
The job of the Performance and Latency Sensitive Applications (PSAP) team at Red Hat is optimizing Red Hat OpenShift, the industry’s most comprehensive enterprise Kubernetes platform, to run compute-intensive enterprise workloads and HPC applications effectively and efficiently. As a team of Linux and performance enthusiasts who are always pushing the limits of what is possible with the latest and greatest upstream technologies, we are operating at the forefront of innovation with compelling proof-of-concept (POC) implementations and advanced deployment scenarios.
NFD Update
OpenShift 4.7 comes with tons of new features and enhancements, and the Node Feature Discovery Operator wasn’t going to fall behind.
The first and most exciting highlight of the release is that v4.7 NFD is the first release cut from upstream NFD Operator Release-v.0.2.0. This release comes packed with:
- Node-Feature-Discovery v0.7.0 (#40)
- Dependencies updated to Kubernetes 1.19 and GO 1.15 (#35)
- An expanded NodeFeatureDiscovery CRD that now exposes nfd-worker-conf as part of the CR, so it can be dynamically modified by simply editing the resource (#39)
- Added support for master:worker hybrid nodes (Single node OpenShift, as well as three nodes master:worker deployment), being used in edge deployments (#37)
- NFD operator enabled to deploy nfd-worker pods on nodes labeled other than "node-role.kubernetes.io/worker" (#31). So deployments with infra nodes, or nodes not labeled as worker nodes but as other custom use cases, will all get the daemon set of the NFD worker pod.
The upstream community has been very busy working on adding stability and new features to the Node-Feature-Discovery project, leading it to its new version v0.7.0. Starting with exciting news, we have a documentation page for all things related to NFD. The list of changes includes:
- Added kconfig and cpuid rules to the custom feature source (#334)
- Support for ARM/Aarch32 cpuid (#322)
- Added a --prune flag to nfd-master (#326)
- Updated cpuid, support for Intel Sapphire Rapids (#406)
- Shortcut to enable all feature sources with --sources=all (#356)
- Bug fix in kernel version number sanitization (#402)
- Fixed sporadic worker restarts (#336)
- Deployment templates that create and mount a nfd-worker.conf ConfigMap (#386)
- Changed default namespace in the deployment specs to node-feature-discovery (#365)
- Updated dependencies to Kubernetes v1.19 and Golang v1.15
- Make-build customization through Makefile variables more coherent (#351, #355, #404)
This is a lot to pack in a release. This is why we moved the API version, and CRD version, from v1alpha1 to v1. This will require users upgrading from 4.6 to create a new CR that will look as follows:
```yaml
apiVersion: nfd.openshift.io/v1
kind: NodeFeatureDiscovery
metadata:
name: nfd-master-server
namespace: <REPLACE_NAMESPACE>
spec:
operand:
namespace: node-feature-discovery-operator
image: registry.redhat.io/openshift4/ose-node-feature-discovery:v4.7.0
imagePullPolicy: Always
workerConfig:
configData: |
sources:
pci:
deviceLabelFields:
- "vendor"
deviceClassWhitelist:
- "0200"
- "03"
- "12"
```
It is highly recommended to delete the old CR v1alpha1 before updating to this release of the NFD operator. This will remove objects owned by the resource and make room for the resources being owned by the new operator version. As always, this can be done using the web console of OpenShift on the “Installed Operators” section, going into the Node-Feature-Discovery Operator, and clicking on “Create new instance.” This will prompt a form that looks like this:
---
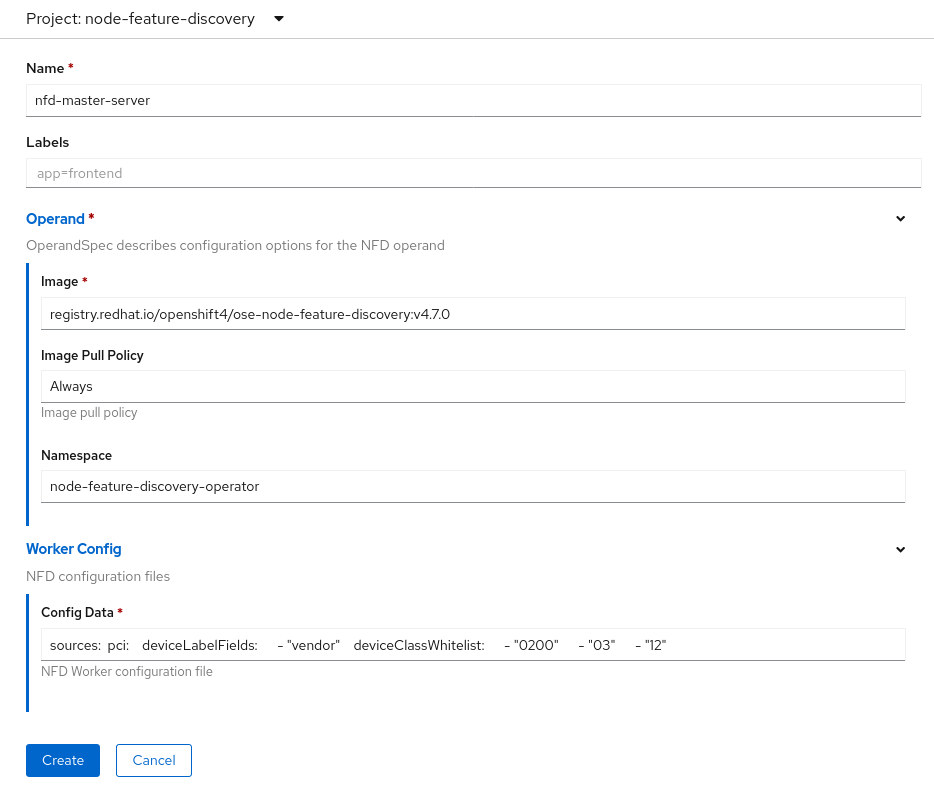
Remember to set the “Namespace” to your preferred one, or leave it as it is (requirement: the namespace has been created previously before installing the operator step).
You can also see that the web form has a new entry from the previous 4.6 version, the “Worker Config.” Now users can define the nfd-worker.conf file from the beginning when installing NFD from the web console and will be able to edit it as necessary by simply editing the NFD custom resource.
Future Work
The Node-Feature-Discovery upstream community is growing and busy making improvements coming in the 4.8 release of NFD, so stay tuned!
We believe that Linux containers and container orchestration engines, most notably Kubernetes, are well positioned to power future software applications spanning multiple industries. Red Hat has embarked on a mission to enable some of the most critical workloads like machine learning, deep learning, artificial intelligence, big data analytics, high-performance computing, and telecommunications, on Red Hat OpenShift. By developing the necessary performance and latency-sensitive application platform features of OpenShift, the PSAP team is supporting this mission across multiple footprints (public, private, and hybrid cloud), industries, and application types.
About the author
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
How Red Hat OpenShift 4.22 impacts enterprise AI’s bottom line
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds