
Challenges of Resource Management
In OpenShift, as a developer, you can optionally specify how much of each resource (CPU, memory and others) a container needs via setting the request and the limit of resources. The Request is what the container is guaranteed to get. The total request of all containers in a pod is then used by the scheduler to determine which node to place the pod on.
Setting resource requests in practice is hard.
Setting the request for a container is not a trivial task. In practice, developers are known to grossly over-provision resources for their containers to avoid under-provisioning risks, including pod evictions due to out-of-memory errors and application performance issues due to insufficient resources. Setting requests way above the actual usage can lead to significant resource over-provisioning and very low resource efficiency. These resources are reserved but not actually used. Setting the requests too low or completely ignoring the requests cannot solve the problem either, as there is no QoS guarantee for your containers.
Benchmarking is cumbersome and may not be feasible for all workloads.
Some may advocate the idea of benchmarking the resource usage of containers under a realistic load to understand what should be set for requests. However, for applications involving tens of microservices, purely benchmarking these microservices one by one requires a considerable amount of manual effort and resource consumption, which go against our purpose of resource efficiency. Besides, generating a realistic load for each microservice is an impossible mission, as you never know how dynamic or heterogeneous the user queries will be.
Overcommitting is risky.
Configuring clusters to place pods on over-committing nodes will definitely save more resources when pods set requests that are too large. However, how much resources are over-provisioned really varies from developer to developer? Some applications may have 2 CPU cores over-provisioned while others may only have 200 milicores. When their actual usage is not considered, and they are both scheduled to the same node allowing over-commitment, the application with more over-provisioning will eventually get more resources during the busy times. Then, all developers tend to allocate more for their applications. Eventually, there will always be some applications that do not over-provision enough and will have poor performance.
Objective: Efficient Resource Management
Cluster admins usually complain that the overall cluster resource utilization is very low. Still, Kubernetes is not able to schedule any more workload in the cluster. However, they are reluctant to resize their containers as these requests are set to handle the peak usage. Such a peak usage-based resource allocation leads to a forever-increasing cluster scale, extremely low utilization of computing resources most of the time, and a huge amount of machine costs.
The main objective for a cluster that runs stable production services is minimizing machine costs by efficiently using all nodes. To achieve this goal, the Kubernetes scheduler can be made aware of the gap between resource allocation and actual resource utilization. A scheduler that takes advantage of the gap may help pack pods more efficiently, while the default scheduler that only considers pod requests and allocable resources on nodes cannot. There are two main goals that are currently targeted as part of this work: Maintaining node utilization at a certain level, and balancing the utilization variation across nodes.
Maintaining node utilization at a certain level
Increasing resource utilization as much as possible may not be the right solution for all clusters. Since scaling up a cluster to handle the sudden spikes of load always takes time, cluster admins would like to leave adequate room for the bursty load to make sure there is enough time to add more nodes to the cluster.
Given the prior observation on the real workload, one cluster-admin finds that the load has some seasonality and periodically increases. However, resource utilization always increases x% before new nodes can be added to the cluster. The cluster-admin wants to maintain the cluster to have all nodes with the average utilization around or below 100 - x%.
Balancing the risk at peak usage
In some circumstances, scheduling pods to maintain the average utilization on all nodes is also risky because how the utilization of different nodes vary is not known..

For example, suppose two nodes have a capacity of 8 CPUs, and only 5 are requested on each. In that case, the two nodes will be deemed equivalent (assuming everything else is identical) by the default scheduler. However, the node scoring algorithm can be extended to favor the node with less average actual utilization over a given period (for example, the last 6 hours).
If both Node 1 and Node 2 are equally favorable according to the average actual utilization over a given period, the scoring algorithm that only considers the average utilization cannot differentiate these two nodes and may randomly select one of those, as shown in the above figure.
However, by looking at historical data and the actual CPU utilization on the node, it is clear that the resource utilization on Node 2 has more variations than on Node 1. Therefore, at peak hours, its utilization is more likely to exceed the total capacity or the targeted utilization level. Node 1 should be favored to replace the new pod to prevent the risk of under-provisioning in peak hours and to guarantee a better performance for the new pod.
In addition to efficient scheduling according to the actual usage, an advanced scheduler that can balance the risks of resource contention during peak usage is needed.
Trimaran: Real Load Aware Scheduling
To minimize operating costs, the scheduler can be made aware of the gap between its declarative resource allocation model and actual resource utilization. Pods can be packed more efficiently in a lower number of nodes compared to the default scheduler, which only considers pod requests and allocable resources on nodes with its default plug-ins.
There are two scheduling strategies available to enhance the existing scheduling in OpenShift: TargetLoadPacking and LoadVariationRiskBalancing under the Trimaran schedulers to address this problem. It currently supports metric providers like Prometheus, SignalFx & Kubernetes Metrics Server. The plug-ins provide scheduling support for all pod QoS guarantees.
Maintaining node utilization at the specified level: TargetLoadPacking Scheduler Plug-in
Many users would like to keep some room in CPU usage for their applications as a buffer with a threshold value while minimizing the number of nodes. The TargetLoadPacking plug-in is designed to achieve this. TargetLoadPacking strategy packs workload on nodes until a target percent of utilization is achieved on all nodes. Then, it starts spreading workload among all nodes. The benefit of using the TargetLoadPacking strategy is that all running nodes maintain a target utilization, so no nodes are under-utilized. However, it does not overload a particular node too much when the cluster is almost full, which leaves some room for applications’ load variations.
Balancing risks of utilization variation: LoadVariationRiskBalancing Scheduler Plug-in
It is well-known that the Kubernetes scheduler relies on the requested resources, rather than the actual resource usage. Thus, this may lead to contention and imbalance in the cluster. Extending the default scheduler, with some kind of load awareness, attempts to solve this issue. The question is what aspects of load variation ought to be employed by the scheduler. The measure that is most commonly used is the average, or moving average, resource utilization. Though simple, it does not capture the variation of utilization over time. In this scheduling strategy, the idea is to enhance the average with the standard deviation measure that leads to a well-balanced cluster, as far as the risk of resource contention is concerned. The LoadVariationRiskBalancing scheduling strategy uses a simple yet effective priority function that combines measurements of average and standard deviation of node utilizations.
System Design and Implementation
We developed the Trimaran scheduler, which works on live node utilization values, to efficiently use cluster resources and save costs. As part of this, we developed and contributed the Load Watcher, TargetLoadPacking plug-in, and LoadVariationRiskBalancing plug-in to the open-source community.
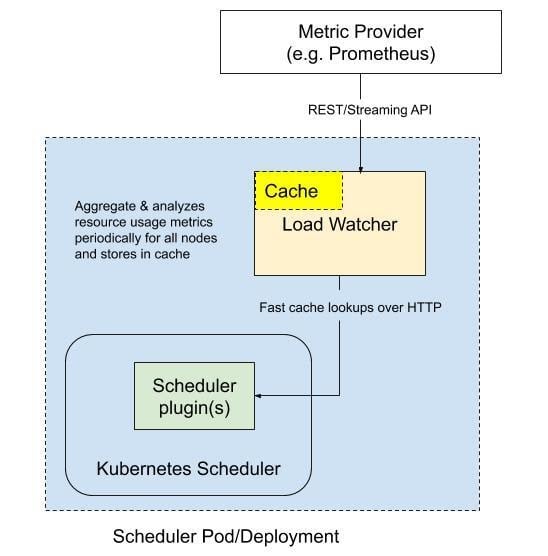
The below graph shows the design of the load-aware scheduling framework. In addition to the default Kubernetes scheduler, a load watcher that can retrieve, aggregate, and analyze resource usage metrics periodically from metric providers such as Prometheus is added. It also caches the analysis results and exposes those to scheduler plug-ins to filter and score nodes. By default, the load watcher retrieves five-minute history metrics every minute and caches the analysis results. However, the frequency of retrieving can be configured.
Using an HTTP server to serve data queries is optional as load watchers can also annotate nodes with analyzed data. However, using annotation is not as flexible and scalable as the REST API. Suppose some advanced predictive analytics is needed to integrate with scheduler plug-ins. In that case, it is easier to use the REST API to pass more data to scheduler plug-ins. The amount of data to cache in the annotation is limited.
The Trimaran plug-ins use a load watcher to access resource utilization data via metrics providers. Currently, the load watcher supports three metrics providers: Kubernetes Metrics Server, Prometheus Server, and SignalFx.
There are two modes for a Trimaran plug-in to use the load watcher: as a service or as a library.
- Load watcher as a service: In this mode, the Trimaran plug-in uses a deployed load-watcher service in the cluster as depicted in the figure below. A watcherAddress configuration parameter is required to define the load-watcher service endpoint. The load-watcher service may also be deployed in the same scheduler pod.
- Load watcher as a library: In this mode, the Trimaran plug-in embeds the load watcher as a library, which in turn accesses the configured metrics provider. In this case, we have three configuration parameters: metricProvider.type, metricProvider.address, and metricProvider.token.
Enabling load-aware scheduling plug-in(s) will cause conflict with two default scoring plug-ins: “NodeResourcesLeastAllocated” and “NodeResourcesBalancedAllocation” score plug-ins. It is strongly advised to disable them.
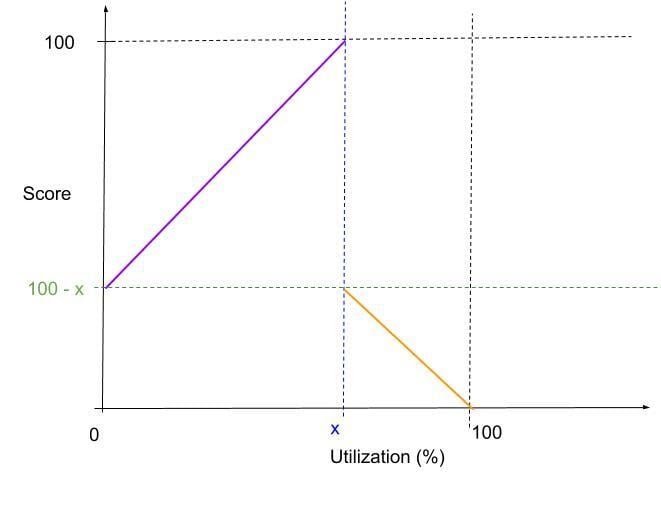
TargetLoadPacking plug-in aims to score nodes according to their actual usage. Eventually, all nodes' utilization can be maintained at a level, x%. It works in two stages, as shown in the figure below. When most nodes in the cluster are idle, the scoring function will favor nodes with the maximum utilization below x%. When all nodes have utilization around or above x%, the scoring function will favor nodes with the minimum utilization. Essentially, it packs workload on nodes until all nodes have around x% utilization and then spreads workload to balance the load on nodes.
A load-aware scheduler that uses only average resource utilization figures may not be enough as variations in the utilization on a node also impact the performance of containers running on that node. The jitter in resource availability to containers over time affects the execution and behavior of the application comprising such containers. Hence, the load-aware scheduler should consider both the average utilization as well as the variation in utilization. A motivating example was mentioned above, where a load-aware scheduler that balances risk should favor the more-stable node for placement of a new pod.
The Load Variation Risk Balancing Plugin scores the nodes based on equalizing the risk, defined as a combined measure of average utilization and variation in utilization among nodes. It supports CPU and memory resources. It relies on a load watcher to collect resource utilization measurements from the nodes via metrics providers, such as Prometheus and Kubernetes Metrics.
The Load Variation Risk Balancing Plug-in is implemented using the Kubernetes Scheduler Framework as a Scheduler Plug-in using the Score extension point. The scheduler plug-in calls the load watcher as a means to get node measurement data about average and standard deviation of CPU and memory utilization. In turn, the load watcher employs a metrics provider such as Prometheus and Kubernetes Metrics. A resource risk factor is defined as a combined measure of the average and standard deviation of the resource utilization. The resource risk factor is evaluated for CPU and memory resources on a node. The node risk factor is taken as the worse of the two resource risk factors. The node score is evaluated as negatively proportional to the node risk factor.
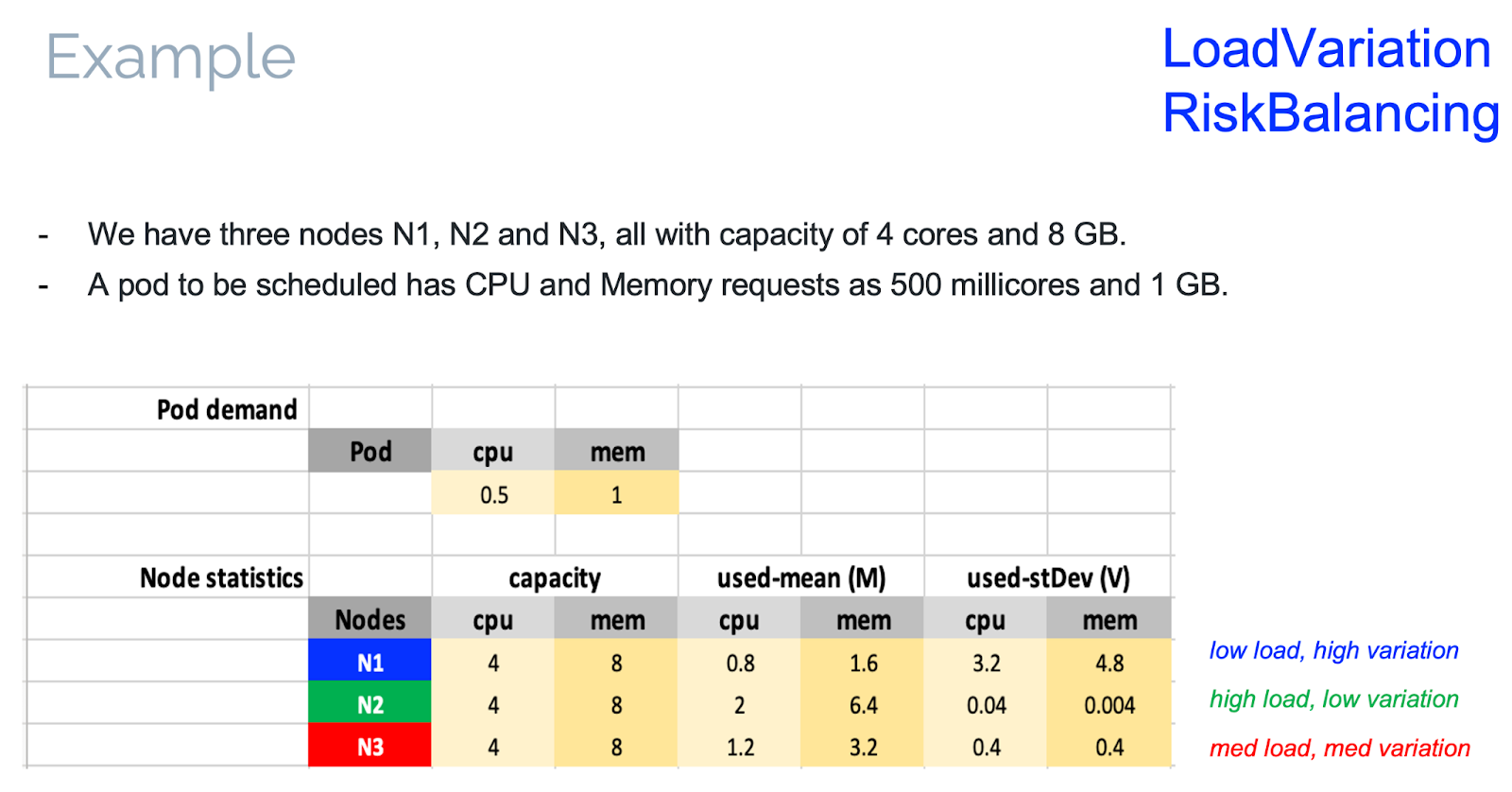
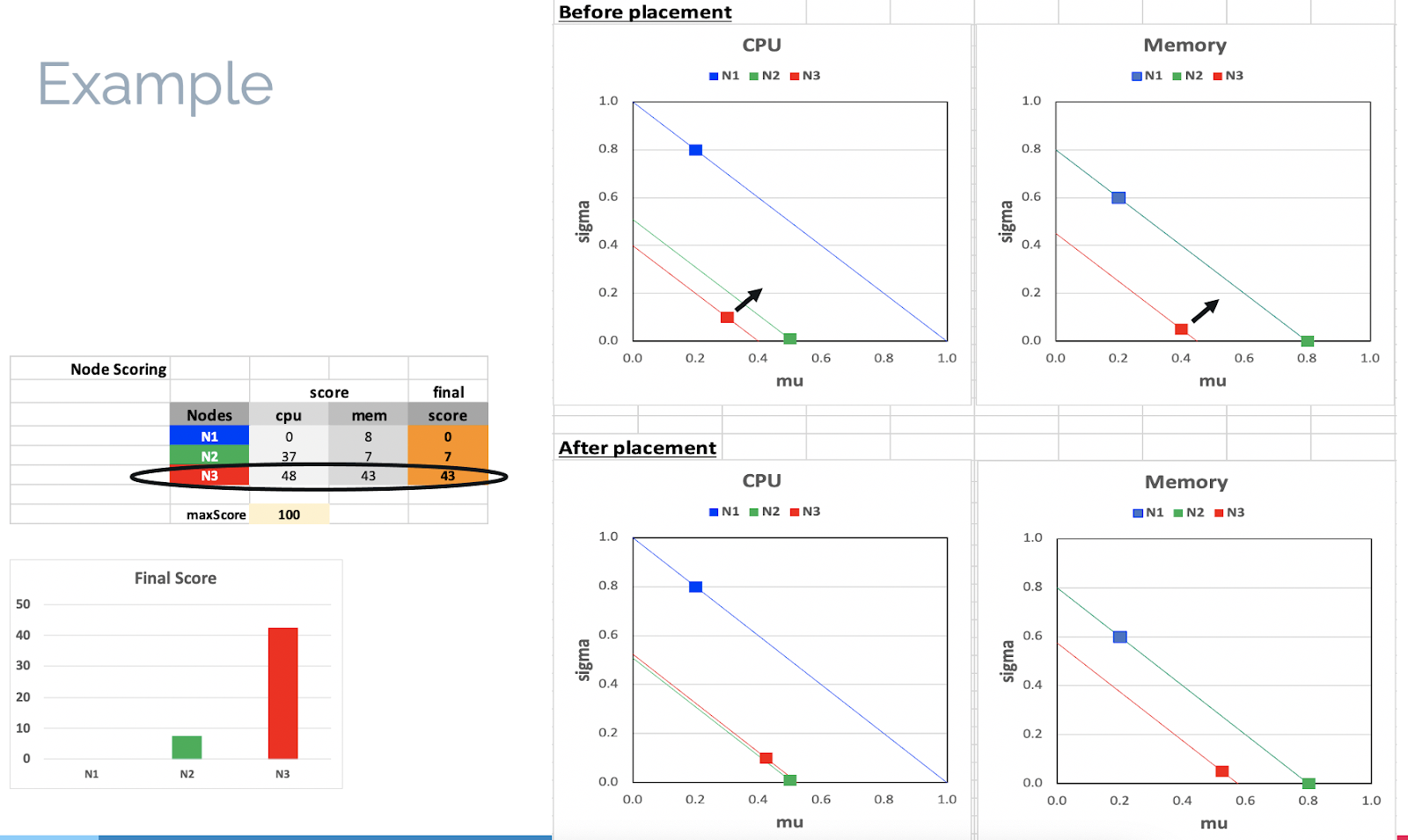
Following is an example scenario with a 3-node cluster (N1, N2, and N3), each with 4 cores and 8 GB capacities. The LoadVariationRiskBalancing Plug-in needs to place a new pod with 0.5 cores and 1 GB requested resources. The average and standard deviation metrics obtained from the load-watcher are such that: N1 has a low average load and high variation, N2 has a high average load and low variation, and N3 has a medium average load and medium variation. The scores are evaluated for the 3 nodes and N3 had the highest score. Pictorially, the figures depicted below demonstrate that, in the two-dimensional average and standard deviation space, node N3 is the farthest away from the line of risk balancing in the cluster. Hence, N3 was picked up by the scheduler to move the cluster in the direction of risk balancing.
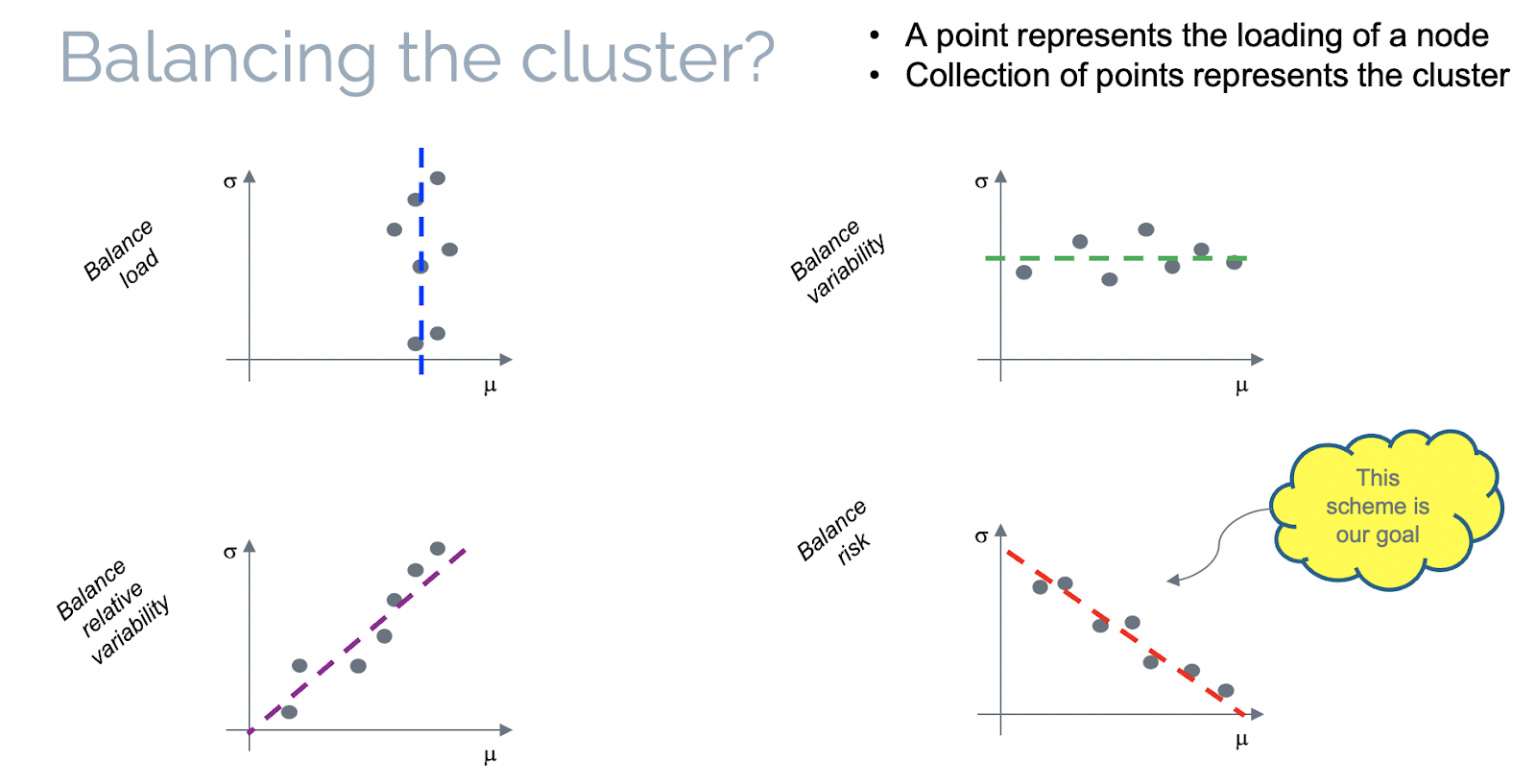
As far as balancing a cluster is concerned and given average and standard deviation utilization measures for all nodes in the cluster, there are basically four ways for a load-aware scheduler to achieve balancing:
- Balance load: Equalize the average utilization among nodes, irrespective of variations.
- Balance variability: Equalize the standard deviation of the utilization of nodes, irrespective of averages.
- Balance relative variability: Equalize the coefficient of variation (defined as the ratio of standard deviation over average utilization) among nodes.
- Balance risk: Equalize the risk factor (defined as a weighted sum of average and standard deviation of utilization) among nodes.
These four ways of balancing a cluster are depicted in the figure below.
Deploy Trimaran Schedulers on OpenShift
OpenShift users can deploy Trimaran schedulers by following the tutorial of Custom Scheduling documentation to deploy Trimaran schedulers as an additional scheduler in OpenShift clusters.
In the following, an example load-aware scheduler that is running out-of-tree scheduler plug-ins is deployed. The scheduler that runs out-of-tree plug-ins needs to run a certain version of the scheduler plug-in image and pass a KubeSchedulerConfiguration to the scheduler binary in the scheduler deployment. For example, the configuration needed to run a load-aware scheduler can be found here.
- Configure plug-ins for a load-aware scheduler. A load-aware scheduler that runs the TargetLoadPacking plugin can be configured as the following:
- To pass the KubeSchedulerConfiguration info to the scheduler binary, it can be mounted as a ConfigMap or mounted as a local file on the host. Here we wrap it as a ConfigMap trimaran-scheduler-config.yaml, to be mounted as a volume in the scheduler deployment. A namespace trimaran for all load aware scheduler resources has been created.
- Accordingly, create a deployment for the load aware scheduler:
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
profiles:
- schedulerName: trimaran-scheduler
plugins:
score:
disabled:
- name: NodeResourcesBalancedAllocation
- name: NodeResourcesLeastAllocated
enabled:
- name: TargetLoadPacking
pluginConfig:
- name: TargetLoadPacking
args:
defaultRequests:
cpu: "2000m"
defaultRequestsMultiplier: "1"
targetUtilization: 70
metricProvider:
type: Prometheus ①
address: https://{{prometheus_url}} ②
token: {{prometheus_token}}
Configure metric Provider as Prometheus ① .
Obtain the Prometheus route URL in ②.
> oc get routes prometheus-k8s -n openshift-monitoring -ojson |jq ".status.ingress"|jq ".[0].host"|sed 's/"//g'
Get the Prometheus token value ③
> oc describe secret $(oc get secret -n openshift-monitoring|awk '{print $1}'|grep prometheus-k8s-token -m 1) -n openshift-monitoring|grep "token:"|cut -d: -f2|sed 's/^ *//g'
> oc create ns trimaran
> oc create -f trimaran-scheduler-config.yaml -n trimaran
---
apiVersion: v1
kind: ConfigMap
metadata:
name: trimaran-scheduler-config
namespace: trimaran
data:
config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
profiles:
- schedulerName: trimaran-scheduler
plugins:
score:
disabled:
- name: NodeResourcesBalancedAllocation
- name: NodeResourcesLeastAllocated
enabled:
- name: TargetLoadPacking
pluginConfig:
- name: TargetLoadPacking
args:
defaultRequests:
cpu: "2000m"
defaultRequestsMultiplier: "1"
targetUtilization: 70
metricProvider:
type: Prometheus
address: https://{{prometheus_url}}
token: {{prometheus_token}}
apiVersion: v1
kind: ServiceAccount
metadata:
name: trimaran-scheduler
namespace: trimaran
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: trimaran
subjects:
- kind: ServiceAccount
name: trimaran-scheduler
namespace: trimaran
roleRef:
kind: ClusterRole
name: system:kube-scheduler
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: trimaran-scheduler
namespace: trimaran
labels:
app: trimaran-scheduler
spec:
replicas: 1
selector:
matchLabels:
app: trimaran-scheduler
template:
metadata:
labels:
app: trimaran-scheduler
spec:
serviceAccount: trimaran-scheduler
volumes:
- name: etckubernetes
configMap:
name: trimaran-scheduler-config
containers:
- name: trimaran-scheduler
image: k8s.gcr.io/scheduler-plugins/kube-scheduler:v0.19.9
imagePullPolicy: Always
args:
- /bin/kube-scheduler
- --config=/etc/kubernetes/config.yaml
- -v=6
volumeMounts:
- name: etckubernetes
mountPath: /etc/kubernetes
Summary
With the Trimaran scheduler plug-ins, users can achieve basic load-aware scheduling that is not implemented in the default Kubernetes scheduler. Trimaran plug-ins can either balance the usage on nodes so that all nodes reach a certain percentage of utilization, or it can prioritize nodes that have lower risk when overcommitting the pods. Trimaran plug-ins can also be used together with overcommitment for better efficiency.
Trimaran plug-ins can further be extended. One extension could be enabling multidimensional bin packing for other types of resources including networking bandwidth and GPU usage. Another extension could be adding more ML or AI models in prediction of pod/node utilization for better scheduling. For the LoadVariationRiskBalancing plug-in, an extension can be made to consider the probability distribution of resource utilization, rather than just the first (average) and second (variance) moments of the distribution. In such a case, the risk may be calculated in relation to the tail of the distribution, which captures the probability of utilization being higher than a configured value. Also, prediction techniques may be applied to anticipate resource utilization, rather than relying solely on past measured utilization.
All types of contributions and comments are welcomed on the following project repositories:
- Trimaran: Load-aware scheduling plug-ins
- Load Watcher: A cluster-wide resource usage metric aggregation and analysis tool.
About the authors
More like this
Stop managing, start orchestrating: Streamlining catalyst operations with Red Hat Ansible Automation Platform
The agentic paradox and the case for hybrid AI
Technically Speaking | Taming AI agents with observability
A composable industrial edge platform | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds