
Kubeflow is an AI/ML platform that brings together several tools covering the main AI/ML use cases: data exploration, data pipelines, model training, and model serving. Kubeflow allows data scientists to access those capabilities via a portal, which provides high-level abstractions to interact with these tools. This means data scientists do not need to be concerned about having to learn low-level details of how Kubernetes plugs into each of these tools. That said, Kubeflow is specifically designed to run on Kubernetes and fully embraces many of the key concepts, including the operator model. In fact, except for the aforementioned portal, Kubeflow is actually a collection of operators.
In this article, we will examine a series of configurations that we adopted in a recent customer engagement to make Kubeflow (1.3 or higher) work well in an OpenShift environment.
Kubeflow Multi-tenancy Considerations
One of the use cases that Kubeflow addresses is the ability to serve a large population of data scientists. Kubeflow accomplishes this by introducing an approach towards multi-tenancy (fully available from release 1.3), where each data scientist receives a Kubernetes namespace to operate within (there are also mechanisms to share artifacts across namespaces, but they were not explored at this time).
It is important to understand this approach to multi-tenancy, because supporting this feature on OpenShift is where a significant portion of the Kubeflow operationalization was spent. One namespace per user versus one namespace per application (which is the more common pattern when deploying OpenShift) may require some redesign when deploying OpenShift depending on how authentication/authorization is organized.
For Kubeflow multi-tenancy to operate properly, a user must be authenticated and a trusted header (kubeflow-userid by default, but is configurable) must be added to all requests. Kubeflow will take it from there, creating the namespace for the user if it does not exist.
The other aspect of Kubeflow multi-tenancy is the concept of a Profile. A Profile is a Custom Resource (CR) representing an environment of a user. A Profile is mapped to a namespace, which Kubeflow manages The kubeflow-userid header must match an existing Profile for Kubeflow to properly route the requests.
Once a Profile is established and associated with a user, the corresponding namespace is created by Kubeflow where all subsequent activities for that user will occur.
Kubeflow is also tightly integrated with Istio. While there is no hard requirement for running Istio with Kubeflow, it is recommended as Kubeflow security is based on Istio constructs. When running with Istio, one of the simplest approaches to supporting multi-tenancy is to have the namespaces created as a result of Kubeflow Profiles belonging to the service mesh and a single ingress-gateway through which all the traffic flows.
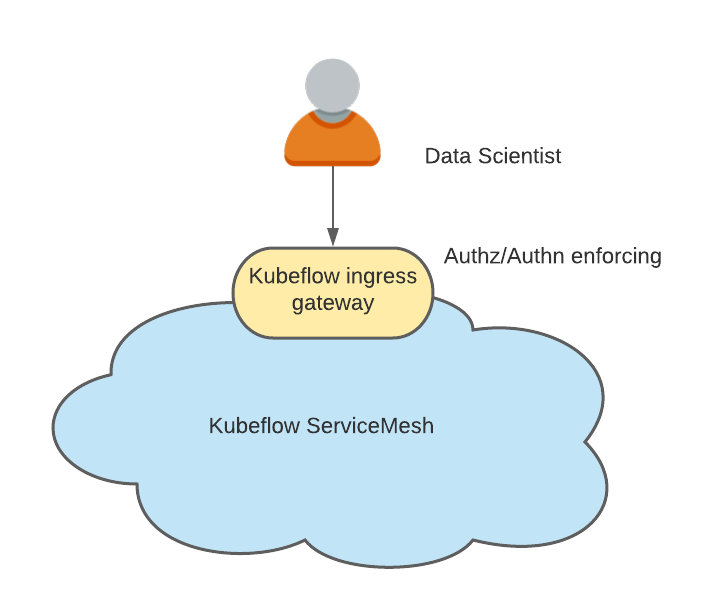
This choke point becomes the natural candidate to perform user authentication and setting the kubeflow-userid header mentioned previously.
Integrating with ServiceMesh
OpenShift Service Mesh is different from Istio in that an OpenShift cluster can contain multiple service meshes, while for upstream Istio, it is implied that the mesh expands to the entire Kubernetes cluster.
In our setup, we decided to fully dedicate a Service Mesh to the AI/ML use cases. With that in mind, only the Kubeflow AI/ML namespaces belong to this AI/ML dedicated Service Mesh.
We also needed to support the fact that data scientists would be added and removed at any time. This led to the decision to adopt the recommended model of one Profile/Namespace per user.
In summary, we had to find solutions for the following requirements:
- Ensure that data scientist connections are authenticated and that the kubeflow-userid header is added to the request in a tamper-proof way.
- Ensure that Kubeflow Profiles are created for each data scientist.
- Ensure that the Kubeflow namespaces created by Kubeflow as a result of a Profile creation belong to the AI/ML service mesh.
Ensure Authentication for Data Scientist
As introduced previously, Kubeflow uses a header to represent the connected user. While there are options to change the default header name kubeflow-userid, it involves modifications in several locations, and as a result, we decided that it would be simpler to just keep using the default header name.
Injecting this header can be accomplished in several ways; the following describes one such approach:
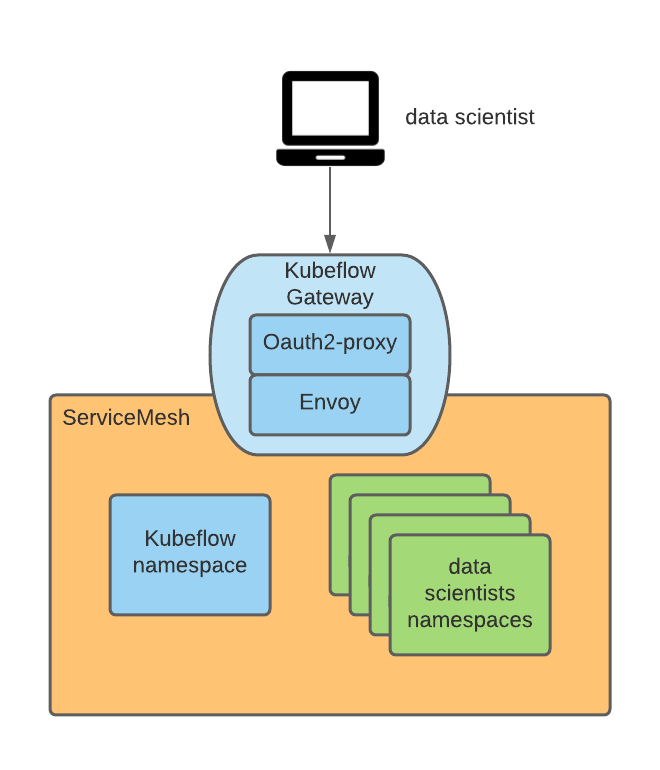
Leveraging the fact that Kubeflow publishes its external facing services on an Istio ingress gateway (by default called Kubeflow), the gateway was instrumented to enforce authentication using an oauth proxy that redirects unauthenticated users to the OpenShift login flow. This oauth-proxy approach is used by many other OpenShift components and enforces that only OpenShift authenticated users with the necessary permissions can make requests. You can find more information on how to integrate the oauth proxy in this blog post.
The oauth-proxy sidecar in the ingress gateway creates a header called x-forwarded-user with the userid of the authenticated user (per http best practices), so we just need to add a transformation rule (implemented as an EnvoyFilter CR) on the ingress gateway to copy the value of that header to a new header called kubeflow-userid. Also, the oauth-proxy sidecar is configured so that only users with the GET permission on pods in the Kubeflow namespaces (one can configure any desired set of permission here which can be used to distinguish between Kubeflow users and non-Kubeflow users) can pass.
This approach achieves the following:
- All Kubeflow users are also OpenShift users (notice that the reverse is not necessarily true). We can leverage what was configured within OCP in terms of integration with the enterprise authentication system. This makes this approach very portable.
- Because there is only one method of ingress into Kubeflow mesh (via the Kubeflow ingress gateway protection), we guarantee that only authenticated users can leverage Kubeflow services.
Ensure Creation of Kubeflow Profiles
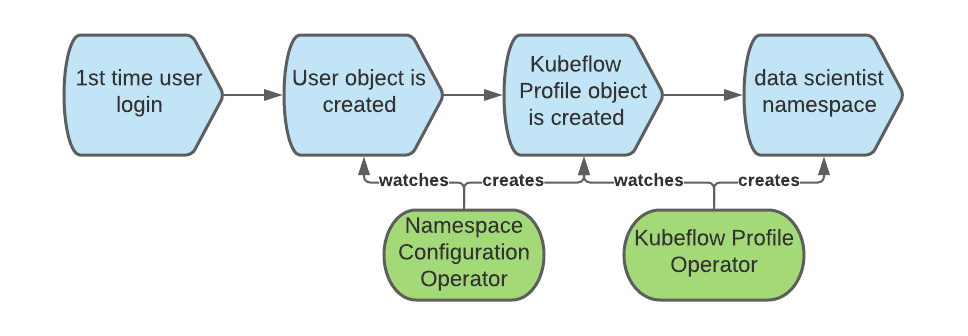
Kubeflow requires a Profile object (CR) to correctly register and handle a user. The creation of the Profile object is called a “registration”. One can let new users self-register, but we decided for an automatic registration process: When a user logs in for the first time, we automatically create the corresponding Profile.
In OpenShift, a User object is created the first time a user logs in. We can intercept that event to also create the Profile object.
To automate the creation of the Profile object, we can use the namespace configuration operator. The following diagram depicts the sequence of events creating the Profile object when a user first logs into OpenShift:
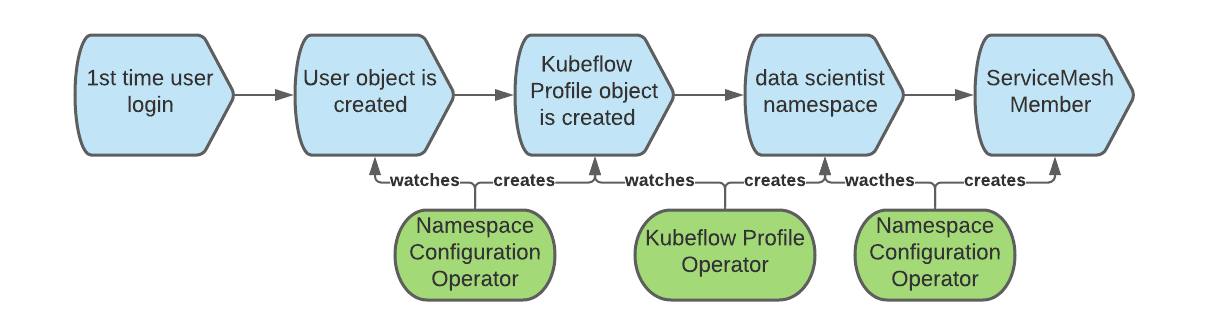
Joining Kubeflow Namespaces to the AI/ML Service Mesh
When we create a Kubeflow Profile object, Kubeflow also creates the corresponding Kubernetes namespace and adds several resources to the new namespace, such as quotas, Istio RBAC rules, and service accounts. Kubeflow assumes that namespaces belong to the mesh, but that is not the case for OpenShift Service Mesh where each namespace must be explicitly joined to a given mesh (there can be multiple). To solve this problem, we can, again, use the namespace configuration operator and this time create a rule that triggers at the creation of namespaces and makes them join the mesh. The full workflow comprises the following:
Once this workflow is set up correctly, the following image represents what a data scientist should see when they log in:
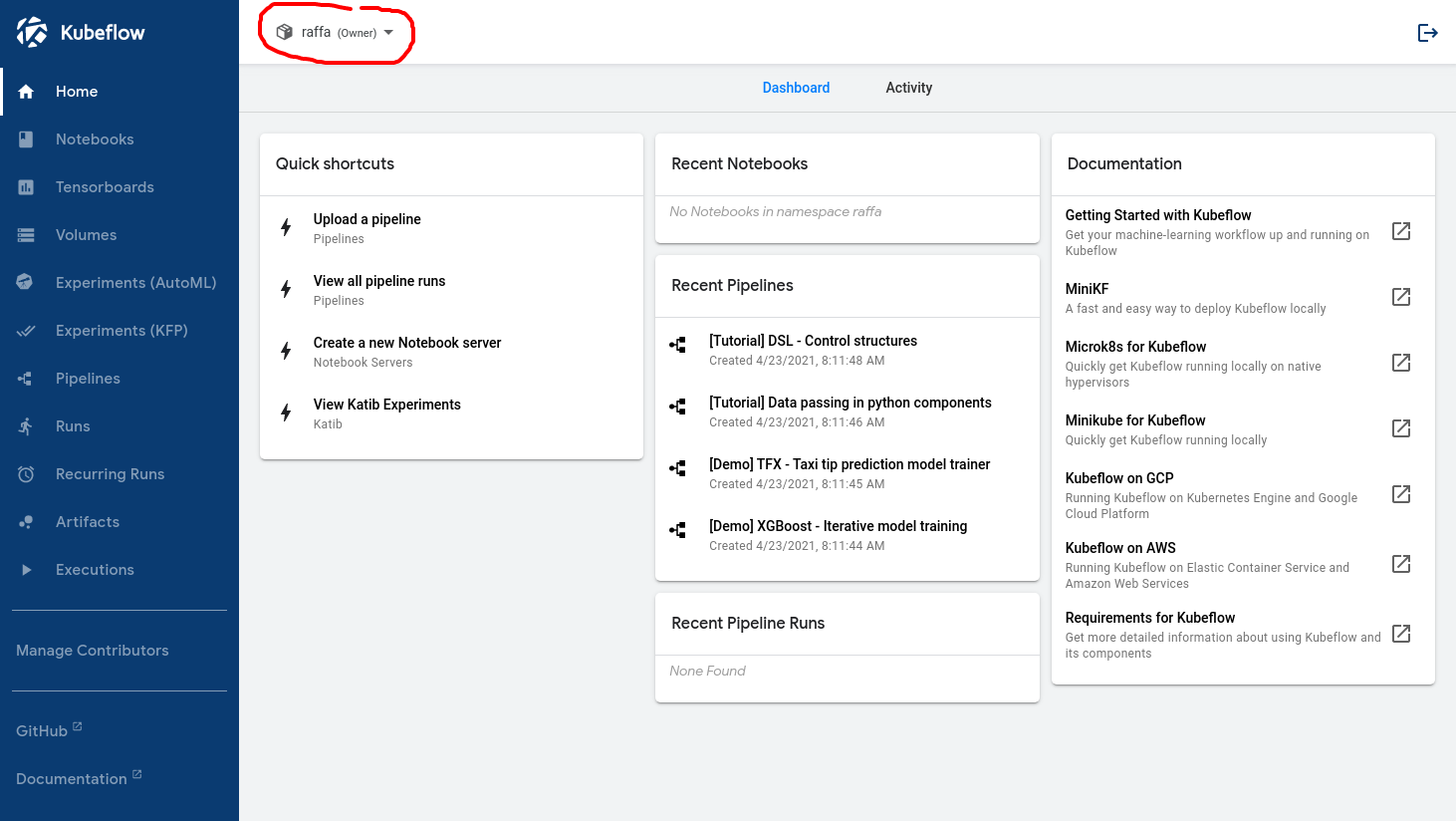
The name inside the red circle confirms that the user has been recognized by Kubeflow.
Enabling GPU Nodes and Node Autoscaling
At this point, data scientists can log in to the Kubeflow main dashboard and start using the provided functionality. Naturally, one of the features that is needed to support several of the AI//ML use cases is the ability to access GPUs.
Enabling GPUs nodes is straight forward, provided the prerequisites are met. This blog post describes the process in detail.
GPU nodes, however, are expensive resources, so it behooves us to implement two requirements to minimize expenses:
- Only AI/ML-related workloads should be allowed on the GPU nodes.
- GPU nodes should be allowed to automatically scale up when more resources are needed and scale down when those resources are no longer needed.
Separating AI/ML Workloads from Normal Workloads
To separate AI/ML workloads from other workloads that may be present in the cluster and that do not require GPU nodes, we can use taints and toleration. We simply have to create the GPU nodes with a taint that will prevent workloads from landing on those nodes by default.
To ensure that non-AI/ML tenants are not able to tag workloads as tolerating the taint, we can use this namespace annotation:
scheduler.alpha.kubernetes.io/tolerationsWhitelist: '[]'
To simplify the life for the data scientist and automatically add the toleration to the workloads running in the AI/ML namespaces, the following namespace annotation can be applied to all Kubeflow namespaces:
scheduler.alpha.kubernetes.io/defaultTolerations: '[{"operator": "Equal", "effect": "NoSchedule", "key": "workload", "value": "ai-ml"}]'In this example, the GPU-enabled nodes have been labeled with “workload: ai-ml” .
Notice that these are alpha annotations and are not currently supported by Red Hat, but, based on our tests, they work fine.
As we discussed previously, Kubeflow will create data scientist namespaces upon first login of the data scientist. Since we do not control how namespaces are created, a process must be implemented so that the correct annotations are applied to the namespace. This can be accomplished using a mutation webhook configuration. This webook can intercept the namespace creation and add the needed annotations. We used Open Policy Agent (OPA) and the Gatekeeper project which integrates OPA with Kubernetes and we deployed it via the Gatekeeper operator.
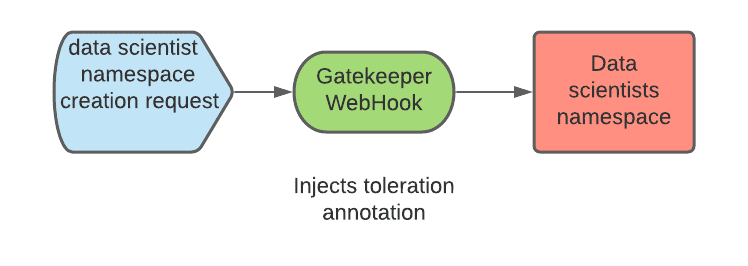
Enable Node Autoscaling
To minimize the number of the expensive GPU-nodes, we need to enable autoscaling on the AI/ML nodes.
Node autoscaling is an out-of-the-box feature of OpenShift and can be enabled using the steps from the official documentation.
When using the node autoscaling feature, it became apparent that the following situations required improvements:
First, the node autoscaler will add nodes only when pods are stuck in a “pending” state. This reactive behavior translates to a bad user experience as users trying to start workloads need to wait for nodes to be created (~5 minutes on AWS) and for GPU drivers to be made available (an additional ~3-4 minutes). To improve this situation, we used the proactive-node-scaling-operator (explained in this blog).
Second, when using GPU nodes, the autoscaler tends to create more nodes than needed. This is because the newly created nodes can’t immediately schedule the pending pods since these nodes are initially not GPU-enabled (while the GPU operator is performing initialization steps, such as compiling and injecting the GPU kernel drivers). To address this issue, a specific label (cluster-api/accelerator: "true") must be added to the node template as explained here. This label will inform the node autoscaler that a given node is intended to have certain features (such as support for GPUs) enabled, even when they are not currently present.
Enabling Access to the Data Lake
For almost every task that a data scientist needs to perform, whether it is data exploration to understand the data structure and its possible internal correlations, training of neural network models via sample datasets, or retrieving a model to be able to serve it, access to data is key. In AI/ML, the data repository, which contains data of all types (relational, key values, documents, tree, and others), is referred to as a data lake.
Securing access to the data lake can be a challenge, particularly in a multi-tenant environment. Moreover, we want to make life easier for data scientists by minimizing the number of Kubernetes and credentials management concepts they need to learn about.
In our case, the data lake consisted of a set of AWS S3 buckets. Alternate storage repository types can leverage many of these same concepts.
The security team also requested that the credentials required to access the data lake represent a workload, not a specific individual. In addition, the credential should be short lived. The goal was to avoid distributing static credentials to the data scientists that could be lost or misused.
To solve this problem, we used bound service account tokens and OpenShift - STS integration, repurposing the latter for user workloads. Let’s look at how these two technologies can be combined together.
With bound service account tokens, one can have OpenShift generate a JWT token which represents the workload and is mounted as a projected volume, similarly to how service account tokens work for any other workload. Differently from service account tokens, this token is short- lived (the Kubelet is in charge of refreshing it) and can be customized by defining its audience property.
STS is an AWS service (similar ones exist for other cloud providers) that allows us to establish trust from AWS to other authentication systems, including OIDC authentication providers. By configuring STS, we can instruct AWS to trust JWT tokens minted by OpenShift and exchange these tokens for AWS tokens with a specific set of permissions. After the exchange occurs, the application running in a pod can start consuming AWS resources. The diagram below depicts this architecture:
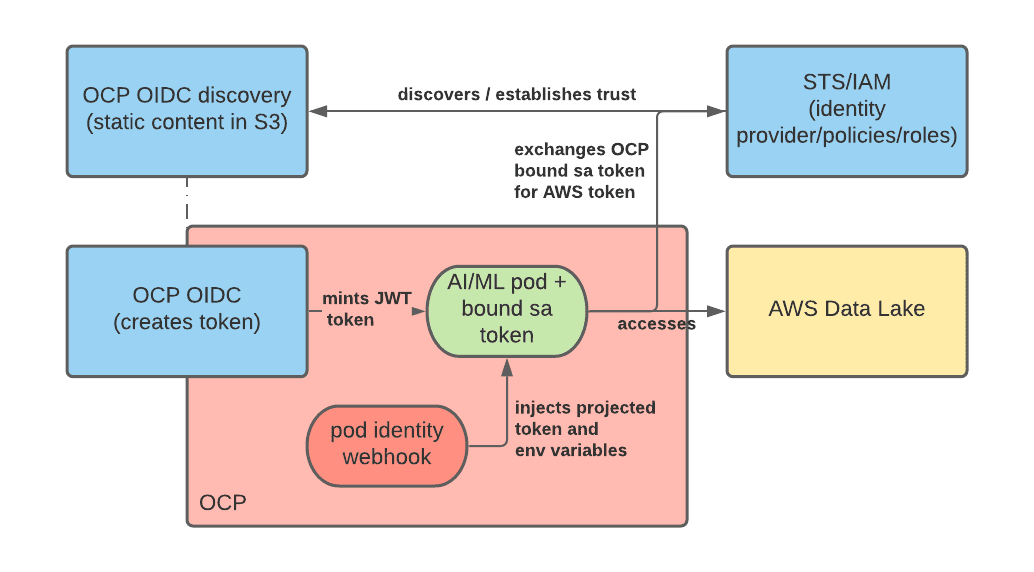
The official docs along with this blog can help you configure the STS integration.
One of the requirements of this approach is that the service accounts used to run the AI/ML pods have specific annotations attached indicating that these workloads require the additional bound service account token. We can do that using OPA and injecting the needed annotations on the service accounts in the data scientist namespaces.
The result of the setup described previously allows the data scientists, and in general, AI/ML workloads, to access the data lake with credentials that represent the workload (and not a particular individual) and are short-lived (and therefore don’t need to be persisted anywhere). In addition, all of this happens transparently to the data scientists who simply need to use any standard AWS client (which understands the STS authentication method) to access the data lake.
Integrating with Serverless
When it comes to serving a model, the default way of accomplishing it in Kubeflow is with Kfserving (other approaches are also supported and are described here).
Kfserving is based on Knative, which in OpenShift, is a feature that can be enabled by installing OpenShift Serverless.
Care must be taken when using ServiceMesh and Serverless as some prerequisites must be met in order to have them integrated properly.
In particular, a NetworkPolicy rule must be created in every service mesh namespace to allow traffic from the serverless namespaces to the mesh namespaces.
In addition, because all mesh services in a multi-tenant Kubeflow ecosystem are protected by Istio AuthorizationPolicies and since serverless components are external to the mesh, we need to modify the RBAC policies to allow connections from the Serverless namespaces pods (specifically Kourier and Activator):
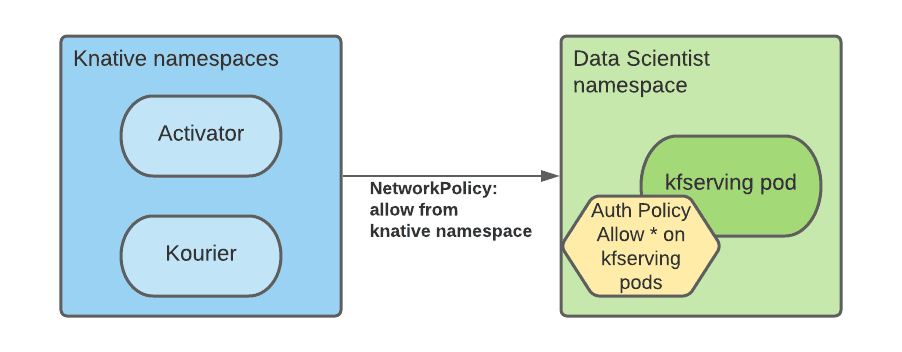
We automated the creation of these rules with the namespace configuration operator, instructing it to add NetworkPolicy and AuthorizationPolicy resources at data scientist namespace creation.
Installation
Step-by-step installation instructions of each of the previously described topics along with their associated configurations are available at this repository. This walkthrough also contains several other minor enhancements and a few examples of AI/ML workloads to validate the setup.
Conclusion
In this article, we have covered several considerations needed to set up a multi-tenant deployment of Kubeflow on OpenShift. This is just the first step in an AI/ML journey, but it should be enough to get started. From here, the data scientist team can start exploring data with Jupyter notebooks and creating data pipelines, which may include training neural network models. When neural network models are ready, Kubeflow can also help with the model serving use case.
It is important to remember that running Kubeflow on OpenShift is currently not supported by Red Hat. Also Kubeflow is a feature-rich product, and as part of this initial deployment, we have not validated that all of the functionalities work correctly (you can see the list of functionalities that were tested in the repo). For example, one important feature that unfortunately is not operationalized at the moment, though may be integrated at a later date, is the entire observability stack that is provided by Kubeflow.
It is the hope that this type of work can be used to jump-start organizations looking to run Kubeflow on OpenShift. In addition, these concepts should provide many of the common primitives that can be used when operationalizing other AI/ML platforms.
About the author
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
From automatic CI/CD to autonomous agentic workflows: Continuous AI with Red Hat OpenShift
Accelerate and upskill with Red Hat AI training and certification
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds