

This blog is part of a series on OpenShift sandboxed containers and focuses on the operator portion of the solution. See this blog for a simple introduction to OpenShift sandboxed containers. You can also refer to the documentation to understand the basics of the OpenShift sandboxed containers operator.
In this blog, we will dive deeper into the internals of what the OpenShift sandboxed containers operator does going bottom-up. We will take you through what happens behind the scenes for performing the installation and maintenance of the Kata containers runtime on an OpenShift cluster.
By the end of this blog, you should have a solid understanding of how this operator performs its tasks in a Kubernetes-native way.
The Operator Framework and Its Usage
What is the Operator Framework?
How does the OpenShift sandboxed containers operator architecture fit into the Kubernetes architecture and the Operator Framework?
Kubernetes is all about automation. The goal of Kubernetes operators is to automate tasks that are typically done by a human operator (an infrastructure engineer or application developers) with simple software. Because it is software, it scales better and potentially manages huge numbers of instances. To achieve this level of automation, Kubernetes lets us extend its API by creating custom resources (CR). Those resources can be treated like original Kubernetes resources, such as Pods and Nodes).
The following diagram shows similarities between the workflow of a human and a Kubernetes operator:

So what exactly makes this imitate the behaviour of a human operator? Where is the translation of knowledge (for example, . about the needs of a second runtime and the effort it takes) into software?
Number two in the above diagram shows how the first step is the installation of the Kata containers on the nodes and configuring it to one's needs. Doing this step manually would mean installing RPMs on each system and editing configuration files. The operator starts the installation by creating a MachineConfig object that triggers another operator, the MCO, to handle the operator. Once installed, a human operator would watch (see number two in the above diagram) the state of the system for events that require an action to keep it in the intended state. Kubernetes provides a concept called watches. By creating a watch, the operator can, for example, support scaling by watching the cluster’s number of nodes. When new nodes are added to the cluster, the Kata runtime needs to be installed on it as well. By adding a watch on the size of the machine config pool "worker," the operator can keep track of it. When notified about a size change, it makes sure all the conditions that sandboxed containers need to run are replicated to the new node as well.
Eventually - step number three in above diagram - when the Kata Containers’ runtime is installed and configured, the last step is to add the RuntimeClass, by creating a new RuntimeClass object. While the human operator does this with “oc apply,” the operator sends an API request to create the RuntimeClass.
Kubernetes Concepts and the Operator Framework
Let's start with a very short introduction to operators in general. This will help you understand what and why the operator does what it does. The controller pattern is close to the heart of Kubernetes. A controller constantly watches and reconciles the specified state of a resource and makes sure the current state matches it.
The following diagram depicts the controller pattern:
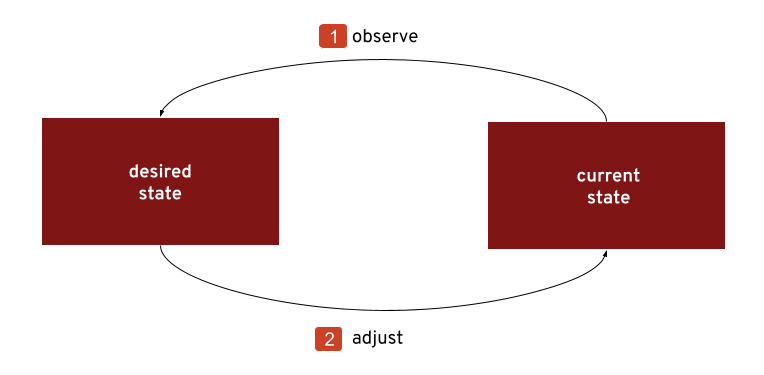
Basically the steps are:
- The controller, which is part of the operator, watches this resource and gets a change event. Now it knows the new desired state of the resource.
- The controller does what it takes to drive the current state towards the desired state it just learned about.
The Operator pattern builds on the controller pattern. An operator uses one or more controllers. It uses a CustomResourceDefinition (CRD) as input and output for the current state and desired state. In this case, the CRD is the KataConfig. An Operator can also own more than one CRD. Typically, it has a reconcile loop for each CRD it owns. But more about reconciling later.
The Operator SDK
Many operators exist today, managing the life cycle of system components, applications, databases, and more. What they have in common is that they implement a pattern, the Operator pattern, which is described in the Operator Framework. Because all operators implement this pattern, it would be a shame if every operator developed had to implement this common logic on its own. Fortunately, that is not the case, because we have the Operator SDK. It lets developers generate most of the code. What is left to implement for an operator developer is the reconciliation loop. That is where the magic happens.
Using the Operator Framework for the Operator
To turn the declared state of Kata in the cluster into reality (such as software being installed or configuration settings changed), an operator uses two building blocks: The first is the KataConfig Custom Resource, which describes the target cluster state. The second is the reconciliation loop, which follows the custom resource current state and converges it to the target state. Let’s provide more details on each of the building blocks.
The KataConfig Custom Resource
A custom resource (CR) is a user-defined resource type. The opposite would be a "Build-in resource type" such as a "Pod." CRs are used when one wants to define new (custom) controllers.
The sandboxed containers operator currently owns one custom resource called KataConfig.
Kata containers is currently the one and only runtime that the operator manages, hence the name. In the future, it is possible that more will follow.
Reconciliation Loop
A reconciliation loop is a part of the operator. It implements the part of the controller/operator pattern that drives the current state towards the desired state.
The following diagram shows the KataConfig reconcile loop:
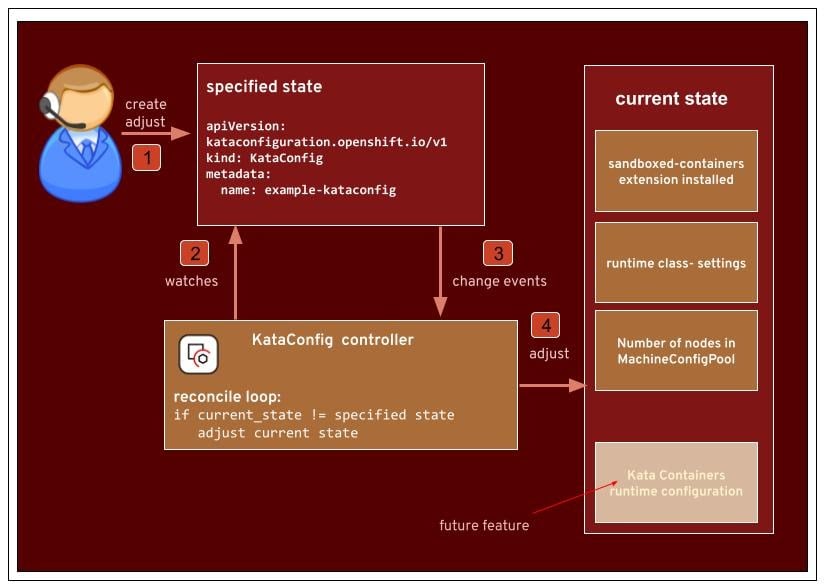
Let’s go through the different steps
- The KataConfig resource is added/modified/deleted.
- The controller watches this resource instance.
- The controller gets a change event along with the resource data and the type of event (added/modified/deleted).
- In the reconcile loop, which is part of the controller, it sends requests to adjust the current state towards the new desired state.
The main action happens when the KataConfig CR is created (1). The Controller in the Operator will run its reconcile function as seen in the above diagram. This is the heart of the Operator, the part where it makes sure that the desired state matches the current state (4). Let’s follow the example in the diagram where a user creates an instance of the KataConfig CR via the OpenShift console. The controller is a client of the API server and watches the resource type. When it is notified about an added instance (3), it creates a new KataConfig instance. The first thing done in the reconcile function is to GET the KataConfig instance. When this GET request returns a KataConfig instance and it is not marked for deletion, the operator will install Kata on the cluster.
The opposite change in state would be when the instance of KataConfig with the name "example-kataconfig" is deleted, for example, 'oc delete kataconfig example-kataconfig'. In this case, the reconcile function is called, and when it finds a deletion timestamp on the KataConfig object, it goes ahead and undoes everything it did during the installation. However, a prerequisite to uninstallation is that all Pods using the Kata runtime have been deleted. If the operator finds Pods that are still using the Kata runtime, it will display a warning message in the status section of the KataConfig Custom Resource and block the uninstallation until it is resolved by deleting the Pods.
The OpenShift sandboxed containers Building Blocks
Going back to our previous blog Operator, Please connect me with Kata Containers let’s recap the main building blocks we have:
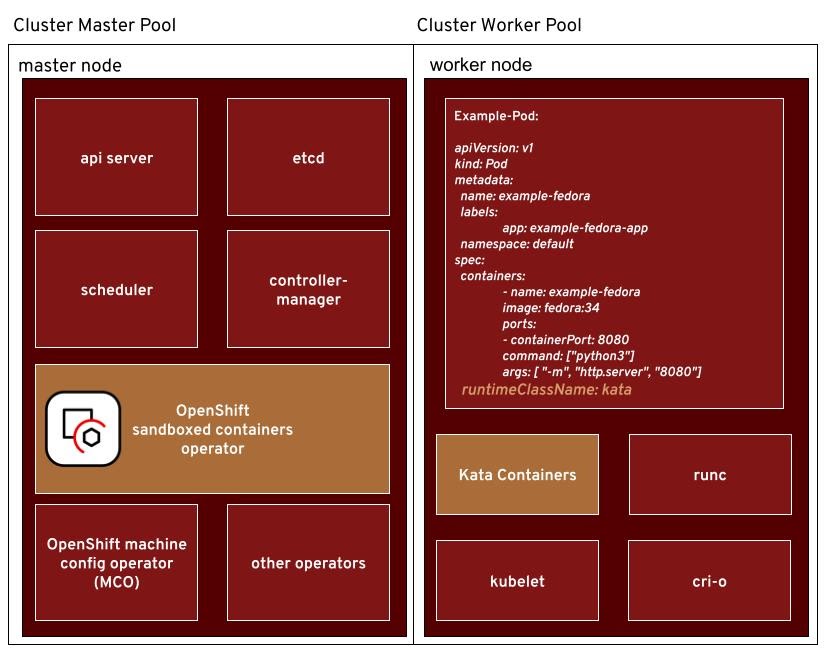
There are two main building blocks. We have the operator itself, which is installed via the OperatorHub in the OpenShift console like any other operator. The other main building block is the Kata Containers runtime and the dependencies it needs to run such as QEMU. These are part of a Red Hat CoreOS operating system extension and are not installed in a default OCP installation.
Enabling the Runtime
Let’s talk about how the operator installs the different components on the nodes.
To distribute configuration files and enable OS services the OpenShift sandboxed containers Operator uses the Machine Config Operator (MCO). It creates MachineConfig objects and watches MachineConfigPools for retrieving information regarding the state of nodes, conditions, and failure information.
A MachineConfig is how OS-level configuration is defined when the snodes are running RHCOS. By using the ignition format, MachineConfigs can be used to change kernel, systemd, storage, and more.
The operator creates the following MachineConfig object to enable the Kata containers runtime on the cluster nodes:
|
apiVersion: machineconfiguration.openshift.io/v1 |
The last two lines in the above snippet are the magic ones that indicate the desire to enable the extension.
The following diagrams shows what is triggered by this:

MCO watches the MachineConfig resource (2) and when notified about a change, takes action and enables the extension. The machine-config-daemon (3) runs as part of a Daemonset that is controlled by the MCO. It applies new machine configuration during updates to the nodes and verifies the new state. When it enables the sandboxed-containers extension, it runs rpm-ostree to install (4) the Kata Containers and QEMU RPMs.
Users can watch the progress of the installation by monitoring the description of the Kataconfig CR they have created, that is, ‘watch oc describe kataconfig example-kataconfig’. When the runtime is installed everywhere, the last step the operator performs is to add the definition of the new RuntimeClass:
|
apiVersion: node.k8s.io/v1 handler: kata kind: RuntimeClass metadata: creationTimestamp: "2021-05-26T08:56:27Z" name: kata [...] overhead: podFixed: cpu: 250m memory: 350Mi scheduling: nodeSelector: node-role.kubernetes.io/worker: "" |
With the container runtime installed and the RuntimeClass created, using the new RuntimeClass is easy. By adding the name of the RuntimeClass to a deployment unit such as Pods or Deployments, the user can now instruct CRI-O to use the KataContainers runtime instead of the default one.
For example:
metadata:
kind: Pod
RuntimeClassName: kata
See our previous blog, Operator, please connect me to sandboxed containers, for how to use the RuntimeClass. Now we will look at how they work.
Kata Runtime Class
So we took you through the process of how the operator creates the runtime class. So the question we then should ask is how does the runtime class work?
Scheduling
Runtime classes enable clusters to be heterogeneous. This means a node does not have to support every runtime class. Why would you want this? From a sandboxed containers point of view, one use case is that an administrator wants to separate his sandboxed workloads from others. Typically sandboxed workloads are sandboxed because they are less trustworthy or belong to different tenants.
The scheduling field in the RuntimeClass kind has a nodeSelector field that can be used to select nodes. It also has a tolerations field. Together nodeSelector and the tolerations field can be used to specify suitable nodes in more detail.
The following diagram shows the use of the RuntimeClass:
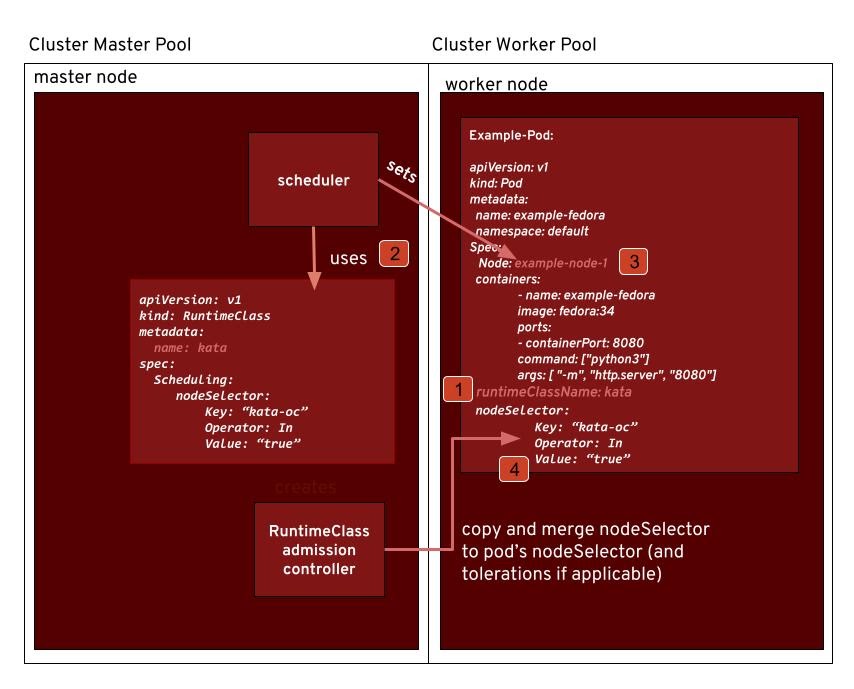
Note the following:
- A Pod is created and it specifies the runtime class ‘kata’.
- During the admission phase of the Pod creation, the nodeSelector and toleration fields are copied to the spec.
- The scheduler takes the RuntimeClass and the nodeSelector in it into account.
- After consideration of all parameters, the scheduler fills in the node field in the Pod’s spec.
A bit more detailed: How does nodeSelector from the RuntimeClass make it to the Pod’s nodeSelector? A user creates a Pod and then … a lot of things happen. One of those is that during admission, the RuntimeClass admission controller merges the runtime class’ nodeSelector into the Pod’s spec. What it does is simply add the key-value pairs. If a key-value pair already exists, it will abort and reject the Pod, that is, creation of the Pod will fail for the user. The merge goes well and the Pod is created. The scheduler can now consider all relevant fields, including those updated by the RuntimeClass admission controller, and decide on which node the Pod will be scheduled for.
Pod Overhead
With Kata Containers, a Pod needs more resources compared to a runc container. It requires more memory because on top of kubelet, container runtime, kernel, and logging, it also runs a virtual machine, that is, a guest kernel, generic Linux userspace programs, and Kata-specific ones like kata-agent. Besides memory, those also need CPU resources. Similar to the scheduling part of the RuntimeClass, PodOverhead is also handled by its admission controller. A user wants to create a Pod, an API request is sent to the API server, and after it is authenticated, the registered mutating admission webhooks are called. One of those is the RuntimeClass admission controller which adds the overhead values specified in the RuntimeClass to the resource requests of the Pod. The values we set as defaults have been measured in our internal tests and proven to be good for most cases. Users can change pod Overhead values,but we recommend not doing so.
Installing on Selected Nodes Only
Let’s talk about what a user should perform when aiming to run Kata Containers only on a subset of nodes in the cluster.
When a KataConfig CR is created, the user can choose a label. This label is applied to nodes that should have the Kata Containers runtime installed by the cluster-admin. What the operator does then is to create a new Machine Config Pool (MCP). All nodes that have the label will become a member of this pool.
The following diagrams shows this scenario:
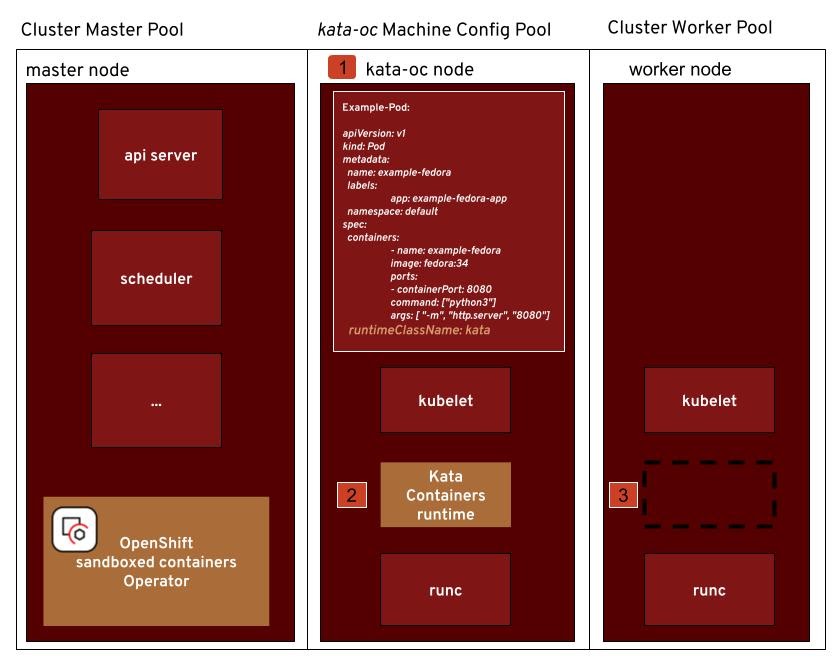
Note the following:
- A new Machine Config Pool called ‘kata-oc’ is created by the operator when it is specified in the KataConfig.
- Nodes that are part of the ‘kata-oc’ pool have the Kata Containers runtime installed.
- All other nodes stay untouched and will not considered when scheduling Pods using the RuntimeClassName ‘kata’.
This is a small snippet of the ‘kata-oc’ MCP specification:
Machine Config Selector:
Match Expressions:
Key: machineconfiguration.openshift.io/role
Operator: In
Values: kata-oc
worker
Node Selector:
Match Expressions:
Key: custom-kata-pool
Operator: In
Values: true
This means that the MachineConfig also slightly changes as follows:
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
app: example-kataconfig
machineconfiguration.openshift.io/role: worker kata-oc
name: 50-enable-sandboxed-containers-extension
spec:
extensions:
- sandboxed-containers
MachineConfig Pools map MachineConfigs to nodes. With this MachineConfig, and the NodeSelector in the pool, we map “extension: - sandboxed-containers” to the kata-oc MachineConfig Pool. What this means is: The extension is enabled on those nodes with label “machineconfiguration.openshift.io/role=kata-oc”.
Summary
With the sandboxed containers operator, a new kubernetes-native way of deploying and managing the Kata runtime is available for OpenShift. In this blog, we covered the key building blocks of theOpenShift sandboxed containers operators. This includes the reconciliation loop, machine pools, runtime classes, scheduling, and more.
In the next blog, we will discuss ways to analyze and troubleshoot problems in the OpenShift sandboxed containers operator.
About the authors
Jens Freimann is a Software Engineering Manager at Red Hat with a focus on OpenShift sandboxed containers and Confidential Containers. He has been with Red Hat for more than six years, during which he has made contributions to low-level virtualization features in QEMU, KVM and virtio(-net). Freimann is passionate about Confidential Computing and has a keen interest in helping organizations implement the technology. Freimann has over 15 years of experience in the tech industry and has held various technical roles throughout his career.
More like this
Why flexibility is non-negotiable in the Middle East’s AI transformation journey
4 reasons to start using image mode for Red Hat Enterprise Linux right now
The Containers_Derby | Command Line Heroes
Crack the Cloud_Open | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds