
At this year’s Ray Summit we’re excited to showcase the infrastructure stack that we are building with IBM Research, which includes Ray and CodeFlare for generative AI distributed workloads. The technologies are introduced in open source communities like Open Data Hub and matured to become part of Red Hat OpenShift AI, which also underpins IBM watsonx.ai and IBM foundation models used by Red Hat Ansible Automation Platform. Red Hat OpenShift AI brings together a powerful suite of tools and technologies designed to make the process of fine-tuning and serving foundation models seamless, scalable and efficient. The platform provides these tools to tune, train and deploy models consistently, whether you choose to do so on-site or in the cloud. Our latest work provides multiple options to fine-tune and serve foundation models, giving data science and MLOps practitioners capabilities such as real-time access to cluster resources or the ability to schedule workloads for batch processing.
In this blog, you will learn how to seamlessly fine-tune and then deploy a HuggingFace GPT-2 model consisting of 137M parameters on a WikiText dataset using Red Hat OpenShift AI. For the fine-tuning part, we will achieve this using the Distributed Workloads stack with the underlying KubeRay for parallelization, and utilize KServe/Caikit/TGIS stack for deployment and monitoring of our fine-tuned GPT-2 foundation model.
Distributed Workloads stack consists of two major components:
- KubeRay: Kubernetes operator for deployment and management of remote Ray clusters running distributed compute workloads; and
- CodeFlare: Kubernetes operator that deploys and manages the lifecycle of three components:
- CodeFlare-SDK: tool for defining and controlling remote distributed compute jobs and infrastructure. The CodeFlare operator deploys a notebook with CodeFlare-SDK.
- Multi-Cluster Application Dispatcher (MCAD): Kubernetes controller for managing batch jobs in a single or multi-cluster environment
- InstaScale: on-demand scaling of aggregated resources in any OpenShift flavor with MachineSets setup (self-managed or managed - Red Hat OpenShift on AWS/ Open Data Hub).

Figure 1. Interactions between components and user workflow in Distributed Workloads.
As shown in Figure 1, in Red Hat OpenShift AI, the tuning of your foundation model will begin with CodeFlare - a dynamic framework that streamlines and simplifies the building, training and refining of models. Underneath that, you will harness the power of Ray, a distributed computing framework, using KubeRay to efficiently distribute your fine-tuning efforts, significantly reducing the time required to achieve an optimal model performance. Once you have defined your fine-tuning workload, MCAD will queue your Ray workload until resource requirements are met and will create the Ray cluster once there is a guarantee that all of your pods can be scheduled.
On the serving side, the KServe/Caikit/TGIS stack is composed of:
- KServe: Kubernetes Custom Resource Definition for production serving models that handles the lifecycle of model deployment
- Text Generation Inference Server (TGIS): Serving backend/server that loads the models and provides the inference engine
- Caikit: AI toolkit/runtime that handles the lifecycle of the TGIS process, provides inference endpoints and modules that handle different model types
- OpenShift Serverless (prerequisite operator): is based on the open source Knative project that enables developers to build and deploy enterprise-grade serverless and event driven applications
- OpenShift Service Mesh (prerequisite operator): is built upon the open source Istio project that provides a platform for behavioral insight and operational control over networked microservices in a service mesh.
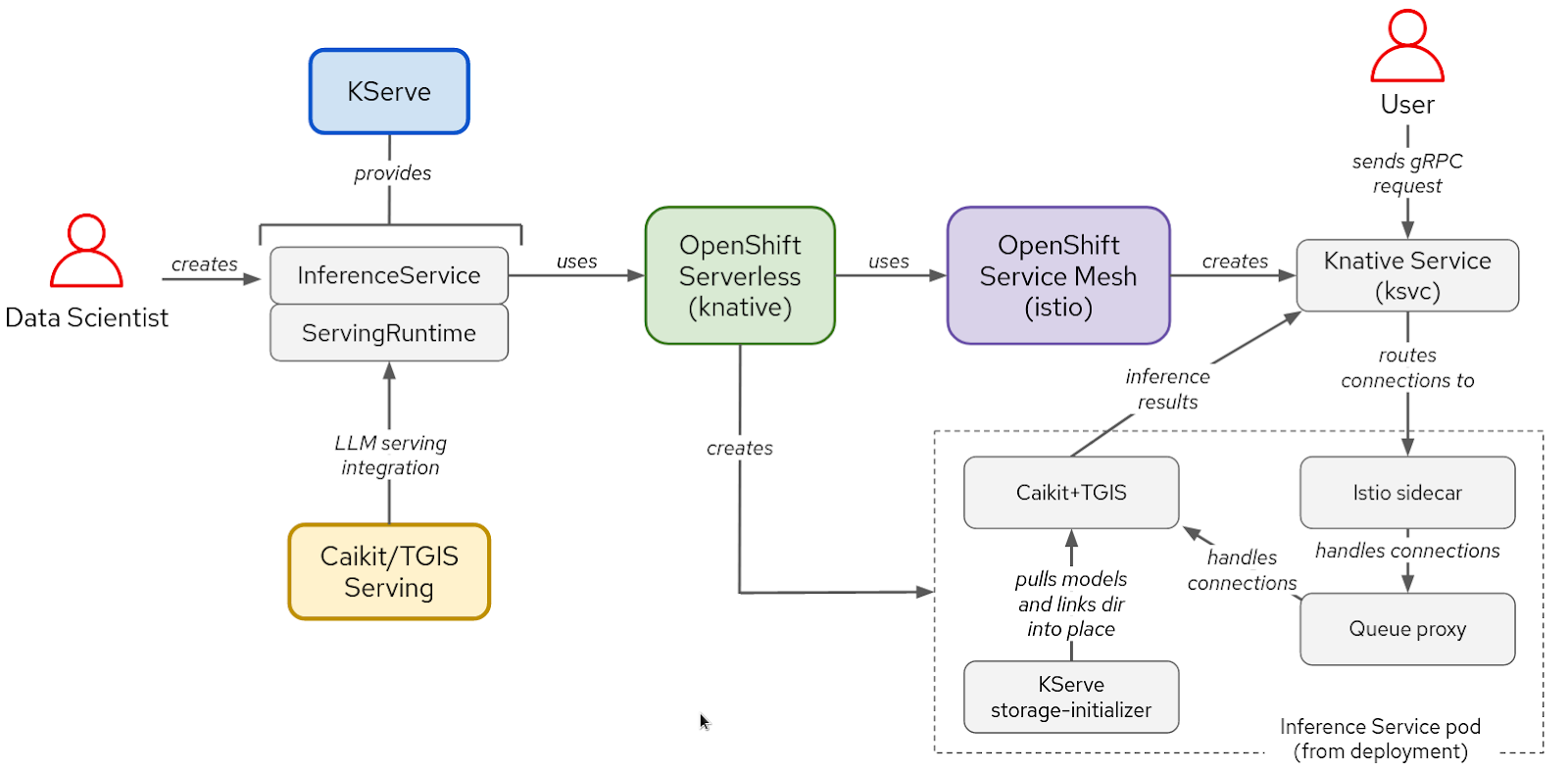
Figure 2. Interactions between components and user workflow in KServe/Caikit/TGIS stack.
Once the model is fine-tuned, you will deploy the model with Caikit/TGIS serving runtime and backend simplifying and streamlining the scaling and maintenance of your model using KServe that provides a reliable and advanced serving infrastructure. In the background, Red Hat OpenShift Serverless (Knative) will provision serverless deployment of our model and Red Hat OpenShift Service Mesh (Istio) will handle all the networking and traffic flows (see Figure 2).
Setting up the environment
This demo assumes you have an OpenShift cluster with Red Hat OpenShift Data Science operator installed or added as an add-on. The demo can also be executed with Open Data Hub as an underlying platform.
To fine-tune your model, you will need to install the CodeFlare community operator available in OperatorHub. The CodeFlare operator installs MCAD, InstaScale, KubeRay operator and CodeFlare notebook image with packages such as codeflare-sdk, pytorch and torchx included. If using GPUs, the NVIDIA GPU and Node Feature Discovery Operators will need to be installed as well.
For the model serving part, you can simply execute this script and it will install all the prerequisite operators and the entire KServe/Caikit/TGIS stack. Please set the TARGET_OPERATOR to rhods.
Although the installation instructions for both Distributed Workloads and KServe/Caikit/TGIS stacks are more or less manual here, both stacks will be available and supported in Red Hat OpenShift Data Science soon.
Fine-tuning an LLM model
You will start off with launching the CodeFlare notebook from Red Hat OpenShift AI’s dashboard (see Figure 3) and cloning the demo repository that includes the notebook and other files needed for this demo.
Figure 3. CodeFlare notebook image shown in the OpenShift Data Science Dashboard.
In the beginning, you must define the parameters for the type of cluster you would like (ClusterConfiguration) such the name of the cluster, the namespace to deploy into, the required CPU, GPU and memory resources, machine types and if you would like to take advantage of InstaScale’s autoscaling capability. If you are working in an on-prem environment, you can ignore the machine_types and set instascale=False . Afterwards, the cluster object is created and submitted to MCAD to spin up the Ray cluster.
When the Ray cluster is ready and you can see the Ray cluster details from cluster.details() command in the notebook, you can then define your fine-tuning job by providing a name, the script to run, arguments if any and list of required libraries, and submit it to the Ray cluster that you had just spun up. The argument list specifies the GPT-2 model to use and the WIkiText dataset to fine-tune the model with. The neat part of CodeFlare SDK is that you can conveniently track the status, logs and other information either via cli or view it in a Ray dashboard.
Once the fine-tuning process of the model is complete, you can see that the output of job.status() changes to SUCCEEDED and the logs in the Ray dashboard show completion (see Figure 4). With 1 Ray worker running on the NVIDIA T4 GPU with 2 CPUs and 8GB of memory, the fine-tuning of the GPT2 model took approximately 45 minutes.
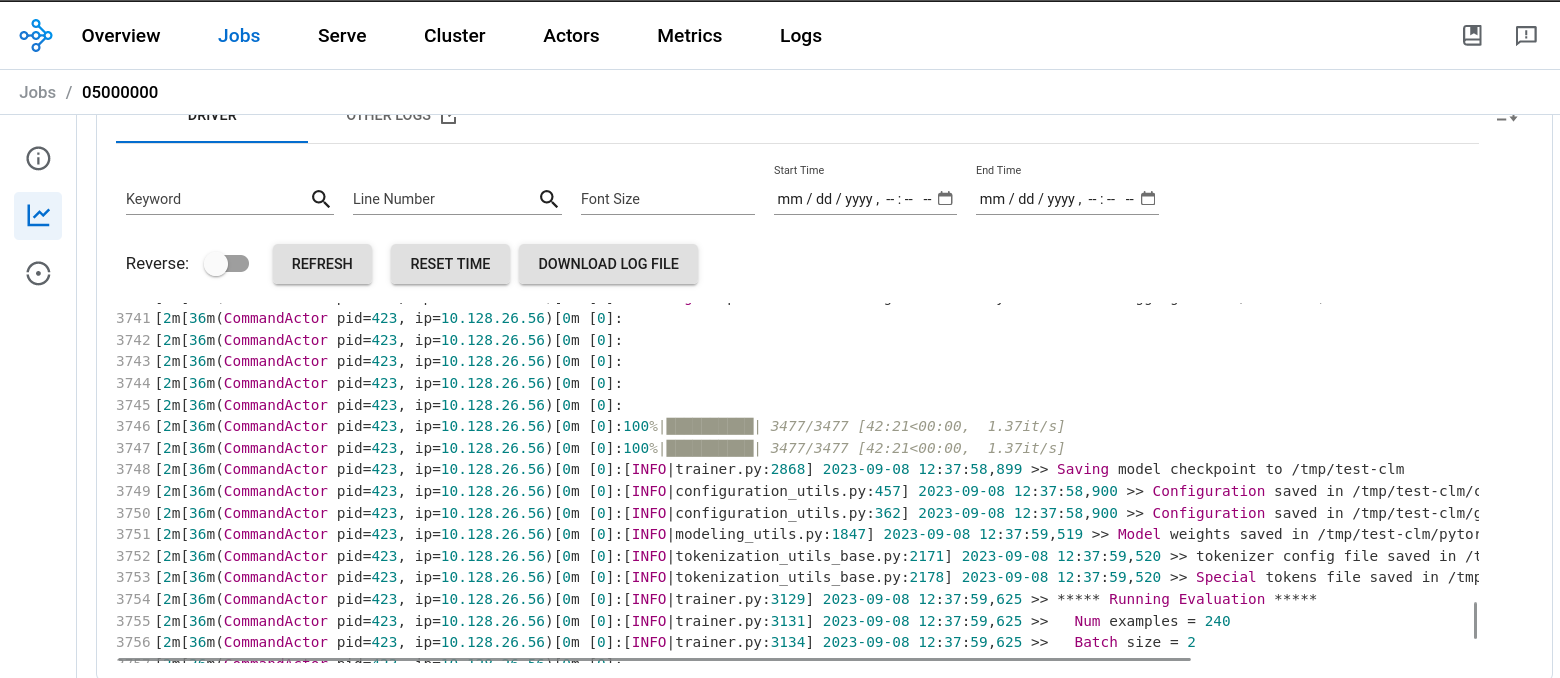
Figure 4. Logs from Ray Dashboard show completion of the fine-tuning process of the model.
Afterwards, you will need to create a new directory in the notebook, save the model there and then download it to your local environment for converting the model and uploading it to a MinIO bucket afterwards. Please note that we are using a MinIO bucket in this demo, however, you can choose to use another type of an S3 bucket, PVC or any other storage you may prefer.
Serving the LLM model
Now that you have fine-tuned your foundation model, it is time to put it to work. From the same notebook where you fine-tuned your model, you would create a new namespace where you will:
- Deploy Caikit+TGIS Serving Runtime;
- Deploy S3 data connection; and
- Deploy Inference Service that points to your model located in a MinIO bucket
A serving runtime is a custom resource definition that is designed to create an environment for deployment and management of models in production. It creates the templates for pods that can dynamically load and unload models of various formats on demand and expose a service endpoint for inferencing requests. You will deploy the serving runtime that will scale up the runtime pods once an inference service is detected. Port 8085 will be used for inferencing.
An inference service is a server that accepts input data, passes it to the model, executes the model and returns the inference output. In the InferenceService that you are deploying, you will specify the runtime you deployed earlier, enable the passthrough route for gRPC inferencing and point the server to your MinIO bucket where the fine-tuned model is located.
After verifying that the Inference Service is ready, you will then perform an inference call asking the model to complete a sentence of your choice.
You have now fine-tuned a GPT-2 large language model with the Distributed Workloads stack and successfully served it with KServe/Caikit/TGIS stack in OpenShift AI.
What’s next
We would like to thank the Open Data Hub and Ray communities for their support. This only scratches the surface of potential AI/ML use cases with OpenShift AI. If you would like to learn more about the CodeFlare stack capabilities, please check out the demo video we developed that covers the CodeFlare SDK, KubeRay and MCAD portions of this demo in more detail.
Stay tuned as we integrate the CodeFlare and KubeRay operators into OpenShift Data Science very soon and develop the UI for the KServe/Caikit/TGIS stack that was recently released in OpenShift Data Science as a limited availability feature.
About the author
Selbi Nuryyeva is a software engineer at Red Hat in the OpenShift AI team focusing on the Open Data Hub and Red Hat OpenShift Data Science products. In her current role, she is responsible for enabling and integrating the model serving capabilities. She previously worked on the Distributed Workloads with CodeFlare, MCAD and InstaScale and integration of the partner AI/ML services ecosystem. Selbi is originally from Turkmenistan and prior to Red Hat she graduated with a Computational Chemistry PhD degree from UCLA, where she simulated chemistry in solar panels.
More like this
Pluggable by design: An agent mesh for software modernization that adopts the next model release
From automatic CI/CD to autonomous agentic workflows: Continuous AI with Red Hat OpenShift
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds