
Update: The steps contained within this article describe an unsupported method for integrating OpenShift and Splunk using Fluentd as a collector and forwarder. It is recommended that the officially supported integration between OpenShift and Splunk available in versions 4.10+ that leverages Vector be used.
Observability is one of the greatest metrics of success when operating in a containerized environment, and one of the fundamental types of observability is application logging. Unlike traditional infrastructures where applications operate on relatively static instances, containerized workloads deploying into an orchestration platform, such as Kubernetes and OpenShift, operate across a fleet of underlying hosts where multiple instances of an application may be running at a given time. The ability to collect logs emitted by these applications is essential to understanding the current operating state. OpenShift provides a log aggregation solution based on the ElasticSearch, Fluentd, and Kibana (EFK) stack as an included feature that fulfills the need for having to create a similar solution of your own. However, as in the case in many organizations, existing enterprise log collection solutions may already be in place for which logs from applications running on OpenShift must also be made available.
Splunk is an enterprise logging solution, and given its popularity, integrations with OpenShift have been made available. One such option is Splunk Connect for Kubernetes, which provides a turn-key supportable solution for integrating OpenShift with Splunk. Splunk Connect leverages many of the same technologies as the out-of-the box EFK stack that is included with OpenShift such as a DaemonSet of containers that collects logs from each underlying host which are then transmitted to Splunk. While Splunk Connect is a suitable standalone option for integrating OpenShift with Splunk, there is a desire for the use of the included EFK stack while also integrating with Splunk. If both the included EFK stack and Splunk Connect were deployed simultaneously, the result would be two independent Fluentd deployments running on each underlying host. Not only does this increase the platform resource requirements, but there is also a possibility that the two may conflict with one another. Instead of running the risks involved in operating two simultaneous solutions, an alternative approach can be used to integrate OpenShift with Splunk.
The need to integrate OpenShift with an external log aggregation system has been a common inquiry. As a result, support has been available for this type of integration since OpenShift 3. The common approach is to deploy a separate instance of Fluentd that acts as a bridge (forwarder) between the Fluentd collectors provided by OpenShift and the external log aggregation system.

Splunk takes the role of the external log aggregation system in this case. In OpenShift 3, to enable this type of functionality, not only was the deployment of the forwarder required, but meticulous modification to the ConfigMap used by the OpenShift’s Fluentd was also required. The ability to automate this configuration while avoiding conflicting with the platform life cycle, such as upgrades, became a challenge.
Starting with OpenShift 4.3 and made Generally Available in OpenShift 4.6, a new approach called the Log Forwarding API was made available to not only simplify the ability to integrate with external log aggregation solutions, but to also align with many of the concepts employed by OpenShift 4, such as expressing configurations through the use of Custom Resources. A new ClusterLogForwarder resource allows for one to define the types of logs that should be sent externally to OpenShift along with the destination type. Logs collected by OpenShift are categorized into three distinct categories:
- application - Container logs generated by user applications running in the cluster, except infrastructure container applications.
- infrastructure - Logs generated by both infrastructure components running in the cluster and OpenShift Container Platform nodes, such as journal logs. Infrastructure components are pods that run in the openshift*, kube*, or default projects.
- audit - Logs generated by the node audit system (auditd), which are stored in the /var/log/audit/audit.log file, and the audit logs from the Kubernetes apiserver and the OpenShift apiserver.
OpenShift allows for logs to be sent to an instance of Elasticsearch (either OpenShift’s included instance and/or external) or several external integration points, including (but not limited to) syslog and Fluentd Fluentd. A pipeline is defined in the ClusterLogForwarder resource to associate the log type and the output. An example is shown below:
apiVersion: "logging.openshift.io/v1"
kind: "ClusterLogForwarder"
metadata:
name: instance
namespace: openshift-logging
spec:
outputs:
- name: openshift-logforwarding-splunk
type: "fluentdForward"
url: tls://openshift-logforwarding-splunk.svc:24224
secret:
name: openshift-logforwarding-splunk
pipelines:
- name: container-logs
inputRefs:
- application
outputRefs:
- default
- fluentd-forward
- name: infra-logs
inputRefs:
- infrastructure
outputRefs:
- default
- fluentd-forward
- name: audit-logs
inputSource: logs.audit
outputRefs:
- default
In the example above, a single output is defined: : forwarding to an external instance of Fluentd. . Sending logs to the Fluentd forwarder from OpenShift makes use of the forward Fluentd plugin to send logs to another instance of Fluentd. Pipelines are defined for each of the log types using a combination of the two outputs. The declarative nature of the Log Forwarding API makes it easy to specify the types of logs that should be considered for log forwarding as well as defining where they should be sent.
With an understanding of the Log Forwarding API, let’s demonstrate how it can be used to integrate OpenShift with Splunk. The first step is to have a deployment of OpenShift’s EFK stack already available. Follow the instructions on how to deploy and configure OpenShift log aggregation if the components are not already deployed. To streamline the integration between OpenShift and Splunk, a solution is available that not only configures the OpenShift Log Forwarding API, but more importantly, deploys the Fluentd forwarder instance as the bridge between OpenShift and Splunk. The solution can be found in the openshift-logforwarding-splunk GitHub repository. The repository consists of two primary components:
- Deploys a minimalistic instance of Splunk with HTTP Event Collector (HEC) input support for demonstration purposes
- A Helm chart to deploy the Fluentd forwarder and OpenShift Log Forwarding API components.
Note: This integration to enable an integration to Splunk is provided in the upstream Open Source community and is not supported by Red Hat.
To complete the demonstration, you will also need the following tools on your local machine:
- Git (Recommended but not required as the contents in the Git repository can be downloaded as an archive)
- OpenShift Command Line tool
- Helm Command line tool
With all of the prerequisites complete, and a deployment of OpenShift’s EFK stack available, ensure that you are logged into the OpenShift cluster locally using the OpenShift Command Line Interface (CLI) with elevated access.
Clone the git repository to your local machine:
$ git clone https://github.com/sabre1041/openshift-logforwarding-splunk.git
$ cd openshift-logforwarding-splunk
To deploy the demonstration instance of Splunk a script called splunk-install.sh is available to deploy a nonpersistent instance of splunk to a project called splunk. Deploy splunk by executing the following command:
$ ./splunk-install.sh
Once the script is complete, Splunk will be deployed to the splunk project and configured with an index called openshift and enabled for HEC input support. Login to Splunk by first discovering the URL of the route that was exposed:
$ echo https://$(oc get routes -n splunk splunk -o jsonpath='{.spec.host}')
The default credentials for the demonstration Splunk instance are as follows:
Username: admin
Password: admin123
Confirm the openshift index has been created by selecting Settings on the navigation bar and then select Indexes.
Now that an instance of Splunk is available, let’s deploy the log forwarding solution using the included openshift-logforwarding-splunk Helm chart contained within the repository in the charts folder. A set of opinionated values have been defined by default in order to demonstrate the integration of these components. Fortunately, since the manifests that are applied to the OpenShift environment can be modified at runtime, the values can be configured to suit your individual environment. In particular, the following values are available to be set as needed:
|
Value |
Description |
|
openshift.forwarding |
A dictionary describing which types of logs should be send to OpenShift’s integrated Elasticsearch instance and Splunk |
|
forwarding.fluentd.caFile |
Certificate to secure communication between OpenShift’s Fluentd and the Fluentd forwarder. A default certificate has been provided by default and can be replaced with another certificate if desired. |
|
forwarding.fluentd.keyFile |
Private key to secure communication between OpenShift’s Fluentd and the Fluentd forwarder. A default key has been provided by default and can be replaced with another certificate if desired. |
|
forwarding.fluentd.persistence.enabled |
Whether to enable persistence for the buffer between the Fluentd forwarder and Splunk. By default, this is set as false. |
|
forwarding.splunk.token |
HEC token to communicate between the Fluentd forwarder and Splunk. This value is required. |
|
forwarding.splunk.index |
Name of the Splunk index to send logs to. By default, this value is openshift. |
|
forwarding.splunk.protocol |
The protocol to communicate between the Fluentd forwarder and Splunk. By default, this value is https. |
|
forwarding.splunk.host |
Hostname of the Splunk instance. |
|
forwarding.splunk.port |
Splunk HEC port number. By default, this value is 8088. |
|
forwarding.splunk.insecure |
Verification of SSL certificates is disabled. By default, this value is true. |
|
forwarding.splunk.caFile |
The SSL certificate for Splunk. By default, this value is not set. |
A full list of available values can be found in the values.yaml file in the chart directory.
One important point to note in contrast to the deployment of a comparable solution for OpenShift 3 is that the Fluentd image that is included with OpenShift contains all of the necessary plugins in order to integrate with Splunk, particularly the splunk_hec plugin. This avoids having to build and maintain a separate Fluend image. The configuration used by the Fluentd forwarder is defined in a ConfigMap and injected into the container at runtime.
As for this demonstration, the only required value that must be defined at instantiation is the HEC token that allows the Fluentd forwarder to communicate with splunk. The default value can be found by locating the hec_token key within a file called splunk_install.yaml.
Now, install the helm chart to the OpenShift environment by substituting the hec_token located in the step above:
$ helm upgrade -i --namespace=openshift-logging openshift-logforwarding-splunk charts/openshift-logforwarding-splunk/ --set forwarding.splunk.token=<token>
The Helm chart will be deployed to the OpenShift environment. Confirm the openshift-logforwarding-splunk pods are running:
$ oc get pods -n openshift-logging
Now that the ClusterLogForwarder instance has been deployed, logs will begin flowing from OpenShift’s Fluentd via the log forwarding instance of Fluentd to Splunk. The Log Forwarding API will automatically restart OpenShift’s Fluentd instances automatically so that they pick up the updated configurations.
While you could view logs that are currently being forwarded to Splunk from OpenShift, let's deploy a sample application to validate the solution. Create a new project and then deploy an example .NET Core application:
$ oc new-project dotnet-example
$ oc new-app dotnet-example
After a few minutes, the automatically triggered Source-To-Image build will complete and the new application will be deployed. You can track the status of the build and deployment within the dotnet-example project and navigate to the exposed application once it is deployed.
Now, navigate to Splunk to verify that logs have been successfully forwarded. Select the Search and Reporting App and enter the following query into the search field:
index=openshift kubernetes.namespace_name=dotnet-example | table _time kubernetes.pod_name message | sort -_time
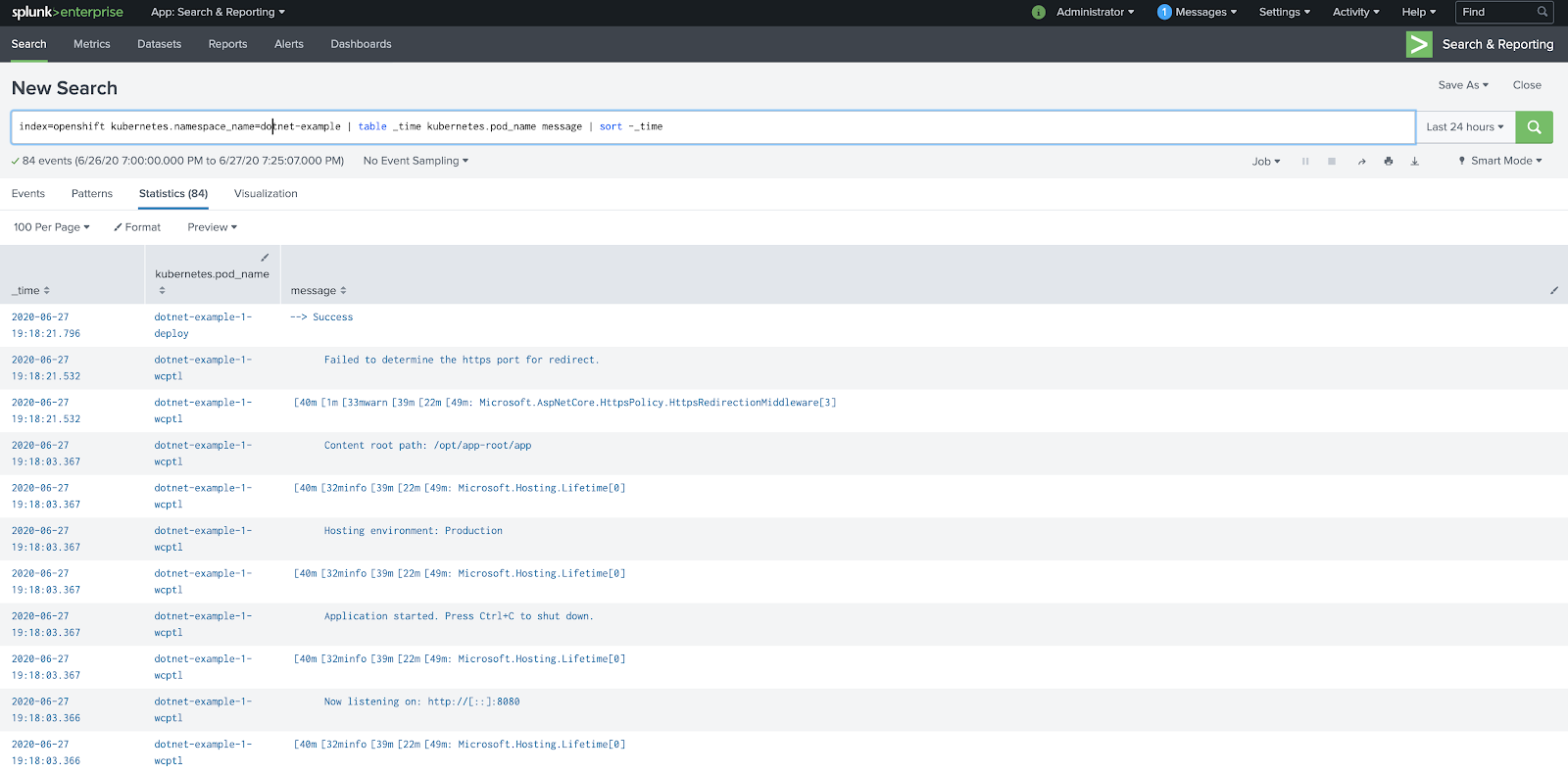
The search results have been limited to those only from the dotnet-example namespace and sorted by date. The first set of results are from the running application container. Navigating further down, the output from the image build can be seen. Take a few minutes to search through some of the other logs that have been sent from OpenShift to Splunk, such as those pertaining to the OpenShift infrastructure set of resources.
As emphasized by assets created within this article, the integration between OpenShift and Splunk is easier, thanks to OpenShift’s Log Forwarding API. Combined with a Helm chart to manage the lifecycle of the Fluentd forwarding instance, the entire solution can be deployed with ease empowering both OpenShift administrators and end users to focus on their business-critical tasks instead of managing complex configurations.
About the author
Andrew Block is a Distinguished Architect at Red Hat, specializing in cloud technologies, enterprise integration and automation.
More like this
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Why Red Hat partners are the ultimate telco business asset
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds