
Introduction
This is the third part of the How Full is my Cluster series.
In part one, we covered some basic concepts and recommendations on how to size all the pods so that OpenShift can make informed scheduling decision and so that we can get better metrics on the state of the cluster.
In part two, we covered how to protect the nodes from being overloaded by pod workload.
In this third part, we are going to talk more in detail about how to do capacity management.
Pods' Resources Estimation
One way to approach capacity management is to compare estimates (resource requests) and actuals (actual resource consumption). Here is a possible plot of these two metrics:
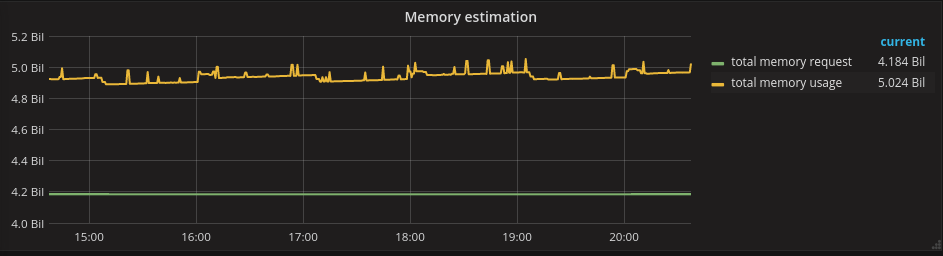
By analysing these two metrics relative to each other and comparing them with the total cluster capacity, we can derive several conclusions as described below.
Well-estimated workload
A cluster's workload is well-estimated if the actuals are within a certain range of the estimate. For this example, we will choose a 20% range.
If we plot a 20% upper and lower threshold around the estimate, we can see that the previous plot shows a well-estimated workload.

Here everything is good and we don't have to do anything.
Overestimation
If the estimate is significantly higher than the actuals, then we are overestimating the resources needed by our pods.
How much is too much? That depends on your tolerance for wasting resources. Using 20% as our tolerance threshold again, the following plot shows what an overestimated workload looks like:
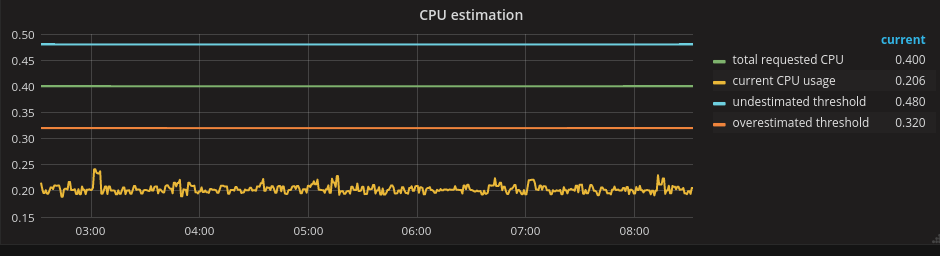
If we end up in this situation we should "drill-down" into our metrics data and identify the pods that contribute the most to the overestimation. We should, then, have a conversation with the owners of those pods. There may be a good reason for the overestimation, but, if not, we should ask the owners to resize the pods and, in doing so, give back some resources to the cluster. If those pods are using the Guaranteed Quality of Service (QoS), one other thing to consider is changing those pods to Burstable (see part two of this series for more details on available QoS in OpenShift). This means decreasing the request but leaving the limit unchanged.
Recommendation: Develop the ability to create a report with the list of pods and the ratio between their request and their average resource utilization over a period of time.
Underestimation
Conversely, if the actuals are above the estimate, then we have underestimated our pods.
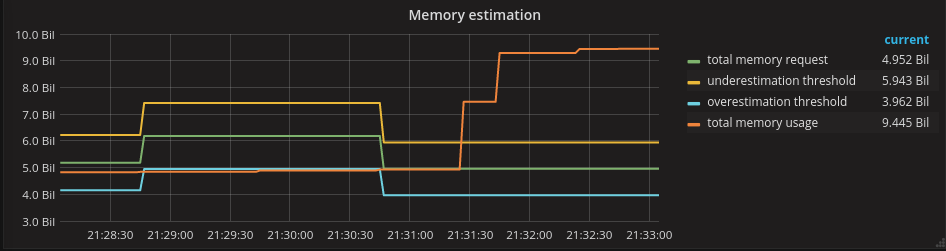
Note that this can only happen if the limits of some of the pods are greater than their requests.
This is a more dangerous situation. In fact, under these circumstances, one or more of our nodes could be overcommitted. See part two of this series on how to manage node overcommitment.
From this graph you should be able to "drill-down" to the list of pods that are using more resources than their request. This is the same report we discussed for overestimation, just sorted the other way around. Again, it may be worthwhile having a discussion with the owner of the pods. In this case, you may want to consider moving those pods from the Burstable to the Guaranteed QoS.
Cluster sizing
Once we are confident that our workload is estimated as best as we can, then we can start reasoning on cluster sizing.
I argue that, if the estimates are reliable, we should use them as the signal to manage the size of the cluster.
This is an important assumption and it is worthwhile spending a minute to think about it.
The other option could be to use the actuals (or a derivative of it, such as moving average of the actuals).
Actuals are unpredictable because they greatly depend on the load that a pod is currently serving. Actuals tend to behave like a stochastic function. A significant amount of literature has been written on how to predict the future behavior of a stochastic function if you know its past. Any book on numerical methods for automated securities trading basically deals with this problem (for example this). And the reality is that there is no good numerical method to predict the future, especially the medium to long-term future.
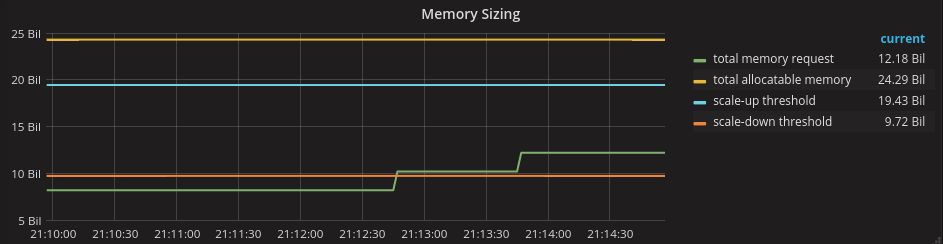
I think that, unless you have additional intelligence about your workload, estimates capture better information about the future than the actuals because they incorporate the cluster tenant's intentions. If we believe in this argument, we can then base our cluster capacity management on the estimates. To do so we are going to compare the workload estimates with the cluster capacity and two scale thresholds defined as follows:
- A scale up threshold at 80% of capacity, arbitrarily chosen.
- A scale down threshold at 40%, arbitrarily chosen.
Using these thresholds, here is a picture of a correctly sized cluster:
Undersized Cluster
The following picture shows an undersized cluster:

This picture shows our estimate above the scale up threshold. We should be notified of this event and start adding nodes.
Recommendation: Create an alert for when the estimate reaches your scale up threshold.
Oversized cluster
Conversely, this images shows an oversized cluster:

We have defined a scale down threshold here at 40% of the total capacity. As for the oversized cluster event, you may want to be notified.
Shirking is much less critical than expanding because if you don't expand your cluster you risk not being able to serve your tenants, however, if you don't shrink your cluster you simply waste resources.
Cluster Commitment Level
In part two of this series we have seen that a node can become overcommitted.
By the same token, a cluster has a commitment level and can become overcommitted.
The commitment level of a cluster can be defined by the ratio of the sum of the granted quotas and the total resources allocatable. Here is a diagram of a cluster that is 40% overcommitted.
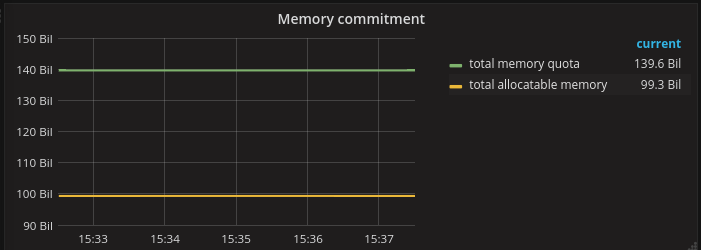
If the commitment level is greater than one, then the cluster is overcommitted. Again, this is not a bad thing per se. In fact, I think that in the case of cluster level commitment, it is perfectly normal to run a cluster that is 50% to 100% overcommitted.
In order to calculate the cluster commitment this way, one should have all the projects under quota (as per the recommendation from part one of this series) and all the quotas should be set on the resource request (not the limit).
You should keep an eye on the commitment level of a cluster, but I don't think that this should be the primary criteria for deciding whether to scale the cluster. The primary criteria should still be the ratio between the estimates and the available resources.
However, some companies may have a very long procurement period when it comes to adding new capacity to the cluster (for example, because new physical hardware must be provisioned) and they cannot react quickly. In these situations quotas can be a better long-term trend indicator than the requests.
Designing a Cluster Autoscaler
A cluster autoscaler is a piece of software that monitors an OpenShift cluster and autonomously decides when to add and remove capacity to the cluster.
Here are some design considerations on a cluster autoscaler:.
- A cluster autoscaler should have two components: One that decides when to scale, and the other that actually carries out the action of scaling up or down. The latter is clearly infrastructure dependent, but the former can be generalized.
- As we discussed, the autoscale decisioner should use the estimates as the signal to autoscale.
- A cluster will be segmented in several logical zones (when we create an OpenShift installation we usually create three logical zones: The masters, the infranodes, and the nodes). The decisioner should consider each zone independently.
- The decisioner should probably use a combination of signals (besides the estimates) to decide when to autoscale, example of other signals are:
- A pod cannot be allocated to due resource constraints.
- The cluster over-commitment level is above the threshold we are willing to accept.
- Maybe something very workload dependent (for example, we know that at a certain time of the day we have a workload peak and we want to preemptively autoscale).
- In order to scale up just one of the conditions need to be true (logical or), while in order to scale down all the conditions need to be true (logical and).
Some initial work on a cluster autoscaler can be found in the upstream community here.
Maintenance Spare Capacity
One more thing to consider when deciding the size of a cluster is that having some spare capacity can help maintenance tasks.
In fact, maintenance tasks as patching, updating, and upgrading all use the same approach, which is to take one or more nodes out of the cluster, execute the maintenance tasks, and then have these nodes rejoin the cluster.
Having the ability to execute these tasks on two, three nodes at the same time reduces proportionally the maintenance time.
Another approach to overcome this issue is to add capacity just before the maintenance tasks begin. If you choose this approach then your maintenance window time frame can become one of the signals of the autoscaler.
Getting Started with OpenShift Capacity Management
You can recreate the above graphs with your favorite monitoring tools. To help you get started quickly, I have created a series of graphs in Grafana powered by Prometheus. To set this up in your cluster, follow the instructions at this page. The Prometheus implementation is not supported, but it should give you a way to get familiar with the concepts expressed in this article.
Conclusions
The discipline of capacity management for Kubernetes/OpenShift clusters is just beginning. The intention of this article and the previous two of this series, was to provide some insight and some advice on how to approach capacity management. I believe that over time we will see better tools being created to simplify these tasks.
About the author
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
Can't patch fast enough? Zero trust as a last line of defense
What's new with image builder for Red Hat Enterprise Linux 10.2 and 9.8
The Containers_Derby | Command Line Heroes
Can Kubernetes Help People Find Love? | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds