
Prerequisites
- Business analysis of applications
- Basic understanding of pod constraints
- Kubernetes based platform (OpenShift, vanilla k8s. etc)
- Prometheus
- Grafana
Introduction
One of the most common questions relating to Kubernetes is how to identify the resource constraints set at an individual pod level. This is not an easy question to answer and is a prime example of the old chicken before the egg idiom. Ultimately you will want production data to define these constraints, yet want to set these constraints before releasing your containerized application into your production environment. This article will describe a process that uses a variety of mathematical principles in combination with metrics collected by Prometheus monitoring tool to show how these values can be shown empirically through data.

Image by OpenClipart-Vectors from Pixabay
One of the core functionalities of containerization is sharing CPU cycles and memory within the same host kernel. This often leads to multi-tenant scenarios where an organization may host many different application teams on the same k8s based cluster. Meaning that each group is going to get their own slice of the pie, leading to the need for ResourceQuotas1 and Pod level resource constraints to enforce fairness across the cluster. One of the easiest ways to solve the problem described at the beginning of this article is to simply guess the values for memory and CPU constraints. This usually works as developers tend to estimate high: a simple stateless Java Spring Boot now has 8Gb of memory and 4 CPU cores, but it runs great; so problem solved, right?
One of the original benefits touted about the cloud is its ability to bring significant cost savings for organizations. While this article won’t dive into the full merits of this statement, it does lead to common expectations that organizations have when first migrating to either a public, private, or hybrid cloud. Going back to the easier scenario described above, this usually leads to the applications being performant, but significant sticker shock once the bill is received. To utilize the cloud efficiently, other solutions are needed. This is where metrics and understanding some core mathematical principles can help determine empirical constraints.
Initial Phase
There are two different states that the application team are usually in prior to asking this question about resource constraints. The first is when an application has already been deployed into a k8s based platform with no given constraints. Eventually, the need for resource constraints comes up due to either cost-saving efforts or overutilization of a multi-tenant cluster. This is the ideal case since there are past metrics that can determine an empirical value for resource constraints.
The second, and most common, is when applications are initially containerized and then deployed into a k8s environment for the first time within a cluster that requires constraints to be set before deployment. The challenge here is that there are no metrics at this point to make any type of empirical decision on what those constraints should be. This is usually when developers set high estimates, leading to applications running fine but with significant monetary cost because of underutilized resource requests. There are two options I recommend in this scenario,
- The first option is to utilize a SIT (System Integration Testing) k8s based environment that matches closely to your production cluster and use tools like J-Meter or Gatling to generate metrics to try to accurately estimate your production usage. It is critical that this simulated usage match what is expected in production as closely as possible.
- The second option is to set high estimates for the resource constraint, then continue to monitor your application and adjust to calculated values as empirical data begins to form in your production environment.
Metrics Driven Constraints
When using metrics to generate empirical values, one of the first questions that needs to be asked is the range of data required to produce those values. This is not just a question for an application developer. Answering this usually takes a partnered business analysis to discover how and when your application is used. Take an application that processes accounts payable and notifies your company’s bank when to send out money, for example. That application may only process a few requests a day, but at the end of the month it sends out a variety of large batch payments that can exceed a few hundred requests. If you choose your range to be a day or a week that doesn’t include the last day of the month, then your analysis will be faulty. These types of requests are typically called burst requests and show up on a graph as a large spike. Make sure to include these significant bursts into the range of any type of empirical analysis. This is why more data collected over time makes it easier to determine empirical values for resource constraints.
The Grafana graphs below show metrics collected from a python application2 that calculates pi using a variety of trigonometry functions that are CPU intensive. To add some variety to the data, a CronJob was set up to make a request every minute and calculate pi from 1 to 120,000 decimal places. These requests took anywhere from 30 milliseconds to around 30 seconds, depending on the amount of decimals being calculated. This data will strictly be showing the CPU usage, but the process is the same when looking at data around memory or network requests. The below image shows a graph of what that CPU usage looks like over the course of 24 hours:

|
# Query A - cpu usage |
The calculate pi example application produces CPU usage data trends that are consistent over time, so a range of 24 hours when calculating the data can show accurate results. The above CPU usage graph shows a number of bursts where the pod usage goes over 0.05 of a single CPU core. If we compare that with a running weekly average graph as shown below, we will see that the averages are consistently around .03 CPU usage throughout the 24 hour range. These averages shown in the graph give a good indicator of where our resource request values will be set; the bursts shown in the CPU usage graph are critical in determining the resource limits when setting the constraints of a single Pod. Understanding the scale and frequency of bursts will also help determine what type of approaches to use when managing the hosting of an application.
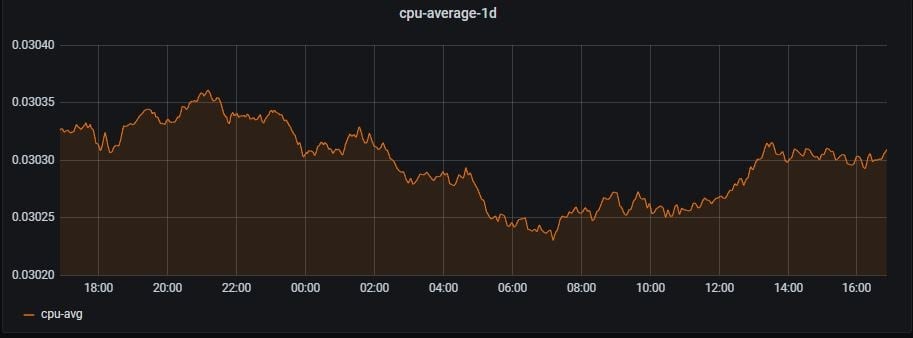
|
pod:container_cpu_usage:sum:avg_over_time_1week{namespace="metrics-blog", pod="metrics-demo-base-64868ddd-xwhzt", prometheus="openshift-monitoring/k8s"} |
The running average shown above and standard deviation used in the next section are two critical sets of data needed to calculate empirical resource constraints that can be calculated using the usage metric already being collected by Prometheus. The image below indicates what the PrometheusRule resource used to start collecting these two calculated metrics:
|
apiVersion: monitoring.coreos.com/v1 |
Detecting Bursts
Now that prometheus is collecting the standard division and average, there is additional data that can be used to learn more about how a certain application utilizes its resources. This article won’t cover in detail what a standard deviation4 or what a z-score4 is, but they are units that show the amount of variety in a set of data. Once the standard deviation is available a z-score can be calculated along with the CPU usage. This next graph shows how many standard deviations that the CPU usage is above or below the running mean average. These values shown on the z-score graph can tell many critical insights into the running application and can be used to determine cost-saving measures.

|
# Query A - z-score |
A high positive or negative z-score value indicates a significant burst. In the case of the example calculate pi application it is an indicator that it is calculating a higher decimal value of pi, usually over 100,000 decimal places. If the graph went over plus or minus 4 units on the z-score graph regularly, that would indicate that the application consists of significant bursts. This might mean that the application only processes jobs periodically, or in the case of the accounts payable example, the possibility that the process only runs once a month. If this is the case, resource constraints shouldn’t be the only solution for cost-saving measures and other solutions should be considered like Knative5 (OpenShift Serverless6) or HorizontalPodAutoscaler7.
Empirical Constraints
A common statistical benchmark is adding different multiples of the standard deviation (commonly expressed as the greek letter sigma) to the average which, if the z-scores are mostly between plus or minus 4, can give a calculated percentile. In this case we are only concerned about positive deviations, as negative values are simply the CPU being underutilized and below the average, not a value we need to calculate our limits. In the case of a single deviation plus the running average (average + sigma), this is around the 84th percentile of CPU usage and also acts as a good value for our resource request constraint. In k8s the request constraint is the amount of CPU that the system will attempt to always have available for your application, even when the application may not be using the full amount allocated.
This calculated value of the average + sigma line is also a useful value for when to trigger horizontal pod scaling if your z-score had periods of significant spikes going over 4 on the graph. Horizontal pod scaling is an effective tool against high bursts of CPU or memory usage, and can help keep costs down by setting parameters around when the pods scale down after a burst.
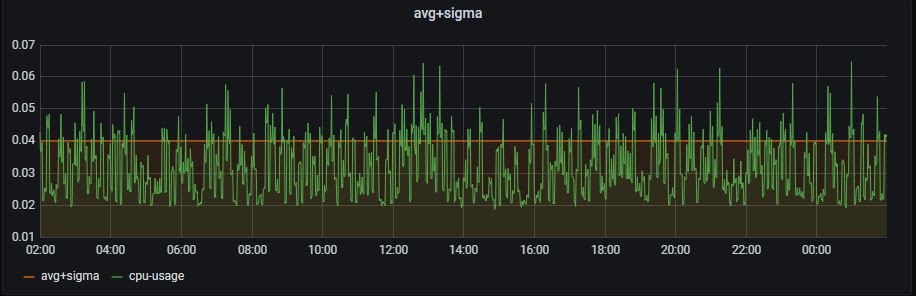
|
# Query A - average + sigma line |
Calculating the limit of a resource constraint for a Pod is a bit easier in that the only value needed is the maximum value within the data. If we look at the graph below, this value is 0.065 CPU cores. Throughout the entire day of usage, we only see about 5 instances where spikes get close to this maximum value. This is a safe value for CPU maximums, but for memory it is recommended to pad this value by adding 20% of the max to the total limit to prevent an Out of Memory (OOM) failure. This can prevent a container from unexpectedly restarting. In k8s the limit8 constraint is the maximum allocated amount for a resource type.
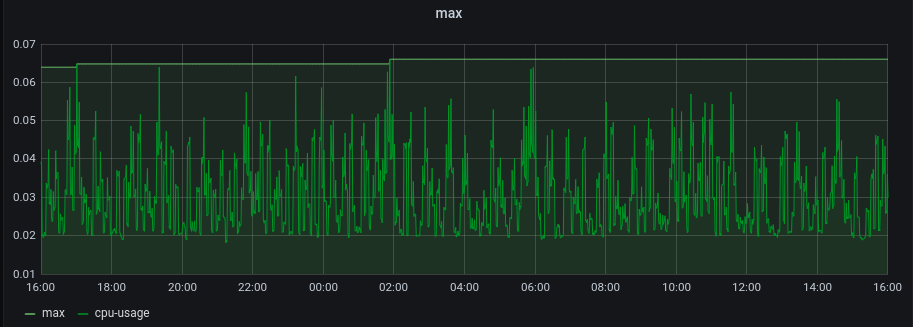
|
# Query A - max cpu |
Conclusion
Metrics can be used to generate a variety of data that can help determine what type of resource constraints to set when configuring your application pods. When combined with graphs, this approach can give significant insights into how your application runs and help discover when tools like horizontal pod scaling are needed. This isn’t an easy solution though, and this type of approach takes constant monitoring of data to reevaluate resource constraints as your application grows. This process takes input from many different stakeholders and requires data collected over time to calculate accurately. In the end you will need to answer the chicken before the egg problem and determine an approach that works best within your product lifecycle.
Additional Resources
- The k8s resources used to produce this blog post can be found on GitHub.
- More about resource constraints and scaling can be found in the following blog series.
- Deploying custom grafana dashboards on OpenShift 4.
- Utilizing z-score within Prometheus monitoring.
References
- https://kubernetes.io/docs/concepts/policy/resource-quotas
- https://github.com/cnuland/metrics-graph-demo/tree/master/base
- https://www.mathsisfun.com/data/standard-deviation.html
- https://www.mathsisfun.com/definitions/z-score.html
- https://knative.dev
- https://www.openshift.com/learn/topics/serverless
- https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autosca…
- https://kubernetes.io/docs/concepts/configuration/manage-resources-cont…
About the author
Christopher Nuland is a Principal Technical Marketing Manager for AI at Red Hat and has been with the company for over six years. Before Red Hat, he focused on machine learning and big data analytics for companies in the finance and agriculture sectors. Once coming to Red Hat, he specialized in cloud native migrations, metrics-driven transformations, and the deployment and management of modern AI platforms as a Senior Architect for Red Hat’s consulting services, working almost exclusively with Fortune 50 companies until recently moving into his current role. Christopher has spoken worldwide on AI at conferences like IBM Think, KubeCon EU/US, and Red Hat’s Summit events.
More like this
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Why Red Hat partners are the ultimate telco business asset
The Containers_Derby | Command Line Heroes
Crack the Cloud_Open | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds