RFC2544 is an established industry benchmarking methodology utilized to assess performance metrics of network devices, including throughput, latency, and packet loss.
This blog will concentrate on RFC2544 throughput tests and offer insights into optimizing the test results.
Test topology and toolings
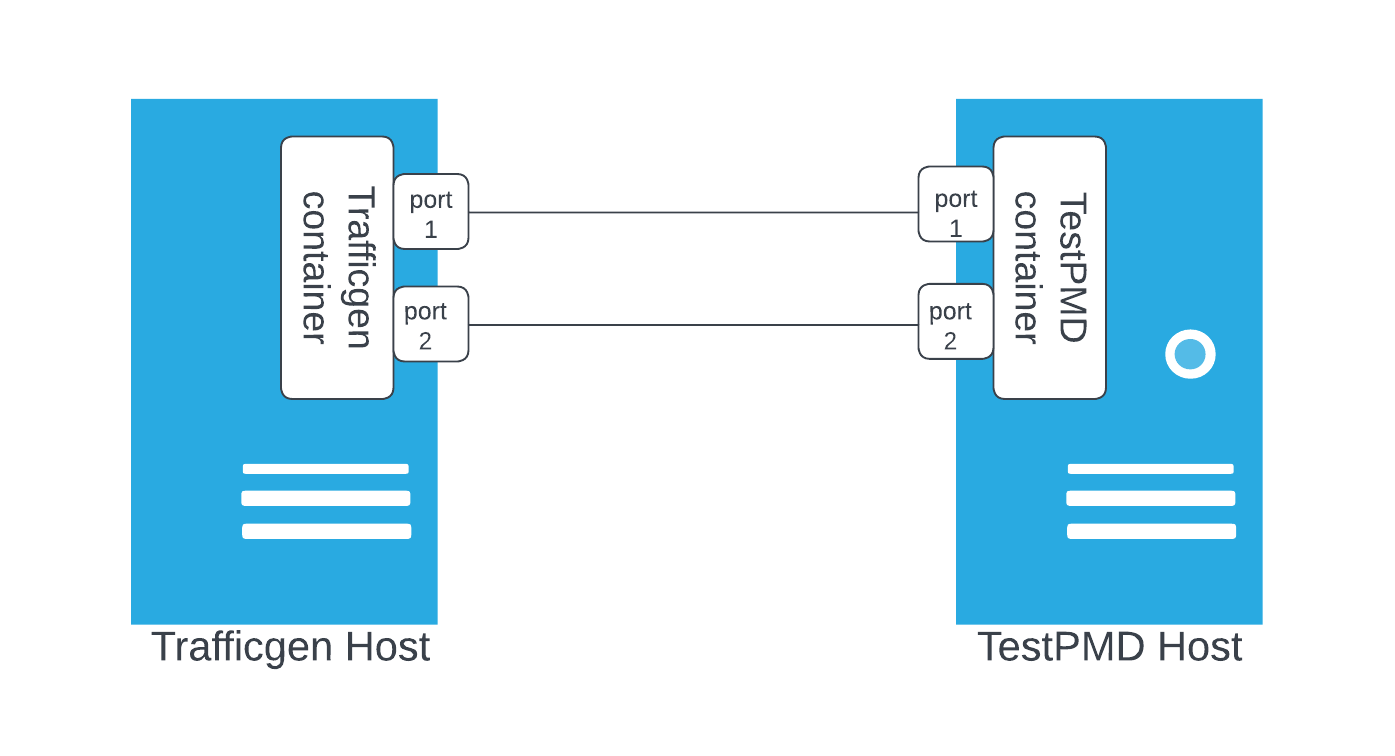
In this testing setup, the host housing the TestPMD container serves as the device under test (DUT). This DUT operates on a single-node OpenShift (SNO) installation.
The Trafficgen container operates on a host equipped with RHEL 8.6.
Readers interested in replicating the process can refer to the instructions in this repository to construct their own test images and execute the RFC2544 test.
The SNO manifests necessary for configuring the system to run the TestPMD container are located in the same repository.
Abundant information regarding these manifests is available in the official OpenShift documentation. Instead of replicating this information, the emphasis will be solely on delving into the challenges we faced while conducting RFC2544 tests within the OpenShift environment.
Noisy neighbor problem
The DPDK worker threads run in the poll mode, and each worker thread expects to take the full core CPU time. When hyperthreading is enabled, a worker thread assigned to an isolated CPU is not necessarily assured with the full core CPU time, as the sibling CPU thread of the isolated CPU can be allocated to other threads and share the same core with the DPDK worker thread. When this happens, the performance of the DPDK worker thread running on a CPU will be impacted. This is referred to as the noisy neighbor problem.
The Kubelet's CPU manager should activate the full-pcpus-only policy to address this issue. When this policy is enabled, the static policy allocates complete physical cores. Consequently, the sibling threads are exclusively reserved, prohibiting any other containers from running on them.
The following performance profile setting will activate the full-pcpus-only policy:
spec:
numa:
topologyPolicy: "single-numa-node"
Alternatively, if there's a specific need to employ the restricted topology policy, it's possible to configure the full-pcpus-only setting explicitly.
metadata:
annotations:
kubeletconfig.experimental: "{\"cpuManagerPolicyOptions\": {\"full-pcpus-only\": \"true\"}}"
spec:
numa:
topologyPolicy: restricted
Users can log in to the node once the performance profile has been applied and the system has completed the necessary reboots. They should then review the contents of /etc/kubernetes/kubelet.conf to confirm that the intended policy is correctly configured. If the performance profile is not functioning as expected, this file will not reflect the appropriate policy settings.
The full-pcpus-only policy assures that a container occupies complete CPU cores. However, to entirely mitigate the noisy neighbor issue, the application must retain control over CPU allocation. For instance, if a DPDK worker thread utilizes CPU 4, the DPDK application should take measures to prevent its other threads from executing on the sibling of CPU 4, such as CPU 36. This provides the intended isolation of resources.
This noisy neighbor problem does not exist if the hyperthreading is disabled.
To achieve the highest throughput performance in the OpenShift (or Kubernetes) environment, a DPDK application must exhibit CPU awareness by effectively binding threads to individual cores according to the CpuSet assigned to the container. There are two approaches to achieving CPU awareness: integrating it directly into the application's code or utilizing a wrapper. The wrapper approach enables CPU-aware behavior without requiring any modifications to the application itself. We implemented a wrapper for TestPMD. This wrapper manages CPU pinning for TestPMD without altering the core functionality of TestPMD itself. Additionally, the wrapper incorporates a REST API, which allows for control and querying of TestPMD operations. While the details of utilizing this API fall outside the scope of this blog, readers keen on exploring it further are encouraged to refer to the documentation provided in the repository.
CPU quota problem
In a DPDK application pod spec, users very often use whole numbers to indicate the required CpuSet, as seen in the example below:
spec:
containers:
resources:
limits:
cpu: "6"
requests:
cpu: "6"
The cpu limits is a CPU quota, even though the entire CPU is already allocated to the container. The CPU quota can lead to the throttling of the application.
Here is a sign that the DPDK worker threads are being throttled:
![]()
Without throttling, the CPU utilization by the DPDK worker threads should have reached 100%.
Another way to observe that a container is being throttled is to examine the cpu.stat content under /sys/fs/cgroup/cpu,cpuacct/kubepods.slice/. Here is an example:
# cat /sys/fs/cgroup/cpu,cpuacct/kubepods.slice/kubepods-podd2709cbe_ad24_4cab_83ae_a3b395f00866.slice/cpu.stat
nr_periods 60582
nr_throttled 31857
throttled_time 4792267674277
The following is the relevant pod specification utilized to disable the CPU quota for the pod:
metadata:
annotations:
cpu-quota.crio.io: "disable"
spec:
runtimeClassName: performance-performance
To find the right runtimeClassName, use the following command:
oc get performanceprofile performance -o yaml | grep runtimeClass
While confirming the correct configuration is vital, it doesn't inherently mean the deactivation of CPU quotas. A notable instance of this occurred during the transition from cgroup v1 to cgroup v2 in CRI-O. Initially, the implementation to disable CPU quotas on a per-pod basis was absent, resulting in performance deterioration during RFC2544 testing. Notably, versions such as 4.13.0 exhibited RFC2544 throughput issues stemming from CPU quotas.
The significance of the RFC2544 performance was affirmed through our ability to identify performance degradation during the throughput test. This allowed us to trace the problem back to the missing CRI-O implementation, further underscoring the value of RFC2544 in pinpointing performance challenges.
Inspect the CRI-O log to verify whether CRI-O is genuinely attempting to disable the CPU quota. By logging into the node and reviewing the output using the command journalctl -u crio, you can observe relevant information. When the DPDK container initiates, CRI-O should generate a message akin to Disable cpu cfs quota for container… indicating the action taken.
Apart from deactivating the pod CPU quota and ensuring that CRI-O effectively enacts this action upon pod startup, disabling IRQ load balancing and CPU load balancing via pod annotations is equally crucial. Additionally, it's recommended to decrease network queues using the userLevelNetworking setting within the performance profile. I recommend the OpenShift official performance tuning guide for a comprehensive understanding.
Wrap up
This blog aims to present the most significant challenges we faced during an RFC2544 test rather than offering an exhaustive list of issues. While it doesn't encompass all possible problems, the blog sheds light on the intriguing obstacles we encountered. The information we share is intended to assist individuals in gaining insight into these challenges and discovering and resolving them effectively.
Furthermore, the test tools and manifests discussed in this blog are tailored to meet our specific testing goals and yield positive outcomes, so they may not constitute a universally applicable standard.
About the author

More like this
The agentic paradox and the case for hybrid AI
Context-aware advisor recommendations in Red Hat Lightspeed
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds