
In this blog post we are going to introduce the principles and patterns of GitOps and how you can implement these patterns on OpenShift. If you're interested in diving into an interactive tutorial, try this link.
What is GitOps?
GitOps in short is a set of practices to use Git pull requests to manage infrastructure and application configurations. Git repository in GitOps is considered the only source of truth and contains the entire state of the system so that the trail of changes to the system state are visible and auditable.
Traceability of changes in GitOps is no novelty in itself as this approach is almost universally employed for the application source code. However GitOps advocates applying the same principles (reviews, pull requests, tagging, etc) to infrastructure and application
configuration so that teams can benefit from the same assurance as they do for the application source code.
Although there is no precise definition or agreed upon set of rules, the following principles are an approximation of what constitutes a GitOps practice:
- Declarative description of the system is stored in Git (configs, monitoring, etc)
- Changes to the state are made via pull requests
- Git push reconciled with the state of the running system with the state in the Git repository
GitOps Principles
- The definition of our systems is described as code
The configuration for our systems can be treated as code, so we can store it and have it automatically versioned in Git, our single source of truth.
That way we can rollout and rollback changes in our systems in an easy way.
- The desired system state and configuration is defined and versioned in Git
Having the desired configuration of our systems stored and versioned in Git give us the ability to rollout / rollback changes easily to our systems and applications.
On top of that we can leverage Git's security mechanisms in order to ensure the ownership and provence of the code.
- Changes to the configuration can be automatically applied using PR mechanisms
Using Git Pull Requests we can manage in an easy way how changes are applied to the stored configuration, you can request reviews from different team members, run CI tests, etc.
On top of that you don't need to share your cluster credentials with anyone, the person committing the change only needs access to the Git repository where the configuration is stored.
- There is a controller that ensures no configuration drifts are present
As the desired system state is present in Git, we only need a software that makes sure the current system state matches the desired system state. In case the states differ this software should be able to self-heal or notify the drift based on its configuration.
GitOps Patterns on OpenShift
On-Cluster Resource Reconciller
In this pattern, a controller on the cluster is responsible for comparing the Kubernetes resources (YAML files) in the Git repository that acts as the single source of truth, with the resources on the cluster. When a discrepancy is detected, the controller would send out notifications and possibly take action to reconcile the resources on Kubernetes with the ones in the Git repository. Anthos Config Management and Weaveworks Flux use this pattern in their GitOps implementation.
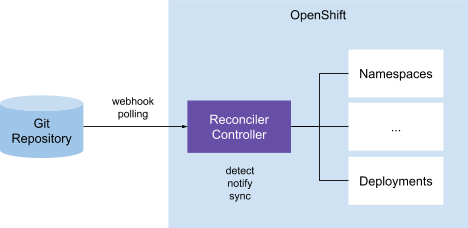
External Resource Reconciler (Push)
A variation of the previous pattern is that one or a number of controllers are responsible for keeping resources in sync between pairs of Git repositories and Kubernetes clusters. The difference with the previous pattern is that the controllers are not necessarily running any of the managed clusters. The Git-k8s cluster pairs are often defined as a CRD which configures the controllers on how the sync should take place. The controllers in this pattern would compare the Git repository defined in the CRD with the resources on the Kubernetes cluster that is also defined in the CRD and takes action based on the result of the comparison. ArgoCD is one of the solutions that uses this pattern for GitOps implementation.

GitOps on OpenShift
Multi-cluster Kubernetes Infrastructure Administration
The increased adoption of Kubernetes withing the organizations, in addition to adopting a multi-cloud strategy and edge computing is
increasing the number of OpenShift clusters per customer.
Edge computing use cases may reach a massive scale of 100s to 1000s of deployments per customer. The result is that customers have to manage multiple independent or cooperative OpenShift clusters running on-prem and on public clouds.
Some of the use cases around this problem space are:
- Ensure clusters have similar state (configs, monitoring, storage, etc)
- Recreate (or recover) clusters from a known state
- Create new clusters with a known state
- Rollout a change to multiple OpenShift clusters
- Rollback a change to multiple OpenShift clusters
- Associate templated configuration with different environments
Application Configuration
Applications often get deployed to multiple clusters (dev, stage, etc) throughout their life cycles before they reach production. Furthermore, the availability and scalability requirements for applications frequently drive customers to deploy applications across multiple clusters on-premise and on public cloud across regions or simply for burst-out capabilities.
Some of the customer needs are:
- Promote applications (binary, config, etc) across clusters (e.g. dev, stage, etc)
- Rollout application changes (binary, config, etc) to multiple OpenShift clusters
- Rollback application changes to previous known stages
OpenShift GitOps Use-cases
- Apply configs from Git
As a cluster admin, I want to store OpenShift cluster configs in a Git repository and have the cluster to apply them automatically, so that I can install a new cluster and bring it to an identical known state from the Git repository.
2. Sync with Secret Manager
As a cluster admin, I want to keep OpenShift secrets in sync with a secret manager like Vault, so that I can manage secrets in a secret management platform.
3. Detect config drift
As a cluster admin, I want OpenShift GitOps to detect and display a warning when cluster configs are not in sync with the designated Git repo, so that I can take action when there is a config drift.
4. Notify config drift
As a cluster admin, I want to be notified when OpenShift GitOps detects a config drift, so that I can take action when there is a configuration drift.
5. Sync on config drift
As a cluster admin, I want to perform a sync on an OpenShift cluster to sync with the configs stored in a Git repository when a config drift is detected, so that the OpenShift cluster would come back to a known state.
6. Auto-sync on config drift
As a cluster admin, I want to configure an OpenShift cluster to automatically sync with the configs stored in a Git repository when a config drift is detected, so that the OpenShift cluster would always be in sync with the config in the designated Git repository.
7. Multiple clusters in one registry
As a cluster admin, I want to define multiple OpenShift cluster config in a single Git repository and apply to clusters selectively, so that I can manage all cluster configs form a single source of truth.
8. Cluster config hierarchy (Inheritance)
As a cluster admin, I want to define a hierarchy of cluster configs (stage, prod, app portfolio, etc with inheritance) in a Git repository, so that I can define configs that apply to a single or multiple clusters.
As an example if an admin defines a hierarchy of prod clusters → foo clusters → foo prod clusters in the Git repository, it is applied a union of the following configs to the "foo" production cluster:
* all production clusters configs
* "foo" cluster configs
* "foo" production cluster configs
9. Templating and Overriding configs
As a cluster admin, I want to override a subset of inherited configs and their values, so that I can adjust the config for the specific clusters they are being applied to.
10. Granularity include and exclude configs
As a cluster admin, I want to define when a certain config should apply or not apply to clusters with certain characteristics, so that I can have granular control over including or excluding cluster configs.
11. Application configs
As a cluster admin, I want to define when a certain config should apply or not apply to clusters with certain characteristics, so that I can have granular control over including or excluding cluster configs.
12. Templating support
As a developer, I want to have a choice on how to define my application resources (Helm Chart, pure k8s yaml etc), so that I can pick the right format based on my application needs.
GitOps Tools on OpenShift
ArgoCD
ArgoCD follows the External Resource Reconcile pattern, it has a central UI that can orchestrate one to many clusters and multiple Git repositories. One weakness is that if ArgoCD goes down, application management cannot be done.
Flux
Flux follows the On-Cluster Resource Reconcile pattern, as there is not a central management of repository definitions, if one cluster goes down. the ability exists still to manage applications. One weakness is that no central UI is provided by the tool.
Installing ArgoCD on OpenShift
In this blog series we are using ArgoCD as it provides a great CLI and WebUI, future blogs will potentially explore different alternatives like Flux.
In order to deploy ArgoCD on OpenShift 4 you can go ahead and follow the following steps as a cluster admin:
- Deploy ArgoCD components on OpenShift
# Create a new namespace for ArgoCD components
oc create namespace argocd
# Apply the ArgoCD Install Manifest
oc -n argocd apply -f https://raw.githubusercontent.com/argoproj/argo-cd/v1.2.2/manifests/install.yaml
# Get the ArgoCD Server password
ARGOCD_SERVER_PASSWORD=$(oc -n argocd get pod -l "app.kubernetes.io/name=argocd-server" -o jsonpath='{.items[*].metadata.name}')
- Patch ArgoCD Server Deployment so we can expose it using an OpenShift Route
# Patch ArgoCD Server so no TLS is configured on the server (--insecure)
PATCH='{"spec":{"template":{"spec":{"$setElementOrder/containers":[{"name":"argocd-server"}],"containers":[{"command":["argocd-server","--insecure","--staticassets","/shared/app"],"name":"argocd-server"}]}}}}'
oc -n argocd patch deployment argocd-server -p $PATCH
# Expose the ArgoCD Server using an Edge OpenShift Route so TLS is used for incoming connections
oc -n argocd create route edge argocd-server --service=argocd-server --port=http --insecure-policy=Redirect
- Deploy ArgoCD Cli Tool
# Download the argocd binary, place it under /usr/local/bin and give it execution permissions
curl -L https://github.com/argoproj/argo-cd/releases/download/v1.2.2/argocd-linux-amd64 -o /usr/local/bin/argocd
chmod +x /usr/local/bin/argocd
- Update ArgoCD Server Admin Password
# Get ArgoCD Server Route Hostname
ARGOCD_ROUTE=$(oc -n argocd get route argocd-server -o jsonpath='{.spec.host}')
# Login with the current admin password
argocd --insecure --grpc-web login ${ARGOCD_ROUTE}:443 --username admin --password ${ARGOCD_SERVER_PASSWORD}
# Update admin's password
argocd --insecure --grpc-web --server ${ARGOCD_ROUTE}:443 account update-password --current-password ${ARGOCD_SERVER_PASSWORD} --new-password
- Now you should be able to use the ArgoCD WebUI and the ArgoCD Cli tool to interact with the ArgoCD Server
Next Steps
In future blog posts we will talk about multiple topics related to GitOps such as:
- Multi-cluster management with GitOps
- Disaster Recovery with GitOps
- Moving to GitOps
About the author
More like this
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Why Red Hat partners are the ultimate telco business asset
Building A Common Language | Compiler: Stack/Unstuck
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds