This is a guest post by Yochay Ettun, CEO & Co-founder of cnvrg.io .
Machine Learning (ML) is rapidly becoming essential to all businesses and organizations around the world. However, this means that IT and DevOps teams are now facing the challenge of standardizing ML workloads and provisioning cloud, on-premise and hybrid compute resources that support the dynamic and intensive workflows that ML jobs and pipelines require.
Not only that, but between all the many tools, scripts, plug-ins and disconnected stacks, developers and data scientists spend over 65% of their time on DevOps and managing infrastructure resources requests and hybrid cloud compute. This manual and labor intensive work pulls them from doing what they were hired to do - deliver high impact ML models.
cnvrg.io on Red Hat OpenShift delivers an out of the box solution that empowers enterprise data science and DevOps teams to better manage infrastructure in the hybrid cloud and accelerate the ML workflow in one automated and unified platform. On top of Openshift, cnvrg.io has also collaborated with NVIDIA DGX systems and NGC (Nvidia GPU Cloud) to provide a GPU optimized, distributed AI OS solution with NVIDIA GPUs and OpenShift foundations.
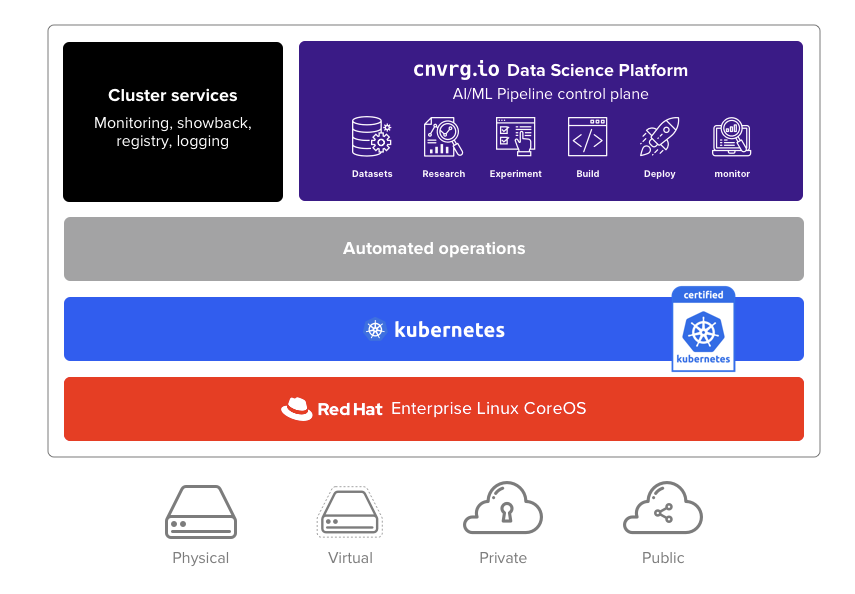
What is cnvrg.io?
cnvrg.io is an AI OS that helps enterprises and data scientists manage, build and automate machine learning pipelines. cnvrg.io’s ML platform helps data scientists spend less time on DevOps, with advanced MLOps solutions, data version control and management, experiment tracking, model management, model monitoring and more. cnvrg.io is a code-first platform and container-based making it agile and flexible to operate on any infrastructure whether in the cloud or on-prem. Its collaborative end-to-end solution enables teams to streamline machine learning and deploy high impact models in half the time. Expert and novice data scientists enjoy the flexibility to use any tool, language or environment while maintaining full control of their models in training and in production.
cnvrg.io on OpenShift: the ultimate MLOps solution
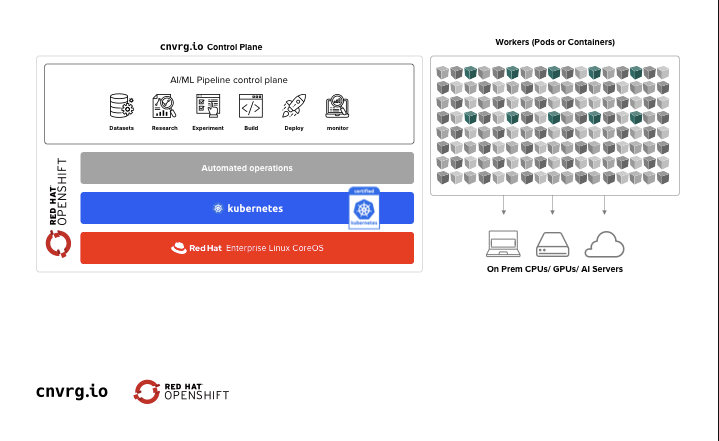
Red Hat OpenShift, the leading enterprise Kubernetes application platform, enables data scientists to launch flexible, container-based jobs and pipelines, as well as providing infrastructure teams with the capabilities to manage and monitor ML workloads in a single managed and cloud-native environment. cnvrg.io then enables data scientists to rapidly launch ML workloads on remote clusters without tinkering with infrastructure or complicated configuration. For infrastructure teams, cnvrg.io provides the ability to manage all ML compute resources in a unified and secure environment with advanced monitoring and administration capabilities built in.
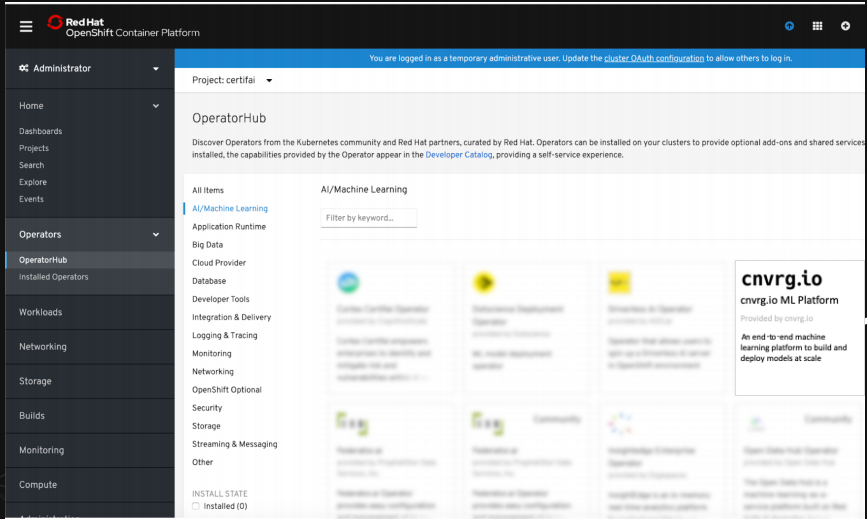
How to operationalize cnvrg.io on OpenShift via OperatorHub
cnvrg.io is operator certified and resides in the Red Hat Openshift OperatorHub. It provides everything a Data Science and DevOps team need to manage their ML workflow out-of-the-box:
- Managed Kubernetes deployment on any cloud or on-premises environment
- Fully automated installation and life cycle management
- All tools data scientists need for ML/AI development: from research to deployment
- Open & flexible, code-first data science platform, which integrates any open source tool
All you need to do is to click on the cnvrg.io tab, and the installation and configuration will be done out-of-the-box with OpenShift.
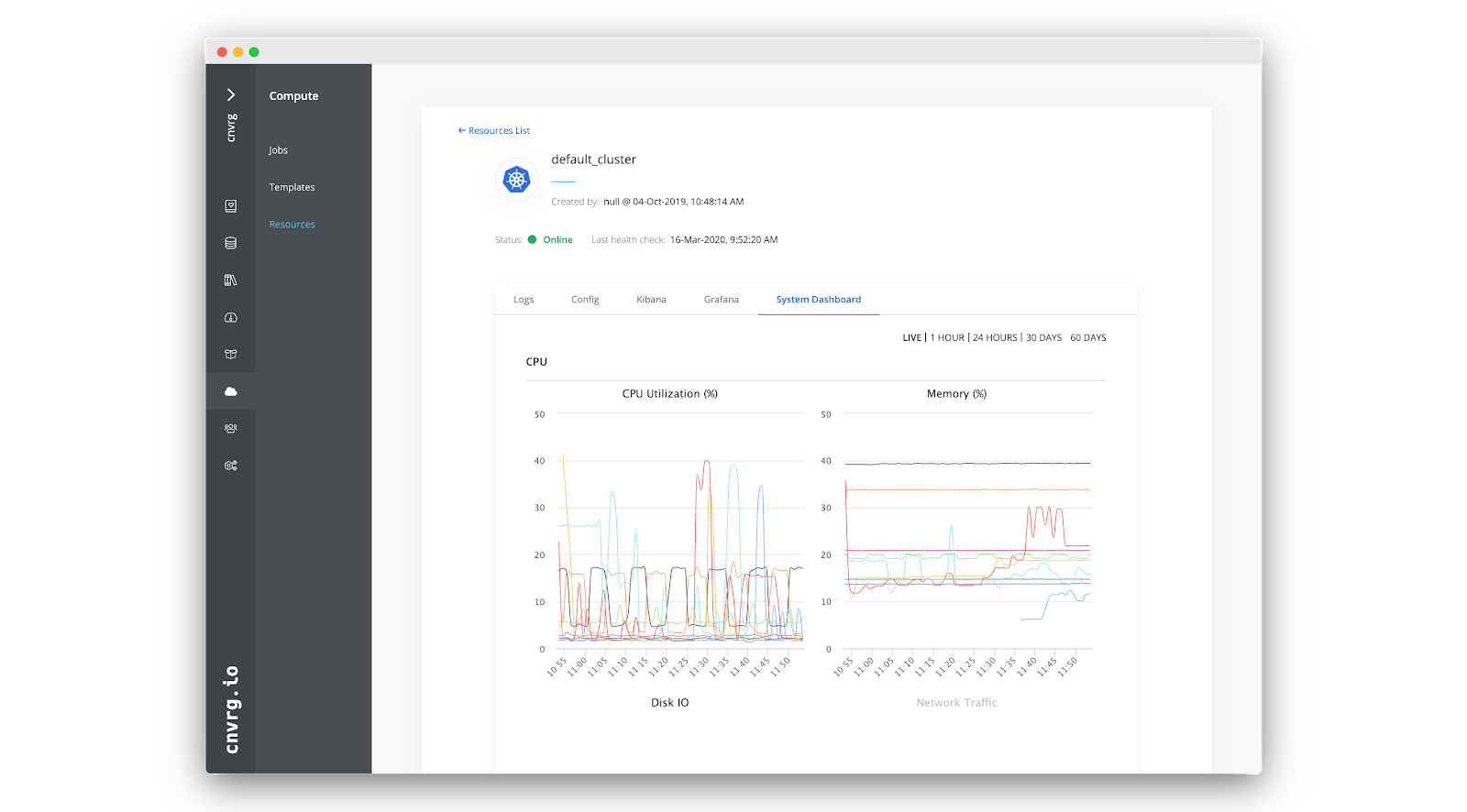
Further, cnvrg.io will be monitored for anomalies and will be tracked to obtain healthy execution across its lifetime. Logs and metrics will be collected, allowing the operations team to monitor and take proactive actions if failure is expected.
Once in the cnvrg.io platform you can begin by starting your own project, or browsing through example projects and start a new workspace. Here’s brief video tutorial to get you started.
Utilizing all your compute resources with cnvrg.io ML pipelines
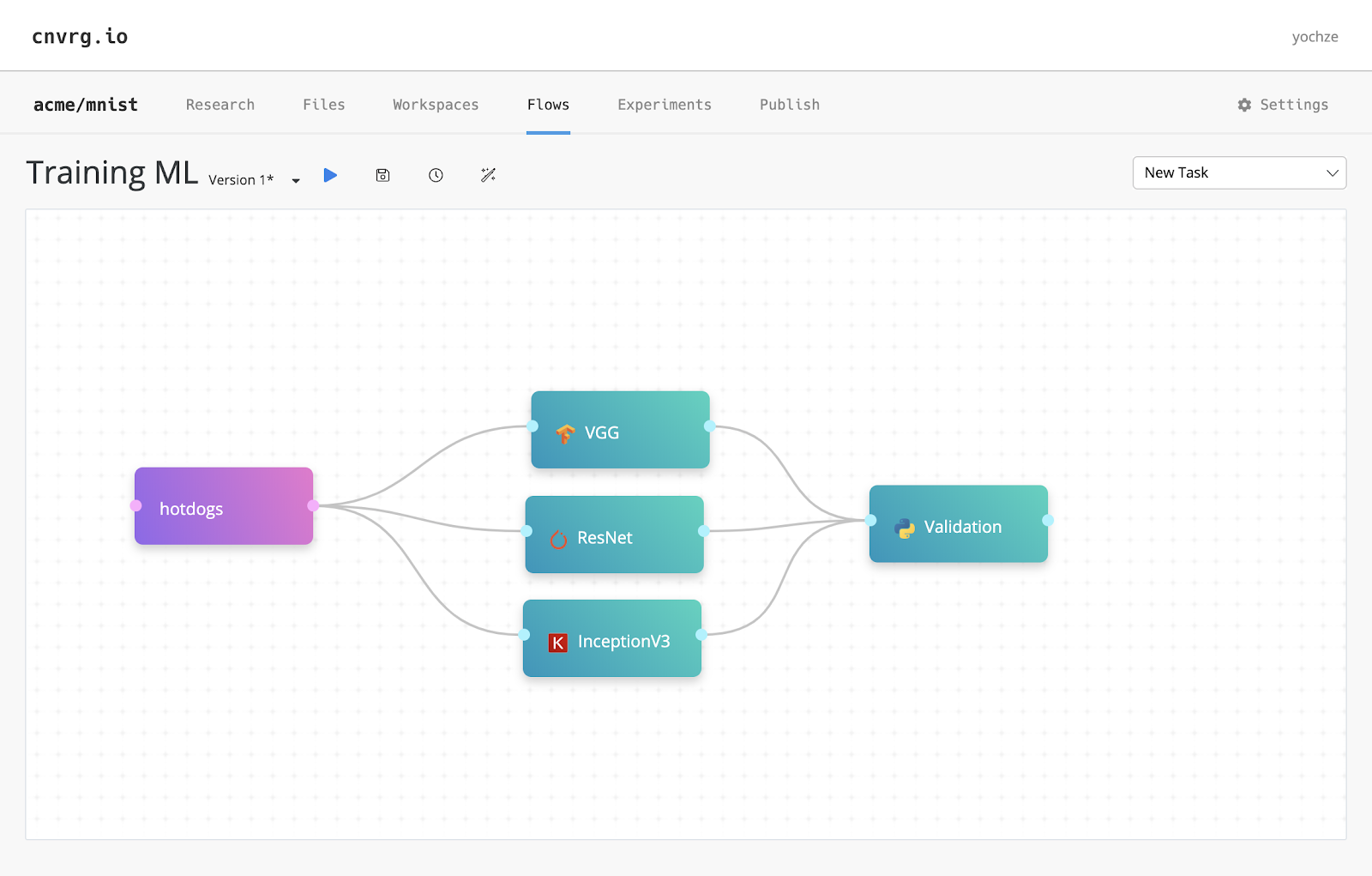
In cnvrg.io you can utilize all your compute resources whether on premise or cloud by controlling your jobs by task, and assigning each job to the most effective resource. You can do this quickly in our Flows feature - production-ready machine learning pipelines that allow you to build complex DAG (directed acyclic graph) pipelines and run your ML components (tasks) with just drag-n-drop. Here’s how to create an end to end ML pipeline with cnvrg.io.
Each task in a flow is an ML component that is fully customizable and can run on different compute resources with different docker images. You can assign each task to a different Kubernetes cluster, location and designating the scale of your resource. For example, you can have feature engineering running on a Spark cluster, followed by a training task running on a GPU instance on AWS. In addition, flows can be versioned, modified, shared, stored, revoked and customized. When a task completes, it frees the resource automatically so it can be utilized elsewhere.
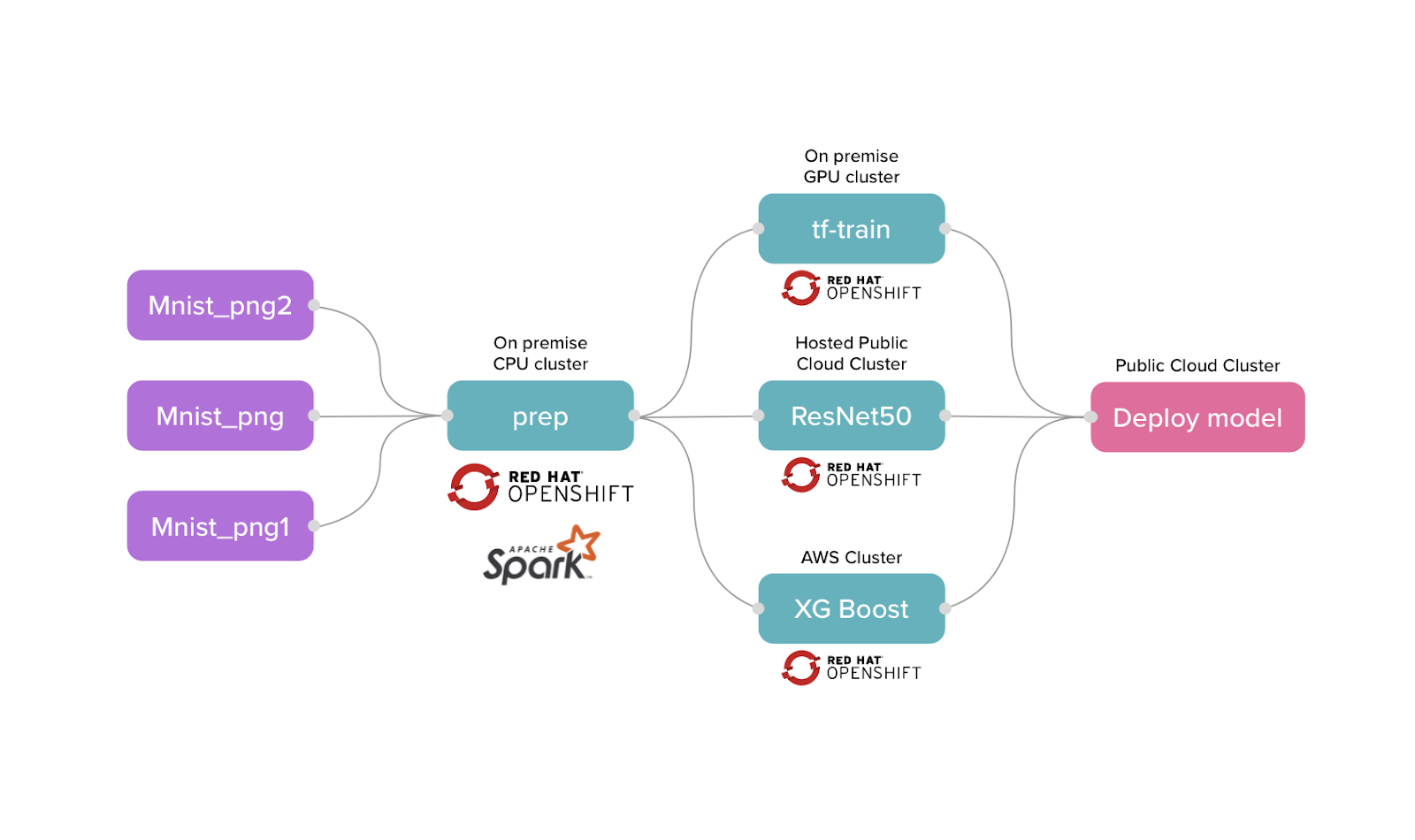
OpenShift is an excellent foundational technology for cnvrg.io, as it provides the ultimate automation for Kubernetes clusters and infrastructure life cycle management. cnvrg.io adds advanced AI/ML capabilities such as model management, rapid experimentation and production ML on top of Openshift Kubernetes infrastructure with a strong and native integration. Together with Red Hat Openshift, cnvrg.io gives data scientists and DevOps engineers an out-of-the-box AI solution to accelerate machine learning life cycles, and provides teams agility, flexibility, portability, and scalability to train, deploy, and maintain ML models in production.
cnvrg.io is free to deploy, you can get started with cnvrg.io in one click via Red Hat OperartorHub.
You can learn more about the benefits of using cnvrg.io on Red Hat Openshift here: https://cnvrg.io/solutions/red-hat-openshift/
About the author

More like this
Manage MCP servers on Red Hat OpenShift with the MCP lifecycle operator
The agentic paradox and the case for hybrid AI
Technically Speaking | Build a production-ready AI toolbox
Technically Speaking | Platform engineering for AI agents
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds