Introduction
When adopting Kubernetes or OpenShift, most enterprises opt for a centralized (or enterprise) container registry. This is the registry in which all of the container images are stored, and from which all Kubernetes clusters can pull (other registries are normally blocked for security reasons).
Many security-conscientious companies also have the requirement that different tenants of the platform should not be able to push and pull images to and from repositories that they do not own. Typically, a development team will be granted access to either a few repositories within the registry, or a namespace for which they have some autonomy to create repositories as they see fit.
This then translates to having credentials be created with the appropriate permissions for each team and apply those credentials in the correct clusters/namespaces (where a given team is allowed to operate).
This is a relatively challenging problem to solve at scale, and what we often see is that companies create a ticket-based process around managing these credentials (which end-up being deployed in Kubernetes as docker secrets). Also, these credentials are long-lived or in some cases, never-expiring to minimize the pain of working through the process on a regular basis.This creates friction and typically slows down the overall team on-boarding process. At the same time, the security stance of this setup is typically not ideal.
In this blog post, we will showcase an approach aimed at automating the provisioning of narrowly-scoped and short-lived pull secrets within Kubernetes environments.
Design
The following is a high-level overview of this approach:
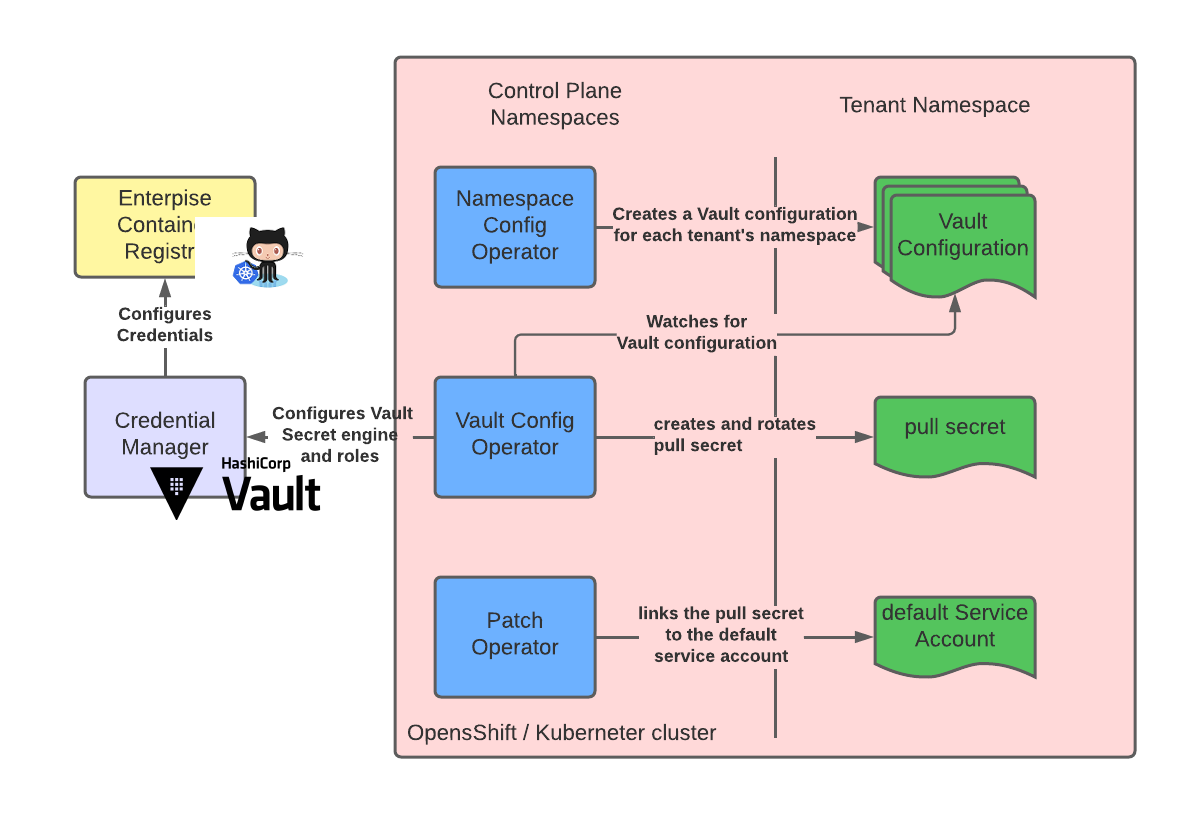
In the diagram above, HashiCorp Vault acts as the secrets management tool and is configured with a secret engine suitable to create credentials within the enterprise container registry.
To support configuring Vault in a declarative way, we use the vault-config-operator.
This operator helps with declaratively configuring Vault, which itself presents imperative APIs.
A more in depth discussion of the raison d’etre and design of vault-config-operator can be found here. This operator will also aid in the creation of a pull secret in each namespace by reflecting and formatting a Vault secret into a Kubernetes secret. In addition, it will also manage secret rotation as well.
In order to create tenant- and namespace-specific configurations, we use the namespace-config-operator.
Finally, to attach the pull secret to the default service account, we will use the patch-operator.Let’s break this process down in its constituent parts and see how a real world example would look. For the registry implementation, the GitHub container registry.
HashiCorp Vault
In order to create an implementation that could support multiple container registry products, we need a solution that provides an interface for managing the credentials and the associated access to them.
HashiCorp Vault is good at this task as it features secret engines. Secret engines are plugins that interface with an API endpoint and create credentials for it. Vault has the added benefit that it will also manage credentials protection in an encrypted storage, credential rotation, access management to these credentials etc… .
Many of secrets engines for container registries are community-supported secrets engines that you will need to install separately. These community plugins include GitHub, Artifactory, and Quay.
In terms of plugin coverage of the major container registry products, there is little among the officially supported secret engines. There are, however, unsupported secret engines for GitHub Container Registry, Artifactory, and Quay.
This was good enough to support the creation of the PoC that we are going to discuss in this article.
For our purposes, Vault can run anywhere. But, if you are interested in installing in your OpenShift cluster, this tutorial can help you.Also, take note that when using custom plugins, some additional installation steps are required to make the plugins available to Vault.
Single Tenant End-to-end Configuration
To implement the design described above, we will have to perform the following steps:
- Configure the GitHub secret engine.
- For each tenant, configure a GitHub secret engine role that is scoped down to only allow access to pull from a limited list of repositories.
- Configure a VaultSecret to create (and rotate) a pull secret in each tenant namespace based on the dynamically generated GitHub credentials.
Before we proceed, take note that in this example, we assume we have correctly initialized Vault to be managed by the vault-config-operator. For the purpose of this example we need a service account in a namespace to be provisioned high-level privileged in Vault.
In our case we use the vault-admin namespace and the default service account. This account will be allowed to login to Vault with the policy-admin Vault role. This Vault role has enough permissions to perform the required steps that are explained in the rest of this article.
You can generate this configuration with the following commands against your Vault instance:
vault auth enable kubernetes
vault write auth/kubernetes/config token_reviewer_jwt=@<token file> kubernetes_host=<kubernetes master api endpoint> kubernetes_ca_cert=@<ca cert file>
vault write auth/kubernetes/role/policy-admin bound_service_account_names=default bound_service_account_namespaces=vault-admin policies=vault-admin ttl=1h
cat << EOF | vault policy write vault-admin -
path "/*" {
capabilities = ["create", "read", "update", "delete", "list","sudo"]
}
EOF
See also the Vault Kubernetes authentication method for more information on how to perform the initial Vault configuration.
Configure the GitHub Secret Engine
Configuring a secret engine in Vault is generally composed of two steps: creating the engine mount and configuring the engine connection to the endpoint for which credentials will be generated. This can be accomplished for GitHub starting with a SecretEngineMount resource as shown below:
apiVersion: redhatcop.redhat.io/v1alpha1
kind: SecretEngineMount
metadata:
name: github
spec:
authentication:
path: kubernetes
role: policy-admin
type: vault-plugin-secrets-github
path: ""
This will create the engine mount and given this configuration, the GitHub secret engine will be available at the path: /github Then, we need to configure the connection to GitHub, this can be accomplished with a GitHubSecretEngineConfig:
apiVersion: redhatcop.redhat.io/v1alpha1
kind: GitHubSecretEngineConfig
metadata:
name: github
namespace: vault-admin
spec:
authentication:
path: kubernetes
role: policy-admin
sSHKeyReference:
secret:
name: vault-github-plugin-creds
path: github
applicationID: <my vault app id>
organizationName: <my organization>
This manifest configures Vault to talk to GitHub (you can also pass a URL to connect to a local GitHub Enterprise instead).
For Vault to manage GitHub credentials, a GitHub application must be created (as specified here) and the SSH private key generated as part of the application creation must be stored as a Kubernetes secret, which is then referenced in the manifest along with the Application ID. The name of the GitHub organization that this secret engine will manage is also specified.
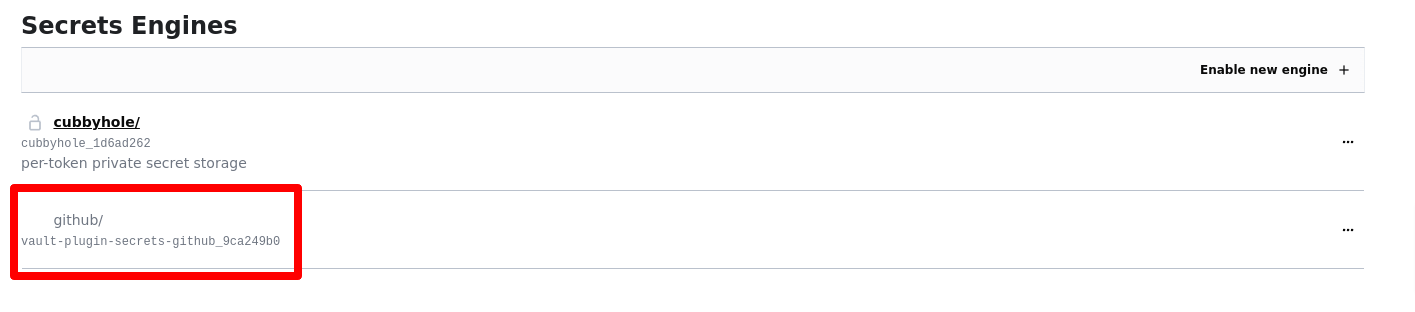
After this phase, if you navigate to the Vault UI, a depiction similar to the following should be present on the Secrets Engines page:
Configure the Tenant-Specific GitHub Secret Engine Role
Now that we have the secret engine configured, we need to configure the tenant roles.
First, we need to make sure that tenants can only request their assigned and restricted Vault roles. This can be accomplished by creating an authentication role with a tenant-specific Vault policy using a KubernetesAuthEngineRole custom resource:
apiVersion: redhatcop.redhat.io/v1alpha1
kind: KubernetesAuthEngineRole
metadata:
name: <team-name>-vault-role
spec:
# Add fields here
authentication:
path: kubernetes
role: policy-admin
path: kubernetes
policies:
- <team-name>-github-read-token
targetNamespaces:
- <team-namespace1>
- <team-namespace2>
...
targetServiceAccounts:
- default
apiVersion: redhatcop.redhat.io/v1alpha1
kind: Policy
metadata:
name: <team-name>-github-read-token
namespace: vault-admin
spec:
# Add fields here
authentication:
path: kubernetes
role: policy-admin
policy: |
# create tokens
path "/github/token/<team-name>" {
capabilities = ["read"]
}
Now, with this configuration in place, the default service account token in the teams’ namespaces will be able to read only from the path /github/token/<team-name>
At this point, we can create the GitHub engine role with the narrowly scoped permissions for GitHub resources. The goal here is for a team to be able to pull only from a limited set of repositories.
apiVersion: redhatcop.redhat.io/v1alpha1
kind: GitHubSecretEngineRole
metadata:
name: <team-name>
namespace: vault-admin
spec:
authentication:
path: kubernetes
role: policy-admin
path: github
repositories:
- https://github.com/<org-name>/<team-repo1>
- https://github.com/<org-name>/<team-repo1>
...
permissions:
packages: read
At this point, you should be able to read a GitHub secret from Vault and get a result similar to the following:
vault read github/team-a/token
Key Value
--- -----
lease_id github/team-a/token/D64WzTCJNqW4mV05jy9lBo4l
lease_duration 1h
lease_renewable false
expires_at 2022-01-12T03:03:56Z
permissions map[packages:write]
repository_selection all
token ghs_XXXXXXXXXXXXXXXXXXXXXXXXX
Creating the Pull Secret
Now that narrowly-scoped and short-lived GitHub credentials can be read from Vault, we need to place them in a Kubernetes pull secret so that they can be used to pull images. This can be accomplished with the following configuration:
apiVersion: redhatcop.redhat.io/v1alpha1
kind: VaultSecret
metadata:
name: github-pull-secret
namespace: <team-namespace>
spec:
vaultSecretDefinitions:
- authentication:
path: kubernetes
role: <team-name>-vault-role
serviceAccount:
name: default
name: githubtoken
path: github/token/<team-name>
output:
name: github-pull-secret
stringData:
.dockerconfigjson: |
{"auths":{"ghcr.io":{"username":"team_puller","password":"{{ .githubtoken.token }}","email":"team_puller@example.com","auth":"{{ list "team_puller:" .githubtoken.token | join "" | b64enc }}"}}}
type: kubernetes.io/dockerconfigjson
The VaultSecret resource references one or more secrets in Vault via the vaultSecretDefinitions field and then creates a Kubernetes secret using a template that receives the Vault secrets as input and is defined in the output field. The controller looking after VaultSecret also takes care of rotating and refreshing the secret if the credentials provided by vault have an expiration date.
The reflected secret will be configured similar to the following:

We will have to apply this configuration in every tenant namespace; which brings up the question: How can we manage this at scale?
Managing the Configuration at Scale
We can use the namespace-config-operator to automate configurations for multiple tenants. More details on how to manage tenant’s namespaces with the namespace-config-operator can be found here. Following some of the guidance from referenced article, we assume that our namespaces are labeled and annotated as follows:
kind: Namespace
apiVersion: v1
metadata:
name: <namespace-name>
labels:
team: <team-name>
annotations:
allowed-repositories: https://github.com/<org-name>/<team-repo1>,https://github.com/<org-name>/<team-repo1>
In short, we have a label identifying the team and an annotation containing a comma-separated list of repositories from which this team can pull images from.
Notice that since tenants are not allowed to edit the contents of the namespace resource, we can trust that these details will not be modified.
It is out of the scope of this article to discuss how the namespaces were created with the needed labels and annotations.
With the above assumption on how tenant namespaces are configured, we can create the following namespace configuration which will take care of all of the configuration discussed in the previous section for all the tenant namespaces:
apiVersion: redhatcop.redhat.io/v1alpha1
kind: NamespaceConfig
metadata:
name: team-github-vault-role
spec:
labelSelector:
matchExpressions:
- key: team
operator: Exists
templates:
- objectTemplate: |
apiVersion: redhatcop.redhat.io/v1alpha1
kind: KubernetesAuthEngineRole
metadata:
name: {{ .Labels.team }}-vault-role
namespace: vault-admin
spec:
# Add fields here
authentication:
path: kubernetes
role: policy-admin
path: kubernetes
policies:
- {{ .Labels.team }}-github-read-token
targetNamespaces:
targetNamespaceSelector:
matchLabels:
team: {{ .Labels.team }}
targetServiceAccounts:
- default
- objectTemplate: |
apiVersion: redhatcop.redhat.io/v1alpha1
kind: Policy
metadata:
name: {{ .Labels.team }}-github-read-token
namespace: vault-admin
spec:
# Add fields here
authentication:
path: kubernetes
role: policy-admin
policy: |
# create tokens
path "/github/token/{{ .Labels.team }}" {
capabilities = ["read"]
}
- objectTemplate: |
apiVersion: redhatcop.redhat.io/v1alpha1
kind: GitHubSecretEngineRole
metadata:
name: {{ .Labels.team }}
namespace: vault-admin
spec:
authentication:
path: kubernetes
role: policy-admin
path: github
# TODO filter down repos
repositories:
{{ range (splitList "," .Annotations.allowed-repositories) }}
- {{ . }}
{{ end }}
permissions:
packages: read
- objectTemplate: |
apiVersion: redhatcop.redhat.io/v1alpha1
kind: VaultSecret
metadata:
name: github-pull-secret
namespace: {{ .Name }}
spec:
vaultSecretDefinitions:
- authentication:
path: kubernetes
role: {{ .Labels.team }}-vault-role
serviceAccount:
name: default
name: githubtoken
path: github/token/{{ .Labels.team }}
output:
name: github-pull-secret
stringData:
.dockerconfigjson: |
{"auths":{"ghcr.io":{"username":"team_puller","password":"{{ "{{" }} .githubtoken.token {{ "}}" }}","email":"team_puller@example.com","auth":"{{ "{{" }} list "team_puller:" .githubtoken.token | join "" | b64enc {{ "}}" }}"}}}
type: kubernetes.io/dockerconfigjson
At this point, a Kubernetes secret named github-pull-secret will be present in each tenant namespace.
For tenant deployments to take advantage of consuming the provisioned pull secret, they have to specify that secret in the pod definition imagePullSecret field.
So, how can we improve the user experience so that our tenants do not have to remember to specify the pull secret? One way is to link the pull secret with the default service account so that it will be used automatically.
Linking the Pull Secret with the Default Service Account
The goal is to have the default service account linked with the provisioned pull secret. This requires the service account resource to mention the pull secret in its imagePullSecrets field.
But, there is an issue with this approach. We do not own the default service account as it is managed by Kubernetes itself, so we cannot create the default service account manifest with the values we want. As a result, we instead need to patch the default service account in every tenant namespace.
The patch-operator can help with this. The Patch definition needed to update the default service account looks as follows:
apiVersion: redhatcop.redhat.io/v1alpha1
kind: Patch
metadata:
name: config-patches
namespace: openshift-config
spec:
serviceAccountRef:
name: default
patches:
puller-secret-service-account-patch:
targetObjectRef:
apiVersion: v1
kind: ServiceAccount
name: default
sourceObjectRefs:
- apiVersion: v1
kind: Namespace
name: '{{ "{{" }} .metadata.namespace {{ "}}" }}'
# gives github-pull-secret to all default service accounts in namespaces with the app label.
patchTemplate: |
imagePullSecrets:
{{ "{{-" }} if and (and (hasKey (index . 1).metadata.labels "app") (not (eq ((index . 1).metadata.labels.environment | toString) "build"))) (not (has (dict "name" "github-pull-secret") (index . 0).imagePullSecrets)) {{ "}}" }}
{{ "{{" }} append (index . 0).imagePullSecrets (dict "name" "github-pull-secret") | toYaml | indent 2 {{ "}}" }}
{{ "{{-" }} else {{ "}}" }}
{{ "{{" }} (index . 0).imagePullSecrets | toYaml | indent 2 {{ "}}" }}
{{ "{{-" }} end {{ "}}" }}
patchType: application/merge-patch+json
In this case, this patch is deployed in the openshift-config namespace in which the default service account has been given enough permissions to perform the patch (see this resource on how to set permissions for patches).
Conclusions
In this article, we demonstrated how to automate the provisioning of image pull secrets at scale (i.e. for multiple tenants hosted in the same cluster). Also, since these assets were provisioned using narrowly-scoped and short-lived credentials, this approach increases the security stance of tenant namespaces.
The example described in this article featured an integration with GitHub Container Registry, but additional plugins to support other container registries, such as Quay and Artifactory, are currently in development.
The approach discussed can be extended to other types of resources beyond image repositories.
For example, it can be used to provision credentials for applications needing to connect to middleware such as databases, messaging services, caches etc. For this use case Vault has definitely good coverage in terms of supported secret engines.
Another area in which this approach can probably be reused is CI/CD. In fact, if you run your pipelines in the cluster (by having the pipeline orchestrator create pods: slaves for Jenkins, runners for GitHub actions, pipelines for Tekton and so on…), you will likely need to provision credentials as Kubernetes secrets for all the endpoints the pipeline needs to talks to. Examples of integrations that a pipeline may need are: git repositories, container registry (for pushing this time), code scanning, image scanning, security scanning, signing services.
Overall, the idea of consuming narrowly scoped and short lived credentials which are declaratively configured and provisioned to the application needing it seems promising and is an area in which the Kubernetes community should invest more effort moving forward.
About the author

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
Building trust through AI red teaming: Red Hat's approach to testing model safety
A decade of open innovation: Red Hat continues to scale the open hybrid cloud with Microsoft
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds