Introduction
In part two of this series, we saw how to deploy a geographically distributed database. We used CockroachDB in that instance; however, no workload was running on that database, except for the TPC-C test we ran to ascertain the performance.
In this article, we are going to see how we can create a geographically distributed deployment of Keycloak running on CockroachDB.
Besides the obvious consideration that having an application consuming the database is a more realistic scenario, Keycloak is an interesting choice for two reasons:
- It manages a session cache (like many front-end applications), so we have to make sure that all the caches are synchronized even across geographies.
- We can configure OpenShift to authenticate using Keycloak as the identity provider. This way, we can ensure users in the Keycloak realm can all authenticate to the three OpenShift clusters that are part of this deployment.
Deploying Keycloak
The logical deployment of Keycloak that we are going to use is relatively simple, and it is described by the following diagram:
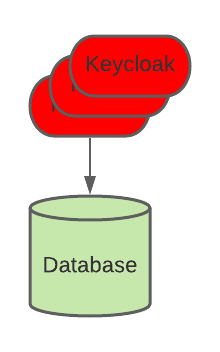
As we can see, we have several instances of Keycloak connecting to the same database. These instances also share a distributed cache implemented with Infinispan.
In our case, the database and the Keycloak instances are distributed across multiple regions.
If you followed the steps in part one and part two of this series, you should already have this architecture:
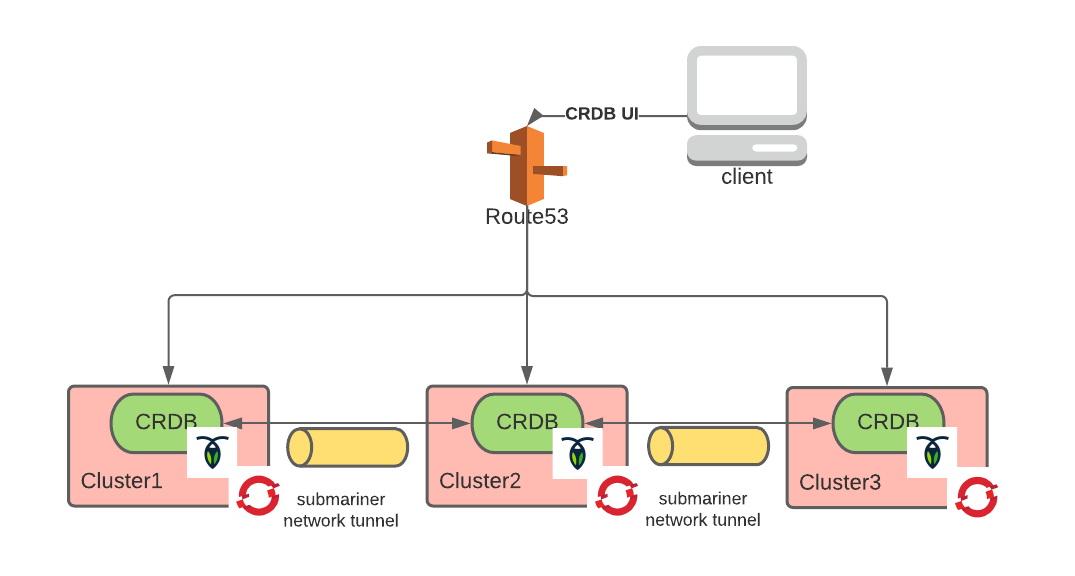
It is worth remembering that we have a global load balancer (implemented Route53) to route client connections, a network tunnel between OpenShift clusters (implemented with Submariner) to enable east-west communication, and CockroachDB as our single logical instance database, which, in fact, is geographically distributed.
Adding Keycloak is conceptually simple, and the new architecture will look as follows:
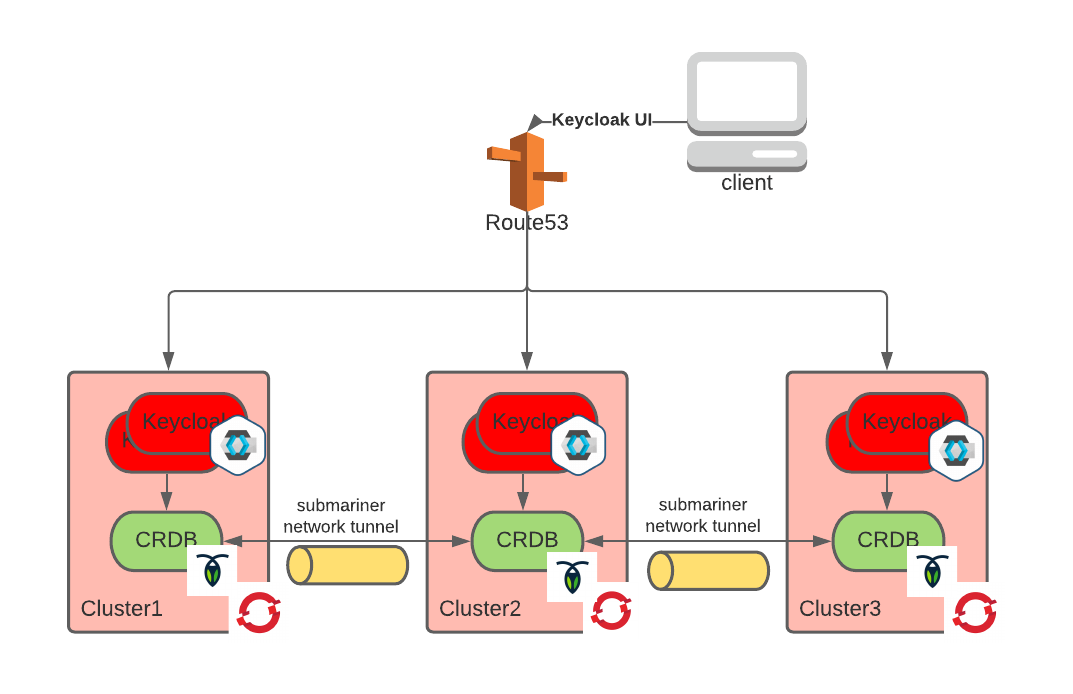
To build this architecture, we decided to use Keycloak.x, the new Quarkus-based Keycloak distribution. Keycloak.x, by using the Quarkus property-based configuration injection, makes it easier to create the advanced configurations needed in this case.
The steps to deploy Keycloak in the way described above can be found here.
Configuring the Infinispan Distributed Cache
Keycloak uses a distributed cache to sync sessions between instances.
Leveraging the network tunnel provided by Submariner, we configured Infinispan as in the below diagram:
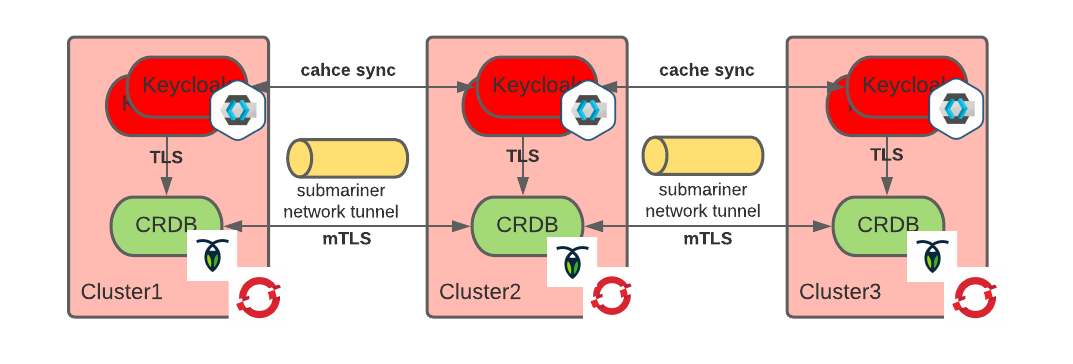
We used the TCP_NIO transport (the optimized, non-blocking TCP transport). We cannot use the more efficient UDP multicast transport because Submariner is a Layer 3 tunnel and does not support multicast.
We use the DNS_PING discovery mechanism to let Keycloak pods find their peers. When exporting a headless service via ServiceExport, Submariner creates a DNS record with multiple entries, one per Keycloak pod across the connected clusters. This works well with the DNS_PING discovery mechanism.
Finally, we configured Infinispan Server Hinting to make sure that the cache keys are in such a way to survive the loss of a region.
Configuring OpenShift Authentication
Now that we have a reliable deployment of Keycloak (zero RPO and near zero RTO in the event of a loss of a region), we can use it to configure our OpenShift clusters to authenticate with it:

This way, the three OpenShift clusters will use the same authentication mechanism, which means users can use the same credentials across these three clusters. One nice benefit of this deployment is that Keycloak, our Identity Provider (IDP), is self-hosted in these clusters.
Instructions on how to do this configuration can be found here.
The same consideration we made for Vault applies here: The IDP, whether it is for OpenShift itself or for the applications hosted in it, is critical infrastructure, so we want to deploy it in the most available way at our disposal.
Disaster Simulation
We can simulate a disaster like we did in part 2 of this series by partitioning the network and completely isolating one of the regions:
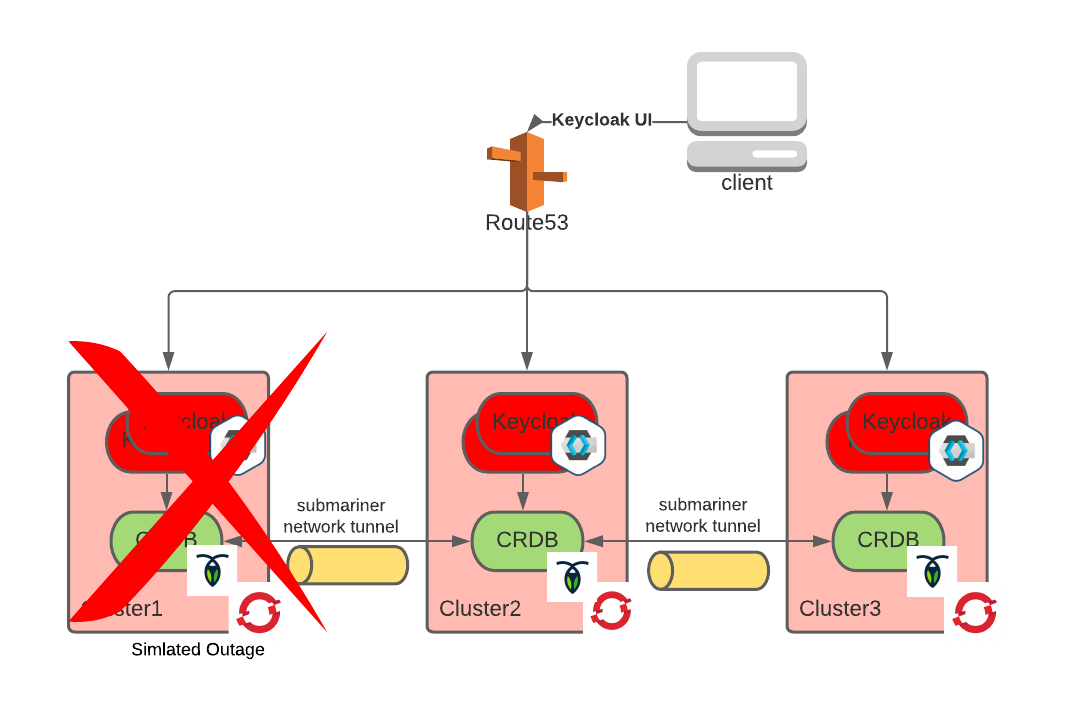
We did that while at the same time working on the Keycloak UI. While we could see that some of Keycloak instances were not available by looking at Route53 health checks, we did not experience any glitches at the UI level.

Once connectivity was restored, all instances became available again. No human intervention was needed, neither when the disaster occurred nor when the issue was resolved.
Enhancements Opportunities
There were a few things that we could not achieve with the deployment that we have described above and that as technology matures will probably become available:
- Ability to automatically create the Keycloak database. Currently an incompatibility between an old version of Liquidbase and CockroachDB prevents Keycloak from automatically creating the database. So the database has to already exist when the Keycloak pods connect to it (see KEYCLOAK-18110 and KEYCLOAK-18109).
- Ability to rotate the database credentials. Currently the database credentials are hardcoded in the Keycloak configuration. A much better way would be to use Vault to rotate the database credentials. We were not able to configure Keycloak.x to use Vault to get the database credentials (see KEYCLOAK-18255).
- Encryption between Infinispan peers. Today Infinispan does not support TLS nor mTLS. It has its own encryption mechanism that requires the creation of keys in a way that is hard to automate inside OpenShift. mTLS would be ideal for peer-to-peer authentication and communication encryption (see JGRP-2487).
Conclusions
In this article, we saw how to implement a disaster-resilient Keycloak deployment across three OpenShift clusters. In part one of this series, we saw how we had to deploy Vault as a way to establish trust and share secrets between OpenShift clusters. Keycloak plays a similar role, but this time, it allows sharing user realms and their roles/permissions configurations. It is worth remembering that RH-SSO is the supported version of Keycloak by Red Hat. In this article we could not use it because we have been hovering around the bleeding edge of the technology using several (yet) unsupported features, the main ones being Keycloak.x and Keycloak running on CockroachDB.
About the author

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
Navigating the Mythos-haunted world of platform security
MCP security: Logging and runtime security measures
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds