This is a guest post written by Jonathan Katz of Crunchy Data.
One reason why enterprises adopt open source software is to help free themselves from vendor lock-in. Cloud providers can offer open source “as-a-service” solutions that allow organizations to take advantage of open source solutions, but this in turn can create a new type of trap: infrastructure lock-in.
Many organizations have adopted Kubernetes to give themselves flexibility in where they can deploy their services in the cloud, without being locked into one provider. Some people express concerns that this instead creates “Kubernetes lock-in,” but because Kubernetes is open source and has both widespread support and active development, it should be no different than adopting Linux as your operating system.
An advantage of running an enterprise Kubernetes platform such as Red Hat OpenShift, and by association, using a Kubernetes Operator, is that it can give you the opportunity to run your own “as-a-service” solutions for stateful workloads without being locked into a single cloud vendor. To take this a step further, you can deploy your database where you have a Kubernetes node hosted, which means you can now run your own database-as-a-service. As the number of databases your team needs to manage increases, the value of having an Operator available can become even greater.
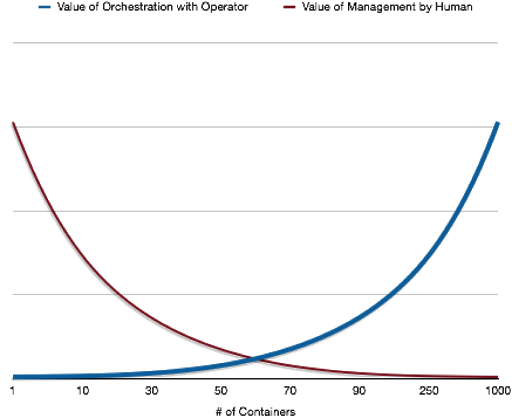
As an example for how an Operator provides value, imagine that you have added a new database administrator to your team to help manage a 600 node PostgreSQL cluster running different versions of PostgreSQL. Before you give them full access to your cluster, you want to provide them with read-only access to all 600 databases. You could try to do this manually for each cluster (which is likely not feasible) or write a script to accomplish this task, though your script would have to account for any differences in user management between versions. Instead, using an Operator that is aware of the nuances of managing a PostgreSQL cluster can provide you a standard interface to accomplish this task from a few commands that can both save time and correctly accomplish the task.
The team at Crunchy Data has been working with container technology for over six years, and were early adopters of the Operator pattern. Using our expertise on building out large scale PostgreSQL deployments, in March of 2017, we launched the open source Crunchy PostgreSQL Operator to give you a cloud-native, PostgreSQL-as-a-service that you can deploy to infrastructure.
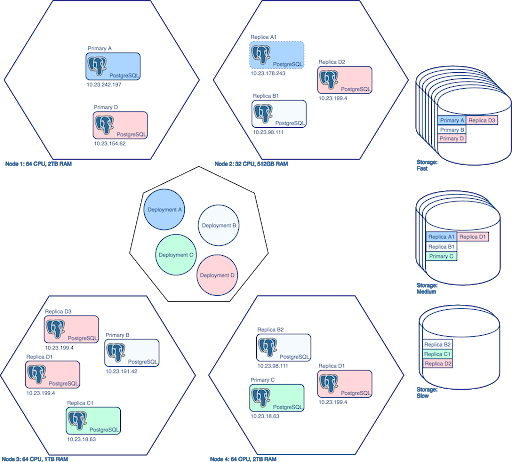
The Crunchy PostgreSQL Operator is designed for flexibility: beyond having features often expected in an enterprise database environment (elasticity, high-availability, disaster recovery, monitoring), the Operator leverages Kubernetes deployments so you can customize:
- Node affinity: You can direct the Operator to deploy to your super performant on-premise hardware, to a cloud-based system, or some combination of both, on a per-database basis. You can also let the Operator decide where to deploy your workloads!
- Resource allocation, e.g. memory & CPU utilization, on a per-database basis. Your primary and replica databases can have different resource profiles within a cluster.
- Storage classes: You can set different primary databases to use different storage classes; a primary can use different storage than a replica.
- Labels and namespaces let you group applications or workgroups together for easier administration, such as upgrades, backups, or user access control.
- Versions and Upgrading: Run the version of PostgreSQL that you need, including the newly released PostgreSQL 11 while only upgrading the clusters that you choose.
- User access: Based on Crunchy Data’s roots in more secure PostgreSQL deployments, we designed the Crunchy PostgreSQL Operator so you can manage users and database-specific access policies with more simple commands.
For example, here are a few commands that will let you build a highly-available PostgreSQL cluster that sets up a robust disaster recovery solution and applies security policies across the project, using pgo - the Crunchy PostgreSQL Operator CLI tool:
# create a cluster named "webapp" for the "www" project that has HA/DR,
# where the primary uses the fast storage and the replicas use
# medium speed storage; the CPU/memory resources fit the "large" profile
pgo create cluster webapp \
--labels=project=www \
--pgbackrest \
--autofail \
--storage-config=fast \
--replica-storage-config=medium \
--resources-config=large
# add two replicas to the "webapp" cluster
pgo scale webapp --replica-count=2
# perform a full backup on the "webapp" project using pgBackRest
pgo backup webapp --backup-type=pgbackrest --storage-config=dr1
# create a user that can access the "webapp" cluster with secrets managed by
# the Operator
pgo create user webappuser --selector=name=webapp --managed
# create and apply a security policy that will be used for the "www" project
pgo create policy wwwpolicy1 --in-file=/tmp/www1.sql
pgo apply wwwpolicy1 --selector=project=www
What’s more, the Crunchy PostgreSQL Operator works within a Red Hat OpenShift environment and lets you connect your other OpenShift applications to create a scalable, highly-available PostgreSQL deployment. We have demonstrated how to create a highly-available PostgreSQL deployment to power Red Hat Ansible Tower.
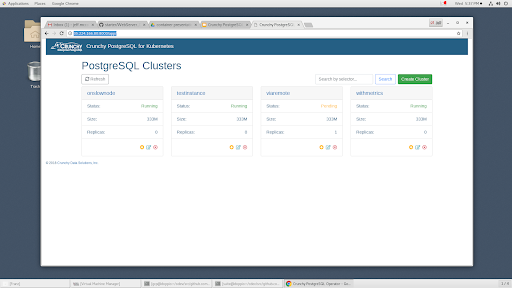
Engineering teams have adopted the Crunchy PostgreSQL Operator to manage their PostgreSQL workloads. Since Red Hat’s announcement of the Operator SDK, we are continuing to add the enterprise features one would expect, including a user interface:
The Crunchy PostgreSQL Operator can let you deploy PostgreSQL to cloud-enabled environments without the worry of infrastructure lock-in, and can help your data meet your compliance and security requirements. For more information on commercial support for the Crunchy PostgreSQL Operator, please visit crunchydata.com/products/crunchy-postgresql-for-kubernetes/
About the author

Red Hatter since 2018, technology historian and founder of The Museum of Art and Digital Entertainment. Two decades of journalism mixed with technology expertise, storytelling and oodles of computing experience from inception to ewaste recycling. I have taught or had my work used in classes at USF, SFSU, AAU, UC Law Hastings and Harvard Law.
I have worked with the EFF, Stanford, MIT, and Archive.org to brief the US Copyright Office and change US copyright law. We won multiple exemptions to the DMCA, accepted and implemented by the Librarian of Congress. My writings have appeared in Wired, Bloomberg, Make Magazine, SD Times, The Austin American Statesman, The Atlanta Journal Constitution and many other outlets.
I have been written about by the Wall Street Journal, The Washington Post, Wired and The Atlantic. I have been called "The Gertrude Stein of Video Games," an honor I accept, as I live less than a mile from her childhood home in Oakland, CA. I was project lead on the first successful institutional preservation and rebooting of the first massively multiplayer game, Habitat, for the C64, from 1986: https://neohabitat.org . I've consulted and collaborated with the NY MOMA, the Oakland Museum of California, Cisco, Semtech, Twilio, Game Developers Conference, NGNX, the Anti-Defamation League, the Library of Congress and the Oakland Public Library System on projects, contracts, and exhibitions.
More like this
A decade of open innovation: Red Hat continues to scale the open hybrid cloud with Microsoft
Stop managing the past and start building IT’s future
Kubernetes and the quest for a control plane | Technically Speaking
Get into GitOps | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds