

Red Hat OpenShift with NVIDIA GPUs is a great platform for running containerized AI/ML workloads. In our previous article we explored cluster autoscaling – a powerful tool that can help you optimize your GPU-enabled clusters. Today, we will show how using precompiled GPU driver containers can reduce the provisioning time by about 50% (or 2 to 3 minutes in a test environment), and improve the general responsiveness of GPU autoscaling.
Precompiled Driver Containers
In order to successfully run workloads, a GPU in an OpenShift cluster needs a driver that matches the system of the cluster nodes. By default, the NVIDIA GPU operator will build a GPU driver for a particular operating system, kernel version, and architecture on the fly, in-cluster, using a suitable Driver Toolkit (DTK) Image. With this approach, driver compilation and packaging is done on every new node, leading to wasted resources and long provisioning times.
A while ago, NVIDIA added a feature that allowed using precompiled driver binaries from a container image, instead of building them on demand. NVIDIA also published driver container images for Ubuntu, as well as a procedure for building custom images.
Recently, code for building precompiled driver images for Red Hat Enterprise Linux (RHEL) became available, and we set out to test how using precompiled drivers affects autoscaling.
Testing Methodology and Result
Resetting a Cluster Policy
If our assumption is correct and precompiled driver images makes installing a GPU driver as easy as pulling and unpacking an image, then using them should shorten the time it takes for a node's GPU capacity to get discovered.
In our first test, we make sure the GPU capacity of a node has been cleared, then apply a cluster policy and poll the node until it lists at least one GPU. For example:
status:
capacity:
nvidia.com/gpu: '1'
After that the ClusterPolicy resource is deleted to clear the GPU capacity. We repeat the test a few times with a conventional ClusterPolicy resource, and then with a ClusterPolicy that includes a precompiled driver image definition:
driver:
usePrecompiled: true
image: nvidia-gpu-driver
repository: quay.io/vemporop
version: 525.125.06
On a Red Hat OpenShift 4.13 cluster with a NVIDIA Tesla T4 worker node (g4dn.xlarge AWS machine type), it took on average 308 seconds to make the GPU available when building the driver on the fly, and only 132 seconds when using a precompiled driver image. We do not include the first sample in this calculation because in both cases the NVIDIA GPU operator had to pull images from a remote registry to the node (DTK for in-cluster builds).
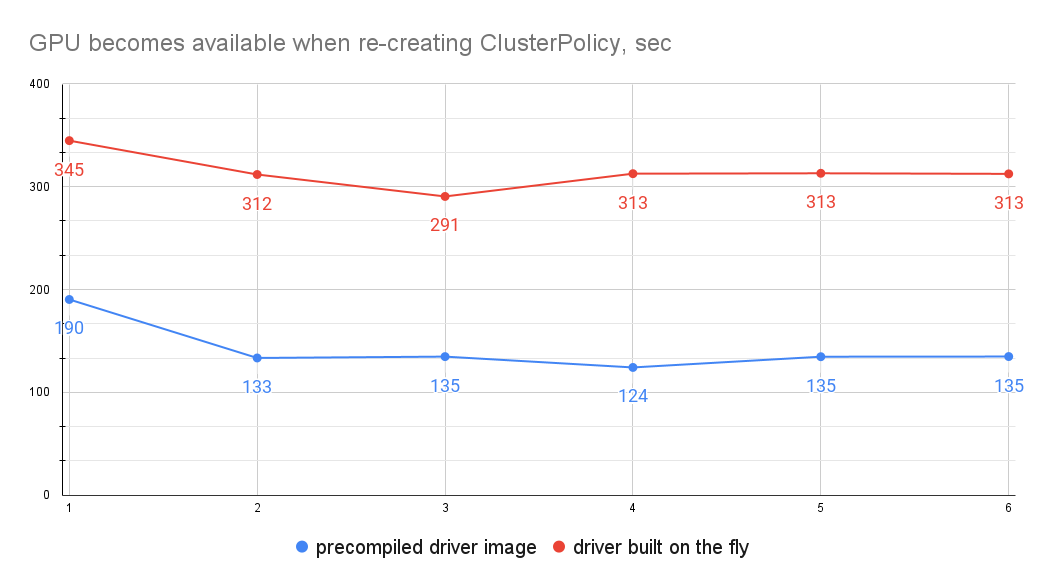
Cluster Autoscaling
We have to admit that the cluster policy test is somewhat synthetic, so let's see how real autoscaling measures. In order to do that, we – well – trigger cluster autoscaling by repeatedly adding (scale up) and removing (scale down) a GPU workload. We measure the time between the moment a new node is ready, and the moment the GPU workload can actually run on it.
The scenarios that were tested:
- The GPU drivers are built on the fly.
- A precompiled driver image is hosted in a public quay.io registry.
- A precompiled driver image is hosted in the OpenShift image registry.
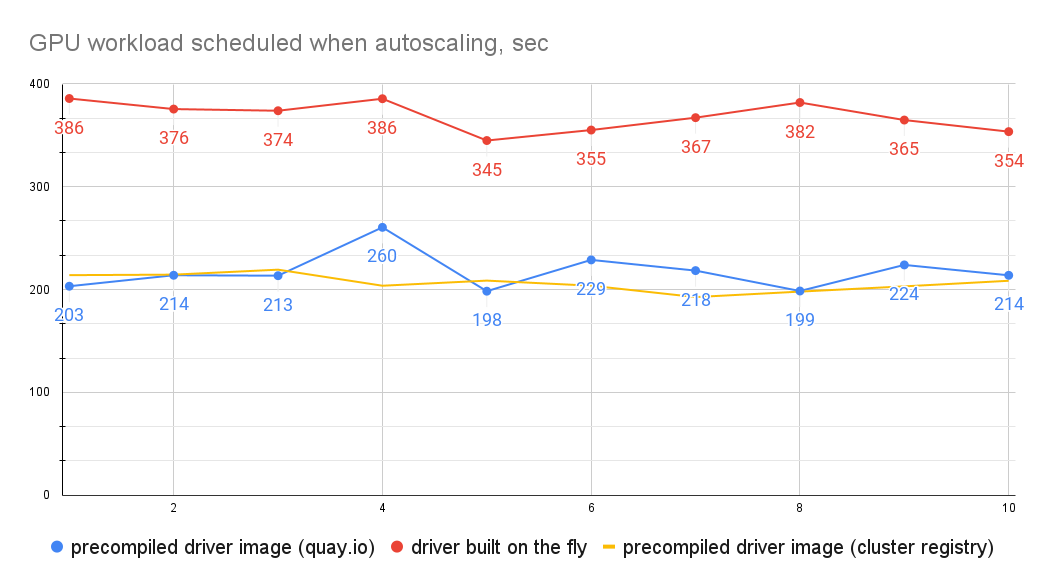
As you can see, there is a significant difference between the GPU provisioning time when the driver is built on the fly and when using a precompiled driver container. It took on average 369 seconds to set up an on-the-fly driver, vs 217 and 207 seconds with precompiled drivers.
We did not observe any significant difference between a remote and cluster registry, probably because:
- The remote image was eventually cached in the cluster anyway.
- A good upstream connection makes differences in the download times negligible.
However, the OpenShift image registry will definitely have benefits for hosting precompiled driver images in a disconnected environment.
Another point to notice is that the time improvement of the precompiled containers over in-cluster builds is not as striking as in the cluster policy case. This is because a newly added node requires a fair amount of heavy lifting before the GPU driver setup kicks in. In general, node provisioning during cluster autoscaling is relatively slow. In any case, using precompiled drivers can still allow you to cut between 2.5 and three minutes off that time!
But more importantly, it turns out that using precompiled drivers will also allow you to shorten the autoscaling timers, such as maxNodeProvisionTime and unneededTime, making your cluster autoscaler more responsive. You can read a detailed explanation of the problem in the original Autoscaling NVIDIA GPUs on Red Hat OpenShift blog post, but here is a quick reminder:
A node that is not considered ready within the maxNodeProvisionTime, will be deleted and replaced with another one until successful, thus increasing the total time until a GPU workload can be scheduled, and wasting money on cloud instances. The chances for this to happen are high with GPUs because they do not belong to core Kubernetes resources.
Our rough tests show that we had to set conservative autoscaling timers when using the conventional GPU driver flow, but could significantly reduce them when using precompiled drivers. Keep in mind though that we did not conduct thorough testing of the autoscaling timers, and recommend fine tuning them in every customer environment anyway.
Conclusion
NVIDIA precompiled driver containers, now available on OpenShift, bring noticeable improvements to cluster autoscaling performance among other benefits. They shorten the GPU worker node provisioning time by two to three minutes in a typical cloud environment. And this improvement is not just about GPU discovery, but also how responsive your cluster autoscaler can be in general.
About the author
More like this
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Why Red Hat partners are the ultimate telco business asset
Machine learning model drift & MLOps pipelines | Technically Speaking
Building a foundation for AI models | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds