NOTE: This blog has been updated to support RHACM 2.3 and beyond, as of March 28, 2022.
Introduction
Red Hat launched the Advanced Cluster Management (RHACM) for Kubernetes tool to enable and empower organizations to overcome the challenges of managing multiple Kubernetes clusters regardless of where they are (public cloud, private, bare metal, physical, edge).
When an organization that adopts Kubernetes starts deploying it in the environment, there will eventually be multiple Kubernetes clusters, ranging from a development, test, QA, and production cluster to clusters serving different types of workloads, purposes, in different infrastructures, or public clouds (multicloud). Then Kubernetes fleet management becomes the challenge that Advanced Cluster Management helps you address by bringing a single pane-of-glass delivering visibility of the fleet, life-cycle management of OpenShift clusters, seamless application deployment (GitOps), and governance and security management for the whole fleet.
That being said, since Red Hat Advanced Cluster Management brings end-to-end visibility to your fleet, it consolidates and centralizes all the metrics of all clusters it manages in a single place through leveraging a handful of technologies such as Thanos and Observatorium.
Thanos stores metrics of all Prometheus instances (Prometheus instances installed on each OpenShift or Kubernetes cluster) which means you have a single place to see metrics from different clusters, delivering a global view of the fleet.
Observatorium abstracts Thanos API and enables connectivity and access to Thanos data and is responsible for pulling metrics from all other Prometheus and pushing those into Thanos.
Challenges
Organizations that have implemented OpenShift and take advantage of Prometheus have consolidated their monitoring dashboards into one place. In these instances, a single Grafana deployment delivering dashboards by plugging into different Prometheus data sources. Although the aggregation of metrics and the creation of dashboards, support are responsibilities of your team since that Grafana deployment sits outside of the stack. The existing Grafana deployment can take advantage of theintegration with Observatorium and Thanos. This is because it has basically the same APIi structure, Also, Thanos consolidated the metrics from different Prometheus instances, it is easier to build your own monitoring dashboards with all the consolidation done for you in one place.
This blog post, however, will tackle how Grafana deployments can connect into Red Hat Advanced Cluster Management and use Observatorium and Thanos as the datasource for all the dashboards.
Prerequisites
- OpenShift 4.7+ installed
- Red Hat Advanced Cluster Management Hub cluster installed 2.3+
- Red Hat Advanced Cluster Management Observability installed
- Grafana version deployed
Scenario
You have been relying on your own Grafana to get metrics from multiple sources (Prometheus) from different clusters and have to aggregate the metrics yourself. With Red Hat Advanced Cluster Management and Observability, that work is done for you. You will only need to configure your Grafana to connect into Observatorium API (which interfaces with Thanos).
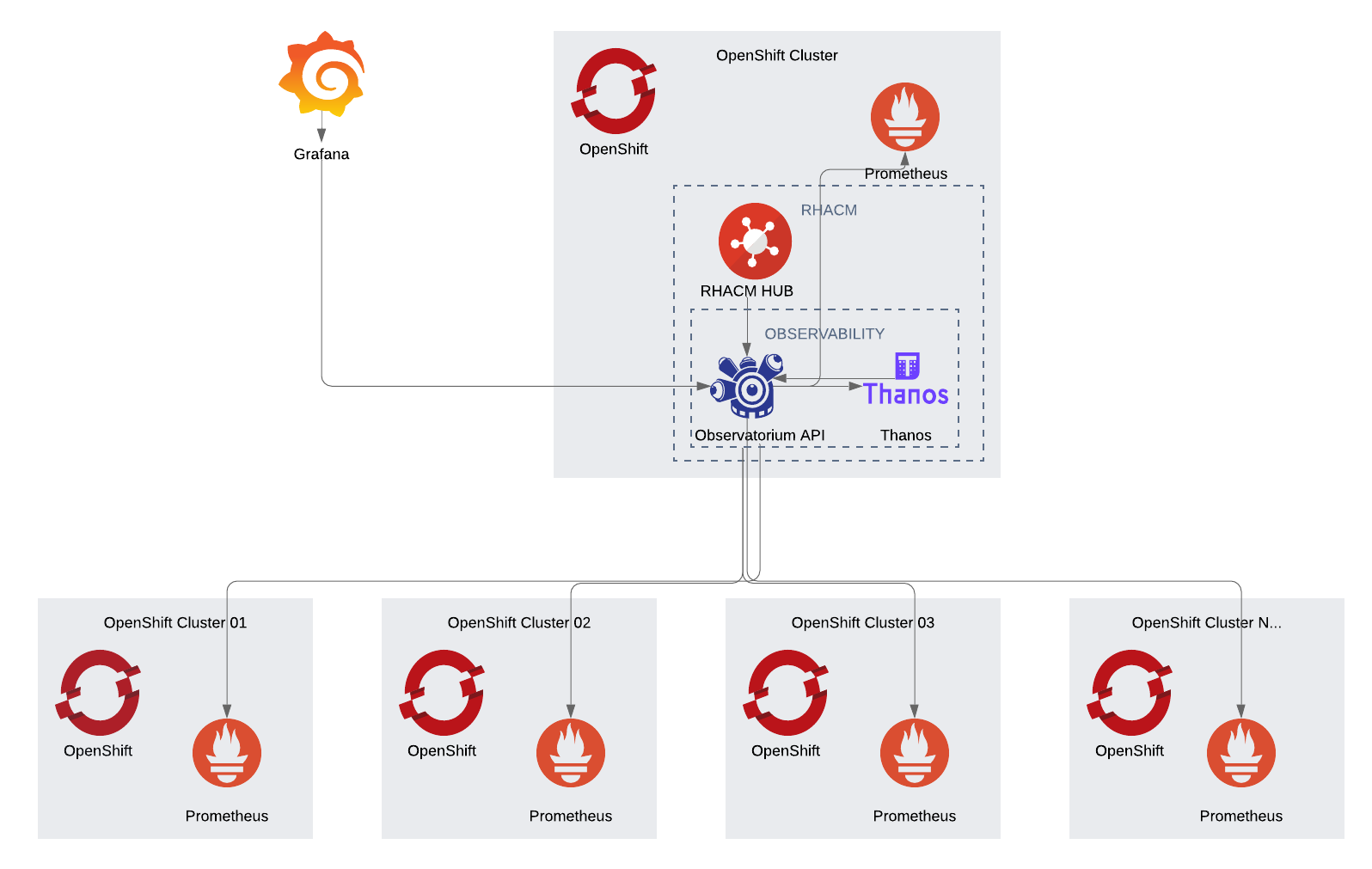
It is important to note that the RHACM Observability piece already installs a Grafana out of the box as part of the RHACM Observability stack. This scenario is specific to environments where teams had responsibilities for their own Grafana deployment and would like to fetch the consolidated metrics from RHACM Observability. It does not impede a team to use or transition to the supported Grafana deployment from within the RHACM Observability Operator.
However, before configuring your Grafana, you will need to follow the steps below to enable the Observatorium API route and get the appropriate secret contents to use as part of the connectivity configuration.
Getting the Route URL
Check the route (you will use it as the url for Grafana to connect to):
oc get route observatorium-api -o json | jq '.spec.host'
"observatorium-api-open-cluster-management-observability.apps.cluster-nbx49.nbx49.sandbox1073.opentlc.com"
Getting the Credentials
Now that you have the url, let's get the right credentials from the observability stack to later configure them on Grafana.(Disclaimer: In the current version 2.2.y, the secret names below are being used. It may change for next versions 2.3+.):
oc get secret observability-server-ca-certs -n open-cluster-management-observability
NAME TYPE DATA AGE
observability-client-ca-certs kubernetes.io/tls 3 70d
Get the CA content from this secret (either via oc cli or through the user interface):
Via OpenShift Console:

Via cli:
oc get secret observability-client-ca-certs -n open-cluster-management-issuer -o json | jq '.data."ca.crt"'
Save the content ca.crt somewhere. We are going to need this later to insert on the Grafana datasource set up.
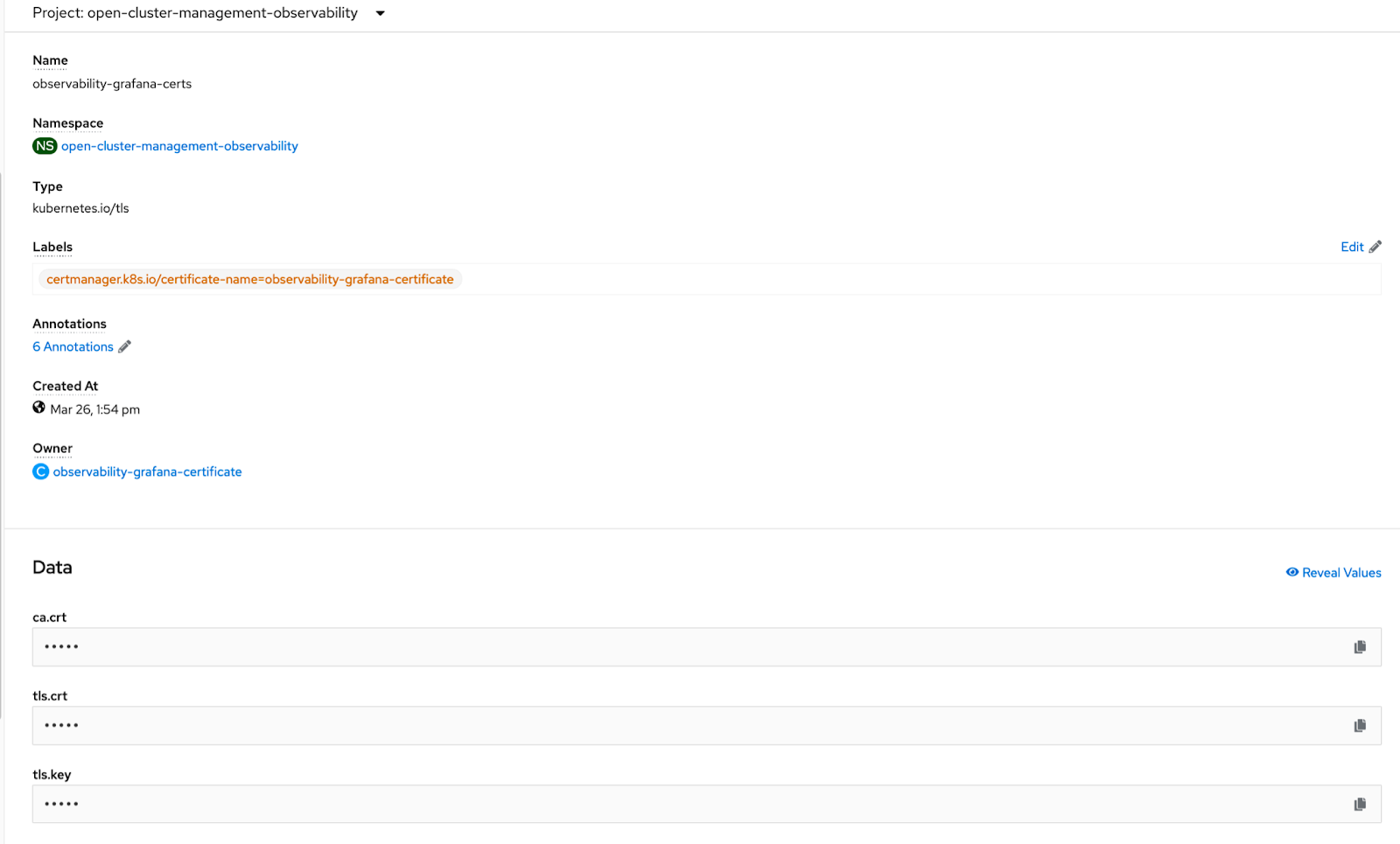
Then go ahead and copy the client certificate and key from the following secret:
oc get secret observability-grafana-certs -n open-cluster-management-observability
NAME TYPE DATA AGE
observability-grafana-certs kubernetes.io/tls 3 70d
Example through the Web Console:
Alternatively, you can get through the CLI by:
oc get secret observability-grafana-certs -n open-cluster-management-observability -o json | jq '.data."tls.crt"'
oc get secret observability-grafana-certs -n open-cluster-management-observability -o json | jq '.data."tls.key"'
Those will be needed for the next step.
Get the tls.crt and the tls.key content.
Configuring Grafana Datasource
In your Grafana, add a source such as Prometheus:
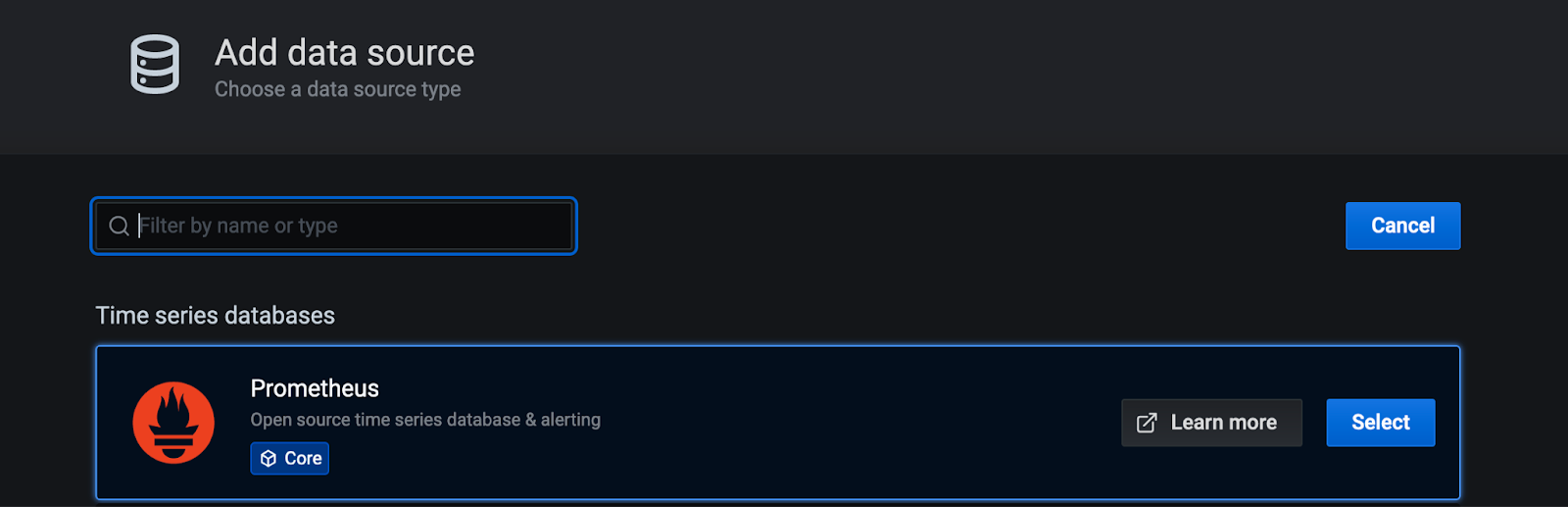
1. Now fill the fields with the information you got previously.
2. Paste the URL from the exposed route, then append a path “api/metrics/v1/default” to the route url
3. Check the TLS Client Auth and paste the client certificate and key once you see those fields enabled by Grafana UI.
4. Check the “With CA Cert” field and paste the CA certificate from the previous steps.
5. Optionally, you can check “Skip TLS Verify” if using a self-signed certificate.

Results
Now we can see the metrics from Observatorium by creating dashboards with the information.
Here it is a query to follow as an example:
(sum(kube_pod_container_resource_requests_cpu_cores) by (cluster) / sum(kube_node_status_allocatable_cpu_cores) by (cluster)) - (1 - avg(rate(node_cpu_seconds_total{mode="idle"}[$__interval])) by (cluster))
A screen caputre of CPU-related metrics from all managed clusters:

A screen capture of memory-related metrics from all managed clusters:

Conclusion
In this post, you were able to follow how a Grafana deployment can connect into the Red Hat Advanced Cluster Management Observability piece through Observatorium exposed API and Thanos as the datasource. This brings the metrics consolidated from a single place to your existing dashboard implementation of Grafana and is able to take advantage and build dashboards based on those metrics. Since the Observability is serving the metrics to an external Grafana, it is essential to be aware that once you have your own Grafana Deployment maintained and curated by you/your team, the management of dashboards and access is the responsibility of the team that deployed and not from RHACM Operators.
About the authors

More like this
Stop managing the past and start building IT’s future
The agentic paradox and the case for hybrid AI
The Agile_Revolution | Command Line Heroes
DevOps_Tear Down That Wall | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds