Introduction
In the first three installments of this blog series, we used a relational database as our geographically distributed workload to demonstrate how it behaves in terms of performance and disaster handling (part 2) as well as how a geographically distributed front-end application consumes it (part 3).
Naturally, there are other kinds of middleware that can also be geographically distributed (part 1 of this series included a discussion of how to set up a secret management service in this fashion). Middleware messaging and streaming is probably second to databases in terms of popularity as they are commonly employed in many integration scenarios.
In this article, we will examine how to deploy Kafka in a geographically distributed manner.
Architecture
Similar to the previously examined stateful workload implementations, we will deploy Kafka across three regions and in three different OpenShift clusters.

Producers and consumers will exist in each of the clusters, but they will produce and consume to and from the single logical Kafka instance.
Unlike the prior post, we will use Google Cloud for performance reasons that will become clear later on in the performance section.
The diagram depicts the nine-instance Kafka cluster with three instances per region. There is also a nine-instance Zookeeper cluster not shown in the diagram (the Zookeeper dependency is purposefully omitted as it is slowly being removed from the Kafka ecosystem).

Each Kafka instance can discover and communicate with the others, generating a single logical Kafka instance. All connections are encrypted: internal control plane connections employ mTLS, while client connections use TLS.
Kafka’s rack-awareness is set on the region, ensuring that partition replicas are spread across regions. To ensure that each region has at least one copy of each message, we need at least three replicas. This will ensure that if we lose a region, we will not lose data, and we can also continue to operate. Notice that Kafka understands only one layer of failure domain (called rack in Kafka jargon). This makes it impossible to model multilayered failure domains that are common in the cloud such as availability zones and regions.
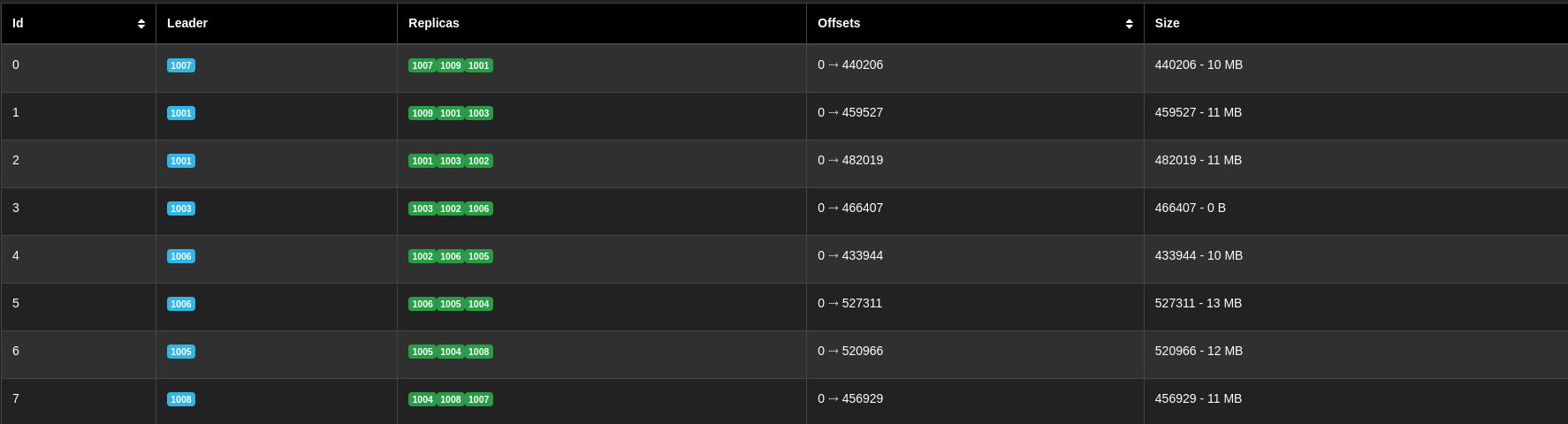
When creating topics with this deployment, it makes sense to define a number of partitions that is a multiple of nine. When things are balanced, this ensures that each Kafka instance gets one or more partitions for which it is the leader and several replicas for which it is the follower. The table below (snapshot from the AKHQ Kafka dashboard) represents how partitions and replicas distribute themselves in a nine-partition topic when things are balanced:

However, for our testing, we used topics with additional partitions (72 to be exact).
To build this architecture, follow the steps described at this repository (in particular, the following steps: step1, step2, step3). Instructions are available for a deployment to Google Cloud if you want to reproduce the same performance results as described within this article (other than that, you should be able to build this architecture in any cloud provider).
Strong Consistency in Kafka
As for the other articles of this series, we want to configure a strongly consistent deployment of Kafka.
Strongly consistent stateful workloads are often preferable to eventually consistent ones because they keep things simple from the developer point of view, increasing productivity and reducing errors, but reducing performance in some instances (also see this article for a more in depth explanation).
But what does it mean to be strongly consistent for a messaging middleware and, in particular, in Kafka?
A message passing configuration with exactly-once delivery semantics and message ordering roughly corresponds to a situation in which exactly one record is written on a table per event, and these records appear to external observers in the same order as the events (serializable isolation level).
In Kafka, it is not possible to configure exactly-once without making some assumptions on the consumers. So, for this article, we will settle for at least once with message ordering within a topic.
To achieve at least once delivery semantics and message ordering, the following settings must be configured:
On the producer configuration:
acks=all
enable.idempotence=true
On the topic configuration:
replication.factor=3
min.insync.replicas=2
These settings are some of the most taxing in terms of performance as they require higher coordination between the partitions replicas and the producers.
Performance Considerations
When working with geographically distributed workloads and strong consistency, we know that we cannot expect good transaction latency (PACELC corollary to the CAP theorem). If one needs very little latency, one needs to employ local deployments, which may have to asynchronously share state at a geographical layer and accept some chance of data loss.
Another aspect of performance is throughput, which is the number of transactions that are completed in a unit of time (or the amount of data committed in the unit of time). Modern stateful workloads tend to be able to scale linearly as resources are added to the cluster. Therefore, at least in theory, any amount of throughput is achievable; one just has to add more resources.
Kafka is popular for its ability to scale linearly along with being, in general, fast at processing messaging, resulting in a high throughput with relatively small infrastructure.
So, assuming that the use case at hand does not require short latency, we can optimize our geographical deployment of Kafka for throughput.
The following is an overview of the settings that were configured. It is worth noting that we were able to increase the throughput by two orders of magnitude, so at least in the case of Kafka, tuning does make a difference.
First we needed to make sure that the network tunnel between OpenShift clusters and cloud regions had good throughput. Based on our experiments and some other evidence (AWS, GCP), it appears that Google Cloud has the best inter-regional throughput.
Also, we configured VPC peering between the VPCs in which OpenShift is installed. This provided a cloud provider controlled confidential tunnel between VPCs. Using the new VXLAN cable driver available in Submariner 0.10.x, we avoided the issue of double encryption (which would be incurred using other cable drivers, such as IPsec or WireGuard). With this setup, we were able to achieve an on-the-line throughput of 3.5 GB/s and about 70ms of latency. The diagram below demonstrates this portion of the setup:
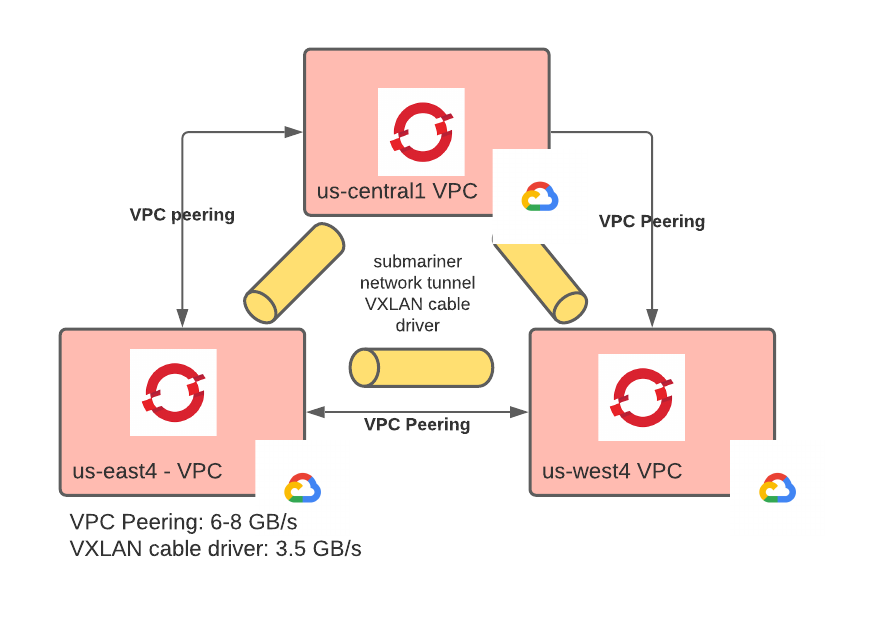
The current Submariner architecture with only one active gateway is the biggest limitation of this deployment. Cloud providers put a cap on inter-regional instance-to-instance communication throughput, so, when it comes to maximizing throughput, having only one active gateway is rather limiting. Having more gateways able to handle the communication would increase the available bandwidth linearly with the number of gateways. Future versions of Submariner should have support for active/active gateways and eventually a full node to node mesh in which each node is also a gateway (see also these RFEs: 34, 35).
On the Kafka side, it is worth noting that to optimize for throughput, one has to focus on the producer throughput as producers are always slower than consumers. A few areas that will help maximize throughput: compression, send and receive buffer size, number of producers, message batches, and number of partitions.
Compression: There are several compression algorithms available in Kafka. We used lz4 as it looked like a good compromise between the compression ratio and CPU usage. In general, compression stresses the CPUs on the producer, while significantly reducing the amount of data that needs to be transmitted on the wire.
Send and receive buffers: This is the send and receive buffer of the raw TCP socket. Based on recommendations in the Kafka documentation, we configured it following the bandwidth-delay approach, using the worst throughput and the worst latency between regions as parameters.
Number or producers: the number of producers also impacts the throughput. Interestingly, throughput does not increase linearly with the number of producers.
Message batches: Kafka offers the ability for the message producer to batch messages together reducing the number of round trip communications needed. In our experiments, we used 1KB messages and various sizes of message buckets. To allow for the buckets to get filled up, linger.ms was set to 50. The following illustrates the performance that we observed with different bucket sizes:

Number of partitions: The number of partitions roughly approximates the number of parallel work that the cluster can process for a given topic. Increasing the number of partitions should provide better throughput until some underlying resource becomes a bottleneck. As shown in the diagram below, when reaching 144 partitions, performance no longer increased and we started seeing contention on the storage layer used by Kafka message logs.

So, with the following configuration:
- Compression: Lz4
- Send and Receive Buffer Size: 3.5GB/s x 70ms = 245MB
- Batch size 128KB
- Message size: 1KB
- Number of producers: 18
- Partitions: 72
We reached a throughput of 1.45 GB/s or around 81000 messages per second.
Running producers and consumers at the same time naturally causes a slight reduction in the producer performance (empirically around 5%).
Consumers were configured with client.rack corresponding to the region in which they were running, so as to consume from a local replica. This keeps the consumer connections local, improving latency and reducing costs as local network communications are less expensive and in some cases free. 18 consumers averaged 108MB/s each for a total of 1.95GB/s.
Cost Considerations
The infrastructure we used to run this Kafka deployment is comprised of the following (not considering the OCP control planes nodes nor the nodes needed to run the message producers):
- 9 n2-standard-8 VMs
- 18 300GB pd-standard disks
The current rate for this infrastructure translates to about $3.8/hour (9x$0.388472=$3.496248 + 18x300x0.040$/month/30/24=$0.3). This represents the fixed cost of this deployment.
To that, we need to add the variable cost, which, in this case, is the cost of inter-region network communication: $0.01 GB (inter region costs for North America) * 1.45 GB/s * 2 (we multiply by two because every message has to be stored in each region) *3600 = $104 per hour.
Rounding up, the cost of this kafka deployment is around $110/h when running at full capacity.
The cost per message is $110 per hour / (81000 * 3600 messages per hour) = 0.000000377 $.
I am not sure if this is a good cost per message ratio, but it appears to me that cost per message is a good benchmark for comparing different Kafka deployments. Let’s recall that in our case, this cost incorporates the guarantee that messages will not be lost and order will be maintained in event of a disaster.
I believe that over time, the fixed cost will be dwarfed by the variable costs as more cost-efficient instances become available (for example ARM instances and disks).
Disaster Simulation
As in the previous posts of this series, our disaster simulation consists of shutting off connectivity to and from one of the regions. We are going to do that while producers and consumers are pushing and pulling messages from a topic.
Before the disaster, we can observe that each partition (only seven are shown here) has three in sync replicas evenly distributed between the various regions:
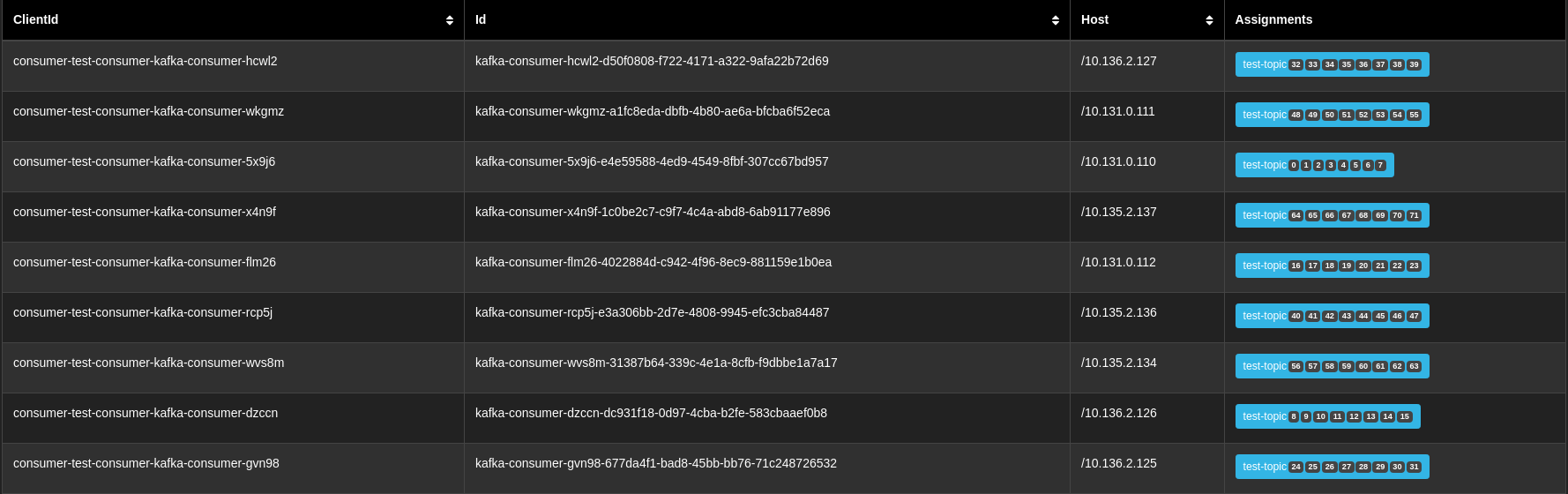
We can also observe that nine consumers are running; three in each region, and each has been assigned nine partitions to consume from.
Then, we trigger the disaster:

At this point, Kafka realizes that the leaders of several partitions are unreachable and elects new leaders, while at the same time, updating the fact that now only two replicas out of three are in sync:

However, this is still enough to keep the lights on. The remaining producers return some transitory errors, but none of them fail. The remaining consumers get rearranged to consume from more partitions as shown in the picture below:

When the disaster condition is removed, Kafka heals automatically by recovering the out-of-sync partitions and rebalancing the partition leaders so that the newly restored brokers get their fair share.
Again, disaster detection and recovery is fully autonomous and requires no human intervention. Likewise, re-establishing normal operations when the disaster condition is removed is fully automated.
Conclusions
In this article, we saw how it is possible to deploy Kafka across multiple regions and in multiple OpenShift clusters. We saw how we needed to sacrifice latency to attain strong consistency and how we were able to achieve a decent throughput (which can probably be improved even further in the future). We also saw that in case of a disaster (in our case, the loss of a region), the system reacts and adapts autonomously without losing messages and becoming unavailable for only a very short time (0 RPO, few seconds of RTO). Anyone should be able to reproduce these results following the script included in the repository shared earlier. Our hope is that companies can use the ideas described in this post to build more reliable message passing and steaming systems using Kafka.
About the author

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
Context-aware advisor recommendations in Red Hat Lightspeed
A decade of open innovation: Red Hat continues to scale the open hybrid cloud with Microsoft
Crack the Cloud_Open | Command Line Heroes
When Should Data Die? | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds