This Blog will go through Ceph fundamental knowledge for a better understanding of the underlying storage solution used by Red Hat OpenShift Container Storage 4.
> Note: This content is relevant to learning about the critical components of Ceph and how Ceph works. OpenShift Container Storage 4 uses Ceph in a prescribed manner for providing storage to OpenShift applications. Using Operators and CustomResourceDefinitions (CRDs) for deploying and managing OpenShift Container Storage 4 may restrict some of Ceph’s advanced features when compared to general use outside of Red Hat OpenShift Container Platform 4.
Timeline
The Ceph project has a long history as you can see in the timeline below.

Figure 29. Ceph Project History
It is a battle-tested software defined storage (SDS) solution that has been available as a storage backend for OpenStack and Kubernetes for quite some time.
Architecture
The Ceph cluster provides a scalable storage solution while providing multiple access methods to enable the different types of clients present within the IT infrastructure to get access to the data.

Figure 30. Ceph Architecture
The entire Ceph architecture is resilient and does not present any single point of failure (SPOF).
RADOS
The heart of Ceph is an object store known as RADOS (Reliable Autonomic Distributed Object Store) bottom layer on the diagram. This layer provides the Ceph software defined storage with the ability to store data (serve IO requests, protect the data, check the consistency and the integrity of the data through built-in mechanisms). The RADOS layer is composed of the following daemons:
- MONs or Monitors
- OSDs or Object Storage Devices
- MGRs or Managers
- MDSs or Meta Data Servers
Monitors
The Monitors maintain the cluster map and state and provide distributed decision-making while configured in an odd number, 3 or 5 depending on the size and the topology of the cluster, to prevent split-brain situations. The Monitors are not in the data-path and do not serve IO requests to and from the clients.
OSDs
One OSD is typically deployed for each local block device present on the node and the native scalable nature of Ceph allows for thousands of OSDs to be part of the cluster. The OSDs are serving IO requests from the clients while guaranteeing the protection of the data (replication or erasure coding), the rebalancing of the data in case of an OSD or a node failure, the coherence of the data (scrubbing and deep-scrubbing of the existing data).
MGRs
The Managers are tightly integrated with the Monitors and collect the statistics within the cluster. Additionally they provide an extensible framework for the cluster through a pluggable Python interface aimed at expanding the Ceph existing capabilities. The current list of modules developed around the Manager framework are:
- Balancer module
- Placement Group auto-scaler module
- Dashboard module
- RESTful module
- Prometheus module
- Zabbix module
- Rook module
- Dashboard module
MDSs
The Meta Data Servers manage the metadata for the POSIX compliant shared filesystem such as the directory hierarchy and the file metadata (ownership, timestamps, mode, …). All the metadata is stored within RADOS and they do not serve any data to the clients. MDSs are only deployed when a shared filesystem is configured in the Ceph cluster.
If we look at the Ceph cluster foundation layer, the full picture with the different types of daemons or containers looks like this.
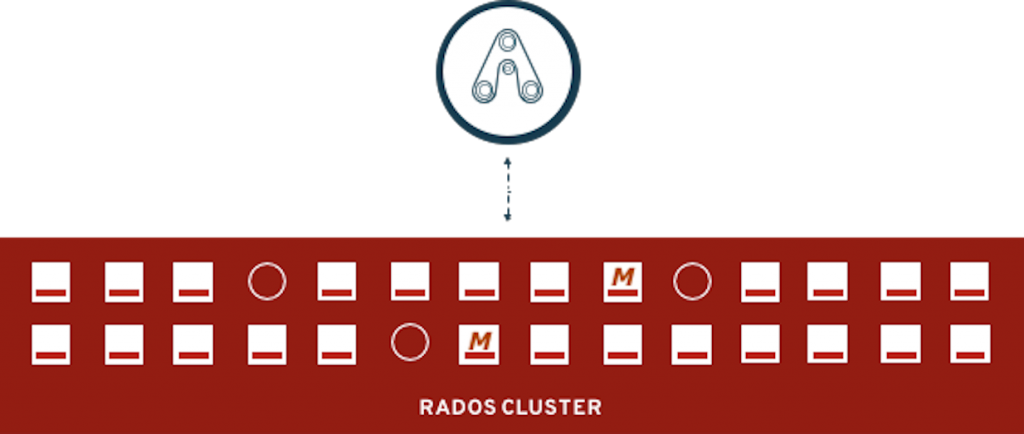
Figure 31. RADOS as it stands
The circle represents a MON, the 'M' represents a MGR and the square with the bar represents an OSD. In the diagram above, the cluster operates with 3 Monitors, 2 Managers and 23 OSDs.
Access Methods
Ceph was designed to provide the IT environment with all the necessary access methods so that any application can use what is the best solution for its use-case.
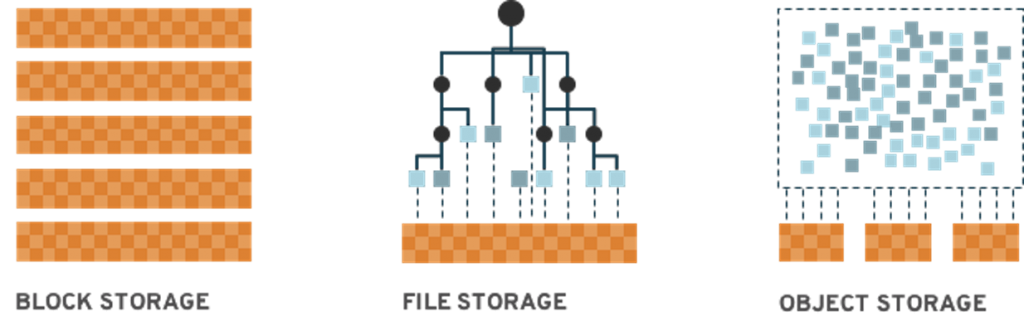
Figure 32. Different Storage Types Supported
Ceph supports block storage through the RADOS Block Device (aka RBD) access method, file storage through the Ceph Filesystem (aka CephFS) access method and object storage through its native librados API or through the RADOS Gateway (aka RADOSGW or RGW) for compatibility with the S3 and Swift protocols.
Librados
librados allows developers to code natively against the native Ceph cluster API for maximum efficiency combined with a small footprint.

Figure 33. Application Native Object API
The Ceph native API offers different wrappers such as C, C++, Python, Java, Ruby, Erlang, Go and Rust.
RADOS Block Device (RBD)
This access method is used in Red Hat Enterprise Linux, Red Hat OpenStack Platform or OpenShift Container Platform version 3 or 4. RBDs can be accessed either through a kernel module (RHEL, OCS4) or through the librbd API (RHOSP). In the OCP world, RBDs are designed to address the need for RWO PVCs.
Kernel Module (kRBD)
The kernel RBD (aka krbd) driver offers superior performance compared to the userspace librbd method. However, krbd is currently limited and does not provide the same level of functionality. e.g., no RBD Mirroring support.
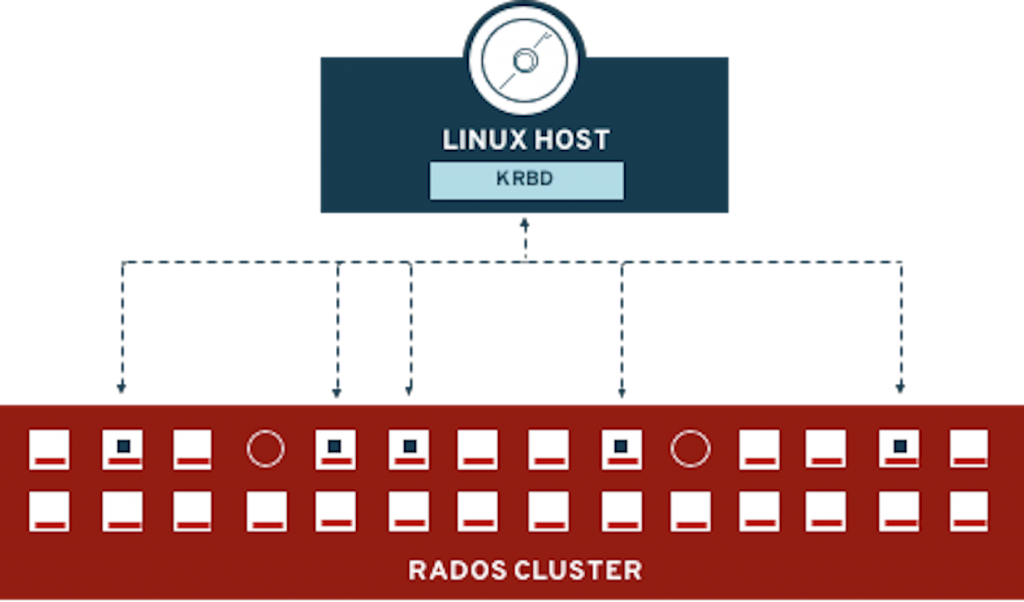
Figure 34. krbd Diagram
Userspace RBD (`librbd`)
This access method is used in Red Hat OpenStack Environment or OpenShift through the RBD-NBD driver when available starting in the RHEL 8.1 kernel. This mode allows us to leverage all existing RBD features such as RBD Mirroring.
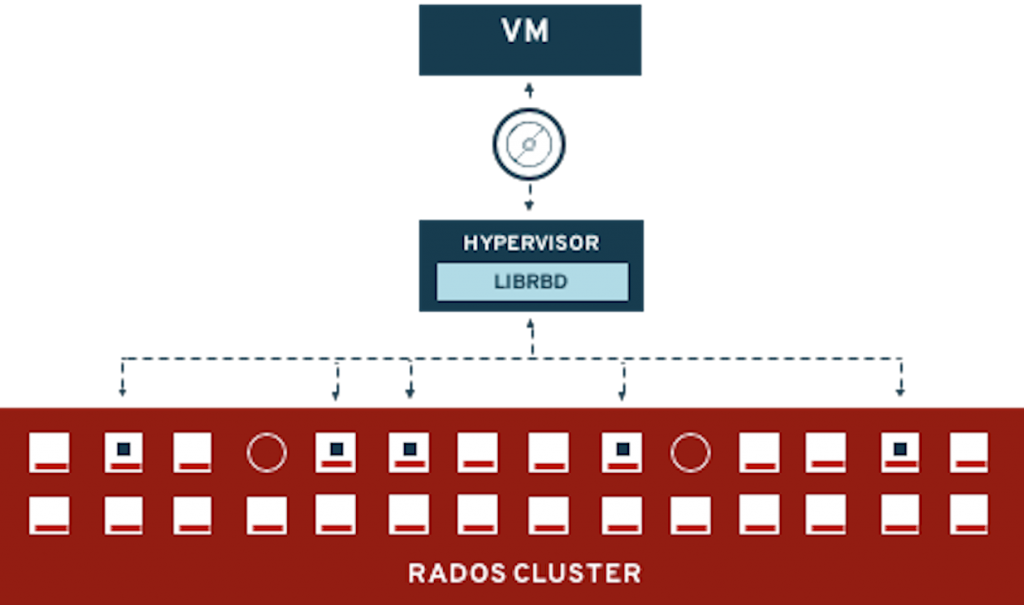
Figure 35. librbd Diagram
Shared Filesystem (CephFS)
This method allows clients to jointly access a shared POSIX compliant filesystem. The client initially contacts the Meta Data Server to obtain the location of the object(s) for a given inode and then communicates directly with an OSD to perform the final IO request.
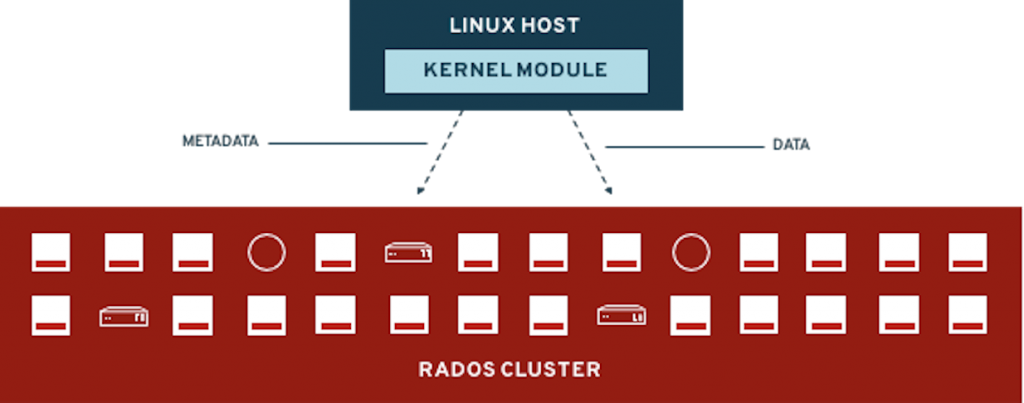
Figure 36. File Access (Ceph Filesystem or CephFS)
CephFS is typically used for RWX claims but can also be used to support RWO claims.
Object Storage, S3 and Swift (Ceph RADOS Gateway)
This access method offers support for the Amazon S3 and OpenStack Swift support on top of a Ceph cluster. The Openshift Container Storage Multi Cloud Gateway can leverage the RADOS Gateway to support Object Bucket Claims. From the Multi Cloud Gateway perspective the RADOS Gateway will be tagged as a compatible S3 endpoint.
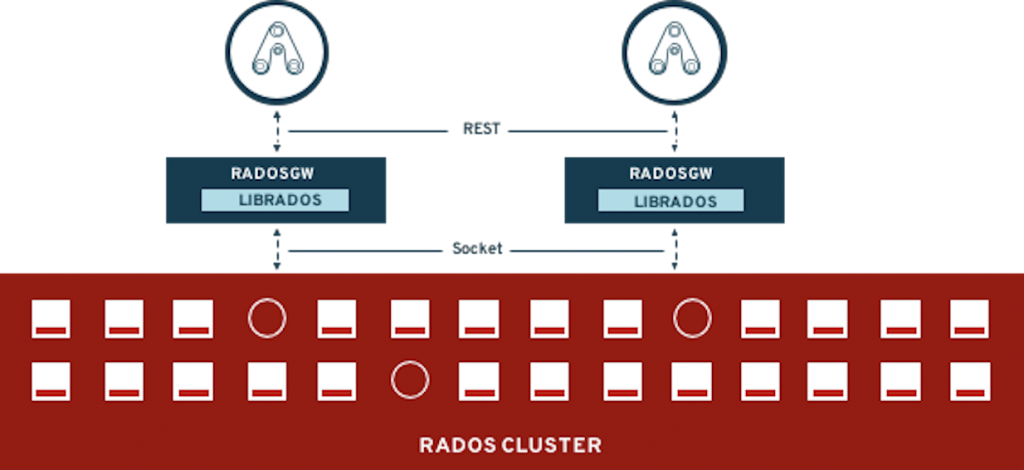
Figure 37. Amazon S3 or OpenStack Swift (Ceph RADOS Gateway)
CRUSH
The Ceph cluster being a distributed architecture some solution had to be designed to provide an efficient way to distribute the data across the multiple OSDs in the cluster. The technique used is called CRUSH or Controlled Replication Under Scalable Hashing. With CRUSH, every object is assigned to one and only one hash bucket known as a Placement Group (PG).

CRUSH is the central point of configuration for the topology of the cluster. It offers a pseudo-random placement algorithm to distribute the objects across the PGs and uses rules to determine the mapping of the PGs to the OSDs. In essence, the PGs are an abstraction layer between the objects (application layer) and the OSDs (physical layer). In case of failure, the PGs will be remapped to different physical devices (OSDs) and eventually see their content resynchronized to match the protection rules selected by the storage administrator.
Cluster Partitioning
The Ceph OSDs will be in charge of the protection of the data as well as the constant checking of the integrity of the data stored in the entire cluster. The cluster will be separated into logical partitions, known as pools. Each pool has the following properties that can be adjusted:
- An ID (immutable)
- A name
- A number of PGs to distribute the objects across the OSDs
- A CRUSH rule to determine the mapping of the PGs for this pool
- A type of protection (Replication or Erasure Coding)
- Parameters associated with the type of protection
- Number of copies for replicated pools
- K and M chunks for Erasure Coding
- Various flags to influence the behavior of the cluster
Pools and PGs

Figure 38. Pools and PGs
The diagram above shows the relationship end to end between the object at the access method level down to the OSDs at the physical layer.
> Note: A Ceph pool has no capacity (size) and is able to consume the space available on any OSD where its PGs are created. A Placement Group or PG belongs to only one pool and an object belongs to one and only one Placement Group.
Data Protection
Ceph supports two types of data protection presented in the diagram below.
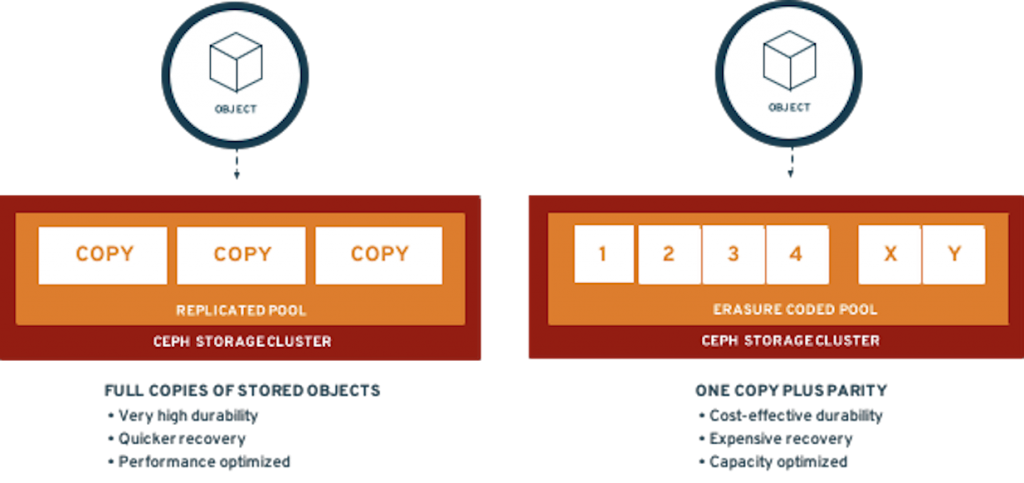
Figure 39. Ceph Data Protection
Replicated pools provide better performance in almost all cases at the cost of a lower usable to raw storage ratio (1 usable byte is stored using 3 bytes of raw storage by default) while Erasure Coding provides a cost efficient way to store data with less performance. Red Hat supports the following Erasure Coding profiles with their corresponding usable to raw ratio:
- 4+2 (1:1.666 ratio)
- 8+3 (1:1.375 ratio)
- 8+4 (1:1.666 ratio)
Another advantage of Erasure Coding (EC) is its ability to offer extreme resilience and durability as adminstrators can configure the number of coding chunks (parities) being used. EC can be used for the RADOS Gateway access method and for the RBD access method (performance impact).
Data Distribution
To leverage the Ceph architecture at its best, all access methods but librados, will access the data in the cluster through a collection of objects. Hence a 1GB block device will be a collection of objects, each supporting a set of device sectors and a 1GB file is stored in a CephFS directory will be split into multiple objects. Similarly, a 5GB S3 object stored through the RADOS Gateway via the Multi Cloud Gateway will be divided into multiple objects. The example below illustrates this principle for the RADOS Block Device access method.
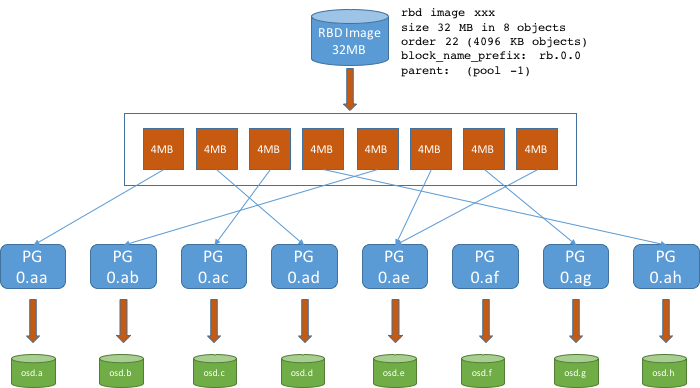
Figure 40. Data Distribution
> Note: By default, each access method uses an object size of 4MB. The above diagram details how a 32MB RBD (Block Device) supporting a RWO PVC will be scattered throughout the cluster.
Resources and Feedback
To find out more about OpenShift Container Storage or to take a test drive, visit https://www.openshift.com/products/container-storage/.
If you would like to learn more about what the OpenShift Container Storage team is up to or provide feedback on any of the new 4.2 features, take this brief 3-minute survey.
About the author

Red Hatter since 2018, technology historian and founder of The Museum of Art and Digital Entertainment. Two decades of journalism mixed with technology expertise, storytelling and oodles of computing experience from inception to ewaste recycling. I have taught or had my work used in classes at USF, SFSU, AAU, UC Law Hastings and Harvard Law.
I have worked with the EFF, Stanford, MIT, and Archive.org to brief the US Copyright Office and change US copyright law. We won multiple exemptions to the DMCA, accepted and implemented by the Librarian of Congress. My writings have appeared in Wired, Bloomberg, Make Magazine, SD Times, The Austin American Statesman, The Atlanta Journal Constitution and many other outlets.
I have been written about by the Wall Street Journal, The Washington Post, Wired and The Atlantic. I have been called "The Gertrude Stein of Video Games," an honor I accept, as I live less than a mile from her childhood home in Oakland, CA. I was project lead on the first successful institutional preservation and rebooting of the first massively multiplayer game, Habitat, for the C64, from 1986: https://neohabitat.org . I've consulted and collaborated with the NY MOMA, the Oakland Museum of California, Cisco, Semtech, Twilio, Game Developers Conference, NGNX, the Anti-Defamation League, the Library of Congress and the Oakland Public Library System on projects, contracts, and exhibitions.
More like this
Navigating the Mythos-haunted world of platform security
Managed identity in Azure Red Hat OpenShift portal
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds