Introduction
Kubernetes and consequently OpenShift adopt a flat Software Defined Network (SDN) model, which means that all pods in the SDN are in the same logical network. Traditional network implementations adopt a zoning model in which different networks or zones are dedicated to specific purposes, with very strict communication rules between each zone. When implementing OpenShift in organizations that are using network security zones, the two models may clash. In this article, we will analyze a few options for coexistence. But first, let’s understand the two network models a bit more in depth.
The Network Security Zone Model
Network Zones have been the widely accepted approach for building security into a network architecture. The general idea is to create separate networks, each with a specific purpose. Each network contains devices with similar security profiles. Communications between networks is highly scrutinized and controlled by firewall rules (perimeter defense).
Typically a network architecture is three-tiered as shown here:
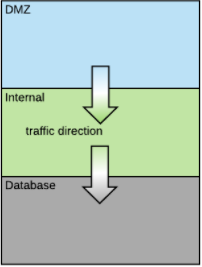
In this architecture, each layer from top to bottom represent a zone with increased security and trust. The first layer is called demilitarized zone (DMZ) and is exposed to the internet. The internal layer is typically where applications reside and the database layer is where the database and other data stores reside.
The DMZ is in certain aspects a special zone. This is the only zone exposed to inbound traffic coming from outside the organization. It usually contains software such as IDS (intrusion detection systems), WAFs (Web Application Firewalls), secure reverse proxies, static web content servers, firewalls and load balancers. Some of this software is normally installed as an appliance and may not be easy to containerize and thus would not generally be hosted within OpenShift.
Regardless of the zone, communication internal to a specific zone is generally unrestricted.
Variations on this architecture are common and large enterprises tend to have several dedicated networks. But the principle of purpose-specific networks protected by firewall rules always applies.
In general, traffic is supposed to flow only in one direction between two networks (as in an osmotic membrane), but often exceptions to this rule are necessary to support special use cases.
OpenShift Network Model
The Kubernetes and OpenShift network model is a flat SDN model. All pods get IP addresses from the same network CIDR and live in the same logical network regardless of which node they reside on.

We have ways to control network traffic within the SDN using the NetworkPolicy API. NetworkPolicies in OpenShift represent firewall rules and the NetworkPolicy API allows for a great deal of flexibility when defining these rules.
With NetworkPolicies it is possible to create zones, but one can also be much more granular in the definition of the firewall rules. Separate firewall rules per pod are possible and this concept is also known as microsegmentation (see this post for more details on NetworkPolicy to achieve microsegmentation).
One OpenShift Cluster per Network Zone
This option is self-explanatory. If we build one OpenShift cluster per network zone, each cluster is network-isolated from the others and therefore the applications running in it are, as well. It is easy to demonstrate compliance with enterprise security standards (and potentially external regulations) using this approach.
One issue with this approach is the cost of maintenance for OpenShift is somewhat proportionally related to the number of clusters. Therefore, this model drives up the cost of maintaining OpenShift.
This model may not securely handle the use of OpenShift deployed in the DMZ since every OpenShift cluster has endpoints that should be considered internal only and not be exposed to the Internet. Endpoints such as the master API, Logging, Metrics, registry, should be internal-only. As such, when installing OpenShift in a DMZ, additional actions are necessary to protect those endpoints.
OpenShift Cluster Covering Multiple Network Zones
The objective here is to have a single OpenShift cluster hosting applications that belong to multiple network zones.The possible communication patterns of these applications will have to comply with the enterprise network policies. There are a few ways to achieve this Here, we are going to examine an approach that is easy to understand and minimizes the firewall rule changes.
With regard to the firewall rule changes needed to support OpenShift, we assume that communication between OpenShift nodes can flow freely when an OpenShift node is installed in a different network zone than other nodes. To achieve this it is likely needed to create firewall rules as prescribed by the standard OpenShift documentation. Your security team must be comfortable creating these exceptions in the firewall. We will see a couple variants of this approach, the above assumption applies to all of them.
The high-level approach is the following:
- Inbound traffic to applications in a given network zone occurs to infra-nodes that are physically located in that network zone.
- Outbound traffic from applications in a given network zone occurs from infra-nodes that are physically located in that network zone and appears to the external observer as if it is coming from an IP belonging to that network zone.
- Internal SDN, pod-to-pod traffic is subject to the same enterprise network policies as the traffic in the normal network zone. To enforce the policies we use the NetworkPolicy API instead of firewall rules on the corporate firewall.
Here is a diagram representing the model over two network zones.

The pod color identifies the network zone they belong to.
Inbound Traffic
To manage inbound traffic, we need to label all the application namespaces (namespaces and projects are very similar concepts in OpenShift, this time we need to use namespaces) with the appropriate network zone. This can be achieved with the following command:
oc label namespace network-zone=<network-zone-name>
We need to deploy two infra-nodes (for High Availability) per network zone in hosts residing in that network zone. These infra-nodes will only contain routers.
We use router sharding with namespace-label-based sharding to make sure that the routers can only route to projects in the same network zone. This can be achieved by adding this environment variable to the network-zone-specific routers:
NAMESPACE_LABELS="network-zone=<network-zone-name>"
If you have a load balancer in front of the routers, then the load balancer VIP must belong to the network zone at hand. In this situation, one alternative is to move the router nodes in the same network zone as all the other Openshift nodes and create network firewall rules from the load balancer to the routers to allow the communication.
Outbound Traffic
In order to manage outbound traffic, we need to deploy two infra-nodes (for high availability) per network zone in hosts residing in that network zone. Depending on load considerations, these nodes can be the same as the ingress nodes.
We can enable static IPs for external project traffic to enforce that all egress traffic from a project egresses with a well known IP (or IPs). This IP will belong to the network zone to which the project belongs (for more information on this new feature, please see also this article).
To configure this, we need to patch the Netnamespace object specifying one or more egress IPs that are supplied by the network zone administrator:
oc patch netnamespace <project_name> -p '{"egressIPs": ["<IP_address>"]}'.
Then we need to patch the nodes with all the egress IPs that they should be managing:
oc patch hostsubnet <egress_node_in_a_network_zone> -p '{"egressIPs": ["<IP_address_1>", "<IP_address_2>"]}'
Note that static egress IPs per project is a feature still in tech preview and currently does not support HA (i.e. egressing from more than one IP).
Using a single egress IP for all the pods of your project makes it impossible to distinguish from which component of the project the connection is coming. This should be perfectly acceptable in most situations. Should you need to be able to distinguish the particular component from which a connection is coming, then you can use an egress router (for reference on how to install this, please see the documentation).
Internal SDN Traffic
For pod to pod traffic, NetworkPolicies can be used to create logical zones in the SDN that map to the enterprise network zones.
For example, based on the above diagram, projects in network zone A will have this network policy:
kind: NetworkPolicy
apiVersion: extensions/v1beta1
metadata:
name: network-zone-A
spec:
ingress:
- from:
- podSelector: {}
- from:
- namespaceSelector:
matchLabels:
name: network-zone-A
- from:
- namespaceSelector:
matchLabels:
name: network-zone-A-router
With this NetworkPolicy, we are allowing traffic from the same namespace, all namespaces that belong to network zone A, and from the routers that route to network zone A.
Projects in network zone B will have the following network policy:
kind: NetworkPolicy
apiVersion: extensions/v1beta1
metadata:
name: network-zone-B
spec:
ingress:
- from:
- podSelector: {}
- from:
- namespaceSelector:
matchLabels:
name: network-zone-A
- from:
- namespaceSelector:
matchLabels:
name: network-zone-B
- from:
- namespaceSelector:
matchLabels:
name: network-zone-B-router
Notice that this NetworkPolicy is similar to the previous one, but adds a rule to allow traffic from network zone A.
Because NetworkPolicy objects become now so instrumental in implementing the enterprise security policy, it is critical to decide who owns the NetworkPolicy objects and to ensure that only the people who have the right to manipulate NetworkPolicies can do so. Custom roles might be needed to secure NetworkPolicy ownership.
With this model, it is irrelevant where the OpenShift control plane (etcd and masters), the infra-nodes dedicated to metrics, registry and logging and the work nodes reside with respect to the network zones served by that cluster. Common options are one of the internal zones, a new network zone dedicated to OpenShift.
The reason why the location of the OpenShift components is irrelevant with respect to complying with the network security policy is that logical network separation is achieved with the use of NetworkPolicy and compute isolation is achieved by the container technology (namespacing and cgroups).
This means for example, that two pods belonging to two different network zones might end up running on the same node. At this point, the isolation is at the logical level rather than physical.
Physical Compute Isolation
Sometimes security policies require that pods belonging to different network zones do not run on the same host. This requirement can also be referred to as physical compute isolation based on network zones.
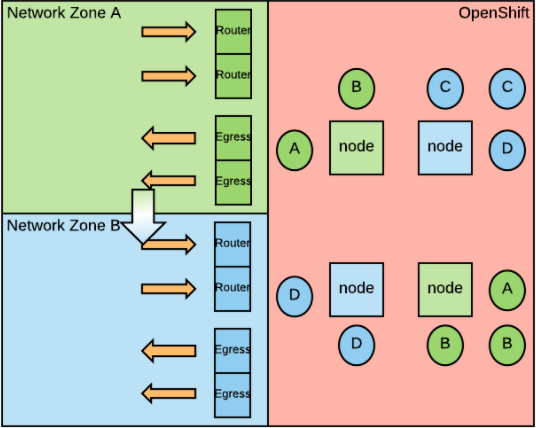
As the picture shows now each node (squares) has a color representing which network zone it serves. And only pods belonging to that network zone can be deployed on it.
To implement this requirement, we can label the nodes based on the network zones:
oc label node network-zone=<network-zone-name>
and then configure the default node selector of the projects to point to the appropriate network zone:
oc patch namespace myproject -p '{"metadata":{"annotations":{"openshift.io/node-selector":"network-zone=<network-zone-name>"}}}'
We also need to make sure that normal users cannot change this annotation.
Notice that by labeling the nodes we create internal fragmentation for the compute resources because this configuration interferes with the ability of OpenShift to optimally allocate workload. For all intents and purposes, with node labeling, OpenShift has to manage multiple separate pools of computing resources, one per network zone.
Another variant is to deploy nodes labeled for a network zone in that specific network zone.
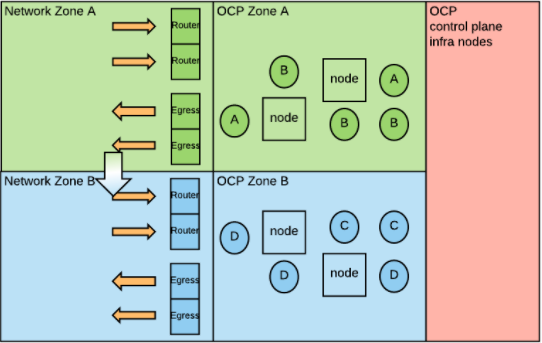
Notice that, because of the initial assumption that all the nodes are free to communicate, this configuration does not significantly increase the security posture, but may make your cluster deployment more complicated. For this reason, the previous approaches are usually considered preferable.
Storage Isolation
Sometimes we can also have storage isolation requirements: pods in a network zone must use different storage endpoints than pods in other network zones. These storage endpoints could be storage servers actually residing in different network zones, or they could just be endpoints belonging to different logical partitions inside a single large storage appliance.
To meet this requirement we can create one storage class per storage endpoint and then control which storage class(es) a project can use by appropriately configuring its storage quota (0 when a project should not use a specific storage endpoint).
For example for a project in network zone A, the quota object may look like:
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage-consumption
spec:
hard:
<A-sc-name>.storageclass.storage.k8s.io/requests.storage: "50Gi"
<B-sc-name>.storageclass.storage.k8s.io/requests.storage: "0Gi"
Physically Segmenting the OpenShift SDN
When reviewing this document with colleagues and customers some have asked if it was possible to physically segment the OpenShift SDN so to have some of the nodes sitting in a network zone physically unable to communicate with other nodes in another network zone. On the surface, this could seem a good way to enforce network isolation. If you remember one of the few assumptions that we made at the beginning is that should never happen. Here is why I strongly recommend against it.
First, one has to make a directional choice on whether to implement network segmentation at the physical layer or at the logical layer (i.e. via SDN policies). The general trend of the IT industry, pushed mainly cloud providers (where everything is at the logical level) is to model policies at the logical layer. The reason is simple, SDN's are more malleable and changes can be introduced more quickly and with less risk. If you make the strategic choice of managing your network policies at the logical level, you shouldn’t mix this direction with physical segmentation as that would be a source of a headache. This is true also in the openshift SDN.
Secondly, the OpenShift documentation clearly states that all nodes should be able to communicate with each other. If you don’t install OpenShift that way you risk that support won’t be able to help you effectively. If you are in this situation I encourage you to make sure with our support team that they can support you.
Finally, there are a set of standard internal services in OpenShift that assume that communication between all the nodes is possible:
- All nodes should be able to pull from the internal docker registry pods, in order to pull images and start pods. All nodes should be able to communicate with elastic search in order to push logs to it.
- The node on which heapster is running should be able to communicate with all the nodes in order to collect metrics.
There can also be third party software that needs connectivity between all the nodes:
- If you have monitoring agents (such as Sysdig or Instana) they usually need to communicate with some central software to push information.
- If you have security agents (such as Twistlock or Aquasec) they usually need to communicate with some central software to get the policies to be enforced.
And with regard to upcoming features:
- The upcoming Prometheus monitoring platform will need to communicate with all the nodes to collect metrics
- If you are planning to install a service mesh (such as istio), the istio control plane needs to communicate with all the nodes on which pods in the service mesh run.
Conclusion
A company’s security organization must be involved when deciding how to deploy OpenShift with regard to traditional network zones. Depending on their level of comfort with new technologies you may have different options. If physical network separation is the only acceptable choice, you will have to build a cluster per network zone. If logical network type of separations can be considered, then there are ways to stretch a single OpenShift deployment across multiple network zones. This post presented a few technical approaches.
About the author

Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
Hardened, ready, and no cost: Container security evolved
OpenShift: Consistent integration for the hybrid enterprise
The Containers_Derby | Command Line Heroes
Can Kubernetes Help People Find Love? | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds