
As you might have guessed, the title of this blog is a reference to the 1998 Pixar movie A Bug's Life and indeed, there are many parallels between a worker ant and a pod in Kubernetes. In the following, we'll have a closer look at the entire pod lifecycle here from a practitioners point-of-view, including ways how you can influence the start-up and shut-down behavior and good practices around application health-checking.
No matter if you create a pod manually or, preferably through a supervisor such as a deployment, a daemon set or a stateful set, the pod can be in one of the following phases:
- Pending: The API Server has created a pod resource and stored it in etcd, but the pod has not been scheduled yet, nor have container images been pulled from the registry.
- Running: The pod has been scheduled to a node and all containers have been created by the kubelet.
- Succeeded: All containers in the pod have terminated successfully and will not be restarted.
- Failed: All containers in the pod have terminated. At least one container has terminated in failure.
- Unknown: The API Server was unable to query the state of the pod, typically due to an error in communicating with the kubelet.
When you do a kubectl get pod, note that the STATUS column might show a different message than the above five messages, such as Init:0/1 or CrashLoopBackOff. This is due to the fact that the phase is only part of the overall status of a pod. A good way to get an idea of what exactly has happened is to execute kubectl describe pod/$PODNAME and look at the Events: entry at the bottom. This lists relevant activities such as that a container image has been pulled, the pod has been scheduled, or that a container is unhealthy.
Let's now have a look at a concrete end-to-end example of a pod lifecycle as shown in the following:
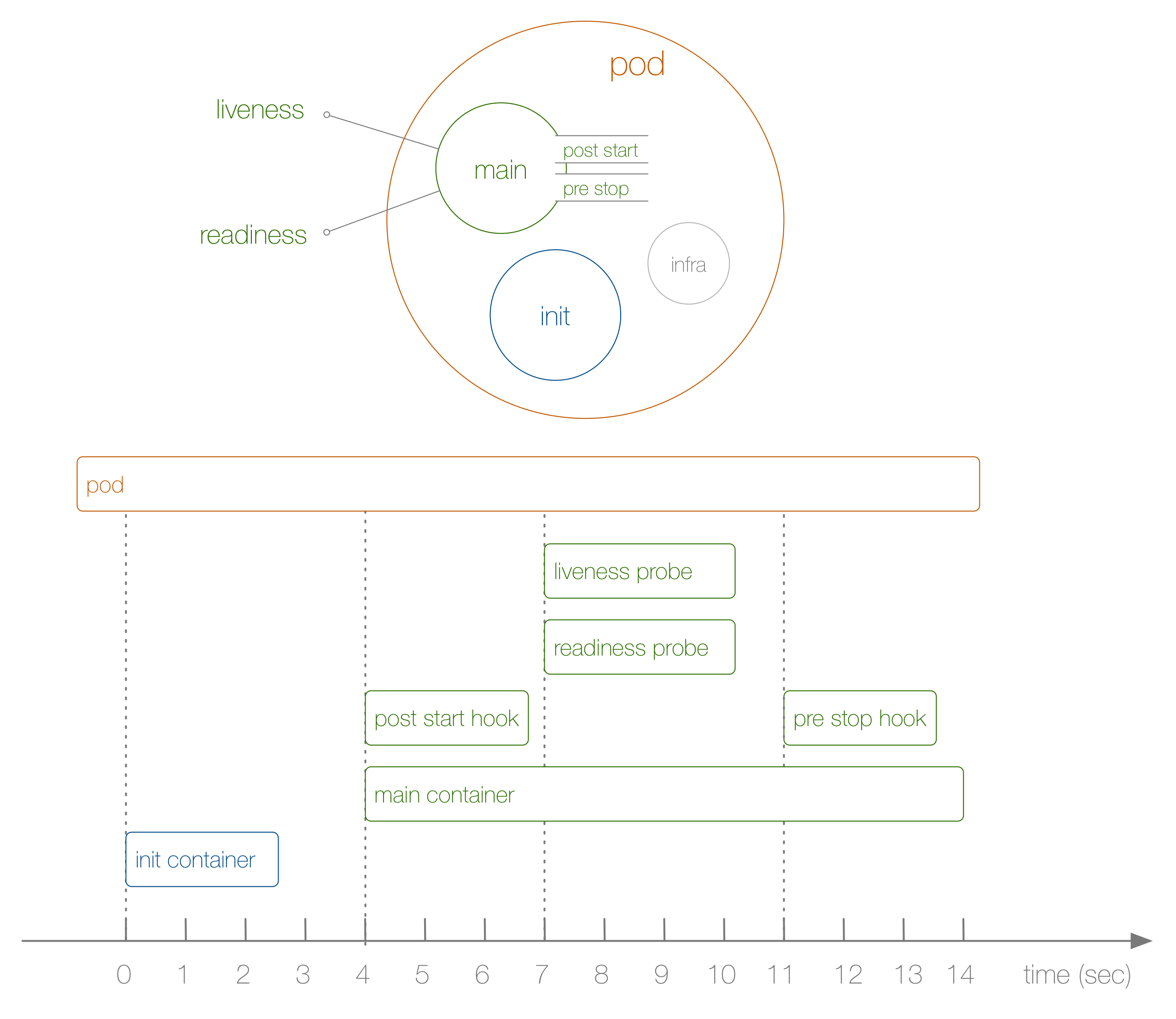
So, what is happening in this example, above? The steps are as follows:
- Not shown in the diagram, before anything else, the infra container is launched establishing namespaces the other containers join.
- The first user-defined container launching is the init container which you can use for pod-wide initialization.
- Next, the main container and the post-start hook launch at the same time, in our case after 4 seconds. You define hooks on a per-container basis.
- Then, at second 7, the liveness and readiness probes kick in, again on a per-container basis.
- At second 11, when the pod is killed, the pre-stop hook is executed and finally, the main container is killed, after a grace period. Note that the actual pod termination is a bit more complicated.
But how did I arrive at the above shown sequence and the attached timing? I used the following deployment, which in itself is not very useful, other than to establish the order in which things are happening:
kind: Deployment
apiVersion: apps/v1beta1
metadata:
name: loap
spec:
replicas: 1
template:
metadata:
labels:
app: loap
spec:
initContainers:
- name: init
image: busybox
command: ['sh', '-c', 'echo $(date +%s): INIT >> /loap/timing']
volumeMounts:
- mountPath: /loap
name: timing
containers:
- name: main
image: busybox
command: ['sh', '-c', 'echo $(date +%s): START >> /loap/timing;
sleep 10; echo $(date +%s): END >> /loap/timing;']
volumeMounts:
- mountPath: /loap
name: timing
livenessProbe:
exec:
command: ['sh', '-c', 'echo $(date +%s): LIVENESS >> /loap/timing']
readinessProbe:
exec:
command: ['sh', '-c', 'echo $(date +%s): READINESS >> /loap/timing']
lifecycle:
postStart:
exec:
command: ['sh', '-c', 'echo $(date +%s): POST-START >> /loap/timing']
preStop:
exec:
command: ['sh', '-c', 'echo $(date +%s): PRE-HOOK >> /loap/timing']
volumes:
- name: timing
hostPath:
path: /tmp/loap
Note that in order to force the termination of the pod, I executed the following once the main container was running:
$ kubectl scale deployment loap --replicas=0
Now that we've seen a concrete sequence of events in action, let's move on to some good practices around pod lifecycle management:
- Use init containers to prepare the pod for normal operation. For example, to pull some external data, create database tables, or wait until a service it depends on is available. You can have multiple init containers if necessary and all need to complete successfully for the regular containers to start.
- Always add a
livenessProbeand areadinessProbe. The former is used by the kubelet to determine if and when to re-start a container and by a deployment to decide if a rolling update is successful. The later is used by a service to determine if a pod should receive traffic. If you don't provide the probes, the kubelet assumes for both types that they are successful and two things happen: The re-start policy can't be applied and containers in the pod immediately receive traffic from a service that fronts it, even if they're still busy starting up. - Use hooks to initialize a container and to tear it down properly. This is useful if, for example, you're running an app where you don't have access to the source code or you can't modify the source but it still requires some initialization or shutdown, such as cleaning up database connections. Note that when using a service, it can take a bit until the API Server, the endpoints controller, and the kube-proxy have completed their work, that is, removing the respective IPtables entries. Hence, in-flight requests might be impacted by a pod shutting down. Often, a simple
sleeppre stop hook is sufficient to address this. - For debugging purposes and in general to understand why a pod terminated, your app can write to
/dev/termination-logand you can view the message usingkubectl describe pod .... You can change this default usingterminationMessagePathand/or leverage theterminationMessagePolicyon the pod spec, see the API reference for details.
What we didn't cover in this post are initializers. This is a fairly new concept, introduced with Kubernetes 1.7. These initializers work in the control plane (API Server) rather than directly within the context of the kubelet and can be used to enrich pods, such as injecting side-car containers or enforce security policies. Also, we didn't discuss PodPresets which, going forward, may be superseded by the more flexible initializer concept.
About the author
More like this
Can't patch fast enough? Zero trust as a last line of defense
What's new with image builder for Red Hat Enterprise Linux 10.2 and 9.8
The Containers_Derby | Command Line Heroes
Can Kubernetes Help People Find Love? | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds