
With the release of Helm v3 as TechPreview on OpenShift 4 users and developers now have a wide variety of options to package and deploy software on OpenShift clusters. This became possible since Helm v3 does not rely on the Tiller component anymore that previously brought up a lot of security concerns.
With this new packaging option, users can now choose to deploy their software via OpenShift Templates, oc new-app, Helm v3 charts and Operators.
Leveraging the Operator SDK users since Helm v2 already have a supported option to leverage Helm charts on OpenShift. With the SDK any Helm chart can be converted into a fully functional Operator and deploy it on cluster in a consistent manner with the Operator Lifecycle Manager. From there on, the Operator would serve Helm releases from that chart as a service.
This is a two part blog series aiming to provide some guiding information for users starting out with Helm charts or looking for ways to package their software on top of OpenShift. The first part will discuss the differences between Helm and Operators. In the second part we are going to compare Helm Charts and Helm-based Operators.

Part I - Helm and Operators
Helm charts lend themselves very well to package applications which lifecycle can entirely be covered by built-in capabilities Kubernetes. That is, they can be deployed simply by applying Kubernetes manifests while leveraging the Helm templating syntax to customize how these objects get created. Updates to software versions and configuration are conducted by updating/replacing the Kubernetes objects. This does not manage to take applications internal state into account however, hence stateless applications fit this pattern best.
Day-1 Operations with Helm
In v3, Helm is used entirely through the helm CLI which is a utility usually run interactively outside of the cluster. Users simply find a chart for the desired software and customize its resources through Helm to deploy Kubernetes artifacts which eventually bring up said software.
After this deployment step the deployed software runs in an unmanaged fashion. That is, updates to either the software or the chart require users to notice and act manually. Manual changes to the deployed Kubernetes resources are accepted as long as they do not prevent a 3-way merge, but should be avoided to keep complexity down. Being based on explicit invocation through the helm CLI, deletions or changes to objects that are part of the charts will not be detected until the next time the Helm CLI is run. Since Helm has no visibility into the applications state additional manual steps are required in order to determine the success of the deployment.
Upgrading to a newer version of the chart needs to be treated with care: not all modifications are allowed, for example increasing the volume size in a StatefulSet’s volumeClaimTemplate. In such a case the current deployment needs to be recreated. Other changes are allowed but potentially disruptive and can result in data loss, for example when the chart changes from using Deployment to StatefulSets.
While access to Helm charts themselves is managed outside the cluster, the ability to deploy resources is subject to users RBAC since Helm v3.
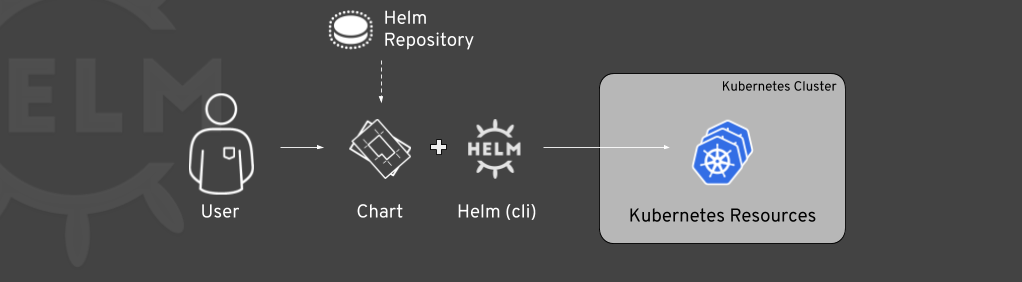
This is easy to get started with and works well for distributed apps that do not maintain state. More complex applications, especially stateful workloads like databases or quorum-based distributed systems, need more careful orchestration. Although there are a lot of Helm charts available for such systems, they only enable the initial deployment. After that, Helms visibility into the workload ends.
However, especially in production these application types require ordered step-by-step sequences for typical Day-2 activities like updates and reconfiguration. To make matters more complex, these procedures need to take the applications internal state into account, in order to prevent downtime. For example: a rolling update of a distributed app may need to wait for the individual instances to regain quorum before proceeding to take out deployments. This becomes very difficult since Helm can only allow what Kubernetes supports out of the box, e.g. Deployment with basic readiness checks. Also, any advanced procedures like backup and restore can not be modeled with Helm charts.
Day-2 Operations with Operators
Enter Operators. These custom Kubernetes controllers are running on the cluster and contain application specific lifecycle logic. With the application state in mind, complex procedures like reconfiguration, updates, backups or restore can be facilitated through the Operator in a consistent fashion. For example: before a backup of a managed database the Operator providing this database is able to flush out the database log and then quiesce the write activity on the filesystem, therefore providing a application-consistent backup. Operators can also be aware of workloads deployed by a previous version of the Operator and migrate them safely to newer deployment patterns.
But even before that, Operators start with providing a Kubernetes-native user experience, that does not mandate any new skills or tools on the user side. Operators enable the consumption of their managed workloads through Kubernetes Custom Resources. Thus they offer a cloud-like user experience: users don’t need to be experts in how the application is deployed or managed but can rely on the Custom Resource as the sole interface to interact with them.
The Custom Resources appear and behave like standard Kubernetes objects. Instances of those Custom Resources represent managed workloads (usually deployed on the same cluster) and can be requested or reconfigured simply with the kubectl CLI.
Thanks to the application specific logic in the Operator’s controller, the application state can accurately be represented and reported through the status section of these Custom Resources, for example to convey access credentials to the user or live health data.
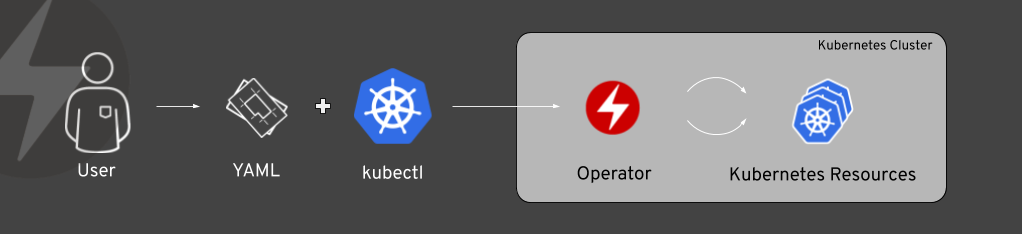
In contrast to Helm charts an Operator needs to be installed on the cluster first, usually by a user with a privileged role. But since they are running on the cluster in a constant software software loop, any manual change to provisioned resources are picked up immediately and rolled back, if diverging from the desired state. Multiple concurrent interactions on the same managed application are serialized and not blocked by a lock. Access to Operator services can be restricted via regular RBAC on the Custom Resources.
Verdict
In short: if the workload does not require any Day-2 operation beyond simple update/replace Kubernetes operations and resources are never manipulated manually, Helm is a great choice. There are a lot of charts available in the community that make it easy to get started, especially in test beds or development environments.
For everything else, Operators provide more application-aware logic for Day-2 operations that are especially important for production environments. Examples range from coordinated updates without downtime over to regularly running backup and even restore. They need to be installed first on cluster but interaction is then entirely handled via standard kubectl tooling leveraging Custom Resources. Projects like the Operator Lifecycle Manager aid cluster administrator in installing Operators and keep them updated. When deployed, Operators provide central orchestration and discovery, which is important to multi-tenant clusters. For individual users reconfiguration or updates to a managed application are as simple as changing a single value in Custom Resources. Creating a new resource can also trigger potentially complex workflows transparently in the background like backups and restore.
This way, users enjoy a cloud-like user experience, independently where the cluster is actually deployed.
About the author
More like this
Can't patch fast enough? Zero trust as a last line of defense
What's new with image builder for Red Hat Enterprise Linux 10.2 and 9.8
The Containers_Derby | Command Line Heroes
Can Kubernetes Help People Find Love? | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds