
We consultants often have to adapt to the customer's infrastructural situation and find the simplest and most maintainable way to face problems that are not always easy to solve.
Fortunately, OpenShift 4 has greatly simplified the installation procedure while maintaining high levels of customization.
This blog will analyze a real customer's requests about a passive disaster recovery procedure and how they have been addressed: let’s get started!
Scenario
The customer is a primary bank in Italy that follows BCE’s best practices for passive disaster recovery based on hypervisor high availability and storage low-level replication. There are two datacenters: one for production and one for the disaster recovery purpose.
For OpenShift disaster recovery this scenario is unsupported because it can lead to corruption of the OCP Etcd database when DR has been activated with standard procedures based on VM replication (e.g. VMware Site Recovery Manager).
Futher, in case of DR, all primary services (VMs) and OCP clusters must go live in the secondary datacenter using same ipv4 address, gateway, DNS and routing table they had in the primary datacenter.
This is a significant constraint that needs to be addressed.
For example, it is impossible to run the same AD server or an Image Repository or the same OpenShift cluster on both data centers simultaneously (the OCP API server IP address can not be changed). Therefore the only possible solution is to start all the virtual machines on the secondary data center only when the primary datacenter is completely isolated or unreachable (from a networking point of view).
The following images describe a high-level overview of the scenario:
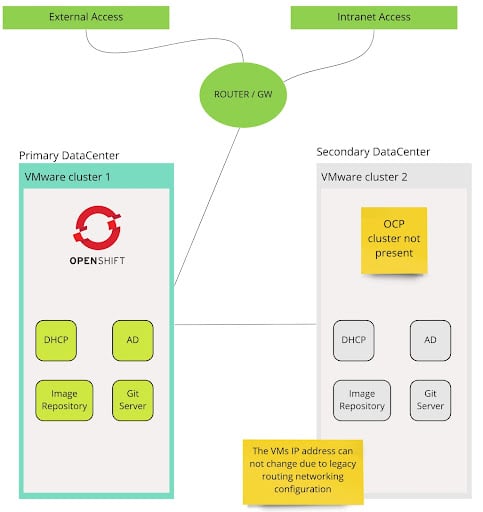
Normal operativity - all the services running in the Primary Datacenter on VMware Cluster 1
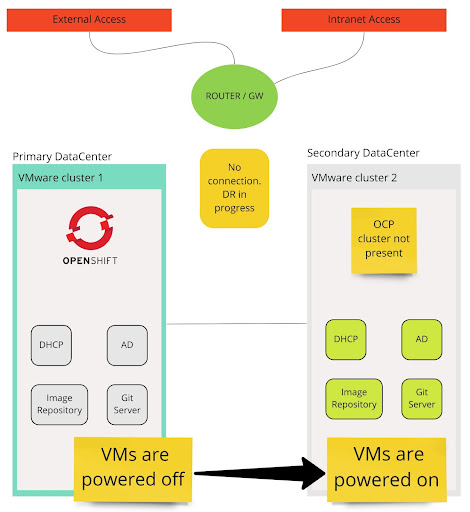
Disaster recovery in progress - all the VMS running on the secondary datacenter will use the same ipv4 address, gateway, DNS and routing table of the primary datacenter
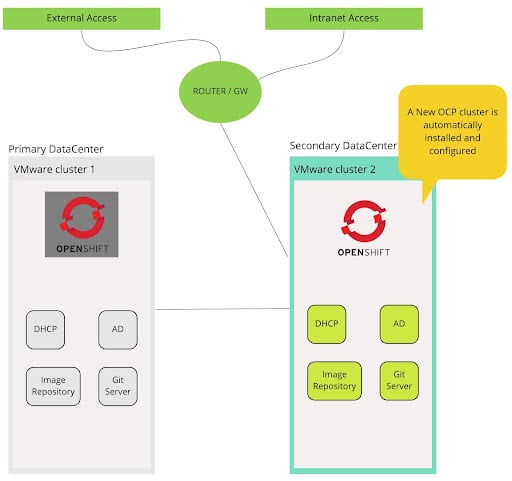
A new OpenShift cluster is created in the secondary datacenter. The connectivity change between the primary and secondary Datacenter is a manual operation, but it can be fully automated.
Speaking of OpenShift, we will take advantage of the powerful "Installer Provisioned Infrastructure" (IPI) method that will allow us, once everything is configured, to create our cluster with a single command. We will use ArgoCD to complete all the configurations when the cluster is operational.
Here is the summary of the customer's requests:
- Automatic Installation of an OCP cluster using the IPI method on a VMware cluster
- Automatic installation of Operators from different catalog sources Configuration of the operators’ custom resources
- Synchronization of LDAP users and groups
- Automatic Installation of an arbitrary number of applications using the GitOps approach
- SLA (service level agreement) <= 2 hours
- “Easy to run” procedure
Strategy
In the “Disaster Recovery Strategies for Applications Running on OpenShift” blog post written by Raffaele Spazzoli, disaster recovery strategies are grouped into two main categories :
-
Active/Passive: with this approach, under normal circumstances, all the traffic goes to one datacenter. The second datacenter is in a standby mode in case of a disaster. If a disaster occurs, it is assumed that there will be downtime in order to perform tasks needed to recover the service in the other datacenter.
-
Active/Active: with this approach, load is spread across all available datacenters. If a datacenter is lost due to a disaster, there can be an expectation that there is no impact to the services.
It is not possible for us to use the Active/Active or Active/Passive approach due to the before mentioned “same IP address” constraint.
In our strategy (also known as “cold start procedure”), after having isolated the primary datacenter at the network level (to avoid the IP addressing problems) the OCP cluster will be created and configured from scratch in the secondary datacenter.
OpenShift will be installed in disconnected mode (More on this later)
The cold start procedure for our OCP cluster is all about creating e configuring services and OCP resources. There is some pre-work to do, here is a summarized list:
- Create a bastion host for mirroring the OCP installation image to a private image registry already present in the infrastructure.
- Find the operator catalogs that include our operators, "prune it,” (remove all the unnecessary images), and mirror only the required operators images.
- Configure a Git repository for our ArgoCD applications
- Prepare all the YAML files that describe the resources we need like:
- Identity providers
- OperatorGroup
- Operator Subscriptions
- Main ArgoCD application
- MachineSets for Infra nodes
These steps are preparatory and must be performed on the primary datacenter. Once all the virtual machines (bastion, private image registry, etc ..) have been prepared, they will be cloned to the secondary datacenter in a power-off state (again for avoiding the IP address problem) using the underlying VMware infrastructure.
The following graph summarizes the logical flow overview of tasks that culminates with the IPI installation process. This also demonstrates how the OpenShift cluster installation can be enriched with preliminary and post-install customizations that can be fully automated.
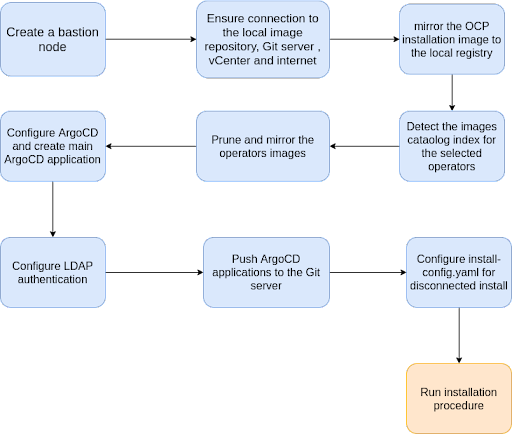
High level procedure schema
Let's dig a little deeper into the preparatory procedure.
OpenShift images mirror
Why do we need to mirror the OpenShift installation image registry?
Almost all the OCP infrastructure services run in containers and to run a container OCP must download the relative image.
In a standard OCP installation, the images are downloaded from the official OCP image repository hosted by Red Hat Quay
What if OCP couldn't reach quay.io for whatever reason? The installation will fail: that’s why we need to clone all the installation images to our local image repository. We will instruct the OCP installer to use our local image repository instead of quay.io.
The OpenShift installation images mirror process requires the following:
- User and password for accessing the local mirror registry
- The OpenShift installation pull secret
- The “oc” utility obtained from https://cloud.redhat.com
These are instructions taken from the official documentation.
- Create the base64-encoded version of the user and password for accessing the local mirror registry
$echo -n 'myuser:mypass' | base64 -w0
bXl1c2VyOm15cGFzcw==
- Add this login information to the original OpenShift pull secrets obtained from https://cloud.redhat.com/
For this example, the local mirror registry FQDN is “myregistry.mydomain.local” and the pull secret full path is “/home/ocp/pull-secret.json”
"auths": {
"myregistry.mydomain.local": {
"auth": "bXl1c2VyOm15cGFzcw==",
"email": "registry@myregistry.mydomain.local"
}
This edited pull secret must be added to the install-config.yaml file.
For convenience, let's value these environment variables:
| VARIABLE | DESCRIPTION | VALUE |
|---|---|---|
| OCP_RELEASE | The OCP version to mirror | 4.9.10 |
| LOCAL_REGISTRY | Local registry FQDN | myregistry.mydomain.local |
| LOCAL_REPOSITORY | Local registry repository | ocp4/openshift4 |
| PRODUCT_REPO | Fixed value | openshift-release-dev |
| LOCAL_SECRET_JSON | Full path to the edited pull secret | /home/ocp/pull-secret.json |
| RELEASE_NAME | Fixed value | ocp-release |
| ARCHITECTURE | CPU Architecture | x86_64 |
The “PRODUCT_REPO” var must have the value of “openshift-release-dev” (even if it sound strange), and the “RELEASE_NAME” must be equal to “ocp-release”
Now let’s run the image mirror on the bastion node:
oc adm release mirror -a ${LOCAL_SECRET_JSON} --from=quay.io/${PRODUCT_REPO}/${RELEASE_NAME}:${OCP_RELEASE}-${ARCHITECTURE} --to=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY} --to-release-image=${LOCAL_REGISTRY}/${LOCAL_REPOSITORY}:${OCP_RELEASE}-${ARCHITECTURE}
After the mirror is complete, save the section “imageContentSources” from the output and add it to the install-config.yaml
Example output from “oc adm release mirror”
imageContentSources:
- mirrors:
- myregistry.mydomain.local/ocp4/openshift4
source: quay.io/openshift-release-dev/ocp-release
- mirrors:
- myregistry.mydomain.local/ocp4/openshift4
source: quay.io/openshift-release-dev/ocp-v4.0-art-dev
The "imageContentSources" directive informs the installer to pull the installation images from our local mirror registry instead of quay.io
After the installation image mirror is completed, we can move on to mirror the needed Operator images.
Operators images mirror
OCP heavily relies on the concept of Operators and, the various components of an Operator run in a container. For the same reason explained in the previous section (to avoid failure due to an internet connectivity problem) we need to mirror all the images required by the Operators.
Mirroring a set of Operator’s images is not straightforward like mirroring the installation images because we need to know exactly what images to mirror for a certain operator.
Some Operators require a few images; others also require 20: we cannot manually select them one by one because it would be a very long job and above all to be updated continuously (updates are quite frequent ...)
Typically, In a connected OpenShift installation, we can easily install operators from four default catalog sources:

Catalog sources are just images containing a list of relevant operators.
For example, the “Red Hat” catalog source image lists only Operators created and maintained by Red Hat.
The “Certified” catalog source image list third-party Operators certified by Red Hat
(more information about how to gain the Red Hat Certification for Operators can be found here.),
In an air-gapped (disconnected) installation, we can not use these default catalogs because we must avoid external internet connectivity issues; instead, we have to create our custom catalog and finally mirror the images of the operators listed in our custom catalog.
The customer asked for a specific set of Operators:
| Operator | Provided by | Catalog source |
|---|---|---|
| OpenShift Logging | Red Hat | Red Hat (redhat-operators) |
| OpenShift Elasticsearch | Red Hat | Red Hat (redhat-operators) |
| OpenShift Jaeger | Red Hat | Red Hat (redhat-operators) |
| Kiali | Red Hat | Red Hat (redhat-operators) |
| Dynatrace | Dynatrace LLC | Marketplace (redhat-marketplace) |
| OpenShift Service Mesh | Red Hat | Red Hat (redhat-operators) |
| ArgoCD | Argo CD Community | Community (community-operators) |
How can we create our custom catalog starting from official catalogs?.
First of all, we need to select the catalog image we need. Just for reference, here are the lists of the four OpenShift official catalogs images name:
| Catalog | Catalog image url |
|---|---|
| redhat-operators | registry.redhat.io/redhat/redhat-operator-index:v4.9 |
| certified-operators | registry.redhat.io/redhat/certified-operator-index:v4.9 |
| redhat-marketplace | registry.redhat.io/redhat/redhat-marketplace-index:v4.9 |
| community-operators | registry.redhat.io/redhat/community-operator-index:latest |
The catalog image runs a gRPC server that we can interrogate for obtaining a list of Operators.
Let’s run one of the catalog images locally serving the gRPC server:
podman run -p50051:50051 -it registry.redhat.io/redhat/redhat-operator-index:v4.9
From another terminal, let’s ask the list of operators included in that catalog image using the grpcurl utility.
But, what is grpcurl used for?
Here the description taken from the grpcurl git repository:
“grpcurl is a command-line tool that lets you interact with gRPC servers. It's basically curl for gRPC servers.”
grpcurl -plaintext localhost:50051 api.Registry/ListPackages
Example output:
{
"name": "jaeger-product"
}
{
"name": "jws-operator"
}
{
"name": "kiali-ossm"
}
{
"name": "klusterlet-product"
}
{
"name": "kubernetes-nmstate-operator"
}
...
This list should be reduced in order to mirror only the images used by our selected operator: we don’t want to mirror all the operator’s catalogs and waste up to 1 TeraByte of disk space.
But how can we reduce the list of operators exposed by the catalog source image? We have to use another utility called “opm”.
Using the opm utility, we can now create our custom catalog image only for the operators we need:
For example, if we need the jaeger, kiali, and service-mesh operators:
opm index prune -f registry.redhat.io/redhat/redhat-operator-index:v4.9 -p jaeger-product,kiali-ossm,servicemeshoperator, -t myregistry.mydomain.local/myorganization/my-custom-catalog:v4.9
In this example, the opm tool creates a custom catalog image called “myregistry.mydomain.local/myorganization/my-custom-catalog:v4.9”.
The custom catalog must be uploaded to our local mirror registry.
podman push myregistry.mydomain.local/myorganization/my-custom-catalog:v4.9
Finally, let’s mirror all the images for our operators:
oc adm catalog mirror myregistry.mydomain.local/myorganization/my-custom-catalog:v4.9 myregistry.mydomain.local/my-operators-images -a ${LOCAL_SECRET_JSON}
--index-filter-by-os='linux/amd64'
After this operation, we will have our Operators’ images mirrored in our local image registry repository.
The “oc adm catalog mirror” creates two files:
- catalogSource.yaml
- imageContentSourcePolicy.yaml
The former describes our custom catalog source; the latter is the catalog content source for the images of our custom catalog. Therefore, we need to create these files after the cluster installation is completed.
How can inform OpenShift to use our local mirror image registry for installing the operators?
After the OpenShift cluster is up and running, we have to patch the “OperatorHub” custom resource called “cluster” for disabling the default (online) Operators images sources :
oc patch OperatorHub cluster --type json -p '[{"op": "add", "path": "/spec/disableAllDefaultSources", "value": true}]'
After that, we need to apply the two files created by the “oc adm catalog mirror” command previously performed.
We have done with the mirroring! Let’s take a look at adding nodes to the OCP cluster.
Adding Infrastructure nodes
When using the IPI installation method, the OCP cluster will be created with three control-plane nodes and three worker nodes.
Thanks to the machineSet OCP resource, we can easily scale our worker nodes but what if we need to create a new machineSet for infrastructure nodes in an automated way, and why do we need those Infrastructure nodes?
We need the Infrastructure nodes for two main reasons:
- Red Hat subscription vCPU counts omit any vCPU reported by a node labeled node-role.kubernetes.io/infra: ""
- Run some workloads on these nodes such as the ingress controller, OpenShift registry, etc ... freeing resources from worker nodes
How Infrastructure nodes can be created in an automated way?
One way is to export and filter the existing worker node machineSet, update at least the labels for the name and role and apply this information to the cluster.
As an example, the infrastructure nodes machineSet can be created with this script:
MACHINESET_NAME=$(oc get machineset -n openshift-machine-api -o jsonpath="{.items[0].metadata.name}{'infra'}")
oc get machineset -n openshift-machine-api -o json\
| jq '.items[0]'\
| jq '.metadata.name=env["MACHINESET_NAME"]'\
| jq '.spec.selector.matchLabels."machine.openshift.io/cluster-api-machineset"=env["MACHINESET_NAME"]'\
| jq '.spec.template.metadata.labels."machine.openshift.io/cluster-api-machineset"=env["MACHINESET_NAME"]'\
| jq '.spec.template.spec.metadata.labels."node-role.kubernetes.io/infra"=""'\
| jq 'del (.metadata.annotations)'\
| jq 'del (.metadata.managedFields)'\
| jq 'del (.metadata.creationTimestamp)'\
| jq 'del (.metadata.generation)'\
| jq 'del (.metadata.resourceVersion)'\
| jq 'del (.metadata.selfLink)'\
| jq 'del (.metadata.uid)'\
| jq 'del (.status)'\
| jq '.spec.replicas=3'\
| jq -r '.spec.template.spec.providerSpec.value.numCPUs=2'\
| jq -r '.spec.template.spec.providerSpec.value.memoryMiB=16384'\
| oc create -f -
ArgoCD configuration
Once the cluster is up and running, all the remaining resources should be created using the GitOps approach: the Git server will be our source of truth, every YAML resource present in our Git repository will be created in the OCP cluster thanks to ArgoCD. This is so far the best and simple method and that’s why ArgoCD is the most popular tool for this kind of scenario.
To follow this approach we need to configure just one ArgoCD application following the “app of apps” pattern.
https://argo-cd.readthedocs.io/en/stable/operator-manual/cluster-bootstrapping/
Once ArgoCD is configured, we need to push our configurations and applications resources to the Git repo. ArgoCD will create all the resources for us.
In OpenShift we can use the ArgoCD power by installing the officially supported Red Hat GitOps Operator.
Ready, set, go
Finally, with everything configured, we need to create, for example, an Ansible playbook that executes these instructions:
- Create a cluster using the openshift-installer and the pre-configured install-config-yaml
- Create the resources from the “Operators image mirror”:
- catalogSource.yaml
- imageContentSourcePolicy.yaml
- Create the infra nodes
- Create the main ArgoCD application that deploys all other applications/resources from the Git server like:
- LDAP identity provider
- Group sync configuration
- Applications
- OperatorGroup and Subscriptions
- ...
The bastion VM can now be cloned ad copied (like all other services VM) to the secondary datacenter. In the case of DR, we need to power on the bastion host and run the Ansible playbook (after all the services VM are up and running).
An example of further automation is to create a systemd service that starts the installation Ansible playbook, after the bastion node has started successfully.
The tests carried out show an average time of 40 minutes to create a cluster of 9 nodes (3 control-plane, three infra, and three workers), to install eight operators and two applications.
The OpenShift installer is all about automation; it greatly simplifies the installation procedure. All typical "day 2" operations can be done declaratively using YAML file resources.
Thanks for reading!
Valentino Uberti vuberti@redhat.com
Reference:
- OCP IPI disconnected on VMware vSphere
- Mirroring images for a disconnected installation
- Mirroring the Operator catalogs
About the author

More like this
Stop managing the past and start building IT’s future
The agentic paradox and the case for hybrid AI
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds