
Red Hat OpenShift has enabled enterprise developers to utilize a fast feedback loop during the development phase of platforms and applications. The idea of ‘as-a-service’ has arisen from the ability of cloud providers to offer an on demand capability to consume services and products. This increased flexibility for organisations can further ease the development path to production.
Kubernetes and Red Hat OpenShift unlocks organisations to achieve freedom with platforms of choice on a number of cloud providers without lock-in as workloads are abstracted from vendor specific constructs. Kubernetes, and Red Hat OpenShift Container Platform, provide the ability to run operators, where operators can act as an organisation’s very own consumable on demand service whilst providing a unique user experience to its intended audience.
As a developer having a personal on demand environment was once one of the reasons for the rise of “shadow IT”. Organisations have since moved from the days of having to build servers for additional workloads through the use of new models of IT services thanks to virtualisation, PaaS and public/private cloud in an effort to adopt the on-demand/as-a-service utopia and enable their consumers to have the freedom to develop and produce strong value proposition products in today's competitive market.
OpenShift has become the platform of choice for many organisations. However, this can mean developers are somewhat restricted in consuming PaaS environment, due to greater process and management surrounding the environment, in accordance with internal IT regulations. OpenShift Hive is an operator which enables operations teams to easily provision new PaaS environments for developers improving productivity and reducing process burden due to internal IT regulations. Hive can do this in a true DevOps fashion while still adhering to an organization's regulations and security standards.
We will be exploring this operator in depth throughout this blog post getting familiar with its installation and uses to enable teams to achieve push-button personalised OpenShift clusters from a primary Hive enabled cluster.
Hive for Red Hat OpenShift Operator Overview
Hive provides API driven cluster provisioning, reshaping, deprovisioning and configuration at scale. Under the covers it leverages the OpenShift 4 installer to deploy a standardised operating environment for consumers to create a day 1 cluster with ease on a number of cloud provider platforms AWS, Azure, GCP.
There are 3 core components to Hive’s architecture. The operator itself, which acts as a deployer, manages configuration and ensures components are in a running state, handles reconciliation of CR’s (Custom Resources) and general Hive configuration. An admission controller, which acts as a control gate for CR webhook validation, and approves/denies requests to core CR’s. Finally, the Hive Controllers which reconcile all CR’s.
Hive Operating Architecture
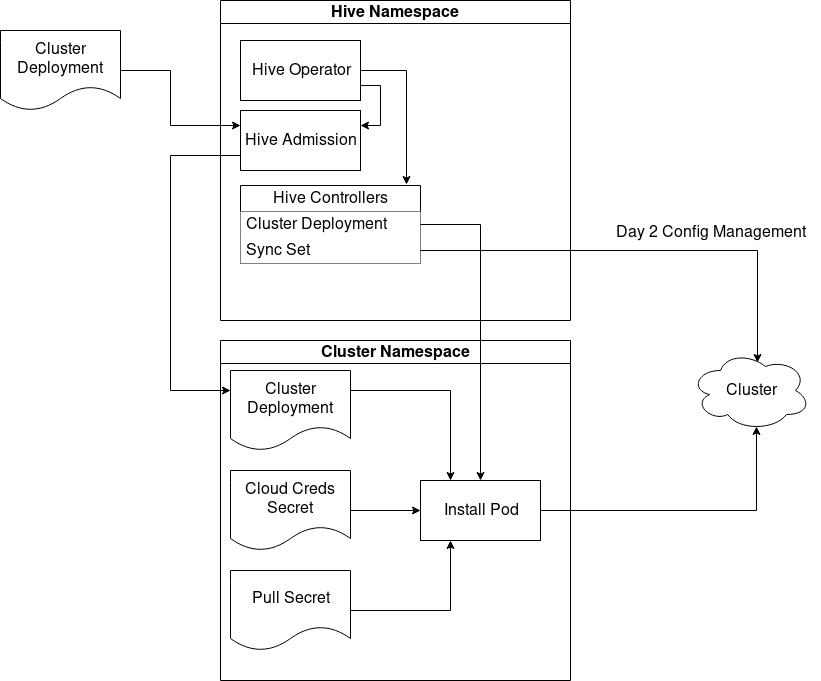
[1] - Architecture Diagram
{kind=link}
Hive utilizes a relatively simple process. API callers create a ClusterDeployment which contains a definition for the state of the cluster whose creation is desired. Hive is designed to work in a multi-tenant environment, therefore secrets and ClusterDeployments can be run in a separate namespace.
Hive generates ClusterDeployment’s through its command line utility hiveutil. These objects can be viewed in both yaml and json. Created objects describe the state of cluster to be generated with options to choose release image, DNS, SSH parameters and many other configuration parameters through hiveutil’s extensive command line flags.
Once configuration of the ClusterDeployment definition is completed and approved, Hive launches an install pod. The install pod is made up of multiple containers, which are used to download and copy the user defined release image and oc binaries. Hive then copies the installer binary to the Hive sidecar and executes the installation. Following the installation, admin passwords and kubeconfig are created as secrets and can be obtained from the CLI for easy access.
If a cluster deployment fails, Hive attempts to clean up cloud resources and retry indefinitely (with backoff). When a cluster is ready to be deleted, Hive invokes a deletion job and deprovisions all cloud resources based on the infraID tag, using the openshift-install deprovision commands.
How To Use OpenShift Hive
The easiest way to install Hive is by using the OpenShift OperatorHub. Hive can also be built from source and installed using `make deploy`, which is covered in the github documentation. In this article, I will build and install Hive from source. From your control/bastion node, there are a set of core dependencies which should be installed and resolved prior to deploying Hive. This includes but not limited to the following: Go, OC, Kustomize and MockGen. Most dependencies can be installed via yum or go get pathways. *Ensure to set $GOPATH to your project directory. A useful command to view your go environment variables is: go envas is go get -d ./…, which uses a special pattern to recursively search and resolve go-gettable dependencies in the project.
Once dependencies have been met, it’s time to install the Hive operator. In this guide, I installed Hive from the github repository using the latest master images to ensure I had the most recent capabilities and features.
Installation process
As a privileged user on an OpenShift cluster or OpenShift SDK/MiniShift, we will create a new project. The architecture described above uses a multi-tenant model, keeping the operator and its core resources in a separate project can be seen as good practice. Follow the steps below to install and deploy a Hive operator in its own namespace.
oc new-project hive
git clone https://github.com/openshift/hive.git
cd hive
make deploy
If you have correctly installed all the required dependencies and ensured the gopaths point to the appropriate places, the Hive operator should now be running it’s installation process. To verify this, the following command should provide some context and ensure resources have been or are in the process of being created.
oc get pods -n hive
NAME READY STATUS RESTARTS AGE
hive-controllers-xxxxxxxxxx-xxxxx 1/1 Running 0 1m
hive-operator-xxxxxxxxxx-xxxxx 1/1 Running 0 1m
hiveadmission-xxxxxxxxxx-xxxxx 1/1 Running 0 1m
hiveadmission-xxxxxxxxxx-xxxxx 1/1 Running 0 1m
Following the installation of the Hive operator, validate you have access to the hiveutil client commands. This will be the core way to interact with Hive for cluster deployments and generate the cluster config. If this is not the case, then run the following command from the projects directory:
make hiveutil
Creating OpenShift Clusters
If you’ve been able to follow this blog, you should have been able to deploy the Hive operator in its own namespace. At this point, we need to ensure our target cloud provider environment (AWS) has a valid Route 53 zone, which is standard practice in all OpenShift 4.x deployments.
Once the zone information has been confirmed, OpenShift will need a number of “secrets” made available to it either globally, per namespace or as environment variables; this will depend on the OpenShift architecture you or your organisation has chosen to use. First, we will want to create a file containing our docker registry pull secret (obtained from try.openshift.com). To ensure this pull secret is used for our cluster deployments, the file will be created in ~/.pull-secret.
Clusters created with OpenShift Hive do not have to be bound to the platform the job has been instantiated from. For example, deployments performed from a local minishift instance to either AWS, Azure, or GCP as a target provider.
During this blog post, the cloud provider for the deployment will be AWS. As such, Hive will need to be aware of AWS related credentials. To accomplish this, we will need to make sure we set our environment variables with credential information. This will allow Hive to inherit these during the cluster creation process. To check what environment variables have been set, use the env command or additionally, credentials can be defined in a file and specified at the time of cluster creation using --creds-file.
env
AWS_SECRET_ACCESS_KEY=blah-blah-secret-access-key-id-blah-blah
AWS_ACCESS_KEY_ID=blah-blah-secret-access-key-id-blah-blah
We now have created the core secrets OpenShift and Hive needs for the deployment. To generate a cluster using the hiveutil CLI, we can run the following command:
bin/hiveutil create-cluster --base-domain=mydomain.example.com --cloud=aws mycluster
What hiveutil does under the covers is makes use of a template file, which has prepopulated options configured and leaning heavily on env vars been defined for example cloud provider credentials. If this isn’t done, many of the options will default to machine defaults or template defaults, e.g. default SSH key or OpenShift image version. The previous create-cluster command will inherit secrets created earlier including desired credentials and pull secrets. If all required fields are satisfied, hiveutill will proceed to generate a deployer pod and create an OpenShift cluster. But what if we wanted to be more granular when creating an OpenShift cluster?
We could explicitly provide parameters based on command line flags available to hiveutil. For example:
bin/hiveutil create-cluster --base-domain=mydomain.example.com --cloud=aws --release-image=registry.svc.ci.openshift.org/origin/release:x.x --workers=1 --ssh-public-key=examplesshstring --uninstall-once=false --ssh-private-key-file=blah mycluster
As you can see, this can become quite cumbersome and difficult to manage with only a small set of configuration parameters defined.
A more manageable option would be to generate a static file and configure the desired specification before initiating a cluster deployment. As with all things OpenShift, we can view the ClusterDeployment in yaml and save the output to a file, if desired, enabling users to validate the configuration.
bin/hiveutil create-cluster --base-domain=mydomain.example.com --cloud=aws mycluster -o yaml > clusterdeployment-01.yaml
This gives an admin the ability to define their ClusterDeployment definition in a yaml text file before running a native oc apply, seen below, to create the objects specified. In this document, under the provisioning header is an example of what we might expect to see in a default cluster definition with minimal user configuration applied.
oc apply -f clusterdeployment-01.yaml
Up to this point, we have been able to quickly define what a desirable OpenShift cluster looks like through the creation of secrets and ClusterDeployment objects in OpenShift using a native oc apply command.
As Hive attempts to deploy a new cluster, an installer pod will be created consisting of multiple containers, during which the management sidecar container will copy the installer binary from the containers in the pod. Next, it shall invoke the OpenShift installer inheriting variables and secrets defined during the previously completed process.
We can easily create another cluster with a different set of parameters by duplicating or recreating the ClusterDeployment file, updating cluster name and desired parameters such as instance types. Once completed, all that is left to do trigger a deployment using oc commands; for example:
oc apply -f clusterdeployment-02.yaml
As with a native install, we can tail logs and get a view of what the installer is doing using oc commands as follows:
oc get pods -o json --selector job-name==${CLUSTER_NAME}-install | jq -r '.items | .[].metadata.name'
oc logs -f <install-pod-name> -c hive
oc exec -c hive <install-pod-name> -- tail -f /tmp/openshift-install-console.log
Once the OpenShift cluster has been installed as indicated in the logs, secrets will be created for kubeadmin password. These will be required for command line access or accessing the web console. We can retrieve the secrets and web console url using the following:
oc get cd ${CLUSTER_NAME} -o jsonpath='{ .status.webConsoleURL }'
oc get secret `oc get cd ${CLUSTER_NAME} -o jsonpath='{ .status.adminPasswordSecret.name }'` -o jsonpath='{ .data.password }' | base64 --decode
For users more fluent with Hive and it’s functionality, the admin kubeconfig is available as a secret post cluster creation. This is able to be retrieved using the following command:
oc get secret -n hive xyz-xyz-xyz-admin-kubeconfig -o json | jq ".data.kubeconfig" -r | base64 -d > cluster.kubeconfig
When deleting the cluster, we can simply invoke the openshift-install job through hiveutil, which deploys a deprovisioning pod and destroys all cluster resources based on InfraID tags using:
oc delete clusterdeployment ${CLUSTER_NAME} --wait=false
OpenShift Hive Extending Its Useability Through Templates
Using Hive, we can create clusters through hiveutil create-cluster commands or using native oc commands with oc apply -f clusterDeployment.yaml. Each method is unique in itself, hiveutil leverages command line flags for parameter updates, while oc apply allows us to append key value pairs in a ClusterDeployment file.
This can still be viewed as a time consuming process to a developer or DevOps engineer who has to recreate ClusterDeployment yaml definitions without having a repeatable mechanism to quickly deploy clusters at scale.
To extend the functionality of clusters-as-a-service, I had the idea to introduce user templating. OpenShift already makes use of environment variables to attain values set by users. Therefore, a command such as oc process can allow for a cleaner clusters-as-code approach using cluster definitions files as templates, which can be harvested and made use of in a repeatable and malleable fashion.
Sticking with a similar change in the ClusterDeployment, we can simply parameterise the number of worker nodes, instance sizes, and cluster name. Below are the variables I want my ClusterDeployment to inherit.
$ cat cluster-deployment.params
CLUSTER_NAME=gallifrey
WORKER_COUNT=1
INSTANCE_TYPE=m4.xlarge
BASE_DOMAIN=example.cloud
The stub of code shown below is a snippet of a ClusterDeployment template file which has been parameterised to inherit the variables defined in a cluster-deployment.params file or from environment variables. Now we can provide a ClusterDeployment template the desired variables file and validate that parameterisation has had the desired outcome using the oc process command.
A bit more on oc process. oc process makes use of OpenShift template files and its supplementary parameters files. OpenShift Hive for its deployment uses a template file to create objects and populates the ClusterDeployment using environment variables if no alternatives have been specified on the command line it can fall back on defaults specified in the template itself.
Linked is a Hive template file. The parameters component of the template will be where user configuration will substitute template defaults. If defaults are defined (e.g. OpenShift version) and not overridden at the points described earlier, these will become fallback options for the template file. We can toggle and append to be more or less opinionated based on the desired approach taken. The rest of the template file is a highly parameterised version of that which is generated from the oc apply seen earlier, a link to the default template github file is here.
For the purposes of this blog I will pre-populate a number of fields in the template, so we can focus on a select few to showcase a cluster-as-a-service development model. Those fields which we will want to parameterise have previously been defined and used in this blog: name, domain,workers and instance type.
By using both a ClusterDeployment template and a populated parameters file with oc process, the notion of clusters as a service becomes a reality. Below is a snippet of pre/post templated files following the oc process command.
- apiVersion: hive.openshift.io/v1alpha1
kind: ClusterDeployment
metadata:
creationTimestamp: null
name: ${CLUSTER_NAME}
spec:
baseDomain: ${BASE_DOMAIN}
clusterName: ${CLUSTER_NAME}
compute:
- name: worker
platform:
aws:
rootVolume:
iops: 100
size: 22
type: gp2
type: m4.large
replicas: ${WORKER_COUNT}
- apiVersion: hive.openshift.io/v1alpha1
kind: ClusterDeployment
metadata:
creationTimestamp: null
name: gallifrey
spec:
baseDomain: example.cloud
clusterName: gallifrey
compute:
- name: worker
platform:
aws:
rootVolume:
iops: 100
size: 22
type: gp2
type: m4.large
replicas: 1
A final step following the processing of a template is the creation of the object itself.
oc process -f clusterdeployment-template.yaml --params-file=clusterdeploy.params | oc apply -f-
This will apply and create the objects templated using oc process. A deployer pod, is created and builds an OpenShift cluster to the desired specification. Through oc process and a parameters file, we can increase the speed of delivery in the creation of OpenShift clusters, whilst adopting a self service model when deploying from namespaces with RBAC applied. Defining a distinct parameter hierarchy would further enhance the speed of cluster development, where variables can be enforced at a cluster or project level, providing a developer the minimal options needing configuration to build clusters specific to their use case.
oc process -f clusterdeployment-template.yaml --params-file=openshift-app1/clusterdeploy.params | oc apply -f-
Conclusion
To conclude, in this blog post we install and use OpenShift’s Hive operator. During installation we resolved dependencies to enable operator functionality. Upon this, we have been able to build, destroy and reshape OpenShift clusters on demand.
The aim of this blog post was to deliver an insight and hands-on look into clusters-as-a-service through OpenShift’s Hive operator. Through using a number of deployment mechanisms including hiveutil or native OpenShift commands like oc apply and oc process. We have further seen its practicality extended when combined with a template file. This allows for fast processing and reduction in time taken to create clusters. For more information go to the OpenShift Hive github repository, where you can find all the resources needed to follow along and try it for yourself.
To extend the use of Hive even further, we can introduce an automation pipeline. This would be pivotal for developers who do not have direct access to clusters or where the creation of user generated ClusterDeployment files would not be an acceptable practice. We can achieve this through the use of git hooks and declarative pipelines, invoking the creation of OpenShift clusters based on updates to files in an organisations source control.
An addition to automation pipelines described above is automated testing. Where upon the success of pipeline automation, organisations can promote changes to different projects in true gitops fashion, whilst in failure cases, errors can be addressed and remediated. This provides auditability and accountability for consumers of Hive’s functions, aligning with enterprise ways of working. This will be visited in a follow up article in the future, exploring how we can integrate and extend Hive’s functionality in a gitops fashion.
About the author
More like this
Why Red Hat partners are the ultimate telco business asset
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds