
OpenShift/Kubernetes provides a few simple concepts for placing pods on nodes that can be used to satisfy a wide variety of use cases.
Node Labels and Node Selectors
The most basic placement-related concept OpenShift/Kubernetes provides is a generic node labeling system that can be used to group nodes as desired. By default, every node will at least have its node name as a label. Node labels can be targeted for deployments using node selectors which can be set at either a project (can be used to restrict which nodes a project gets access to) or pod level. Example groupings based on node labels include Region/Zone/Rack for reasons of availability and latency as well as Production/Stage/Test to segregate environments to different parts of the cluster. The node labeling system is completely open ended though so you can choose whatever groupings make sense for your use cases.
Predicates and Priorities
Where things get more interesting is configuring the best fit algorithm for the scheduler. To do this, Kubernetes provides configuration mechanisms known as predicates and priorities. The two concepts are very simple and similar, and yet provide a great deal of flexibility. The scheduling algorithm works as follows:
- From the list of available nodes, filter out those which don't match the configured predicates.
- Ex: Remove nodes which don't match the node selector or don't have enough resources to run a particular pod
- Assign priorities to the remaining nodes based on the configured priorities.
- Ex: Prefer to schedule to the most empty nodes
- Pick the node with the highest priority.
Sounds simple right? But this tool set can be quite powerful. Let's go through an example:
Zones and Racks:
You can adjust the default scheduler policy by modifying /etc/origin/master/scheduler.json. Let's say you want to have affinity for pods of a service within a zone, and anti-affinity for the pods of a service across racks. This configuration should give you what you want:
{
"kind":"Policy",
"apiVersion":"v1",
"predicates":[
{
"name" : "PodFitsResources"
},
{
"name":"ZoneAffinity",
"argument":{
"serviceAffinity":{
"labels":[
"zone"
]
}
}
}
],
"priorities":[
{
"name":"LeastRequestedPriority",
"weight":1
},
{
"name":"RackSpread",
"weight":1,
"argument":{
"serviceAntiAffinity":{
"label":"rack"
}
}
}
]
}
In this setup, the two predicates require that all pods of the same service end up in the same zone (this is a common setup when latency is an issue/concern) and that the selected node has the resources required to run a given pod. While the priorities specify that pods of the same service are desired to be spread across racks within a zone and to favor nodes with the least requested resources. This is a very common setup where availability is desired and latency across rack isn't a concern.
Regardless of your cluster topology, this system should provide you with the flexibility to place pods as desired.
Common Scenarios
I'll refrain from showing the json/yaml for these examples. But it's worth noting a few common setups for the scheduler.
Small-Large Scale / High Availability / Fairly Low Latency (~10-1000 nodes)
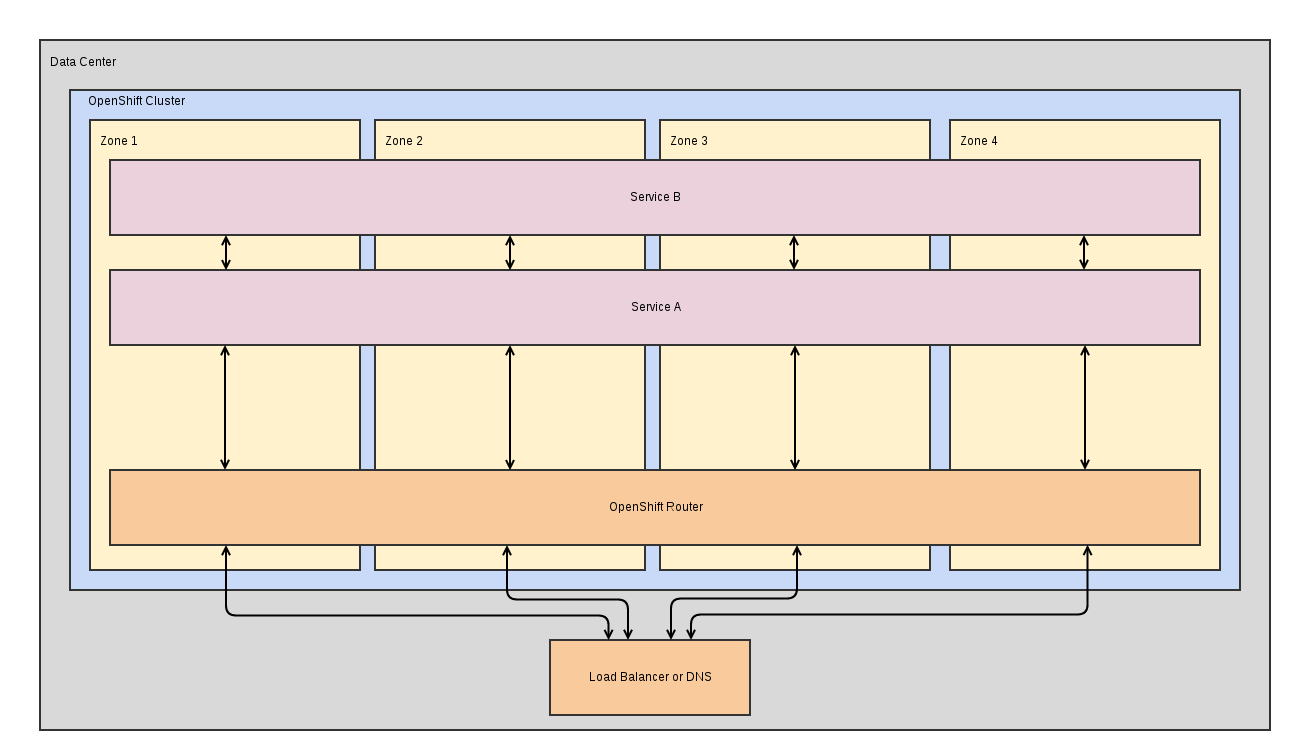
For most applications, there is a desire to get a reasonable amount of HA, even at small to medium scale. As long as you have reasonably low latency between zones, or your applications don't require a lot of cross talk between components, this setup provides a nice balance balance of HA, low administrative overhead, and good user experience. To achieve this setup, you would simply need to set a priority for serviceAntiAffinity across zone. The benefits are enormous:
- Single OpenShift cluster to manage
- Less for the operators to manage
- Easier for users/operators to deploy and maintain their applications
- Scale a component to 2 or more and it gains some level of resiliency. As long as all your application components are scaled. A single zone outage won't take you offline.
If latency between zones is a problem, an alternative approach is to use serviceAffinity for the zones. The downside being that to get resiliency, you will have to deploy your application components multiple times to target each of the desired zones.
Large Scale / Highly Available Applications / Redundant Infrastructure / Extremely Low Latency (~100-10000 nodes)
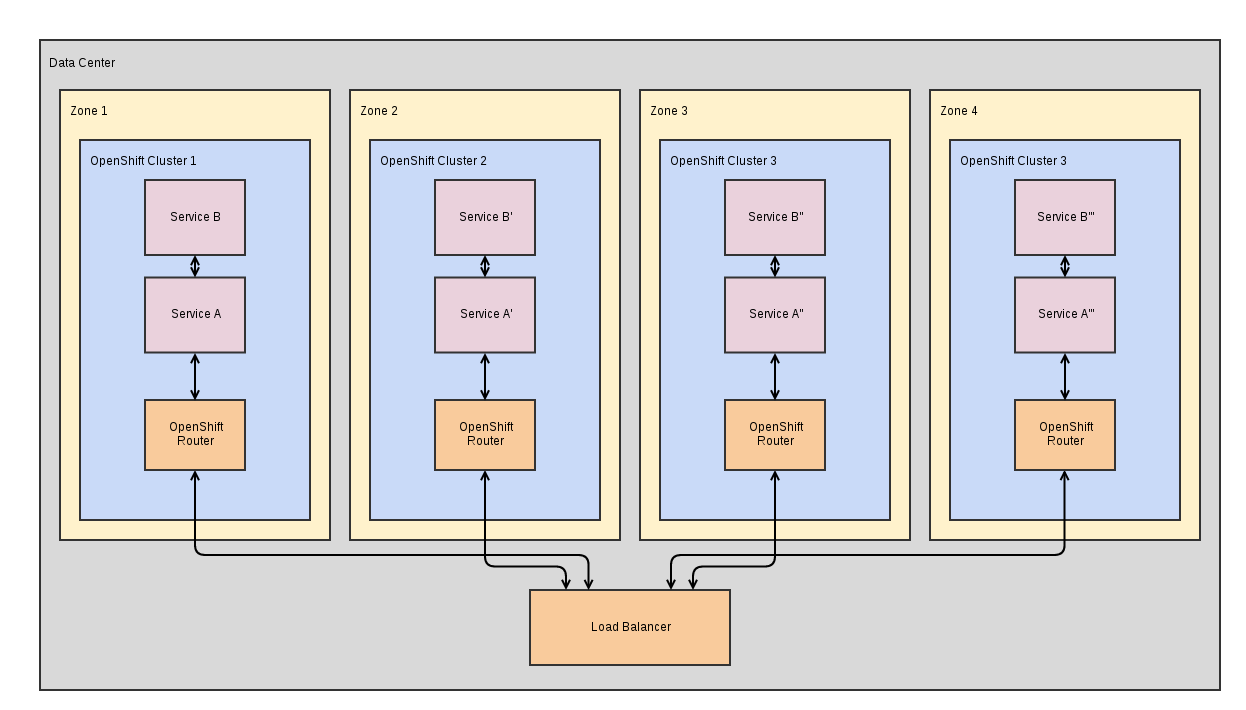
In cases where resources aren't a limitation and high availability takes precedence over usability and simplicity, a cluster per availability zone has its advantages. This setup requires no additional scheduler configuration (unless you are able to apply labels down to the rack or powerbar). There are, however, some obvious downsides to this approach:
- Operators have to maintain multiple OpenShift clusters
- Users/Operators have to deploy their application multiple times and tie together with an external load balancer
But the hard fought advantages are sometimes mission critical:
- Every application component will be redundant
- Losing a zone puts you into a very clear cut degraded state which makes it easy to calculate how many zones you can lose and still have enough capacity to handle expected load
- Having redundant clusters means outages with OpenShift infrastructure (masters, routers, registries, etc) are likely limited to a single zone.
Hopefully that helps to demystify any of the complexity expected with scheduling and node placement. Of course I didn't cover every scenario, but hopefully you can see how to use these building blocks to accomplish most anything.
About the author
More like this
Beyond the blind spots: Defeating frontier AI model threats in your application development process
Achieve high scalability using Red Hat Satellite Capsule Server
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds