
OpenShift sandboxed containers provide a way to better isolate workloads running in pods in an OpenShift cluster by running pods in dedicated lightweight virtual machines. It utilizes Kata Containers 2.0 as its OCI runtime. One consideration when doing so is the performance of sandboxed containers versus containers running in the node's native Linux context. This is the first in a series of technical deep dives by members of the Red Hat performance organization on our findings.
In this blog, I will be focusing on networking performance with sandboxed pods compared with that of conventional pods, along with a brief discussion of the CPU overhead involved. I will also discuss ways by which the user and system administrator can improve the network performance.
I'm going to start with a summary of my findings, including high-level performance information and what you can do to improve network performance with sandboxed containers. The remainder of this blog will consist of the details.
Summary
Out of the box, sandboxed pods have limits to networking performance that go beyond simple virtualization overhead, resulting in increased latency and reduced bandwidth compared to non-sandboxed pods. The penalty varies (I will present basic data at the end of this summary), but with default settings and single stream data transfer, it is typically in the range of 20% to 50%. The limiting factors include:
- Availability of CPU resources to the guest
- Limited hypervisor kernel threads (vhost) to perform network operations on behalf of the guest
- CPU resource limits declared by the pod's containers that apply to the vhost threads in addition to the VM and its vhost helper threads
- Longer data path due to the additional (virtual) network hop
- Greater CPU utilization
There is not much that we can do about the fact that the data path is longer. And while we can get improvements, they come at a cost in CPU overhead; for example, in some cases, I observed a factor of 2.5x difference in CPU usage.
Availability of CPU resources
By default, a sandbox VM gets a single core that is shared between the pod's payload, the guest kernel, and other operating system services in the guest. We can increase the size of the VM by counterintuitively setting a CPU resource limit for the pod's containers (Yes, limiting the amount of CPU a sandboxed pod can consume gives it access to more CPUs.). If a CPU resource limit of two cores is set, the pod's VM will receive a total of three cores, although the pod, including its vhost helpers, can only use two. This is the most straightforward (and the supported) way to increase the CPU power available. This approach is useful for heavily threaded workloads that are not very demanding of network bandwidth. But if you are reading this, you are likely interested in network bandwidth.
Limited hypervisor network threads
If your workload makes heavy demands on network bandwidth, particularly if it is multithreaded or multiprocess, simply increasing the CPU limit will not help you, because all the network traffic will be forced through a single thread. Fortunately, it is possible to increase the number of network threads for a sandbox, and the same method will also increase the number of CPUs allocated to the guest VM without requiring the use of a CPU limit.
By means of applying an annotation to your pod, it is possible to request a larger number of CPUs and network threads. That annotation, which is not supported at the time of this writing, is io.katacontainers.config.hypervisor.default_vcpus (which I abbreviate as default_vcpus for the remainder of the blog), and is declared in the metadata section of the pod YAML. It is specified as a string, with a value of at least one and less than the number of CPU threads on the node. You might also want to increase the pod's memory (in MiB) while you are at it if your VM is going to be very large.
apiVersion: v1
kind: Pod
metadata:
annotations:
io.katacontainers.config.hypervisor.default_vcpus: "4"
io.katacontainers.config.hypervisor.default_memory: "8192"
This has the happy side effect of increasing the number of vhost threads. That number will always be the same as the value of default_vcpus. You may find a benefit in setting this up to the degree of multithreading of your workload. Setting it higher than that, however, may increase contention and CPU utilization without yielding better throughput.
So what about using both a CPU limit and the default_vcpus annotation? Well, that really is not a good idea at all. Yes, you will have an even bigger VM, but the CPU limit will restrict you such that you will not be able to use all of those CPUs. Worse yet:
CPU resource limits apply to I/O helpers, too
CPU (and other) resource limits on Linux are enforced by means of cgroups; all processes and threads placed within a cgroup can be limited in their CPU consumption even if there is more CPU available. Increasing default_vcpus gives you more I/O threads, which will be competing against each other in addition to your sandbox hypervisor and VM, and in almost all the cases I have explored, has reduced performance, often by a lot.
So the bottom line is, use the default_vcpus pod annotation or a CPU resource limit, but not both.
Performance basics
To illustrate the above points, I am going to present two sets of data here: throughput using 4096 byte messages and latency using 16 byte messages. The cell values are geometric means (in Gb/sec and usec respectively) of my performance measurements on sandboxed containers with default_vcpus values and both sandboxed and non-sandboxed containers with different CPU limits. The row titled "Sandboxed default_vcpus: all" refers to default_vcpus set to the number of CPUs on the node itself. The "avg all default_vcpus counts" refers to the geometric mean of all tested default_vcpus values. The heat map colors are referenced to the non-sandboxed values.
Looking at the bandwidth chart, we see that with a CPU limit set, performance generally degrades as the default_vcpus value is increased (with a few exceptions, most notably with a limit of eight and default_vcpus value of two). However, with no CPU limit, performance improves with a larger value of default_vcpus. It does not improve beyond a value of two, because by that point, we are already matching the non-sandboxed performance. This illustrates the guidance above: do not use both the default_vcpus annotation and a CPU limit.
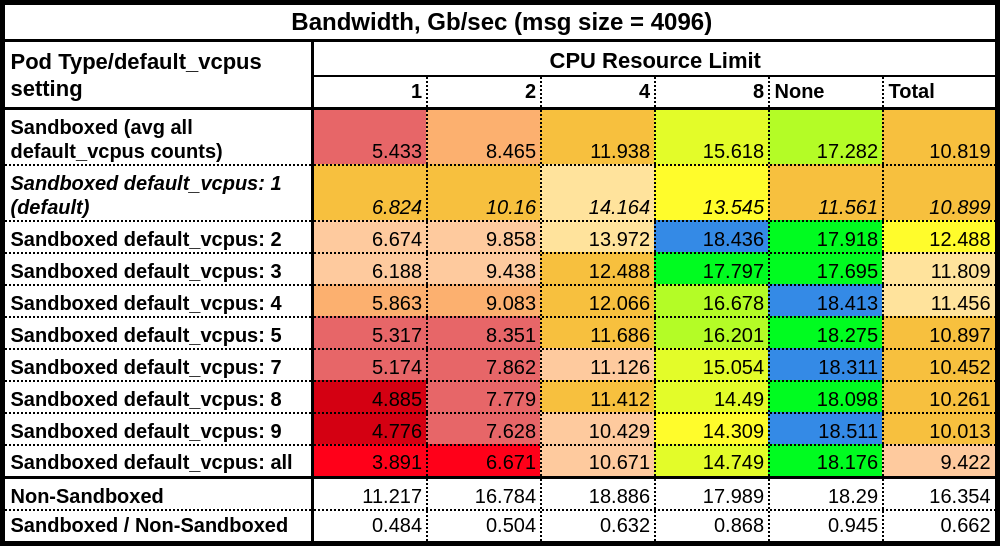
With latency, we observe essentially the same behavior: increasing default_vcpus improves performance only if there is no CPU resource limit set. If there is a limit set, particularly if the limit is low, performance degrades.

The remainder of this post discusses the test procedure in depth, with much more detailed results and analysis.
Test procedure
I performed this testing using OpenShift 4.8.0, the tech preview release of OpenShift sandboxed containers, using uperf with one worker pod per node. I used Pbench for data collection.
This work was performed on a cluster consisting of three master nodes and two workers. All nodes had the following configuration:
| Server Model: | Dell PowerEdge R740xd |
| CPU: | Intel(R) Xeon(R) Gold 6130 CPU @ 2.10GHz 2 sockets * 16 cores/socket = 32 cores, 64 threads |
| Memory: | 192G, 2666 MHz, Quad channel, 2 installed DIMMs/channel |
| Network Interface Card (NIC): | Intel XXV710, 25 Gb/sec |
| OpenShift version | Client Version: 4.8.0 Server Version: 4.8.0 |
| Kata Containers version | kata-runtime-2.1.0-4 |
I used the quay.io/rkrawitz/bench-army-knife:latest container image, based on CentOS 8.2.2004 with the 4.18.0-193.24.1.el8_2.dt1.x86_64 kernel. This image includes uperf-1.0.7-1.el8 with pbench 0.69.3.
For each test case outlined below, I ran a single iteration for 120 seconds. Experiments have shown that startup effects are negligible with this test and that behavior remains steady and consistent throughout the run. The Pbench default of 5 iterations of 60 seconds would have required prohibitive time.
I ran tests with the cross product of the following combinations:
- Measurements: bandwidth, latency/transactions per second
- Connections per pod: 1, 4, 16
- Message size: 16, 256, 4096, 65536 bytes
- CPU limit/request per pod: none, 1, 2, 4, 8 (requests = limits)
- Pod Technology: sandboxed, non-sandboxed
- Normally in OpenShift each pod gets its own network address via a software defined network (SDN). This allows pods to manage their networking without interfering with the host node.
- default_vcpus: 1, 2, 3, 4, 5, 7, 8, 9, 80
- The largest legal value is the number of physical CPUs.
- The run with default_vcpus=6 failed for unrelated reasons, and I had enough data to not rerun it.
On Sandbox VM SizingThe issue of sandbox VM sizing deserves further discussion, as there is an important difference in behavior between sandboxed pods and conventional pods with respect to the handling of CPU requests and limits. A general description of compute resources for Kubernetes, including OpenShift, may be found here. While conventional pods may take advantage of all available CPUs on the node, sandboxed pods are limited by the number of virtual CPUs in the virtual machine. Consequently, conventional pods may receive any amount of CPU up to their CPU resource limit (subject to other users of the system), whereas sandboxed pods will never receive more than the number of virtual CPUs (vCPUs) in the guest, which is determined from the rounded-up number of cores of their CPU resource limit (counter-intuitively, not the CPU resource request). If a sandboxed pod specifies no CPU limit, it will not normally receive more than one core. Viewed another way, the default CPU limit for a sandboxed pod is 1 core, while the default CPU limit for a conventional pod is unset (subject to other administrative controls). By default, for a sandboxed pod with no limit specified for CPU, the sandbox VM is allocated 1 vCPU and 2 GB RAM. Again, any resource request is disregarded for the purpose of sizing the VM; only the resource limit affects the VM size. If a pod specifies a CPU limit (or rather, its containers specify limits), an additional 0.25 core is added to the limit to allow for some overhead. The processes subject to the limit include the guest VM's hypervisor (including the VM) and any other I/O helpers that are required. The I/O helper for networking is called vhost; the helper for file system services is called virtiofsd. The VM itself receives additional hot plugged CPUs equal to the CPU limit and additional memory equal to the memory limit. So if the pod specifies a CPU limit of 2500 millicores (2.5 cores), that 2.5 is rounded up to 3, and 1 core is initially given to the VM for system use, then the VM will boot with one core and have 4 cores while running the container. The pod, however, will not receive more than its 2.5 (actually 2.75, as explained above) CPU limit. Similarly, if the pod specifies a memory limit of 8 GiB, the VM will receive 10 GiB (2 GiB plus the memory limit). There is another way to change the number of CPUs and amount of memory allocated at boot to a pod, through pod annotation. The io.katacontainers.config.hypervisor.default_vcpus annotation allows specifying the number of CPUs desired at boot. The io.katacontainers.config.hypervisor.default_memory annotation allows specifying the amount of memory (in MiB) desired at boot. Note that use of pod annotations for this purpose is not supported as of the time of this writing (OpenShift 4.8). apiVersion: v1
The value of default_vcpus can be anything from one to the number of physical CPUs on the node. Any additional vCPUs requested via the pod limit are then added via the hot plug. So if default_vcpus is set to three, and the pod's CPU limit is four cores, the VM will in fact receive seven cores, but the pod's limit will still be four. The behavior of default_memory is similar. However, note with memory that if your pod, including its helpers, attempts to exceed the memory limit, then it will be killed on the host, whereas a pod that attempts to exceed its CPU limit will simply be throttled. There is another aspect of this setting that was found to be very important for networking: The sandbox receives one vhost process for each boot-time thread, but not for hot plugged threads. This is a known issue. Thus, it is only possible to increase the number of vhost processes by increasing default_vcpus, so if you determine that you need more network performance, you should use annotations to increase your VM size. Setting this default higher may (or may not) improve pod performance. Here are some examples of the number of cores a VM will receive:
|
Tooling
Pbench is a harness that allows data collection from a variety of tools while running a benchmark and is open source software created by the Red Hat performance organization. It uses agents running on the systems under measurement to collect this data. I chose to use Pbench for data collection rather than the built-in Prometheus metrics for two reasons:
- The Kata runtime at the time I performed this work does not support metrics collection. This support is being worked on at the time of this writing.
- Pbench generates data in a form that is very easy to analyze offline. It generates a tarball of all of the collected data, including benchmark results, and that can be moved to an external server and either downloaded or analyzed in-place offline.
My solution was to build a containerized deployment for Pbench that could be run alongside the benchmark workload. Pbench at the time was not designed to run in dynamic containerized environments, but there was no real barrier to it doing so; the necessary elements were not connected yet. I named the tooling I created for this purpose bench-army-knife, and I plan to describe it in more detail in a separate blog. For the second matter, I created tooling to generate graphs en masse from the data files produced by Pbench, which work I have contributed back to Pbench. This, too, I plan to describe in more detail separately.
Test results
Result summary
In most cases, I observed, as expected, that conventional pods outperformed sandboxed pods, albeit with considerable variation. I have summarized this in charts after each section (bandwidth and latency), as interpreting those charts will require understanding a lot of concepts that I will develop through this blog.
We are going to cover a number of different cases here to illustrate different findings, and with each case, we are going to dig into some data. So get settled into a comfortable chair with your favorite water bottle, and let's get started.
Note that while the CPU utilization plots show only one side of the connection, I have in all cases picked the side showing the greater usage. Since you are likely interested in improving networking performance, it is most useful to find the bottlenecks, and the side of the connection using the most CPU is generally going to be what restricts the performance. Note that the CPU consumption can differ depending upon whether your pod is mostly sending or receiving traffic, so if you are doing point-to-point bandwidth measurements, you should observe CPU consumption using Prometheus on both sides.
Single stream bandwidth
We are first going to investigate what happens with single data streams with varying message sizes and different CPU limits. For large messages, even with a single stream, we see conventional pods getting reasonably close to line speed. Sandboxed containers performed reasonably well at 4K message size in this test, but for small and for very large messages, they lag their conventional counterparts by typically 30% to 50%.
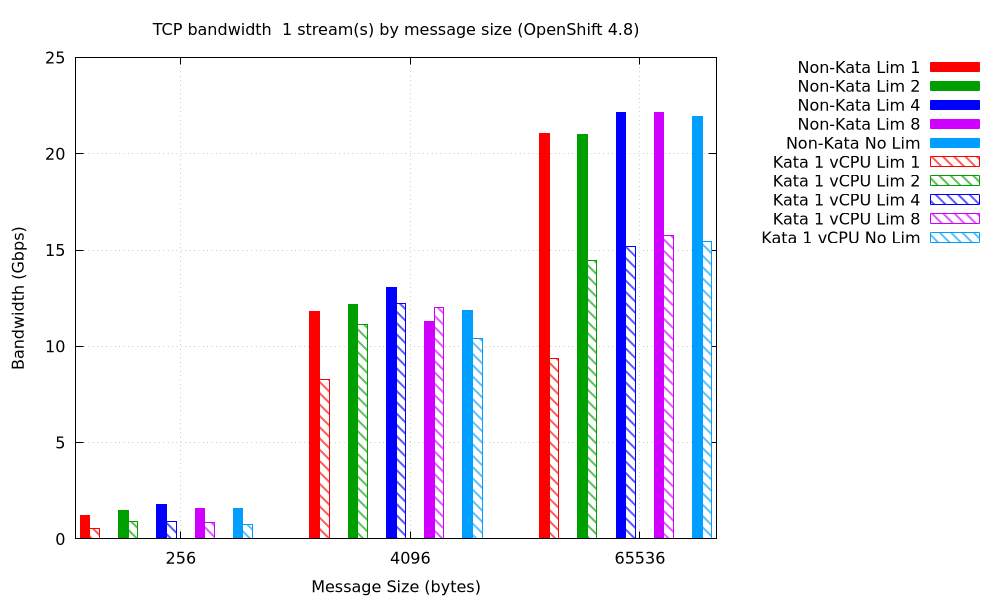
This raises some interesting points:
- If we were limited by guest CPU resources, we would expect to see performance improve with a larger CPU limit, which also means a larger guest and that a pod with no CPU limit (and therefore only one CPU, as discussed above) would yield the worst performance. While we do see significant improvement going from a limit of one to a limit of two, we see that the case with no CPU resource limit actually performs relatively well, so that does not appear to be the problem.
- If we were limited by the bandwidth of the one vhost process, we would expect to see steady performance regardless of the CPU limit.
What we actually observe is something different: steady performance for no limit or a limit of two or greater, but worse performance for a CPU limit of one core. That suggests that the CPU limit is kicking in when the limit is only one core, but with a larger limit, or no limit at all, something else is the limiting factor. Let's start looking at some traces from the low-performing case.
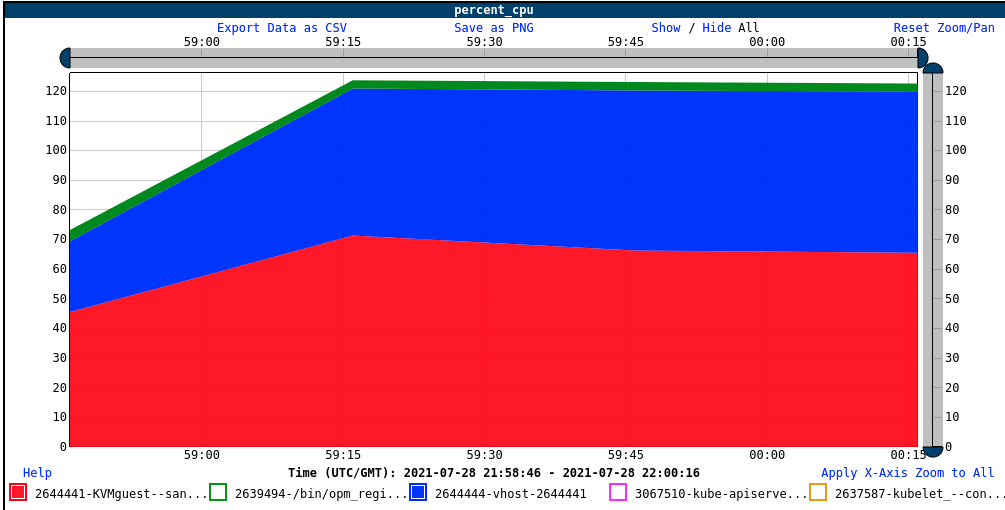
If we look at CPU consumption inside the guest, which requires special tooling I created for this occasion, we see that the guest is actually using very little CPU, about 30% of one core despite having two cores available.

But if we look on the host side, we see that between the KVMguest (the hypervisor running the guest VM), the vhost, and one other process in the same cgroup (virtiofsd, which is the filesystem helper), we are consuming a little bit over 1.2 cores (1.23, to be more exact). Note that the KVMguest consumes more CPU than the CPU consumption reported inside the guest, although still nowhere near 1 core. Based on some additional tracing, we suspect that some of that CPU time is spent spinning in the hypervisor waiting for I/O operations to complete, but we have not tracked this down for certain. In any event, 1.23 is very close to the imposed limit of 1.25 cores, so in fact in this case, we are capped by the cgroup CPU limit:
Let's look at the same graphs for no CPU limit at all. Inside the guest, we have only one core, which is running at about 60% utilization. That is about twice the CPU of the one-core limit case, and we are not actually getting twice the bandwidth, but we are doing quite a bit better. Even so, we are not limited by the one core.
So what's happening on the host? The KVM guest is consuming close to its full core, but the vhost helper is now consuming about 85% of a core. That certainly looks like a possible culprit in that scenario.
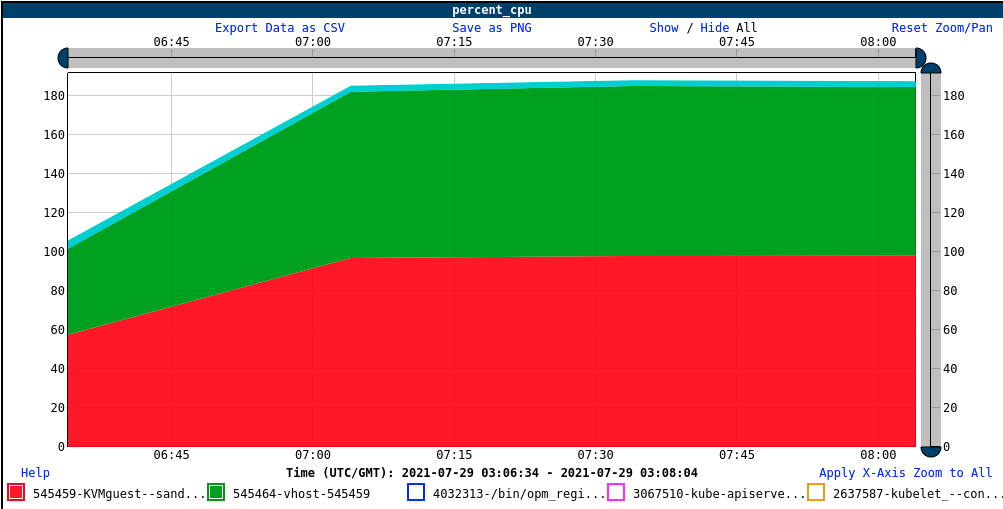
85% is not 100%, but we have only a single worker thread, so there is likely some idle time in vhost while waiting for the next request. It looks like there is a pretty good chance that this is the limiting factor, and we have not found anything obvious that is a tighter bound. Let us look at some other cases to see what happens.
Multistream Bandwidth
When the limiting factor for bandwidth is the fact that we have a single stream, we might be able to improve it by using more workers. Perhaps four workers will do the job?
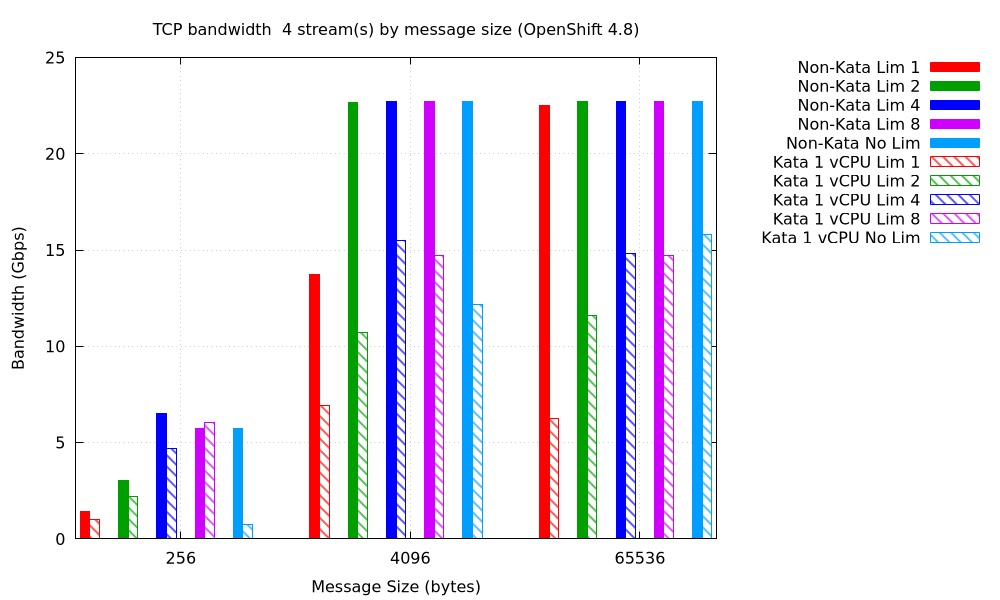
Alas, no, and, indeed, for a limit of one or two cores, performance is actually worse. That suggests we are hitting the CPU limit even harder, but we would expect that we might be able to do better with a high CPU limit. But we are not.
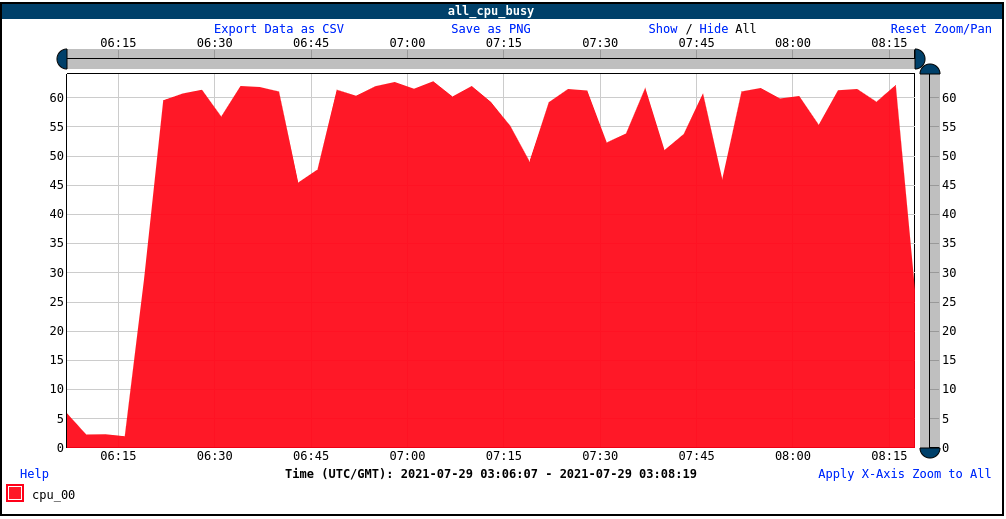
First, let's rule out whether there is any kind of CPU restriction on the guest, possibly a restriction from bottlenecking on one core. There is not; we are consuming about 70% of one core total, but the first core is using somewhat more than its share (about 30%):

On the host, we are seeing the KVM guest consuming about 280% of one core, so there is a lot of overhead, but nowhere near the number of cores in the guest (nine) or the CPU limit (eight). Looking closer, we see the vhost consuming close to 90% of one core:
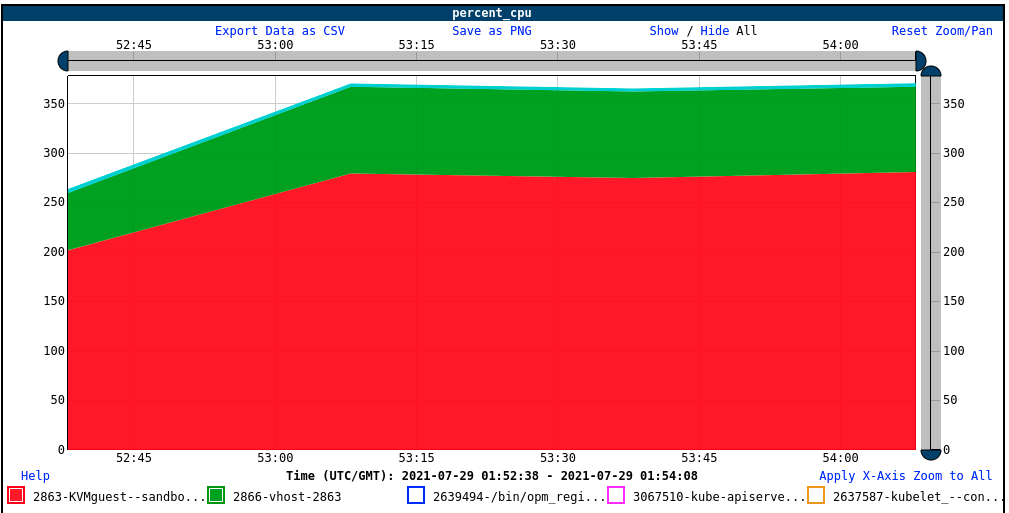
That certainly suggests the possibility that the vhost process is the bottleneck, at least on our system. But what can we do about it?
Recall that normally the sandbox VMs are started with one core and one vhost. As noted in the sidebar, it is possible to increase the boot size of the guest VM, and thereby also increase the number of vhost helpers, by means of the io.katacontainers.config.hypervisor.default_vcpus pod annotation (which I will henceforth refer to as default_vcpus). Let's see what happens if we try changing that to other values (such as 2, 4, and 8), using 16 streams and 64K byte messages. I have also tried using VMs with as many vCPUs as there are physical CPUs on the host. At the time I performed this work, the annotation was not available to me, and I had to set it using a per-node configuration file that allows this, but the effect is the same.
Note that in the graph below, the total number of CPUs the guest VM has is the sum of the default_vcpus value and the CPU limit. Hence, a CPU limit of two and a default_vcpus value of four yields a guest with six CPUs: four at boot (via default_vcpus) and two added because of the limit. This will be the case for all such graphs below.

Now we are getting somewhere. Setting default_vcpus to 2, we easily achieve the same performance we do with conventional containers, as long as there is either no CPU limit at all or a high enough CPU limit. Also, we see that if we increase default_vcpus further with a limit set, we get worse performance than with default_vcpus = 2 and no limit. This conclusion remains even when the limit is higher than the number of default_vcpus given. I will come back to these points later, but let's start by celebrating our victory and analyzing how we achieved it. First, we will look at guest-side CPU consumption, with a message size of 64K, a CPU limit of 8, and default_vcpus set to 2:
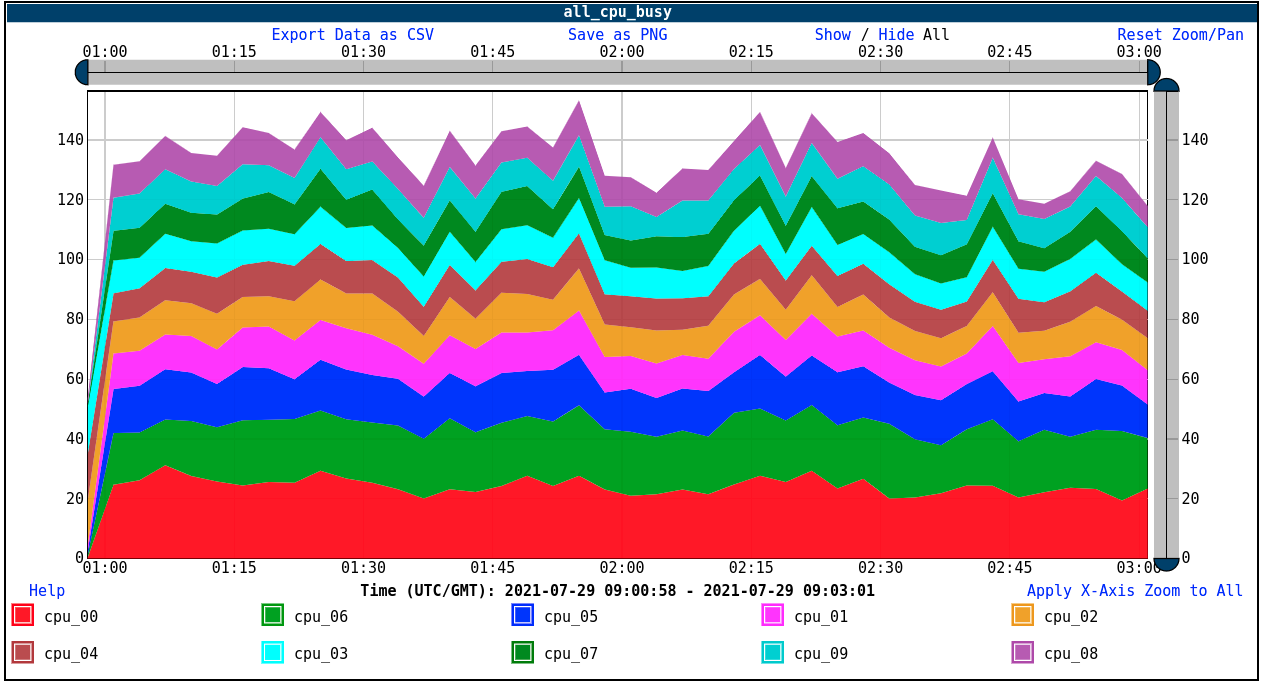
Our guest is using something over a core on average, which is a lot more than it was by default. What about the host?

We see the hypervisor using almost 3 cores, so there is still a lot of overhead. But look at vhost. As there were two boot CPUs, there are now two vhost kernel threads (which show as processes), which combined are using about 1.15 cores. So this certainly confirms our hypothesis that we were limited by the vhost helpers.
By the way, I want to point out that this does not come free of charge: Achieving the same performance requires a lot more CPU. The non-sandboxed pod consumes only about 1.8 cores versus the 4.5 cores for the sandboxed pod and its helpers:

Note also that we saw above that with a low CPU limit, increasing default_vcpus actually made performance worse. We believe at present that this is due to contention or some similar overhead with the larger number of cores and vhost processes available, but we have not found the root cause. So as a general principle, do not set default_vcpus if you are also using at least a low CPU limit. We will shortly see more examples of why that is a bad idea.
Let's look at small (16 byte messages) now. Of course, we expect less throughput, but how much less?

We need to recall that the total number of CPUs in the guest is the sum of the CPU limit and the default_vcpus value, for example, "Kata 1 vCPU Lim 8" results in a guest with 9 CPUs total, 1 at boot and 8 added for the CPU limit. For all the cases with a CPU limit, we actually do quite well, very close to the performance with conventional pods. So the bottleneck here is likely somewhere lower in the network stack, but that is not our concern right now. However, with no limit, the behavior is very different: The performance is about the same as with a limit of 1, much worse than with a higher limit. What is this telling us?
First of all, the lone CPU in the non-limited guest is completely saturated:
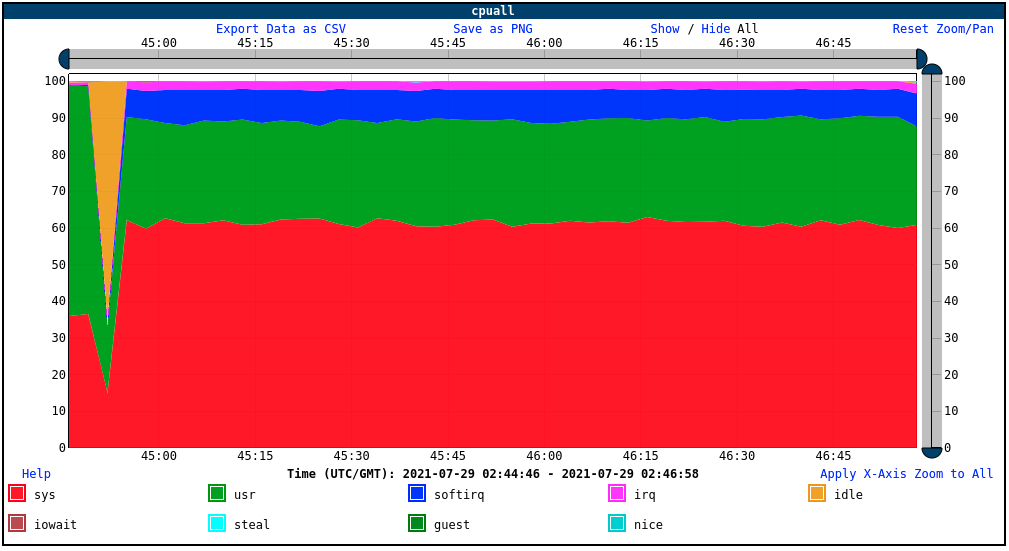
On the host side, we see the saturated KVMguest, and the vhost is consuming a little over 10% of one core; combined with the virtiofsd, the cgroup as a whole is consuming about 1.2 cores:
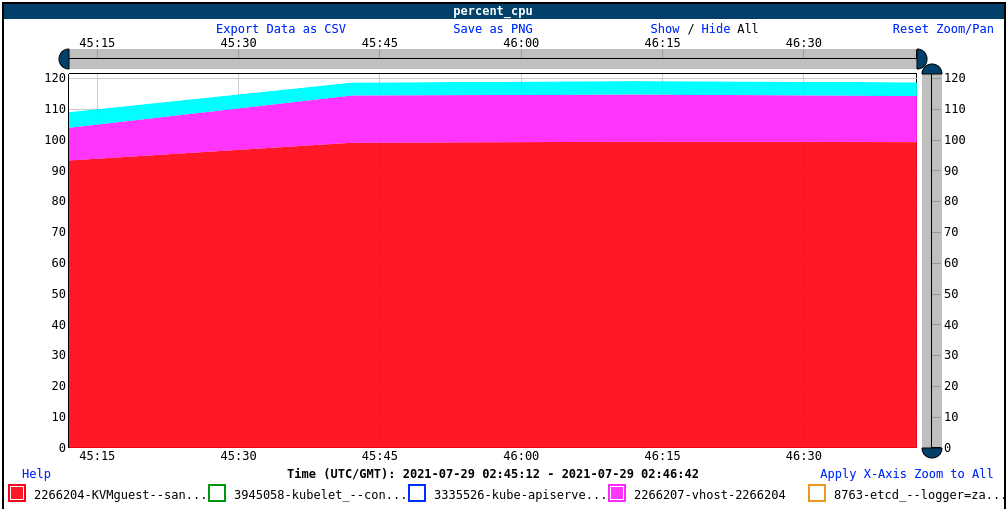
The pod running with a limit of 1 core will have 2 CPUs in the guest, so it could use more CPU, but the cgroup CPU limit will not let everything exceed 1.25 cores. So it is likely coincidence that the 1-core limit and the no-limit cases perform just about the same. We could test this by increasing the 0.25 core bonus for the Kata runtime, but we have not actually done so.
So can we do anything with default_vcpus here? The answer is, "Yes, with a caveat":

If a pod has no CPU limit, increasing default_vcpus improves performance, at least up to the number of workers in the guest running uperf. However, with many threads, increasing the CPU limit does not help matters (at least up to the eight that we have tried), and indeed makes matters worse. So as a rule of thumb: to improve performance, use either a CPU limit or the default_vcpus annotation, but not both.
One final graph here to illustrate this. We are comparing performance with varying settings of default_vcpus, using no CPU limit (solid bars) and a limit of 8 cores (crosshatched bars), using varying numbers of streams and 256 byte messages. Notice that with no limit, the performance improves, at least up to the number of workers. With a limit, even as high as 8, set, performance degrades as default_vcpus is increased. In this graph, the color refers to the setting of default_vcpus (or conventional pods), while the hatching pattern refers to the CPU limit:
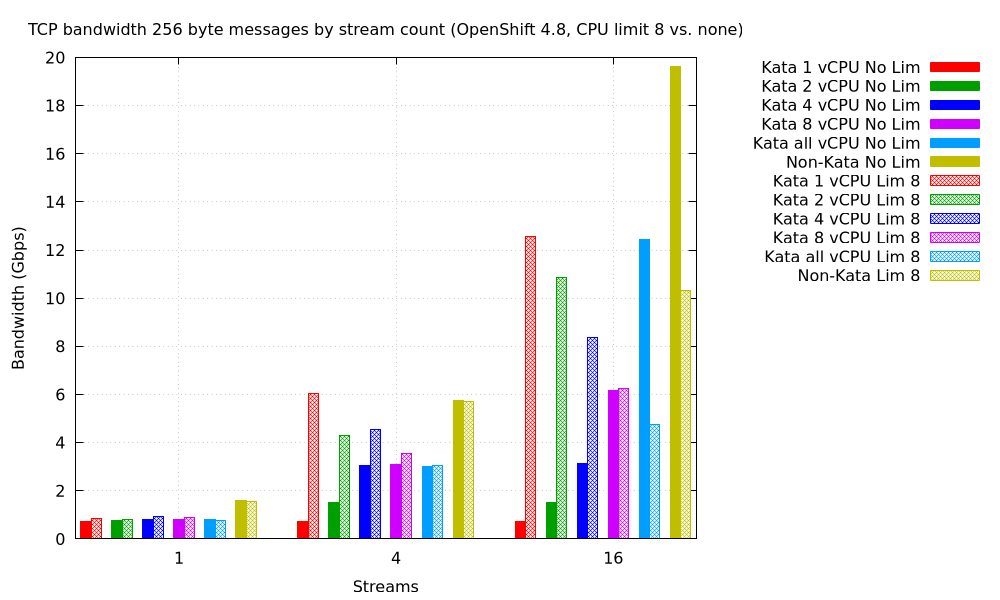
The upshot here is that if you want to experiment with default_vcpus, you should:
- Understand the workloads that you are going to run on the node: Are they network-bound and heavily multithreaded or multiprocess?
- Understand the effect of CPU limits: With a CPU limit, increasing default_vcpus can make matters worse. So use either the default_vcpus annotation or a CPU limit, but do not use both.
Latency
Latency held fewer surprises. First, single stream latency, with default_vcpus not set (that is, equivalent to set to 1):
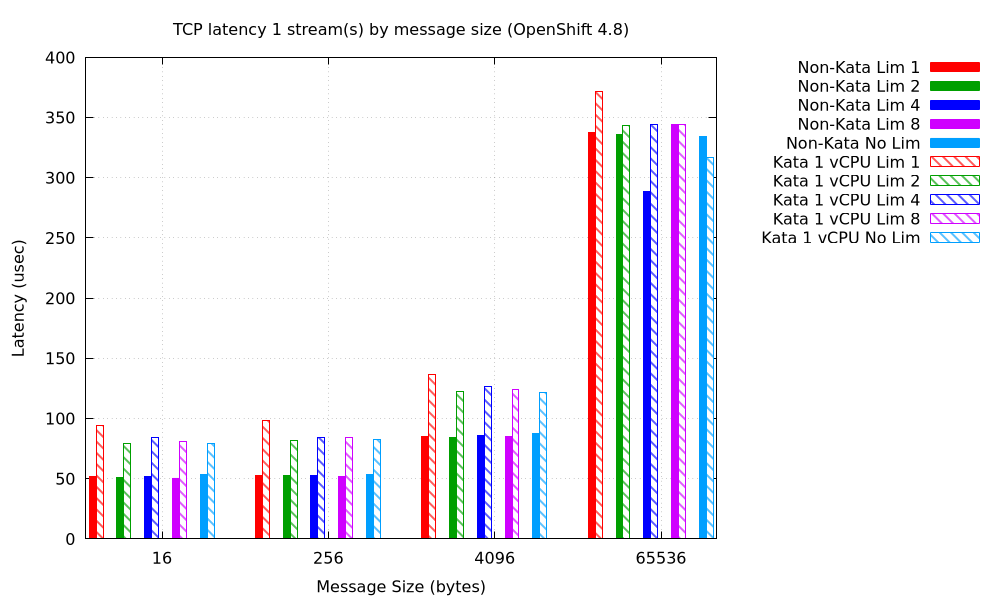
What we see here is roughly constant time overhead of 30 microseconds, regardless of message size, for sandboxed pods versus non-sandboxed (with a small additional penalty for sandboxed pods with a limit of 1 core). So that suggests that the problem is data path length; there is one more thing (vhost) in the path.
Multistream latency was a bit different; with 16 streams:

Here we are seeing something that looks more like a constant factor overhead rather than constant time; it suggests that the vhost is being saturated. Will increasing default_vcpus help us? In this case, I'm going to use 4 streams with 16 byte messages to better illustrate a few points:
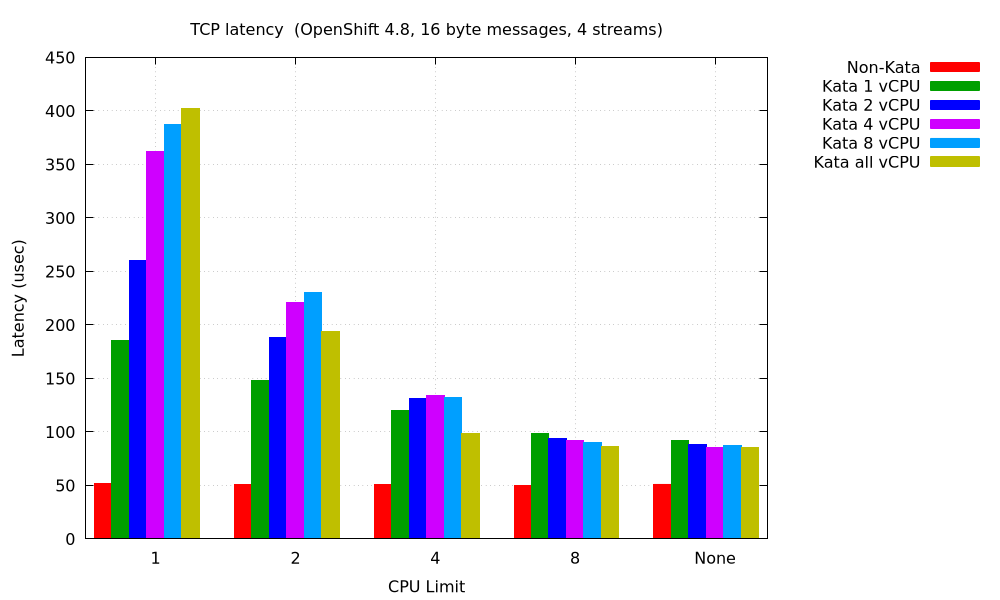
We are seeing behavior very similar to the behavior with bandwidth:
- If there's no CPU limit, latency improves with increasing default_vcpus.
- With a low CPU limit (less than the number of streams), however, latency degrades (this is even more apparent as the number of streams increases further).
- With a large CPU limit, latency typically also improves, but is not better than with no CPU limit.
Again, do not combine default_vcpus with a CPU limit. It will likely make your performance worse.
What's next?
I hope this blog has been useful to you in your quest for network performance with OpenShift sandboxed containers. Stay tuned for future blogs on OpenShift sandboxed containers performance.
About the author
More like this
Why Red Hat partners are the ultimate telco business asset
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds