
$ oc -n openshift-user-workload-monitoring get secret \
| grep prometheus-user-workload-token \
| head -n 1 \
| awk '{print $1 }'
prometheus-user-workload-token-kdrdc
$ oc get secret prometheus-user-workload-token-kdrdc \
-n openshift-user-workload-monitoring -o json \
| jq -r '.data.token' \
| base64 -d
eyJhbG...[Deleted for Brevity]...qCyrdKUHt0jzovjtb_WGdrSsimPXKPgFwQ6o
Then I get the Thanos endpoint.
$ oc get route thanos-querier -n openshift-monitoring -o json | jq -r '.spec.host'
thanos-querier-openshift-monitoring.apps.cluster.example.org
Now my rayh user can query the metrics. The following queries the custom app_connections created earlier, but there are many other very useful metrics to query.
$ curl -X GET -kG "https://thanos-querier-openshift-monitoring.apps.cluster.example.org/api/v1/query?" \
--data-urlencode "query=app_connections" \
-H "Authorization: Bearer eyJhbG...[Deleted for Brevity]...qCyrdKUHt0jzovjtb_WGdrSsimPXKPgFwQ6o" \
| jq .
{
"status": "success",
"data": {
"resultType": "vector",
"result": [
{
"metric": {
"__name__": "app_connections",
"app": "db",
"connection_max": "100",
"connection_min": "0",
"endpoint": "exmet",
"instance": "10.128.3.122:9100",
"job": "node-exporter-service",
"name": "testdb",
"namespace": "dynamation",
"pod": "virt-launcher-rhel8-philosophical-vicuna-tt4c9",
"prometheus": "openshift-user-workload-monitoring/user-workload",
"service": "node-exporter-service"
},
"value": [
1644423835.277,
"184"
]
},
{
"metric": {
"__name__": "app_connections",
"app": "web",
"connection_max": "1024",
"connection_min": "0",
"endpoint": "exmet",
"instance": "10.128.3.122:9100",
"job": "node-exporter-service",
"name": "testweb",
"namespace": "dynamation",
"pod": "virt-launcher-rhel8-philosophical-vicuna-tt4c9",
"prometheus": "openshift-user-workload-monitoring/user-workload",
"service": "node-exporter-service"
},
"value": [
1644423835.277,
"149"
]
}
]
}
}
Exposing the Metrics Outside the Cluster
I think I would also like to expose the metrics outside the cluster. Maybe a developer wants to do something fancy with the metrics. Maybe they need to do comparison checks between metrics in different clusters to determine if there is an issue.
I should be able to just expose the Service so a route is created. Let's try that. I will need to do this as a cluster administrator.
$ oc expose service node-exporter-service
route.route.openshift.io/node-exporter-service exposed
I need to get the FQDN assigned to the route.
$ oc get route -o=custom-columns=NAME:.metadata.name,DNS:.spec.host
NAME DNS
node-exporter-service node-exporter-service-dynamation.apps.pearl.example.org
Now I should be able to pull the metrics from outside my cluster.
$ curl -s http://node-exporter-service-dynamation.apps.pearl.example.org/metrics|grep "^node_uname_info"
node_uname_info{domainname="(none)",machine="x86_64",nodename="rhel8-coherent-muskox",release="4.18.0-305.el8.x86_64",sysname="Linux",version="#1 SMP Thu Apr 29 08:54:30 EDT 2021"} 1
I did not expect that. I thought I would get the output for all the virtual machines running node_exporter. Lets try that again.
$ curl -s http://node-exporter-service-dynamation.apps.pearl.example.org/metrics|grep "^node_uname_info"
node_uname_info{domainname="(none)",machine="x86_64",nodename="rhel8-philosophical-vicuna",release="4.18.0-305.el8.x86_64",sysname="Linux",version="#1 SMP Thu Apr 29 08:54:30 EDT 2021"} 1
Oh, the next results are from a different virtual machine. I wonder if it is just giving me the results in a round-robin fashion?
$ curl -s http://node-exporter-service-dynamation.apps.pearl.example.org/metrics|grep "^node_uname_info"
node_uname_info{domainname="(none)",machine="x86_64",nodename="rhel8-mutual-snipe",release="4.18.0-305.el8.x86_64",sysname="Linux",version="#1 SMP Thu Apr 29 08:54:30 EDT 2021"} 1
$ curl -s http://node-exporter-service-dynamation.apps.pearl.example.org/metrics|grep "^node_uname_info"
node_uname_info{domainname="(none)",machine="x86_64",nodename="rhel8-coherent-muskox",release="4.18.0-305.el8.x86_64",sysname="Linux",version="#1 SMP Thu Apr 29 08:54:30 EDT 2021"} 1
Look at that! It appears that is exactly what it is doing.
This is not ideal for me if users are wanting to monitor only their own applications. But I could just create multiple services, one for each virtual machine if I need to. I could just expose each service outside the cluster as needed. This would give them each a unique FQDN which could be desirable.
Wrapping It Up
Now that the users have ways to monitor their own virtual machines, hopefully I will be able to enjoy my morning beverage tomorrow. I think the next step will be to set up some alerting based on the metrics, but thats left for another day. But first I need to let the users test the different methods for getting metrics and let me know which they like best for their situation. And to give them time to create custom collectors to populate the .prom files for their custom metrics.
About the author
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
Storage processing accelerates VM migrations in the migration toolkit for virtualization 2.12
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds