
Introduction
OpenShift Pipelines is a Continuous Integration / Continuous Delivery (CI/CD) solution based on the open source Tekton project. The previous articles in the series, starting here, showed how to:
- Use the OpenShift source 2 image process to build an application.
- Create and store a runtime image.
- Create an overall orchestration process of Tekton pipelines to bring together the tasks into a single, seamless process that executes all required steps.
In this article, the process for triggering pipeline execution from a webhook will be explained, and an example will be presented that uses the build pipeline from the previous series of blog posts.
Access to the source content
All assets required to create your own instance of the resources described in this article can be found in the GitHub repository here. In an attempt to save space and make the article more readable, only the important aspects of Tekton resources are included within the text. Readers who want to see the context of a section of YAML should clone or download the git repository and refer to the full version of the appropriate file.
Using the example build and trigger process
If you want to experiment with the build process described in this article, then you can easily do so. The prerequisite is that you have an OpenShift cluster with the OpenShift Pipelines operator installed. Follow the instructions at the end of this article to create the process.
A comment on names
The Open Source Tekton project has been brought into the OpenShift platform as OpenShift Pipelines. ‘OpenShift Pipelines’ and Tekton are often used interchangeably, and both will be used in this article.
Continuous Integration and Delivery
In a software delivery pipeline, the terms continuous integration and continuous delivery are frequently used. While these terms are open to nuances of interpretation, a simple view is that continuous integration is a mechanism for taking the development efforts of a team and validating that the application build is successful. The definition of ‘successful’ in this case includes building without errors to produce an executable, and it should also include an element of testing, which can include source code analysis, functional testing, performance testing, and others.
Continuous delivery is viewed by many as the process of getting changes into production. There are few companies that have automated processes for delivering software changes to production in a fully automated manner. For many organizations, a good continuous delivery process includes the build of source code and the deployment of the resulting application to an environment in which meaningful testing can take place. Following this testing phase, a further automated, or manual, process will be used to progress the tested assets through the route to a live production environment.
A realistic continuous delivery process is often a sequence of automated operations for each environment separated by testing phases, reviews, and approval processes. Smoothing out those different phases into a continuum of automation is the nirvana for many organizations. The first part of the process is to create a build and deployment automation mechanism that responds to developer activities to trigger a software build. The build process is then followed by subsequent activities for image creation, image storage, and application deployment to an initial environment.
OpenShift Pipelines
OpenShift Pipelines are created from a series of different Kubernetes resources that together form an ordered execution of a sequence of steps. Each step is small and easy to understand, and it is possible to create large, interwoven chains of activities that collectively deliver a great deal. Each step is executed within its own container image, resulting in a high degree of separation between steps. This also enables controlled and managed sharing of assets and data when required. The overall relationship between the different elements of the process is shown in figure 1:

Figure 1: Tekton resource relationships
The previous articles in the series showed how to create the above resources and also explained how the different resources come together in a pipeline. This article will focus on how to trigger a pipeline execution from an event in GitHub.
Triggering the Tekton Pipeline
An action in GitHub will trigger the execution of the Tekton pipeline as shown in figure 2:
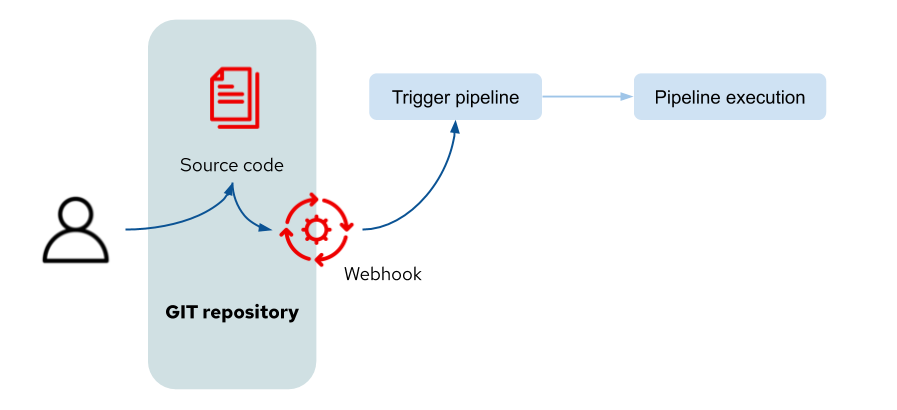
Figure 2: Triggering the pipeline
The user action to manipulate the source code will cause GitHub to make a call to the webhook URL, passing to it an event-specific payload of information. A long list of GitHub actions are able to trigger webhooks, which are listed here, together with information regarding the payload content. The mechanism of exposing the URL for the webhook and for handling the data sent to it is described in the next section.
Tekton Trigger Resources
To participate in a continuous delivery pipeline requires an event listener to which the GitHub webhook can send events, as shown in figure 3. This is simply an OpenShift route which exposes a service that routes communication to the event listener application. The event listener connects to both the trigger binding and the trigger template. The trigger template is responsible for calling the pipeline to execute the Tekton tasks. The trigger binding identifies which data fields are to be extracted from the GitHub webhook payload and presented to the trigger template.
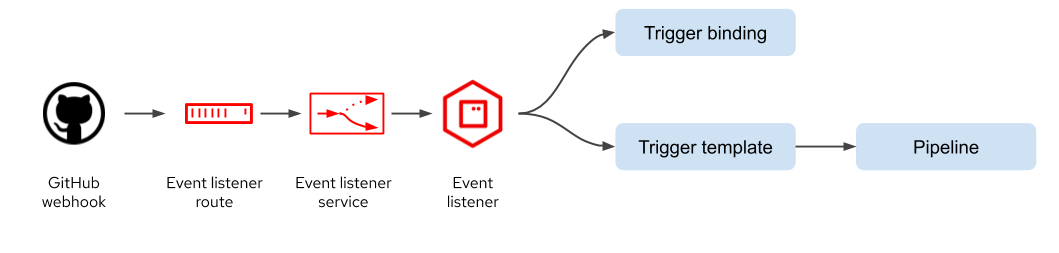
Figure 3: Tekton trigger resources
Event listener
The event listener is a resource for connecting the trigger binding to the trigger template as shown below. It also creates an application running in the project namespace that will invoke the pipeline when required.
apiVersion: triggers.tekton.dev/v1alpha1
kind: EventListener
metadata:
name: liberty-rest-GitHub-listener-interceptor
spec:
serviceAccountName: pipeline
triggers:
- name: GitHub-listener
bindings:
- ref: liberty-rest-pipeline-binding
template:
name: liberty-rest-trigger-pipeline-template
The example above shows an event listener which has the name:
Liberty-rest-GitHub-listener-interceptor
The service account called pipeline is created by the Tekton operator and is used to execute the pipeline.
Within the triggers section in the example above, a single ‘trigger’ identifies the relationship between the binding and the template. Note that multiple versions of the OpenShift Pipelines operator are available, and these do not necessarily have to match exactly the version of the OpenShift platform. The versions of the operator are referred to as the ‘channel’ to which the operator subscribes, as shown in figure 4.
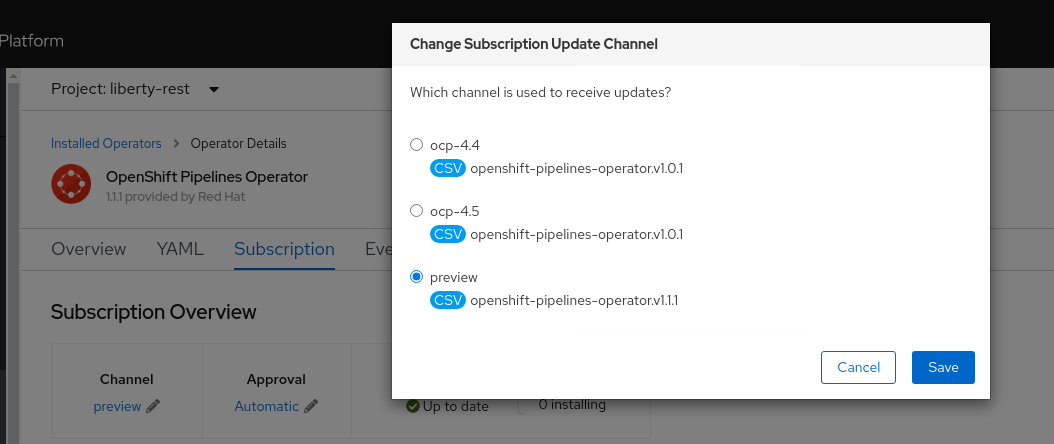
Figure 4: OpenShift Pipelines subscription channel
Up to and including version 4.5 of the OpenShift Pipeline channel the binding reference in the event listener was as below:
triggers:
- name: GitHub-listener
bindings:
- name: liberty-rest-pipeline-binding
If using the ‘preview’ channel subscription (or any future numbered version beyond version 4.5), use the example presented at the top of this section, with the term ‘ref’ for the binding name.
As shown above, each trigger has a name, and for a single event from GitHub multiple triggers can be executed if the event listener contains multiple triggers. It is perfectly fine for a single webhook event to trigger multiple pipelines, and there are mechanisms to filter the events and select which pipelines to trigger. The trigger definition can include an ‘interceptor,’ which contains specific logic to determine whether or not each trigger should be fired. This makes it possible to use a single event listener to receive a broad selection of events from GitHub and then decide which pipeline to execute within the event listener logic. Five different interceptors are available which are:
Webhook interceptor - Reference to an external Kubernetes resource that will receive the payload of the original webhook action. The Kubernetes resource (service and application) will then process the incoming data and return a new JSON payload together with a HTTP 200 status if processing is to continue to the Tekton pipeline. Any other response will halt processing.
GitHub, GitLab and Bitbucket interceptors - Use the logic of each source code management system to filter and validate the payload of the request
CEL interceptor - Use the Common Expression Language (CEL) to filter and modify payload content.
Trigger Binding
The trigger binding identifies which fields are to be extracted from the webhook JSON payload to be presented to the trigger template.
apiVersion: triggers.tekton.dev/v1alpha1
kind: TriggerBinding
metadata:
name: liberty-rest-pipeline-binding
spec:
params:
- name: gitrevision
value: $(body.pull_request.head.sha)
- name: gitrepositoryurl
value: $(body.repository.html_url)
- name: pull_request_title
value: $(body.pull_request.title)
To view which content is available within the webhook payload, go to the webhook page on the GitHub repository and find an instance of the firing of the webhook in the section called recent deliveries. Open a webhook event and scroll to the payload section. Select the JSON content and copy the entire payload into a JSON viewer and browse the content. All items are prefixed with the term ‘body.’ Three examples are shown above. Alternatively, if you have not yet created a webhook in GitHub, use the documentation page here that describes the payloads for different webhook requests.
Trigger Template
The trigger template connects the parameters defined in the trigger binding with a pipeline run resource. The pipeline run is defined within a resource template such that an instance of a pipeline run is created at execution time from the template with the specific parameters from the trigger binding.
An example of the trigger template is presented below; note that some elements are missing to improve presentation, and the full version is available within the GitHub repository detailed at the start of the article.
apiVersion: triggers.tekton.dev/v1alpha1
kind: TriggerTemplate
metadata:
name: liberty-rest-trigger-pipeline-template
spec:
params:
- name: gitrevision
- name: gitrepositoryurl
- name: pull_request_title
resourcetemplates:
- apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
generateName: liberty-rest-app-run-pr-tr-
spec:
pipelineRef:
name: liberty-rest-app
resources:
- name: app-source
resourceSpec:
type: git
params:
- name: revision
value: $(params.gitrevision)
- name: url
value: $(params.gitrepositoryurl)
Params:
- name: title
value: $(params.pull_request_title)
- name: revision
value: $(params.gitrevision)
- name: url
value: $(params.gitrepositoryurl)
The three fields of information are pulled into the template from the Trigger binding. A template for a generated name is provided and ends with the letters -pr-tr- to indicate pipeline run from a triggered operation. Having a naming convention of this kind helps teams to identify pipeline executions that have been triggered from GitHub events and those that have been started manually. Within the resources section, an application source resource is created. In a pipeline run resource (for a manually executed pipeline), the application source resource is a reference to a Tekton resource object, which has a defined URL and branch. When using a trigger template, the application source git resource is created as needed, and a resource object for the source code is not required. This is particularly useful because it allows the Git event to be triggered from any branch, the name of which will be passed through the trigger binding to the trigger template in the gitrevision parameter. The pull request title, GitHub revision, and the GitHub repository URL are all passed to the pipeline identified with the name liberty-rest-app, under the shortened names of title, revision, and url respectively.
GitHub Data in the Container Image
In situations where the pipeline process creates a container image, it is useful to store information about the build process and the source code content in the container image. Container image labels are the ideal place to store this information.
Build information can be added to a pipeline process in the following way. The example below shows how to add a single field for the Git commit ID. Note that all of the yaml shown is abbreviated and does not show any complete files. The sample resources presented in the following section already have these steps applied, so you do not have to perform the steps below. The detailed instructions are given because there are a number of steps to adding any property to a Tekton pipeline successfully. Follow these instructions if you want to add further properties to the process as a result of using an alternative GitHub action such as a pull request validation for example.
- Identify the fields that are required to be extracted from the webhook payload.
- Add such fields to the trigger binding as shown below. The value field references the body from the webhook payload.
Spec:
params:
- name: commit.id
value: $(body.head_commit.id) - Add the field as an incoming parameter to the top of the trigger template as shown below:
spec:
params:
- name: commit.id - Add the field as a parameter to pass to the pipeline in the following part of the trigger template. The yaml below shows the incoming parameter from the trigger binding identified as params.commit.id being passed to the pipeline under the identifier commit_id.
resourcetemplates:
- apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
generateName: liberty-rest-app-run-pr-tr-
spec:
pipelineRef:
name: liberty-rest-app
params:
- name: commit_id
value: $(params.commit.id) - Add the field as an incoming parameter to the top of the pipeline as shown below:
apiVersion: tekton.dev/v1beta1
kind: Pipeline
name: liberty-rest-app
spec:
params:
type: string
- name: commit_id - Add the parameter to the list of parameters passed to the required task within the pipeline as shown below. The incoming commit_id parameter for the pipeline is passed to the task create-runtime-image under the same name.
tasks:
- name: create-runtime-image
params:
- name: commit_id
value: $(params.commit_id)
taskRef:
kind: Task
name: create-runtime-image - Add the field as an incoming parameter of type string to the top of the task called create-runtime-image.
kind: Task
metadata:
name: create-runtime-image
spec:
params:
- name: commit_id
type: string - Create references to where the parameter is used within commands in a step. In this example, the parameter is added as a label to the dockerfile that is used to create the runtime image.
steps:
- name: gen-binary-extraction-dockerfile
command:
- /bin/sh
- '-c'
args:
- |-
## Sequence of commands reduced. Look here for the more details.
echo "LABEL github.commit.id=\"$(params.commit_id)\"" >> d-file.gen
echo "------------------------------"
cat d-file.gen
echo "------------------------------"
image: registry.redhat.io/ocp-tools-43-tech-preview/source-to-image-rhel8
The above steps are summarised in the diagram in figure 5:
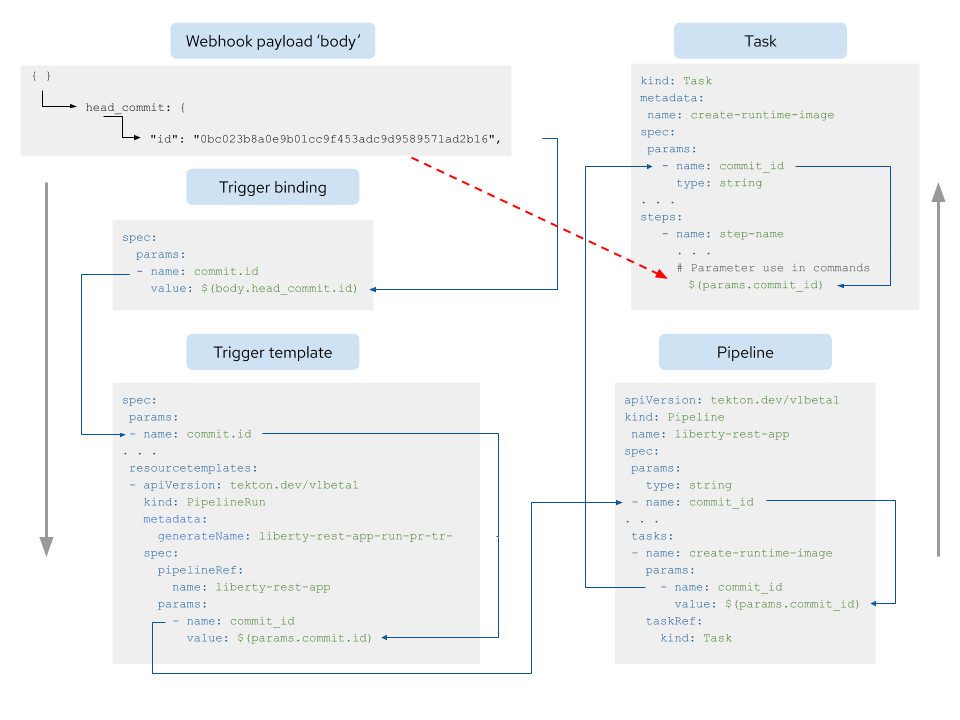
Figure 5: Sequence of information to be added to get a webhook payload value into a Tekton step
Pipeline contextual information in the image
In addition to the storing of Github data in the final image, it is also possible to store information about the pipeline, pipeline run, and task in the image, too. This is possible in the versions of OpenShift Pipelines beyond version 4.5 as shown in figure 4 above. The information to be added to record the pipeline name and the pipeline run name are:
- name: pipelineName
value: $(context.pipeline.name)
- name: pipelineRunName
value: $(context.pipelineRun.name)
The above fields are added to the pipeline field definitions at the top of the file. Within the task, the parameters are added as input parameters (similar to the commit_id in step 8 above), and then the parameters are used within the step in a similar way to the commit_id in step 9 above.
The task identifier is simply added to the step where it needs to be used as $(context.taskRun.name) with no prior definition step needed.
WebHook payload properties
The commit ID is not the only useful property from the GitHub webhook payload to be stored in the image. The example presented in the GitHub project associated with this article contains the following properties:
|
WebHook Payload |
Example |
|
body.repository.html_url |
|
|
body.repository.full_name |
marrober/pipelineBuildExample |
|
body.head_commit.id |
0bc023b8a0e9b01cc9f453adc9d9589571ad2b16 |
|
body.before |
Ac8c3f152e2941685f36681d49ba7756749a3eda |
|
body.ref |
refs/heads/experiment |
|
body.head_commit.timestamp |
2020-10-08T09:38:31+01:00 |
|
body.head_commit.message |
Commit message text |
|
body.head_commit.author.name |
Commit user full name |
Note that other properties are available depending on the webhook action that you are using as a trigger.
Inspecting the image
Assuming that the previous articles mentioned at the start of this document have been used as the source material, a new image will have been pushed to OpenShift and to Quay.io. To view the result of applying the labels, use a command similar to that below to inspect the image:
skopeo inspect docker://quay.io/marrober/liberty-rest:latest | jq '.Labels'
The result of this will display something similar to:
{
"architecture": "x86_64",
"build-date": "2020-09-01T19:43:46.041620",
"github.commit.date": "2020-10-12T11:35:23+01:00",
"github.commit.id": "7e055dcf77836373d0b3b05144d2ec81a824d9d3",
"github.commit.ref": "refs/heads/experiment",
"github.commit_author": "Mark Roberts",
"github.repository.fullname": "markroberts-rh/pipelineBuildExample",
"pipeline.name": "liberty-rest-app",
"pipeline.run": "liberty-rest-app-run-pr-tr-kcp2f",
"pipeline.task.run.name": "liberty-rest-app-run-pr-tr-kcp2f-create-runtime-image-qr8w7",
"release": "8",
}
Conflict of Pipelines
If a pipeline and set of tasks have additional properties added to them to support the gathering and use of data from a webhook payload, then care must be taken when running the pipeline without using a webhook. For example, a triggerBinding can be used to extract a value of the property body.head_commit.id from the payload and supply it to the trigger template using a value of commit.id. The pipeline expects a value to be provided for the property commit_id and if a value is not supplied the pipeline run will result in an error. To overcome this, add blank entries to the pipeline run that will be used to call the pipeline from outside the scope of a webhook. Figure 6 shows this issue resolved pictorially, with the manually executed pipeline run on the right hand side containing a blank parameter for commit_id.
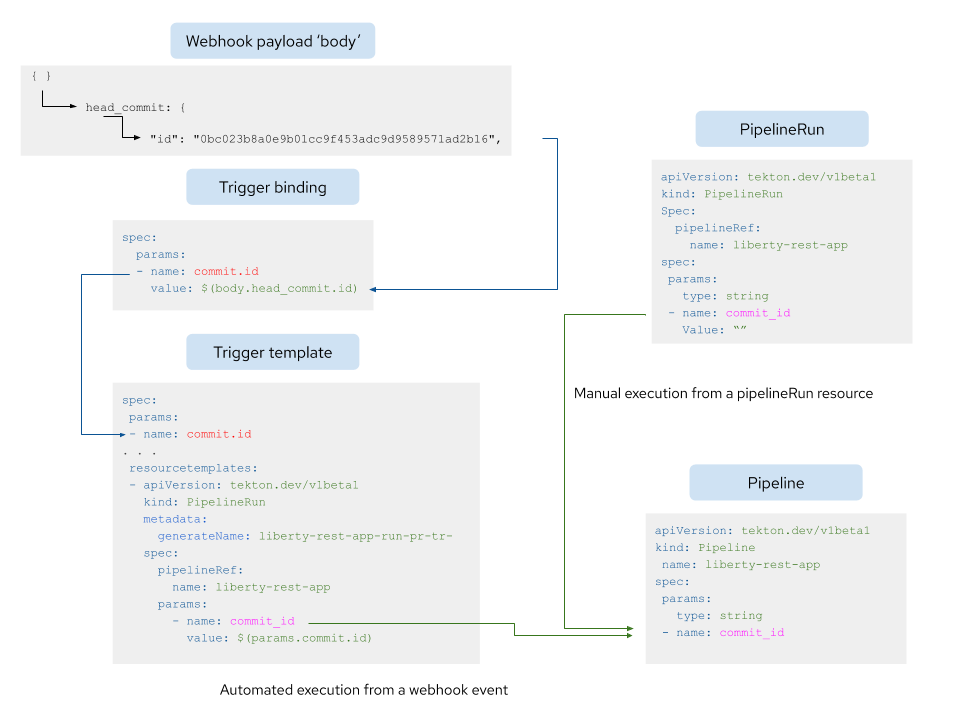
Figure 6: Resolving the issue of webhook properties when calling a pipeline by hand
Using the example assets to create a triggered build
- The assets required for the pipeline are located here. Since the triggering process requires you to be able to push changes to the GitHub repository, you must fork the repository into your own GitHub account instead of simply cloning it.
- If you do not already have one, create a quay.io account.
- Once you have forked a copy of the GitHub repository, clone your copy to create a local file system using the git clone command.
- Switch to the triggers branch using the command: git checkout triggers. This is important to ensure that you have the version of the tasks that respond to the injection of properties from the webhook payload.
- On the local copy of the assets, there are a small number of changes to make.
- Change the GitHub repository location in the file build/resources/sourceCode-GitResource.yaml.
- If you choose to use a different project name on OpenShift, change all instances of “namespace: liberty-rest” and also change the “5000/liberty-rest/” in build/resources/imageStreamResource-liberty-rest-app.yaml too.
- In the file build/pipelineRun/pipelineRun.yaml change the value of the property quay-io-account to match your Quay.io account name. Ensure that the value for property quay-io-repository matches a repository that you create under your quay.io account; see below. Repeat this process for the same properties in the file build/triggers/triggerTemplate.yaml.
- On your OpenShift cluster, ensure that the OpenShift Pipelines operator is installed with the version above version 4.5 as shown in figure 4. At the time of writing, this version is currently identified as ‘preview,’ but this can be expected to change to version 4.6 in the future.
- Create the new project using the command: oc new-project liberty-rest. Use a different name for the project if you have made the changes as indicated in step 4.b above.
- Go to the build directory of your cloned repository and issue the command: create-tasks.sh to create the resources.
- Create a quay.io authentication secret:
- Create an account on quay.io if you do not already have one.
- Log in to quay.io in the web user interface and click on the username in the top right corner.
- Select account settings.
- Click the blue hyperlink ‘Generate Encrypted Password’.
- Re-enter your password when prompted.
- Select the second option in the pop up window for ‘Kubernetes secret’ .
- Download the file.
- Create a repository in the quay.io account to match the OpenShift project name.
- Edit the secret file to change the name of the secret to be: quay-auth-secret.
- Create the secret using the command: oc create -f <filename>
- Create the trigger resources by executing the command: create-trigger-resources.sh
- You now need to identify the route to be used within the GitHub webhook. Execute the command below to locate the route for the trigger listener:
oc get route/liberty-rest-github-listener-el -o jsonpath='{"http://"}{.spec.host}{"\n"}'Copy the resulting URL.
- In GitHub locate the relevant repository and select ‘settings’ and then select ‘webhook’ from the left hand side. Create a new webhook with the following settings:
- Paste the route URL copied at step 11 into the payload URL field.
- Select content type: application/json.
- For the setting “Which events would you like to trigger this webhook?” select “Just the push event.”
- Everything is now ready. Make a small change to the application source code, commit the code to GitHub with a meaningful comment, and push the change to the remote GitHub repository. A suggested change is to replace the characters after Java Home in the file src/main/java/io/liberty/guides/rest/PropertiesJavaHome.java.
- Watch the webhook event appear in GitHub (you may need to refresh the browser page), and then watch the pipeline run start in the OpenShift web user interface.
- Watch the pipeline run execute and then examine the resulting image on quay.io using the skopeo command indicated above. Alternatively you can pull the image locally to your computer using buildah pull and then inspect the image using buildah inspect.
Summary
This article explains the use of Tekton resources to create webhook triggers to initiate pipeline activity from a user action in GitHub. Further areas to explore include the use of multiple triggers for different purposes, filtering the webhook payload using an application on OpenShift to ensure that just the required actions result in builds, and triggering deployment actions for higher environments as a result of activities in GitHub. These areas and more will be explored in further blogs in this series.
About the author
More like this
The agentic paradox and the case for hybrid AI
The new reality of supply chain trust: Why platform-native security is non-negotiable
Command Line Heroes: Season 2: Bonus_Developer Advocacy Roundtable
Frameworks And Fundamentals | Compiler: Stack/Unstuck
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds