
I have written in the past about the importance of a global load balancer, along with approaches for how one can be implemented. In this post, I’ll share how we implemented K8GB as a global load balancer at BankCorp (fictional name), a financial institution.
The beginning
At BankCorp, our Red Hat OpenShift deployment was beginning to be successful: the infrastructure was stable and several tenants were making use of the platform – deploying applications working their way through the software development lifecycle, all the way up to production. However, everything was deployed in a single datacenter.
It was time to start thinking about leveraging the second datacenter for these workloads. We already had clusters in the second datacenter and the applications at the time were all stateless. So, all that was needed was to simply determine a method for load-balancing the applications between the two datacenters (henceforth referred to as east and west).
The standard way to build global load balancers at BankCorp was to configure F5 BIGIP devices, so we contacted the F5 team. They were happy to meet our needs for a global load balancer solution: we just needed to submit the appropriate request.
This was unacceptable for us as we had made an unbreakable promise to our tenants: if you come to our platform, you’ll never have to open a ticket again.
To eliminate the need to submit a service request, we asked the F5 team for access to the F5 APIs. Access was not available for external consumers and no delivery date for this capability was on the roadmap. We couldn’t wait: we had to find another solution.
MVP Global Load Balancer implementation
For our first MVP implementation, we decided to simply create a wildcard DNS record with a global entry pointing to the OpenShift’s ingress virtual IPs (VIPs). The following depicts the high-level design:
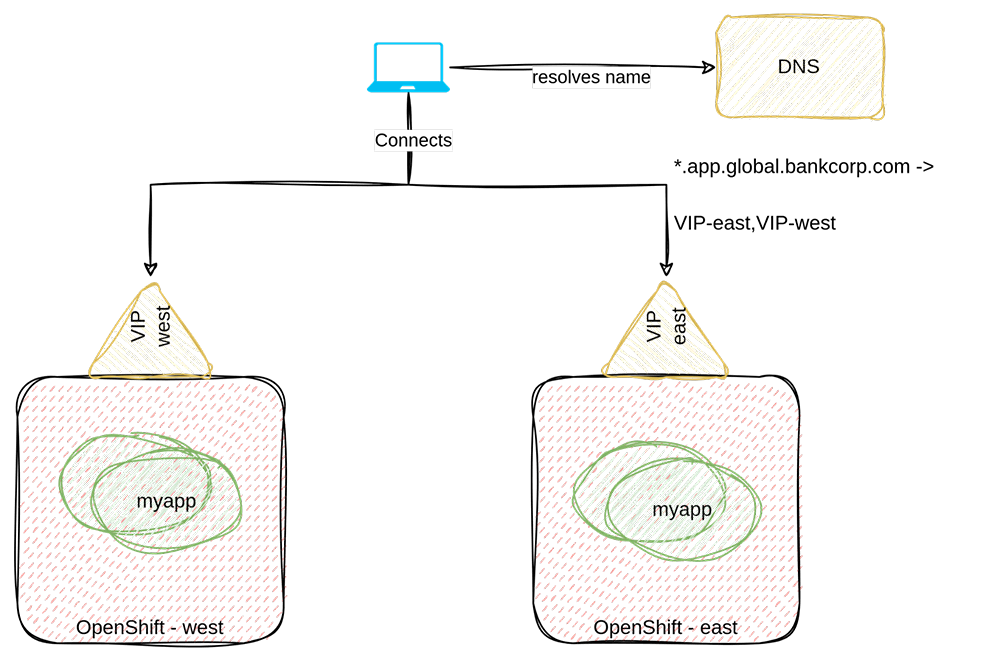
With this approach, when a client tries to resolve a global FQDN, they get redirected by DNS either to the east or west VIP.
While this is a simple design, it has the following limitations:
- All applications in the cluster must follow the same disaster recovery (DR) strategy – that is, they all need to be either active/active or active/passive.
- Applications will failover together as the failover happens at the cluster level.
- There is not a feasible method for performing application health checking. As a consequence, failovers must be triggered manually.
- This is a simple round-robin load balancing strategy, not suitable for all use cases.
These limitations are on top of the inherent limitations of using a DNS-based load balancing approach:
- If multiple IPs are returned by the DNS server, the order of the values returned is meaningful (i.e., there is an expectation that the client will try the first IP first). We rely on the intermediate DNSs to not change the order and on the client to honor the order.
- Each DNS reply has a TTL, which indicates how long that entry can be cached. Short TTLs allow for quicker reactions (i.e., failing over quickly in the case of an outage), but imply more frequent requests against the DNS server. For TTLs to work properly, we rely on the intermediate DNSs and the client to honor them.
This approach worked for us because when we adopted it we had essentially a single application architecture pattern: stateless microservices. Also, at this stage, all the microservices were part of the same business application and it was acceptable that they all failover at the same time.
However, we couldn’t stay on this architecture for a long time as we needed applications to be able to failover independently.
Enter K8GB
K8GB is a global load balancer operator and a CNCF project. This operator works by creating a zone delegation record in the DNS used by an organization (apex DNS) pointing to a self-hosted (in Kubernetes itself) distributed DNS.
A zone delegation instructs a DNS to forward queries regarding a specific domain (for example, .global.bankcorp.com) to an alternate DNS. In the case of K8GB, the alternate DNS is actually a distributed DNS with one instance listening in each of the Kubernetes clusters whose applications have a need of being load balanced
The delegated requests will be redirected to multiple DNS instances hosted in the clusters that are being load balanced. CoreDNS is used to implement these DNS instances and their entries are populated by the K8GB controller.
The following is a high-level architecture of K8GB:
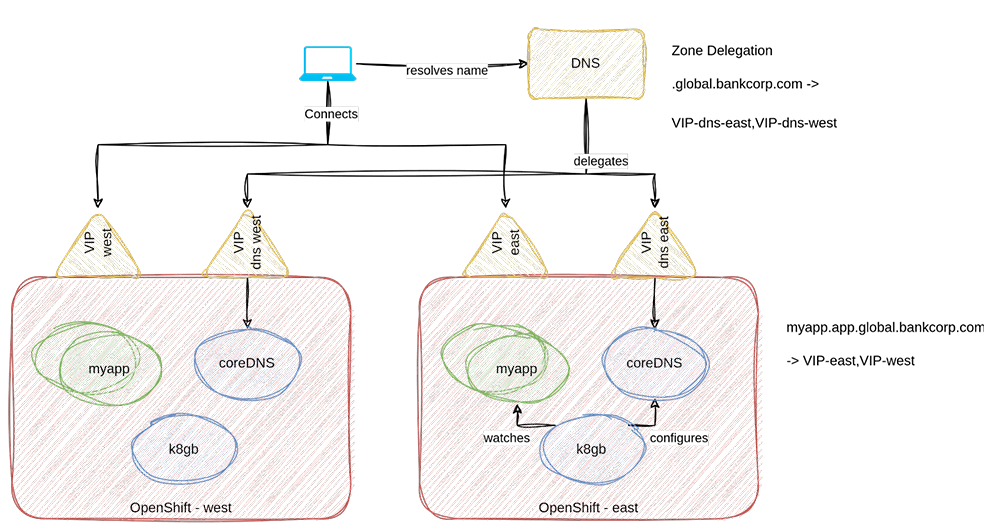
The K8GB controller populates the entries of the local coreDNS instance by observing the definition of the K8GB CRs or annotations on ingresses. So, if a tenant wants their application to be globally load balanced, they will create an Ingress resource for that application that looks similar to the following:
kind: Ingress
metadata:
annotations:
k8gb.io/dns-ttl-seconds: "30"
k8gb.io/strategy: roundRobin
name: myapp
namespace: myapp
spec:
rules:
- host: myapp.apps.global.bankcorp
http:
paths:
- backend:
service:
name: myapp
port:
name: http
path: /
pathType: PrefixThis implementation enables a self-servicing capability, which, as mentioned at the beginning of this article, was a very important feature for us.
By adopting K8GB, we introduced the following enhancements:
- Applications can now failover independently. In fact, K8GB manages individual DNS records (even though they all point to the same ingress VIPs).
- Applications will failover automatically – no need for human intervention to determine that there is an issue. K8GB monitors the availability of an application in a cluster by looking at the number of endpoints behind the service associated with an Ingress. So, as long as the pod has reliable readiness checks, K8GB will make the appropriate failover decisions. Notice that it is preferable to have external health checks which take into account not only internal issues with an application, but also possible networking issues from the client point of view. However, we judged that internal health checks were satisfactory for our use case.
- Finally, we could support different styles of disaster recovery strategies. Important for us were active/active and active/passive, both of which are supported load balancing strategies by K8GB.
K8GB behavior under failure
If we are going to trust K8GB to failover traffic to our workloads during failures, we should understand in depth how the system works.
When you create a globally load balanced Ingress, K8GB creates a DNSEndpoint similar to the following:
kind: DNSEndpoint
metadata:
annotations:
k8gb.absa.oss/dnstype: local
labels:
k8gb.absa.oss/dnstype: local
name: myapp
namespace: myapp
spec:
endpoints:
- dnsName: localtargets-myapp.apps.global.bankcorp.com
recordTTL: 10
recordType: A
targets:
- 10.1.196.48
- dnsName: myapps.apps.global.bankcorp.com
labels:
strategy: roundRobin
recordTTL: 10
recordType: A
targets:
- 10.1.196.48
- 10.1.196.28This resource is interpreted by a CoreDNS plugin and loaded in CoreDNS. Notice that this DNSEndpoint actually contains two DNS entries. The first one is a local entry, which is used by the remote K8GB instances to learn about the entries that the local K8GB instance is managing. This entry is never used by the end user. This entry can be retrieved by querying the CoreDNS instances directly using a fully qualified domain name (FQDN) that can be calculated by by knowing the global FQDN and prepending “localtargets-”.
A K8GB instance can discover the remote CoreDNS endpoints using a concept called geo tags. K8GB instances receive the list of geo tags as a startup parameter and can learn about all of the CoreDNS endpoints by querying the apex DNS for the DNS delegation record.
For each global FQDN that it is managing, K8GB can then query the remote CoreDNS endpoints directly, computing the local entries and receiving the remote VIP addresses. Based upon the information retrieved, the second part of the DNSEndpoint is updated with the full list of IPs for a given global entry.
With this simple algorithm, the global entries of all of the CoreDNS servers will converge to the same values relatively quickly.
This process represents the steady state. But what happens when there are failures? Let’s analyze the following three failure scenarios:
Application becomes unavailable at one location
This is the main use case for which this operator has been designed: the ability to failover applications individually. In this case, K8GB will update the local entry to have zero IPs and update the global entry not to have that specific IP. As a consequence, the other K8GB instances will relatively quickly remove the IPs that have failed. At that point, all of the CoreDNS instances will have converged to the same representation of the situation in which the entry of the failing location has been removed.
CoreDNS becomes unavailable at one location
This scenario can occur either because a CoreDNS instance has failed, or more likely, because an entire location has become unavailable. From the point of view of the other K8GB instances, there is no way to tell. Either way, if the remote CoreDNS cannot be reached, the corresponding entries will be removed. Also, since that DNS instance cannot be reached, the apex DNS will direct queries to the other instances.
A network partition occurs between clusters, but the clusters are still available for the apex DNS and consumers
In this case, each K8GB instance will behave as if the others do not exist, removing the corresponding entries as explained previously. However, both the apex DNS and the clients still have full connectivity.
In this scenario, depending on where the apex DNS redirects the query, clients will get different results: The returned IP is always the local one address relative to the CoreDNS to which the apex DNS redirected the DNS request. The system still works and is still somehow load balancing. However, this scenario leads clearly to a degraded state in which, for example, the K8GB load balancing strategies no longer work.
Conclusions
If you are deploying applications to more than one cluster, you need a global load balancer. If you want to be able to automatically configure the global load balancer based on what applications are being deployed to the cluster, then you need some form of automation, such as a global load balancer operator. This capability relieves consumers of the platform from having to open a ticket to get the global load balancer configured for their applications.
K8GB is one operator that can serve this purpose. In fact, it is one of the few global load balancer operators for Kubernetes and the only one associated with the CNCF.
As explained in this blog post, K8GB can be used with OpenShift. It is important to note that as of the time of this writing, it is not supported by Red Hat, but can be deployed as an operator supported by the community.
If you decide to implement K8GB in your environment, we recommend testing the above failure scenarios to ensure that the system overall behaves in a predictable and correct manner.
If you were wondering what we ended up implementing at BankCorp, at the time of this writing, all tests in the lower environments look good and we are getting ready to move this architecture into their production environments.
About the author
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
The evolution of infrastructure automation in the age of AI: 4 key takeaways from Red Hat Summit 2026
From alert fatigue to automated action: Automated patching in the AI era
Untangling Networks | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds