Introduction
In the first part of this series, we introduced the concept of SLI (Service Level Indicator), SLO (Service Level Objective), and error budget along with some approaches for configuring error budget-related alerts and dashboard. While this discussion provided a good initial baseline, the error budget is probably not the only metrics that we should monitiing for our services. What other metrics should we be monitoring to provide a more holistic approach?
Metrics-Gathering Approaches
If we intimately know the service that we need to monitor, we also have an understanding of which metrics are the better indicators of the service performance.
But, can we try to abstract the question and capture meaningful metrics regardless of the specific nature of the service?
There are two main lines of thoughts on the correct metrics to collect and display in a dashboard for a given service:
- The USE method (as in Utilization, Saturation, Errors) is conceptually a white box method that focuses on internal service metrics.
- The RED method (as in Request rate, Errors and Duration) is conceptually more of a black box approach that focuses on the externally observable metrics.
At Google, SREs use the four golden signals, which roughly corresponds to the RED method plus the saturation metric.
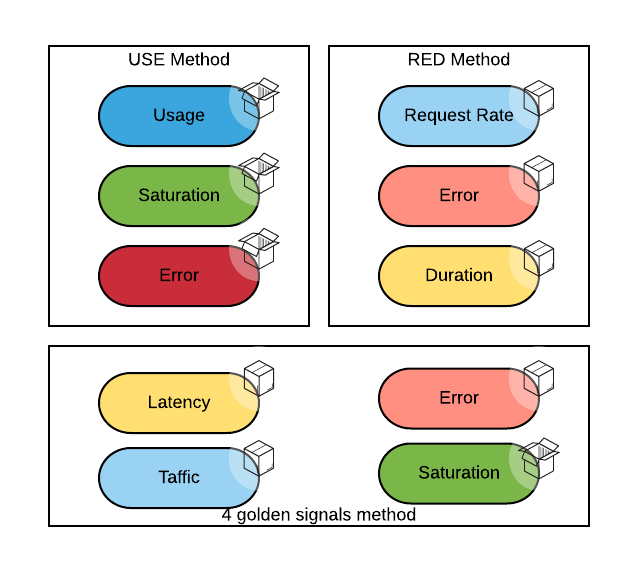
The color coding in this diagram tries to depict when two metrics are the same even if they have different names in different methods. The open box signifies a white box approach (you need to know the internal of the systems to observe it), while the close box emphasizes a black box approach (you can observe the system from the outside).
The USE Method
The USE method, as previously stated, consists of collecting and displaying the following metrics:
Utilization: the percentage of time a resource has been utilized
Saturation: the degree to which the resource has extra work that it can't service; often queued
Errors: the number of error reported by each resource
These measures should be collected for the significant resources of a system, typically memory, CPU, disk, and network.
In OpenShift, these types of metrics are collected by the cluster monitoring stack.Below we present how we can query these metrics with PromQL (with an assumption of pod level aggregation):
CPU Utilization:
pod:container_cpu_usage:sum
CPU Saturation:
sum by (pod,namespace) (rate(container_cpu_cfs_throttled_seconds_total{container=!""}[5m]))
CPU Errors: N/A : cpu errors, which is not an easy concept to define to begin with, are not exported by cAdvisor
Here is what this section of the dashboard might look like:

Memory Utilization:
sum by(pod,namespace) (container_memory_working_set_bytes{container="",pod!=""})
This rule also exists: pod:container_memory_usage_bytes:sum, but it considers parts of memory (such as the cached file system), which can be evicted under pressure. working_set is a more accurate method to track the actual usage.
Memory Saturation:
max by (pod,namespace) (container_memory_working_set_bytes{container!=""} / on (pod,namespace,container) label_join(kube_pod_container_resource_limits_memory_bytes{},"container_name", "", "container"))
Here, we calculate the ratio between the used memory and the memory limit of a container (if the latter exists).
If a pod has more than one container, we keep the highest ratio.
Memory Errors:
sum by (pod,namespace) (rate(container_memory_failures_total{container!="POD"}[5m]))
Here is what this section of the dashboard might look like:

Network Utilization:
sum by (pod,namespace) (rate(container_network_transmit_bytes_total[5m])) + sum by (pod,namespace) (rate(container_network_receive_bytes_total[5m]))
Network Saturation: N/A
Not enough metrics exposed. Difficult to calculate without knowing the network bandwidth.
Network Errors:
sum by (pod,namespace) (rate(container_network_receive_errors_total[5m])) + sum by (pod,namespace) (rate(container_network_transmit_errors_total[5m])) + sum by (pod,namespace) (rate(container_network_receive_packets_dropped_total[5m])) + sum by (pod,namespace) (rate(container_network_transmit_packets_dropped_total[5m]))
Here is what this section of the dashboard might look like:

Disk Utilization:
pod:container_fs_usage_bytes:sum
Disk Saturation: N/A
Not enough metrics exposed. Saturation is also dependent on disk type.
Disk Error: N/A
Not enough metrics exposed.
Here is what this section of the dashboard might look like:

We have chosen to aggregate these metrics at the pod level as it seemed the most appropriate level for troubleshooting.
The panels with N/A metrics represent metrics that are currently difficult to measure or collect. Future evolution of the Kubernetes metrics system might allow us to fill those gaps.
The RED method
The RED method consists of observing the following metrics:
Rate of requests: generally in the form of requests per second.
Errors: Number of requests that returned an error condition.
Duration: The time it took to process the requests.
These metrics may change based upon the use case. For a HTTP service managed by Istio, we can create a set of standardized PromQL expressions. All the metrics in the tables below are collected by the OpenShift ServiceMesh observability stack:
Rate:
sum(rate(istio_requests_total{reporter="source"}[5m]))
Errors:
sum(rate(istio_requests_total{reporter="source",response_code~”5.*”}[5m]))
Duration:
sum by (le,destination_service_name,destination_service_namespace) (rate(istio_request_duration_seconds_bucket[5m]))
This will create a histogram with the same buckets that are preconfigured in Istio
Here is what a RED method dashboard for an Istio service might look like:
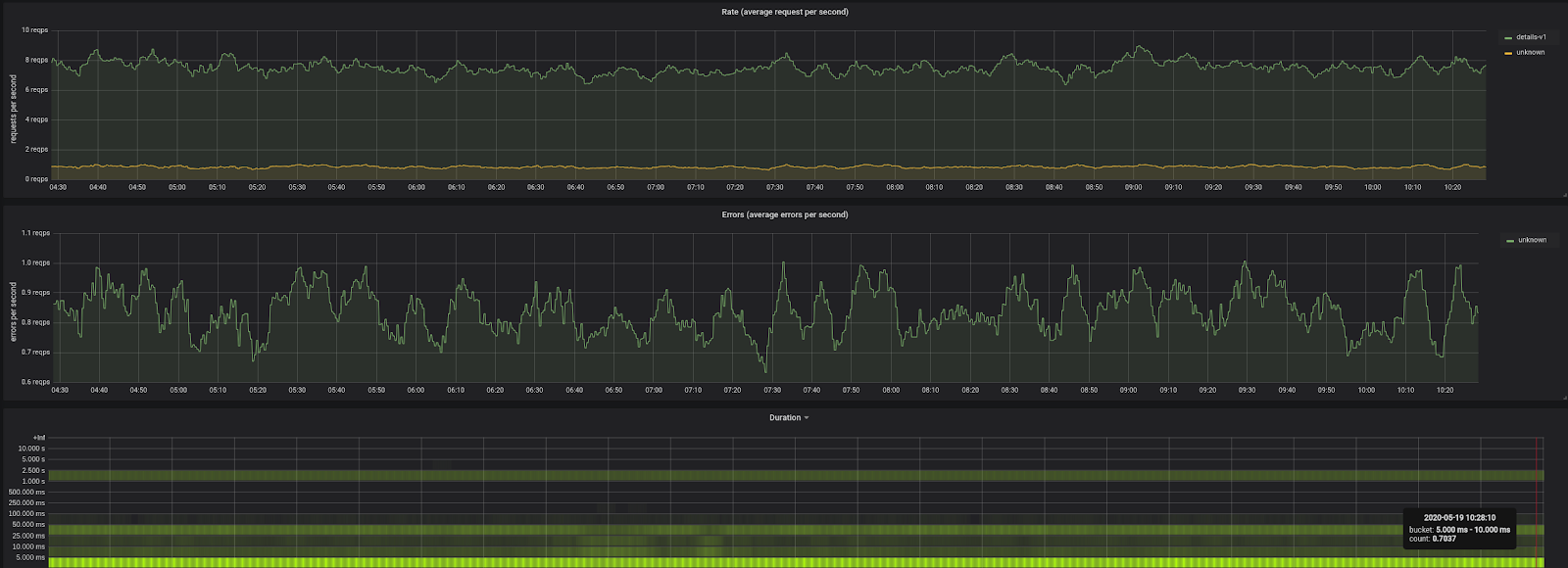
The Four Golden Signals
As introduced previously, the four golden signals are the same metrics as per the RED method plus saturation. Saturation here is not intended to be represented as the basic resource saturation, as in the USE method. Saturation is more of a measure how much of the system capacity of handling requests we are consuming. If the system is a queue, then the saturation is essentially the length of the queue. Other systems will have specific metrics that can be used to calculate saturation. For this reason, it is difficult to standardize on a saturation metric, and Istio does not provide a simple way to do it. This is a place where, for example, Knative (or OpenShift Serverless) provides more insight as it allows us to inspect the depth of the request queue.
We did not create a dashboard for the four golden signals as it would look the same as the RED method dashboard.
Installation
Using this repository, you can find instructions on how to deploy the dashboard showcased in this article.
Alerting and Automation
We saw how to create alerts on the Error Budget, which gives us a method for determining if an issue is occuring to our services. But, is there a way to proactively alert before something goes wrong?
In theory, the metrics collected by the methods we have examined do allow for that, and the saturation metric is best at sensing when something is about to go wrong. For example, if we are reaching a certain saturation threshold, it might be an indication that something is about to break, even if things are presently working fine.
Preventive alerting enables the creation of self-remediating automations. The most well-known example of this capability is horizontal pod autoscaler (HPA). HPA scales on CPU or memory saturation, and OpenShift has a tech preview feature to enable HPA to scale based on an arbitrary PromQL expression.
Another example is Knative, which also horizontally scales on saturation. However, this time, saturation is interpreted as the length of the request queue.
Keda is another example of an operator that allows for fine-grained autoscale policies to be set based on metrics collected potentially from outside of the cluster.
Vertical Pod Autoscaler (VPA) aids in automatically scaling an application (this time vertically, that is, creating containers of bigger sizes).
It is also conceivable that automation could be created to extend a volume that is getting full. Another example is, in the scenario of a multi-cluster deployment, to start redirecting traffic from one cluster to another if the first cluster is overloaded (when Istio service mesh deployed across multiple clusters behaves in this fashion).
As you can see, operators exist for the most common proactive remediation scenarios. Additional operators and automation implementations can be created for more use case specific scenarios.
In general, it is part of the responsibilities of an SRE to identify preventive care use cases and automate them. Usually, the identification of these use cases occurs as a consequence of a post-mortem analysis.
Conclusion
In this article, we addressed which metrics are generally relevant to collect, based on some industry standard monitoring approaches and how it is possible to create dashboards with those metrics. This is just the beginning of the journey to build a solid monitoring system. As you learn more about your workload, you might have to collect non-standard metrics and build more specialized dashboards. In addition, you will uncover the proper thresholds for your preventive alerts and what are the correct preventive actions to be triggered by those alerts.
About the author

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
The agentic paradox and the case for hybrid AI
Context-aware advisor recommendations in Red Hat Lightspeed
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds