The scope of use
Liveness and Readiness probes are Kubernetes capabilities that enable teams to make their containerised applications more reliable and robust. However, if used inappropriately they can result in none of the intended benefits, and can actually make a microservice based application unstable.
The purpose of each probe is quite simple and is described well in the OpenShift documentation here. The use of each probe is best understood by examining the action that will take place if the probe is activated.
- Liveness : Under what circumstances is it appropriate to restart the pod?
- Readiness : under what circumstances should we take the pod out of the list of service endpoints so that it no longer responds to requests?
Coupled with the action of the probe is the type of test that can be performed within the pod :
- HTTP GET request - For success, a request to a specific HTTP endpoint must result in a response between 200 and 399.
- Execute a command - For success, the execution of a command within the container must result in a return code of 0.
- TCP socket check - For success, a specific TCP socket must be successfully opened on the container.
Liveness
I come from a background of real-time embedded systems applications that need to run for many years without service interruption. I have never been a huge fan of the universal computer fix: “switch it off and back on again.” So to use a liveness probe we must identify a suitable test from the three available options that will sensibly result in a requirement to perform a pod restart if the test fails.
It is important to identify that the pod with the liveness probe attached is the pod that needs to be restarted. This means not running tests with the liveness probe that result in a transaction involving other containers in other pods. However, if we make the liveness probe too simple, it may never give a meaningful indication of the poor health of the container. Ultimately, liveness probes are not the only facility that should be used in the management and monitoring of complex microservices-based applications; a structured logging and monitoring capability should be designed into the architecture from the start. Something like Prometheus.
As a simple example of the use of liveness probes, consider a web application server for a travel booking site. The application server responds to web site requests on URL endpoints such as /flights, /trains and /hotels. Each of these URL’s results in a transaction that will require interaction with further containerised applications that look up seat or room availability. They may also perform tasks such as obtaining the users profile and looking up their frequent traveller points etc. In short, this is not a trivial transaction, and it involves multiple downstream interfaces. If we use one of the above URL endpoints as part of the liveness probe, then the result may be that we restart the container after a failure or slow response from one of the downstream services. The application server may be performing perfectly, but we may restart it for the wrong reasons. Alternatively, we look for a different endpoint to give an indication of pod health. Adding a new URL such as /health -which simply validates that the application server is operating and serving requests - is a more atomic test that will only result in restarting the pod if the application server is unable to respond to a simple request.
The process of finding a credible liveness test is not yet complete, however. Having identified a suitable endpoint we now have to identify the appropriate parameters for the liveness test to ensure that it operates under the right circumstances. The parameters required for the configuration of a URL response test involve the following:
- initialDelaySeconds - Number of seconds after the container has started before the probe is scheduled. The probe will first fire in a time period between the initialDelaySeconds value and (initialDelaySeconds + periodSeconds). For example if the initialDelaySeconds is 30 and the period seconds is 100 seconds then the first probe will fire at some point between 30 and 130 seconds.
- periodSeconds - The delay between performing probes.
- timeoutSeconds - Number of seconds of inactivity after which the probe times-out and the containerised application is assumed to be failing. Note that this parameter is not used with a probe that involves the execution of a command in the container. The user must find some alternative way to stop the probe, such as using the timeout command line utility.
- failureThreshold - The number of times that the probe is allowed to fail before the liveness probe restarts the container (or in the case of a readiness probe marks the pod as unavailable).
- successThreshold - The number of times that the probe must report success after it begins to fail in order to reset the probe process.
The initialDelaySeconds parameter must be set to an appropriate value at which the health check probe should begin. Given that the /health probe runs on the same application server platform as the other more resource consuming URL’s, the initial delay must be long enough to ensure that the health check URL will be active. Setting this value too high will leave a period of time during which the container applications are active and the probe is not.
The periodSeconds parameter should be treated with care as this will dictate the frequency at which the Kubernetes platform probes the pod to see if it is successfully operating. Too aggressive a setting results in unnecessary workload, while too big a gap between probes results in long delays between probing actions.
Probe Timing
The example below illustrates the probe in action through a timeline. The first probe is successful, but the second, third and fourth fail. Assuming a default setting of 3 for the failureThreshold the pod will restart after the failure of the fourth probe.
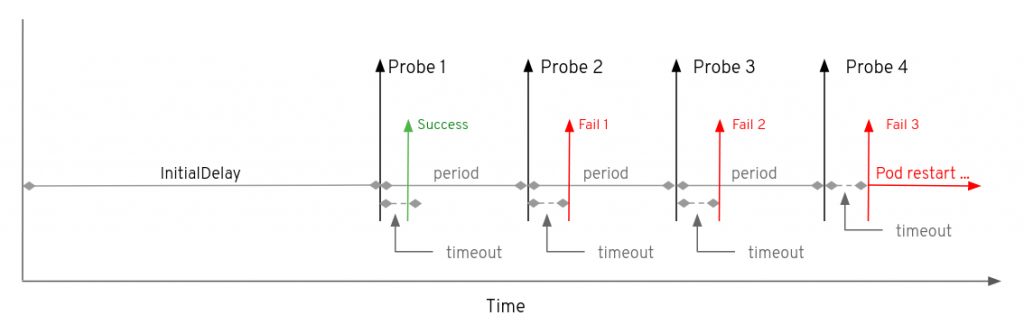
Assuming that a pod fails to start successfully, the lowest amount of time that can elapse before the pod is restarted due to the liveness probe is given by:
time = initialDelaySeconds + failureThreshold - 1 periodSeconds + timeoutSeconds
Under normal steady state operation, and assuming that the pod has operated successfully for a period of time, the initialDelaySeconds parameter becomes irrelevant. In such a case, the minimum amount of time that will elapse between a failure and a pod restart is given by:
time = failureThreshold - 1 periodSeconds + timeoutSeconds
As shown by the image below, the failure point can occur just before a probe occurs or just after a successful probe has occurred. If the periodTime is long such that there is minimal interference on the pod, then it is possible that the time before the pod restarts could result in almost an additional periodSeconds time interval being added before restart.
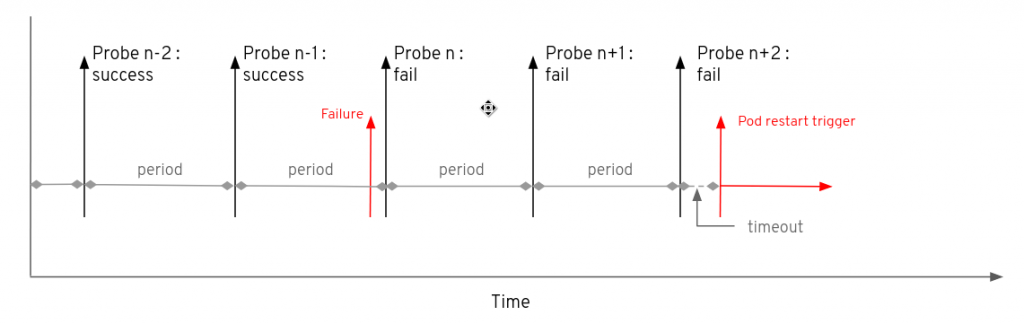
The failureThreshold parameter must be used with caution. If the parameter is set too high there is a danger that time is wasted while a pod has failed and it is not being restarted. If this parameter is set too low then there is a danger that the pod may be restarted prematurely if the pod comes under an unusually heavy load such that, while serving hotel and train booking requests, it does not respond to the health probe quickly enough. If this situation arises and the pod is restarted, then the system has lost part of the workload serving customer requests and more workloads will be placed on the remaining pods, which will make their overall performance spiral down further.
Readiness
Everything stated above regarding liveness probes applies equally to readiness probes. The obvious difference is the end result when the probe takes action, and in the case of a readiness probe the action is to remove the pod from the list of available service endpoints. Under normal circumstances the endpoint reports all pods that support it as shown below:
oc get ep/node-app-slave -o json
{
"apiVersion": "v1",
"kind": "Endpoints",
...
"subsets": [
{
"addresses": [
{
"ip": "10.128.2.147",
After a readiness probe has been actioned the addresses line changes to:
oc get ep/node-app-slave -o json
{
"apiVersion": "v1",
"kind": "Endpoints",
...
"subsets": [
{
"notReadyAddresses": [
{
"ip": "10.128.2.147",
One of the obvious differences between a liveness probe and a readiness probe is that the pod is still running after a readiness probe has taken action. This means that the successThreshold parameter has a greater role to play. Even after taking the pod out of the list of endpoints, the readiness probe will continue to probe the pod. If the pod somehow manages to self-correct (perhaps due to the fact that it was temporarily under severe workload and unable to respond to the probes), then the pod may start to respond successfully to the probes. The default value for the successThreshold is just 1 so there only needs to be one successful probe response to cancel the period of isolation and add the pod back into the service endpoint list. Consequently, readiness probes act particularly well at giving the pod some breathing space to recover from being overwhelmed.
Once again, the question must be asked - ‘Given the overall architecture of the application and the expected workloads, under which it must operate, what action do we want to take when a pod is overwhelmed?’ Similarly to unnecessary pod restarts that place additional workload on other pods within the system, temporarily taking a pod ‘out of service’ may simply indicate that the functionality of the application or the overall architecture needs a rethink in terms of how it behaves under load.
Taking a pod out of service
For a readiness probe, the failureThreshold parameter defines how many times the probe must fail before the pod is removed from the endpoint list. Consider the situation in which a readiness probe has a failureThreshold of 5 and a default successThreshold of 1. In the diagram below the pod suffers three consecutive failures to respond the to probe, followed by one successful response (probe 5). This successful response resets the counter on failures such that a further sequence of five failures occur (probes 6 to 10) before the removal of the pod from the endpoint list at probe 10.
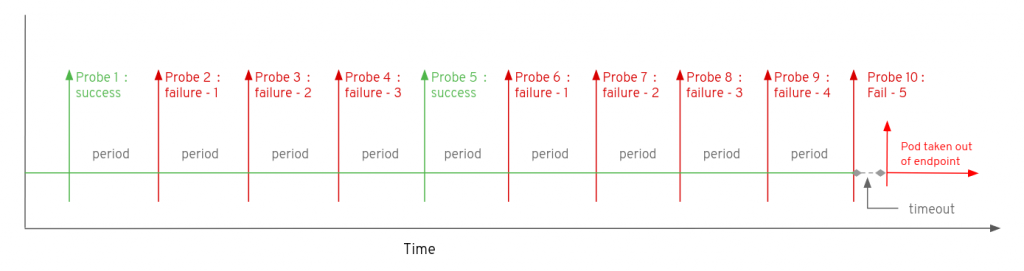
Returning a pod to service
For a readiness probe the successThreshold parameter works alongside the failureThreshold to define the circumstances under which the pod should be returned to the endpoint list. Obviously, the successThreshold parameter has no impact on a liveness probe. Consider the situation in which a readiness probe has a failureThreshold of 5 and a successThreshold of 3. In the diagram below the pod suffers a fifth failure to respond at probe number 5 resulting in the removal of the pod from the endpoint list. Note that the pod remained in the endpoint list through the period of time from probe 1 to probe 5 even though it was struggling to respond successfully. One further probe failures occur at probe 6 before the health of the pod improves and it responds successfully at probe 7. Since the successThreshold is set to three it takes a further two successful probe responses at probes 8 and 9 before the pod is returned to the endpoint list.
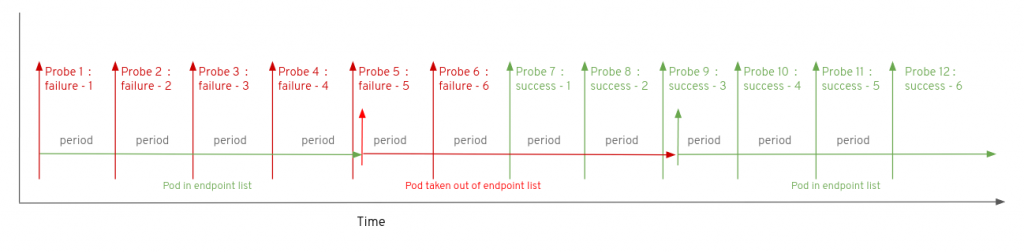
The minimum amount of time for which a pod can be returned to health but still not servicing requests is given by :
time = successThreshold - 1 periodSeconds
Consider an Istio Circuit Breaker
Many microservices-based applications will benefit from the introduction of Red Hat Service Mesh for the management, monitoring and observability of services. As a consequence it may be appropriate to introduce the Istio circuit breaker capability. This operates in a similar manner to the readiness probe, in that it will remove the poorly performing pods from the routing rules it manages. Istio can take more granular actions on pods, however. If one begins to fail, for example, Istio can turn the flow of traffic to that pod down to a trickle, then reopen the flow when performance improves.
Conclusion
Liveness and readiness probes have a part to play in the reliable and efficient delivery of application services. By considering exactly what is being used as the probe and what action we want to take for failure and recovery, it is possible to make good use of probes to help to manage the continued delivery of a microservice application.
{{cta('1ba92822-e866-48f0-8a92-ade9f0c3b6ca')}}
About the author

More like this
OpenShift: Consistent integration for the hybrid enterprise
Hardened, ready, and no cost: Container security evolved
Can Kubernetes Help People Find Love? | Compiler
Scaling For Complexity With Container Adoption | Code Comments
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds