Introduction
This is the first post of a blog series describing a backup and disaster recovery solution and general procedures suitable for hybrid OpenShift Container Platform environments with multiple block and object storage back ends.
In this post, we will describe the role of each component, how they interact with each other, and possible improvements to the architecture (for example using OpenShift Container Storage Operator). We will also provide an Ansible-based installer that can be used as a reference and possibly adapted to your environment.
The challenge
It is becoming an increasingly common requirement to define a backup and restore strategy for your applications that is flexible enough to work in disconnected clusters as well as in cloud installations.
Customers often have to write and schedule custom backup tools that version application objects such as DeploymentConfigs, Routes and Services, as well as the data stored in each persistent volume. As time passes, these tools can become outdated or non-standardized across environments.
The same amount of thinking must go into how to restore an application in case disaster strikes, since simply reversing the steps taken during a backup might not be the solution relative to individual component ordering, their dependencies and data location.
Ideally, in an OpenShift environment one could consider a backup solution that uses and recognizes Kubernetes native objects, and provides replication and bucket encryption features, data tiering policies, object versioning, quotas and access management across environments.
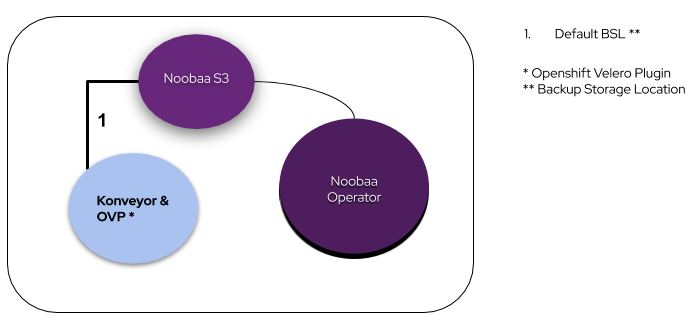
High Level Architecture

We will describe each component of the above diagram in the next section, but for now, it is important to mention that we are using certain container images and a plug-in from the Konveyor project, namely Konveyor-Velero and Restic images, together with the OpenShift Velero Plug-in.
During bootstrap, Velero checks for an available BackupStoreLocation (1), in this case Noobaa’s S3 object store endpoint. Once this is confirmed, additional BackupStoreLocations (BSLs) with other object stores can be configured per namespace and added to Velero (2). The Restic daemonset will handle the backup and restore pod physical volume data (3) using mountPropagation: HostToContainer.
Steps 4 and 5 illustrate possible connections to external cloud provider object storage services such as AWS S3 or Azure Blob Storage.
As an extra to the features of the Noobaa UI, Noobaa Operator ships with default Prometheus rules that can be used by Prometheus, Telemeter, and Alertmanager.
Component Description
Konveyor (Velero and Restic)
Velero is the main component that keeps track of selected objects within an OpenShift project via two main custom resources, backup and restore.
Before installing Velero, we need an available default location for storing and retrieving backups. This is defined as follows in the BackupStorageLocation (BSL) CR:

In our case, “velero_bsl_s3_url” is the noobaa s3 route defined as our object storage target.
This is the basic required components diagram:
A check for a valid connection to noobaa’s s3 bucket is done right after Velero and OVP are installed.
Our example bucket is called first.bucket. You can create or delete buckets with noobaa CLI.

And it will watch for objects similar to the following:

The backup custom resource (CR) defines a full backup operation, named mysql-persistent, for the ‘mysql-persistent’ namespace, using the default storage location, which in most cases will be the configured default StorageClass.
Before applying the backup, we can log in to the mysql database pod, and create two dummy files with random data: 1000.txt and 2000.txt.
Once we execute oc apply -f mysql-persistent-backup.yaml, the backup procedure will start. This might take a while depending on the network and storage backend. Backup completion can then be verified by executing:
oc get backup -n velero mysql-persistent -o jsonpath='{.status.phase}'
Look for Completed in the output. This can also be seen in the velero pod log:
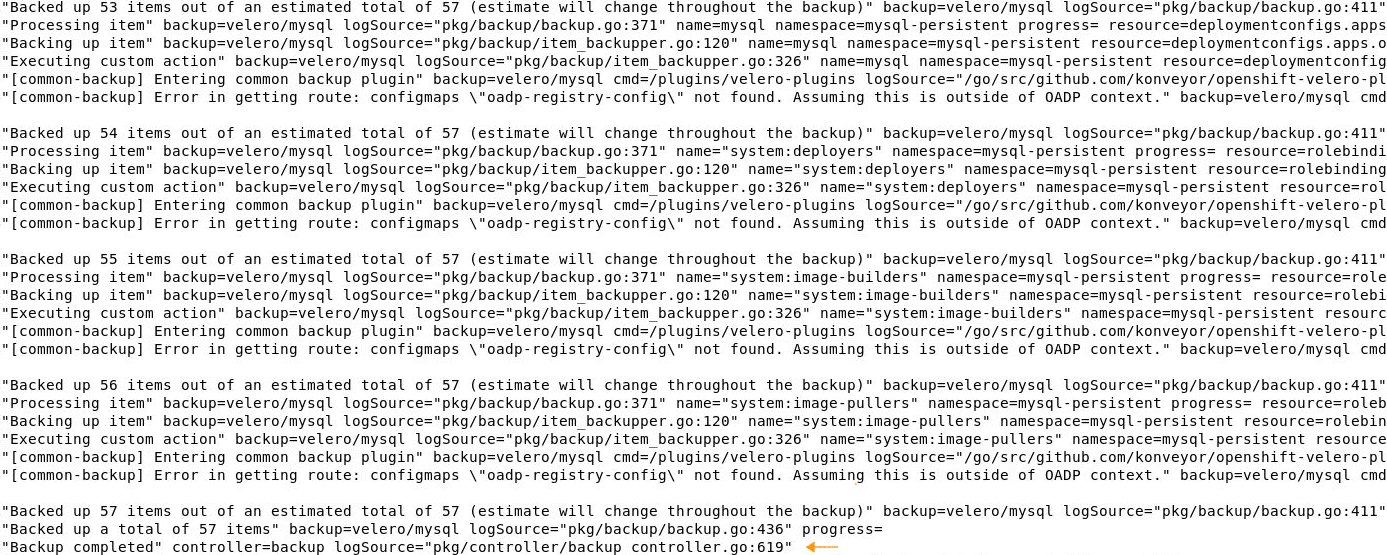
We will see later where the namespace object data (OpenShift Resources) is actually stored.
At this point we can delete the mysql-persistent project and “oc apply” the restore CR as follows:
oc delete project mysql-persistent
oc apply -f mysql-persistent-restore.yaml

The restore CR, uses the previously created backup as seen in spec.backupName, and excludes certain unneeded kubernetes resources at restore time. Both custom resources must be applied in the Velero namespace:
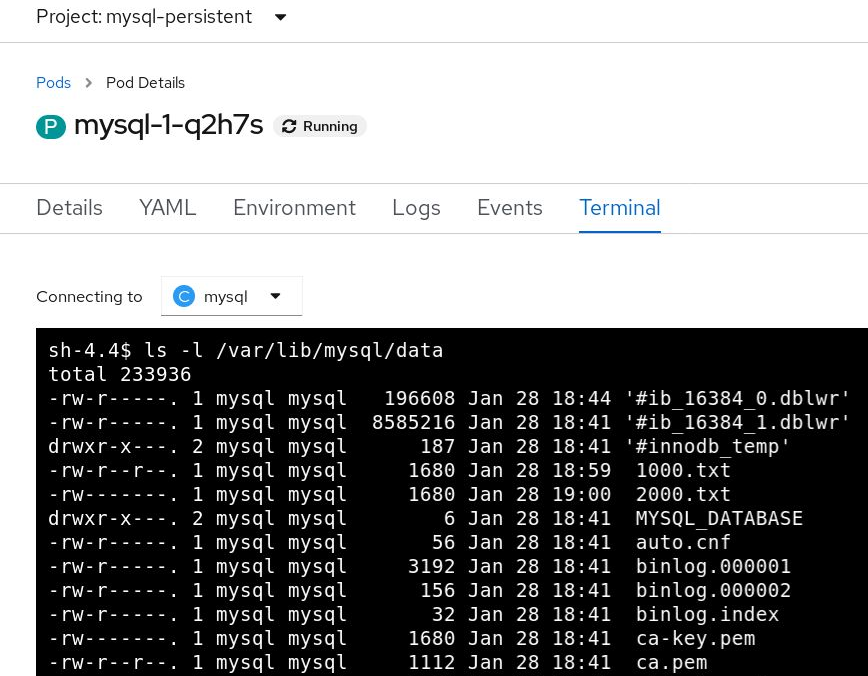
Besides the initial pod data related to mysql, we can see that the two dummy files added, 1000.txt and 2000.txt, were also restored. You can also create databases loaded with test data.
The restore logs:

The test databases that were added:
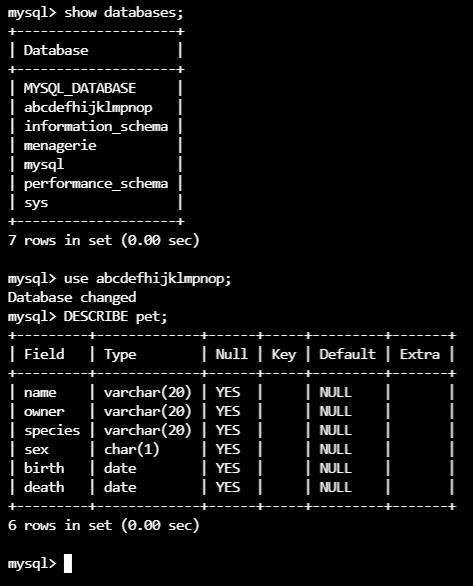
For full application installation, backup, and restore descriptions, check the examples repository: https://github.com/konveyor/velero-examples. Make sure to adjust the storageClass to be used accordingly. This particular example is available at: https://github.com/rflorenc/openshift-backup-infra/tree/master/examples
Restic
As you might have noticed, we have defined restorePVs: true in the restore CR.
This is where Restic and Restic-Restore-Helper initContainer come into play in order to restore the data of each pod. For now, we will manually define restorePVs in the spec and manually annotate the pods whose data we want to restore by defining backup.velero.io/backup-volumes: mysql-data in the DeploymentConfig:
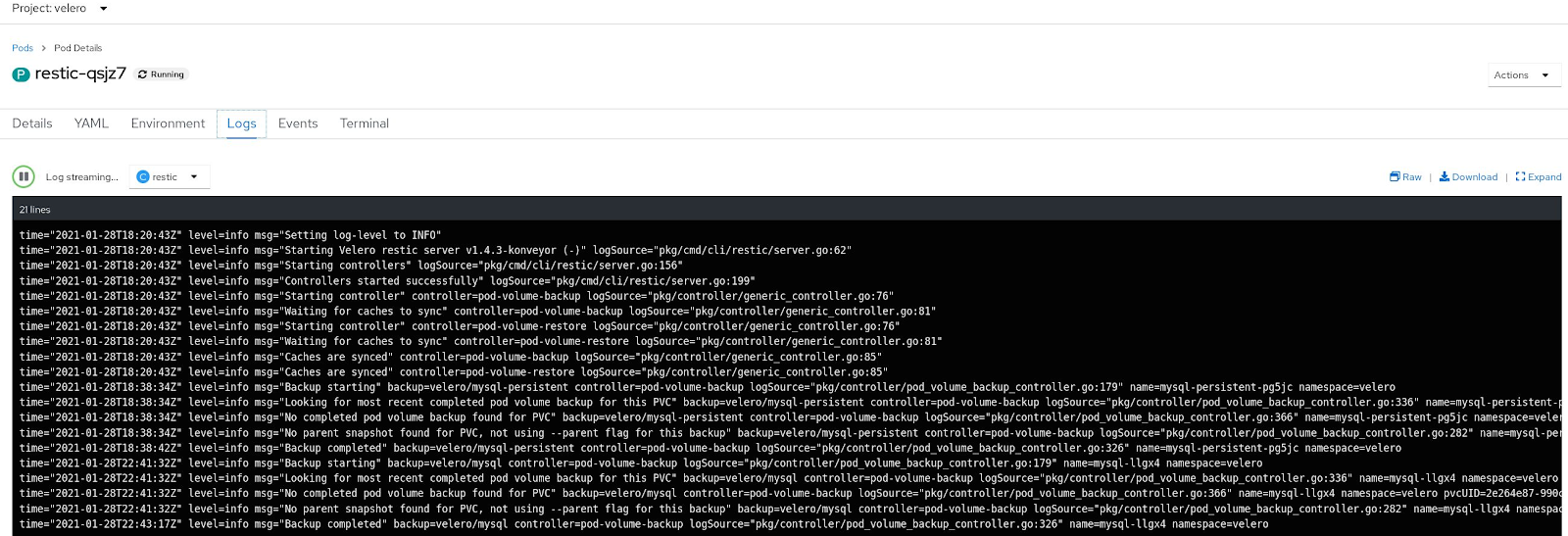
We can see Restic volume backup related operations in the pod log.
In the next blog post, we will discuss alternatives to this annotation process via a custom operator.
Openshift Velero Plug-in
We will use Openshift Velero Plug-in (OVP) in order to backup/restore OpenShift specific objects. After Velero/Restic are installed and the correct BackupStorageLocation is being used, we install OVP with the following command:
velero plugin add docker.io/dymurray/openshift-velero-plugin:skipImages
You should now see the new entries in the Velero pod log related to the OVP plugin registration.

velero get plugins now outputs openshift.io specific Backup and Restore ItemActions.
You can also build it from source and push to a chosen registry. If you would like to contribute, there is more information in the following github repository: https://github.com/konveyor/openshift-velero-plugin
Noobaa Operator
NooBaa is defined as a Multi-Cloud Object Gateway, and it allows us to cover the requirement of having a default object store service on premises and in cloud environments, providing any firewall rules or ACLs are in place for egress and ingress traffic between environments.
In our example, the noobaa CLI is used to install all required services.
When the backup CR is created in the Velero namespace, data is stored in the noobaa s3 bucket:
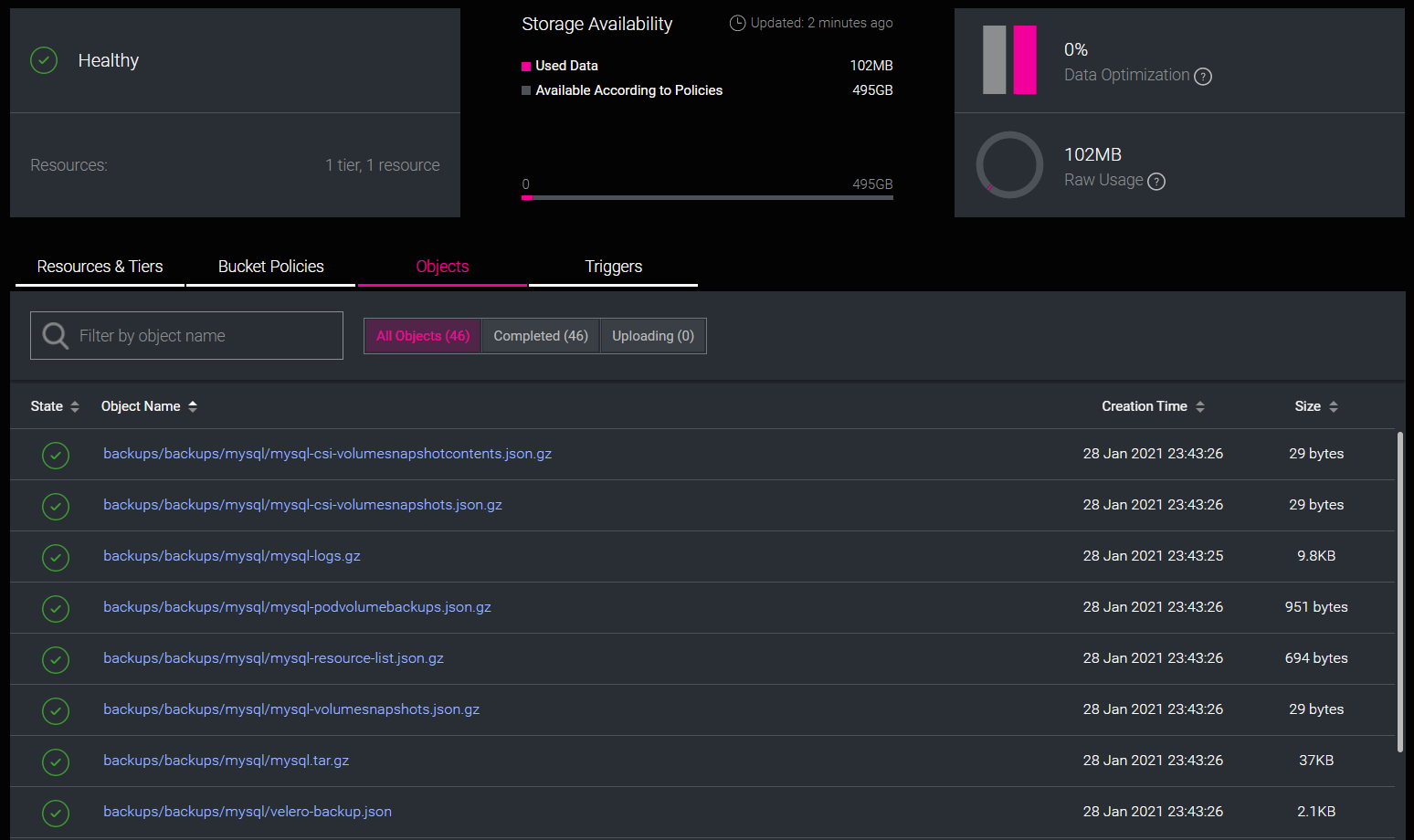
This is where we can also define connections to cloud provider object storage services:

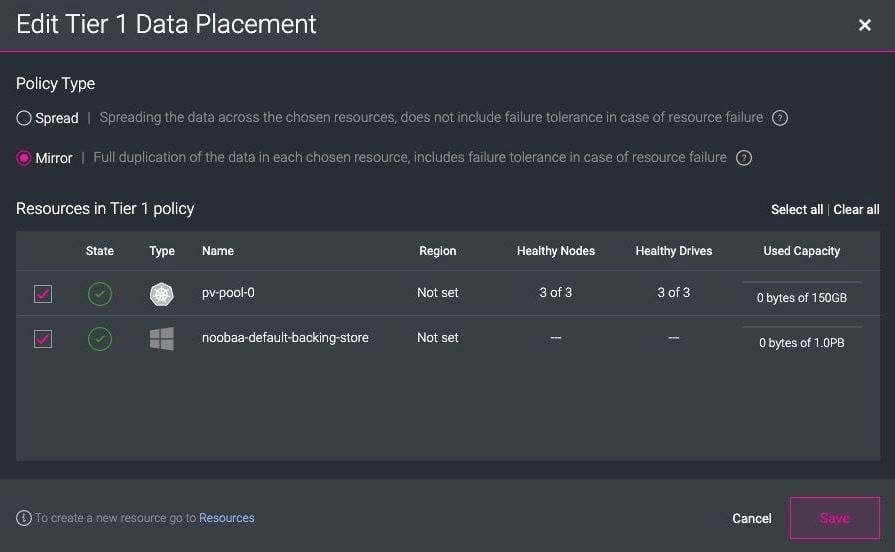
It is worth mentioning that with the OCS (OpenShift Container Storage) Operator, it is possible to create and use different Backing Stores, Object Bucket Claims, and Bucket Classes natively in the OpenShift Developer console. You can adapt one of the predefined backing stores, provide access credentials, and a remote endpoint. With Bucket Classes, you can define data-tiering policies such as Spread (spreading data across chosen resources) or Mirror (data duplication in each resource).
The developer will just see an available bucket to use, but behind the scenes, the data is being replicated across Azure Blob and PVC pools. You can configure replication via the Noobaa management console.
Installation
If you want to try out this solution in your own dev environment, follow the steps in the following GitHub repository: https://github.com/rflorenc/openshift-backup-infra
You might have to adapt the container image repository and resource requests and limits to match your environment. This setup was tested in OpenShift 4.5 and 4.6 using NFS backed storage classes, without OLM access.
Conclusion
In this introduction, we have described the main components of a backup restore solution that can be used on-premises and in a cloud environment. Specifically to OpenShift, we have shown how to use the OpenShift Velero Plug-in and Restic to backup application physical volumes.
Noobaa provides many more functionalities than the ones here described, but we will come back to that in a follow-up post. We will also discuss how to improve the process of managing all the annotated pods for backup in different clusters with a custom-built operator and talk about the new OADP Operator.
About the author

More like this
AI in telco – the catalyst for scaling digital business
Introducing OpenShift Service Mesh 3.2 with Istio’s ambient mode
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds