Introduction
In Part 1: How to Enable Hardware Accelerators on OpenShift we gave a high-level overview of the Special Resource Operator (SRO) and a detailed view of the workflow on enabling hardware accelerators.
Part 2 will go into detailed construction of the enablement, and explain which building blocks/features the SRO provides to make life easier.
The most important part is the DriverContainer and its interaction with the cluster during deployment and updates. We will show how we can handle multiple DriverContainer vendors, and how SRO can manage them.
Automatic Runtime Information Injection
Parts of the enablement stack rely on different runtime information which needs to be included in manifests and other resources like BuildConfigs.
SRO will auto inject this information using several keywords that are used as placeholders in the manifests.
We are using golang’s template package to implement data-driven templates for generating textual output.
We have identified the following crucial runtime information that can be used inside the operator to update the resources or in the manifests to be auto injected. Going through the manifests one by one we will see those patterns in action.
{{.RuntimeArchitecture}}For different architectures, one can download different drivers and take different actions. This is based on runtime.GOARCH. We can leverage the templating if clauses to create a mapping e.g.{{if eq .RuntimeArchitecture "amd64"}}x86_64{{end}}Here we create a mapping for the arch=amd64 as exposed by OpenShift and GO to x86_64 the later is more common.{{.OperatingSystemMajor}}Depending on the OS deployed on the workers, SRO will use NFDs features to extract the correct OS version. We are mainly concerned about the major version and hence, we replace this tag either with rhel7, rhel8 or fedora31. One has to make sure that when referencing the files, containers etc. that they actually exist.{{.OperatingSystemMajorMinor}}Sometimes drivers are built for specific minor releases of the operating system. To have more control, one can use this tag to do a fine-grained selection. This results in rhel7.6, rhel8.2 and so forth.{{.NodeFeature}}This is the label from the special resource as reported by NFD, e.g in the case of the GPU it is:feature.node.kubernetes.io/pci-10de.present. We are using this label throughout SRO to deploy the stack only on nodes that are exposing this hardware.{{.HardwareResource}}This is a human-readable name of the hardware one wants to enable. We’re using this with the manifests so that we have unique names for these special resources. The name tag should follow this semantic: <vendor>-<specialresrouce>. In the case of the GPU, we are settingHARDWARE=nvidia-gpuin the Makefile that is used to populate the ConfigMap with the right annotations.{{.ClusterVersion}}Sometimes features are only available on certain versions of the cluster being used to deploy images. See the section about DriverContainer how one would modify the image tag to pull a specific version.{{.KernelVersion}}Building or deploying drivers without knowledge about the current running kernel version makes really no sense. Additionally for the OS the kernel version is used to steer the right drivers or build them on the node.
Attaching Metadata to SRO Resources
Currently, there are two ways to attach metadata to resources in a cluster: (1) labels and (2) annotations. With labels, one can select objects and find collections of objects. One cannot do this with annotations. The extended character set of annotations makes them more preferable to save metadata and since we’re not interested in any kind of filtering of resources. SRO uses annotations to add metadata.
Following a collection of annotations used throughout the operator to enhance the functionality of a specific resource used (DaemonSet, Pod, BuildConfig, etc).
specialresource.openshift.io/wait: "true"Sometimes one needs an ordered startup of resources and a dependent resource cannot start or be deployed before the preceding is in a specific state. This annotation will instruct SRO to wait for a resource and only proceed with the next one when the previous one is in a set state: Pod in Running or Completed state, DaemonSet all Pods in Running state, etc.specialresrouce.openshift.io/wait-for-logs: "<REGEX>"Besides having all Pods of a DaemonSet or Pod in Running state sometimes one needs some information from the logs to say that a Pod is ready. This annotation will look into the logs of the resource and will use the “<REGEX>”to match against the log.specialresource.openshift.io/state: "driver-container"This will tell SRO in which state the resources are supposed to be running. See the next chapter for a detailed overview of the states and validation steps.specialresource.openshift.io/driver-container-vendor: <nfd>We are coupling a BuildConfig with a DriveContainer with these annotations. We are using the NFD label of the special resource to have a unique key for this very specific hardware. In some circumstances, one could have several pairs of BuildConfigs and DriverContainers.specialresource.openshift.io/nfd: <feature-label>This annotation is only valid in the hardware configuration ConfigMap and will be ignored otherwise. The feature label is a unique key for various functions in SRO and is the label exposed by NFD for specific hardware.specialresource.openshift.io/hardware: <vendor>-<device>A human-readable tag, also only valid in the hardware configuration ConfigMap, to describe the hardware being enabled. It is the textual description of the NFD feature-label discussed in the previous point. Used for the naming of all OpenShift resources that are created for this hardware type.specialresource.openshift.io/callback: <function>Sometimes one will need a custom function to enable a specific functionality or to make changes to a resource that are only valid for this manifest. SRO will look for this annotation and execute the <function> only for this manifest.
We are using one label (specialresource.openshift.io/config=true) to filter the hardware configurations during reconciliation which is used to gather the right configs for hardware enablement.
Predefined State Transitions in SRO and Validation
The SRO pattern follows a specific set of states. We have gone into great detail what each of those states is doing in Part 1, but just for completeness, we’re going to list the annotations used in the manifests and add some brief comments to it.
SRO can handle multiple DriveContainers at the same time. Sometimes one needs multiple drivers to enable a specific functionality. SRO will use customized labels for each vendor-hardware combination.
"specialresource.openshift.io/driver-container-<vendor>-<hardware>": "ready"Drivers are pulled or built on the cluster. We can now go on and enable the runtime."specialresource.openshift.io/runtime-enablement-<vendor>-<hardware>": "ready"Any functionality (e.g. prestart hook) needed to enable the hardware in a container is done, move on and expose the hardware as an extended resource in the cluster."specialresource.openshift.io/device-plugin-<vendor>-<hardware>": "ready"The cluster has updated its capacity with the special resource, we can deploy now the monitoring stack."specialresource.openshift.io/device-monitoring-<vendor>-<hardware>": "ready"This is the last state that SRO watches. We can still use the other annotations to wait for resources or inject runtime information beyond this state.
To validate the previous state, the current state resource will deploy an initContainer that executes the validation step. InitContainers run to completion and the dependent Pod will only be started if the initContainer exits successfully. Using this functionality, we have implemented a simple ordering and a gate for each state. We do not have to have a dedicated state for each of the validation steps.
Throughout one state we are using the same name for all different resources. Taking e.g the DriverContainer state the name consists of {{.HardwareResource}}-{{.GroupName.DriverBuild}}. For each state there is a GroupName following the complete list of predefined GroupNames:
GroupName: resourceGroupName{ DriverBuild: "driver-build", DriverContainer: "driver-container", RuntimeEnablement: "runtime-enablement", DevicePlugin: "device-plugin", DeviceMonitoring: "device-monitoring", DeviceGrafana: "device-grafana", DeviceFeatureDiscovery: "device-feature-discovery", },
With all those text fragments and predefined templates, only one has to update the hardware configuration ConfigMap with the right values. Then, SRO takes care of almost “everything”. Next, we have an example of a ConfigMap for GPUs.
Hardware Configuration ConfigMaps
For each accelerator or DriveContainer one has to create their own ConfigMap. Each ConfigMap describes the states that need to be executed to enable this accelerator. Here is an example patch.yaml we use in the Makefile to patch the ConfigMap for the GPU.
metadata: labels: specialresource.openshift.io/config: 'true' annotations: specialresource.openshift.io/nfd: feature.node.kubernetes.io/pci-10de.present specialresource.openshift.io/hardware: "nvidia-gpu"
The Makefile will create the ConfigMap from the files in a subdirectory specially stored for the accelerator <sro>/recipes/nvidia-gpu/manifests and patch the ConfigMap with the correct accelerator configuration.
SRO now knows the label to filter the nodes, annotate the manifests for node selection and how to add the glue between DriverContainer and BuildConfig. Lastly, a human-readable tag is used to identify the hardware by a descriptive name. See the following chapter to see all the information mentioned in the previous chapters that come into play.
Building Blocks Breakdown by State
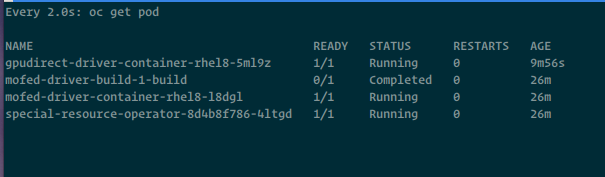
Presumably, vendors are creating prebuilt DriverContainers with a tested configuration between hardware drivers and kernel versions, so SRO need only pull the DriverContainer. If a DriverContainer cannot be pulled, this could mean that for this combination of driver and kernel version, there is no prebuilt DriverContainer; they might be incompatible.
Pulling a prebuilt DriverContainer should always have the highest priority before attempting to build one from the source. This is only a fallback solution, but sometimes it is the only solution; perhaps it is very early on in development, or simply has not established a CI/CD pipeline for automatic builds.
SRO will first try to pull a DriverContainer if it detects an ImagePullBackOff or ErrImagePull it will kick off the building of the drivers via BuildConfig. How SRO knows which BuildConfig to use and how the DriverContainer is annotated will be shown next.
BuildConfig and DriverContainer Relationship
SRO can handle multiple DriverContainer <-> BuildConfig combinations. The annotation to represent this relationship is this:
annotations: specialresource.openshift.io/driver-container-vendor: {{.NodeFeature}}
The {{.NodeFeature}} is populated by the value specialresource.openshift.io/nfd from the ConfigMap. A unique key used to identify the drivers for a specific hardware. Some enablements need more than one driver to enable a specific functionality.
State BuildConfig
Taking a look at 0000-state-driver-buildconfig.yaml one can easily spot the places where SRO will inject runtime information. For every label or name we are appending {{.HardwareResource}} to tag all resources belonging to the special resource we want to enable.
The BuildConfig has to be able to build drivers for different operating system versions. Thus, we inject the operating system into the BuildConfig so when the input source-a github repository-is checked out, the build system knows which directory holds the build data for rhel7 or rhel8.
The resulting image has runtime information injected because we want to make sure that only compiled drivers land on the node that has the right kernel version.
output: to: kind: ImageStreamTag name: {{.HardwareResource}}-{{.GroupName.DriverContainer}}
Last but not least we have the driver container vendor key that is used to match a BuildConfig to a DriverContainer as described above.
State DriverContainer
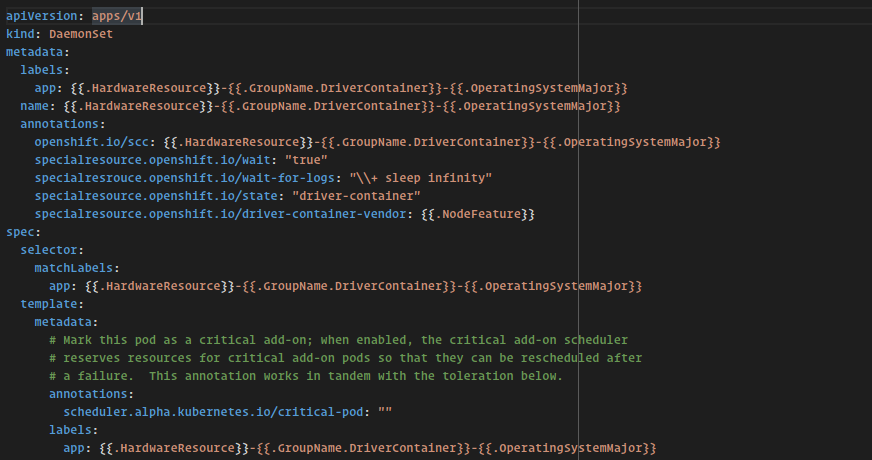
For 0001-state-driver.yaml we follow the same pattern; append the hardware tag to any label or name and try to pull the image the BuildConfig has created.
In disconnected environments, a prebuilt DriverContainer could be pushed to the internal registry to prevent the BuildConfig from being created and the build process started. The BuildConfig installs several RPMs. In future versions of the operator we will support custom mirrors that are located in disconnected environments.
annotations: specialresource.openshift.io/wait: "true" specialresrouce.openshift.io/wait-for-logs: "\\+ wait \\d+|\\+ sleep infinity" specialresource.openshift.io/inject-runtime-info: "true" specialresource.openshift.io/state: "driver-container" specialresource.openshift.io/driver-container-vendor: {{.NodeFeature}}
The DriverContainer uses most of the annotations we have described. Essentially we are saying that the operator is waiting for this DaemonSet that all Pods are in Running state and we are matching the regex in the logs to advance to the next state.
After the DriverContainer is up and fully running, SRO will label the nodes with the provided state from the annotation.
As discussed, the last annotation is used to bond the DriverContainer with the BuildConfig.
nodeSelector: {{.NodeFeature}}: "true" feature.node.kubernetes.io/kernel-version.full:{{.KernelVersion}}
The above snippet shows how the runtime information can be used to run the DriverContainer only on specific nodes in the cluster. (1) Only run the DriverContainer on nodes that have the special resource exposed, (2) place the DriverContainer only on nodes where the kernel version matches. This way we prevent the DriverContainer from running on the wrong node.
State Runtime Enablement
The runtime enablement manifest has two new interesting constructs. The DriverContainer has labeled the node with …/driver-container: ready. The runtime enablement uses nodeAffinity to deploy the Pod only when the drivers are ready.
spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: specialresource.openshift.io/driver-container-{{.HardwareResource}} operator: In values: - ready
Each special resource will have their own set of state labels, this way one can build up a hierarchy of enablements. For example we can enable a dependent driver when driver-container-<vendor-one>-<hardware> is ready.
The second construct is the use of initContainer to run the validation step of the previous state.
spec: initContainers: - image: quay.io/openshift-psap/ubi8-kmod name: specialresource-driver-validation-{{.HardwareResource}} command: ["/bin/entrypoint.sh"] volumeMounts: - name: init-entrypoint mountPath: /bin/entrypoint.sh readOnly: true subPath: entrypoint.sh
Again, we are appending the human readable tag to all names to distinguish the resources belonging to one special resource. The runtime enablement will check if the drivers are loaded for the special resource.
For the entry points for each of the containers we’re using ConfigMaps as entry points that hold bash scripts. This is a very flexible way to adapt or to add commands for the startup.
State Device Plugin
No new features are introduced for the manifests in this state, but lets recap them to see what we’re leveraging here. (1) add special resource specific naming, (2) nodeAffinity on the previous state, (3) initContainer for validation and (4) nodeSelector to only run on a special resource exposed node.
State Device Monitoring, Device Feature Discovery
After exposing the special resource to the cluster via Extended Resource we have only one common dependency of these two states; namely, the readiness of the device plugin. The nodeAffinity of these states are the same, which means they are executed in parallel.
State Grafana
The Grafana state is special because we are using a custom callback that enables Grafana to read the cluster’s prometheus data. This callback is only valid for Grafana, and cannot be generalized to other manifests.
metadata: name: specialresource-grafana-{{.HardwareResource}} namespace: openshift-sro annotations: specialresource.openshift.io/callback: specialresource-grafana-configmap
The specialresource-grafana-configmap is a key into a map of functions. If one wants to have more customer callbacks one has to append the function to the map and annotate the manifest with the corresponding key.
Container Probes
There are currently three probes that the kubelet can react upon. We will shortly discuss why we haven’t used probes in SRO to provide a means of synchronization or a kind of ordering.
- livenessProbe If this probe fails, the kubelet kills the Container and, according to the restart policy, an action is taken. This probe cannot help us in the case of SRO regarding synchronization or ordering.
- readinessProbe This probe indicates if a Container can service requests. If this fails, the IP addresses are removed from the endpoints. A readiness probe cannot be used in SRO in a general way because almost all driver and similar containers do not provide any (externally) accessible service.
- startupProbe The thought behind using this probe was to signal SRO as to the readiness of an application within the Container. The only problem is that, despite the state of the application, the status of the Pod is always Running. If the probe fails, the Container is killed. We cannot deduce any readiness of the application within that container.
To truly know if a specific application in a Container is really ready, one must look for the Running phase and examine the logs. Some applications are really fast, and keeping an eye on the Running status of a Pod is, in most cases, sufficient.
Future Work
In this part of the second blog, we discussed in detail the building blocks of SRO and how one can use these to enable their own accelerator. One important factor missing is how to use SRO in disconnected environments with or without a proxy.
Stay tuned for part three discussing the open points and a new accelerator that we enabled with SRO.