
Introduction
On the wave of the successes attained with stateless workload with regards to multi-data center active/active deployments and uptime, expectations are rising for stateful workloads too.
In particular, it is becoming more and more common for IT organizations to want to deploy their stateful workloads with multi-data center, active/active, always-available and always-consistent configurations.
In this blog post we will see that if the requirement is to deploy a stateful workload so that it is available and consistent even during a disaster scenario, then it is necessary to have three data centers.
Conventionally we define as stateful workloads all those pieces of software or applications that in some way manage a state. Typically state is managed in storage and middleware software such as software defined storage, databases, message queue and stream systems, key value stores, caches etc… . This definition is similar to the one adopted by the Storage Landscape whitepaper published by the CNCF storage SIG.
High Availability and Failure
High Availability (HA) is a property of a system that allows it to continue performing normally in the presence of failures. Normally, with HA, it is intended the ability to withstand exactly one failure. If there is a desire to withstand more than one failure, such as two, it can be written as HA-2. Similarly, three failures can be written as HA-3.
The concept of Availability for a system has its roots in mechanics and electronics engineering (in those disciplines, it is known as reliability) and the science and math behind it is consolidated at this point. Given the Mean Time Between Failures (MTBF) of each individual component, one can calculate the MTBF of the entire system by applying a set of formulas. Redundancy of each component is the key to achieving HA.
The foundational idea of HA is that the Mean Time to Repair (MTTR) a failure must be much shorter than the MTBF (MTTR << MTBF), allowing something or someone to repair the broken component before another components breaks (two broken components would imply a degraded system for HA-1).
It is often understated that something needs to promptly notify a system administrator that the system has a broken component (by the very same definition of HA one should not be able to notice that by the normal outputs of the systems).
This means we need a good monitoring and alerting systems. Without it, an HA system would just keep working until the second failure occurs (~2xMTBF) and then still be broken, defeating the initial purpose of HA. Unfortunately, there are still a significant number of organizations that primarily put effort and resources in designing and building HA systems, without having solid monitoring systems.
With regards to stateful workloads, HA implies that one needs multiple instances (at least two) of each workload and that the state that these instances manage needs to be replicated between them. Usually, some kind of heartbeat ensures the peers are alive and some kind of gossip protocol ensures state is synchronized and consistent across all of them.
If, for example, one builds a stateful system with two instances and instance A suddenly cannot contact instance B, instance A will have to make a decision on whether to keep working or not. Instance A cannot know whether instance B is down or healthy-but-unreachable. It could also be that instance A is the one that is unreachable. In practice, in a distributed system, failures are indistinguishable from network partitioning where the presumably failed component has become unreachable due to a network failure.

If a piece of software is designed to keep working when the peers are unreachable, its state may become inconsistent. On the other hand, if a piece of software is designed to stop when the peers is unreachable, then it will maintain consistency, but will not be available.
The CAP Theorem
This situation is formalized in the CAP theorem. Simply put, the CAP theorem states that a stateful workload in case of network partitioning (P) can choose between consistency (C) (as in the integrity of the data) or availability (A), but cannot have both.
During a network partition, the stateful workload will need to work in a degraded state: normally either read-only if the application chooses consistent, or inconsistent if the application chooses availability.
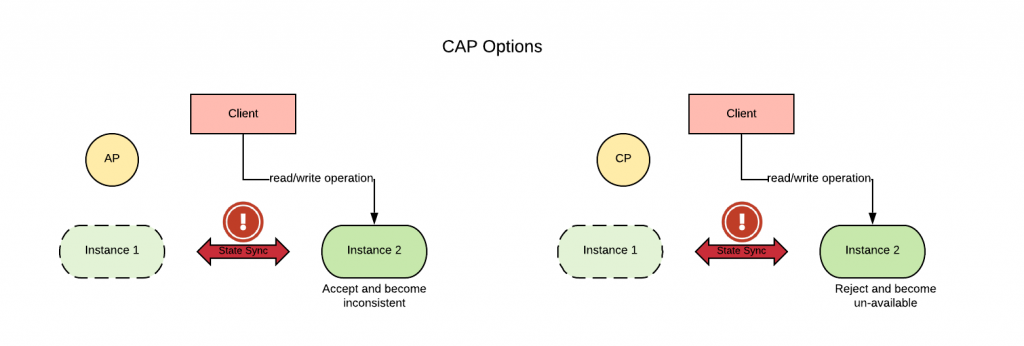
A corollary of the CAP theorem called PACELC (Partition? Availability or Consistency, Else? Latency or Consistency) states that under normal conditions (absence of a network partition), one needs to choose between latency (L) or consistency (C). That is to say that under normal circumstances one can optimize for either speed or consistency of the data, but not for both.
Sometimes consistency is not a strict requirement. Eventually consistent databases (mostly belonging to the NoSQL class of databases) are an example of this type of software.
Note that eventual consistency does not imply eventual correctness; it simply means that eventually, all instances will present the same state. Usually, a conflict resolution algorithm decides which state to keep if two instances have different states. During the lapse of time while the state was inconsistent, the application using the stateful workload may have made wrong decisions that altered the state to also be incorrect, and these situations cannot be reconciled by the conflict resolution algorithm.
The following list illustrates some stateful workload and their choice in terms of PACELC Theorem:
- DynamoDB: P+A (on network partitioning, chooses availability), E+L (else, latency)
- Cassandra: P+A, E+L
- MySQL Cluster: P+C, E+C
- MongoDB: P+C, E+C
Source wikipedia, see the link for a more stateful set examples.
Most SQL databases are absent from this table, but you can assume they choose consistency over the other alternatives, as this is required by the ACID property of RDBMS.
Most stateful workloads (and in particular databases) also employ partitions or shards to increase throughput.
Partitions
Partitions, or shards, are a way to increase the general throughput of the workload. Usually, the state space is broken into two or more partitions based on a hashing algorithm. The client or a proxy decides where to send requests based on the computed hash. This dramatically increases horizontal scalability, whereas historically for RDBMS, vertical scaling was often the only practical approach.
From an availability perspective, partitions do not have a significant impact. Each partition is an island, and the same availability considerations that apply to a non-partitioned database also apply to each individual partition. Stateful workloads can have replicas of partitions which sync their state to increase the availability of each individual partition.
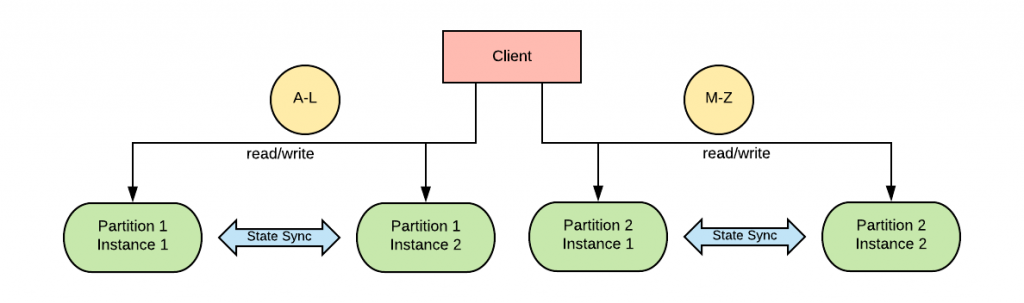
Partitions, however, while allowing for horizontal scalability, introduce an additional complication which is the need to maintain consistency between them. If a transaction involves multiple partitions, there needs to be a way to make sure that all of the involved partitions are coordinated into participating in their portion of the transaction.
Partitions are widely adopted by modern databases and while not contributing to the availability discussion, need to be taken into consideration, especially with regard to the multi-partition consistency issue.
So, with replicas and partitions running in separate processes and needing some level of synchronization, how can there be a reassurance that the workload is highly-available and the state remains consistent?
Consensus Protocols
A consensus protocol allows a set of peers to agree on a shared state. An ingredient of consensus protocols is a leader election process, which, based on the strict majority of the members of the stateful workload cluster, designates a leader that is the ultimate and undiscussed owner of the state.
As long as the strict majority of the elements of the cluster can talk to each other, the cluster can continue to operate in a non-degraded state (without violating the CAP theorem). This results in a stateful system that is both consistent and available, while sustaining a number of failures.
In a cluster of two, if a member is lost, the remaining member does not represent the strict majority. In a cluster of three, if a member is lost, the two remaining members do represent the strict majority. As a consequence, for a stateful workload that implements a leader election protocol there must be at least three nodes to preserve availability and consistency in the presence of one failure (HA-1).
As of today, there are two main generally accepted consensus algorithms based on leader election:
- Paxos Generally considered very efficient, but arcane to understand and complex to deal with in real life corner cases.
- Raft, Generally considered easy to understand and code in a real life scenario, even though less efficient.
Most of the new stateful software tends to be based on Raft as it is simpler to implement.
Leader election-based consensus protocols work well when a set of peers need to agree on the same set of operations. But when the different participants need to perform different operations, and they just need to agree on committing to those operations or not, a different family of consensus protocol is used: the two-phase commit (2PC) protocol and derivatives.
In the two-phase commit protocol, a coordinator orchestrates a set of resources into either all commit or abort a transaction in which each participant needs to perform a different task. The two-phase commit protocol has several limitations amongst which:
- All participants must be available for it to succeed (we needed only the strict majority for the leader election-based protocol)
- The coordinator is a single point of failure and if it fails in the middle of a transaction, the participant may end up never completing (either committing or aborting).
The two-phase commit protocol is suitable to coordinate transactions that involve multiple partitions.
The following are examples of stateful workloads and their use of consensus algorithms (this information is not always easy to uncover, what follows is based on my personal research and could be inaccurate):
- Etcd: Raft, no partitions
- Consul: Raft, no partitions
- Zookeeper: ZooKeeper Atomic Broadcast (a derivative of Paxos), no partitions
- Elasticsearch: Intra-partition: Paxos, (no Multi-partition consistency?)
- Cassandra: Intra-partition: Paxos, (no Multi-partition consistency?)
- CockroachDB(1): Intra-partition: Raft, Multi-partition: 2PC
- YugaByte-DB(1): Intra-partition: Raft, Multi-partition: 2PC
- TiKV: Intra-partition: Raft, Multi-partition: Percolator
- FaunaDB(2): Calvin (Multi-partition version of Raft)
- Nats: Raft, no partitions
- Spanner(1): Intra-Partition raft, Multi-Partition 2PC + high precision time service
(1) Some claims that CockroachDB and YugaByte-DB are not fully consistent can be found here. The argument basically says that in order to ensure serializability isolation-level, a mechanism to achieve a total order or events is needed. Spanner does that with a high-precision clock that is available only in Google datacenters. YougaByteDB and CockroachDB can only approximate that service. The author proposes Calvin as a solution to these problems.
(2) A counter argument that Calvin is not usable for enterprise use cases can be found here.
In general, consistency across partitions with off-the-shelf infrastructure seems to be where the frontier of the theoretical research is headedhas gotten to at this point in time.
Failure Domains
While it is useful to assume (as we do when we design for HA) that individual components will fail in isolation, this is often not the case. Multiple components may fail altogether. Failure domains are areas of an IT system in which all the components inside that area may fail all at the same time.
Examples of failure domains are: pods, nodes, racks, entire kubernetes clusters, network zones and datacenters.
As one can see from these examples, failure domains exist at different scales.
When designing a Highly Available system (HA), one considers the smallest scale: component level and, generally speaking, one makes all components redundant.
However, one should not lose track of the higher scale failure domains. For example, there may be several instances of an application, but if all those instances run on the same rack, there is still a single event that can take the application down.
Applying this same line of reasoning to stateful workloads, one should ensure that workload instances run in different failure domains, irrespective of the scale. If there is a need for consistency and availability at the same time, stateful workloads should be run in at least three different failure domains.
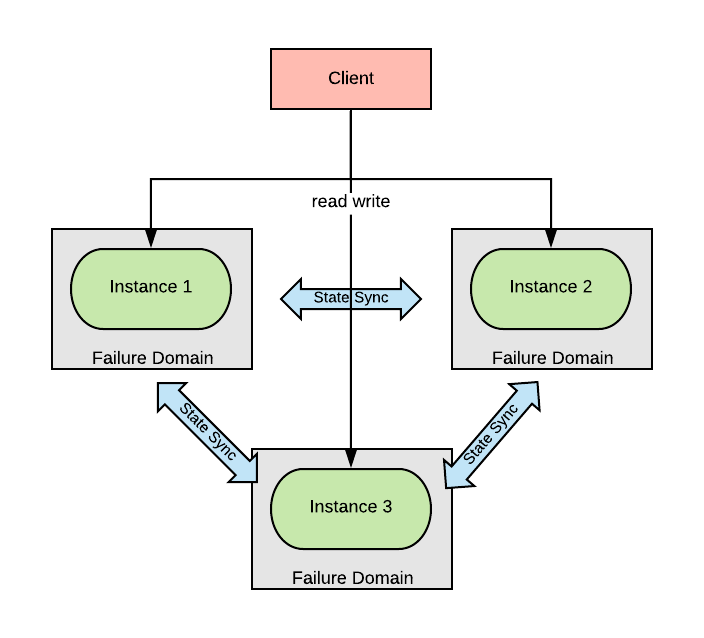
In Kubernetes, there are standard node labels (failure-domain.beta.kubernetes.io/region , failure-domain.beta.kubernetes.io/zone) to capture the idea of failure domains in a cluster. Designers of stateful workloads should consider creating anti-affinity rules based on those labels when packaging their software to be deployed in kubernetes.
Disaster Recovery
Disaster recovery (DR) normally refers to the strategy for recovering from the complete loss of a datacenter.The failure domain in this situation is clearly the entire datacenter.
Disaster recovery is usually associated with two metrics:
- Recovery Time Objective (RTO): the time it takes to have the systems back online after a datacenter fails.
- Recovery Point Objective (RPO): how far back in time the state will be from the time the datacenter fails.

In the old days, these metrics were measured in hours and users followed a set of manual steps to recover a system.
Most DR strategies employed an active/passive approach, in which one primary datacenter was handling the load under normal circumstances and a secondary datacenter was activated only if the primary went down.
But having an entire datacenter sitting idle was recognized as a waste. As a result, more active/active deployments were employed, especially for stateless applications.
With an active/active deployment, one can set the expectations that both RTO and RPO can be reduced to almost zero, by virtue of the fact that if one datacenter fails, traffic can be automatically directed to the other datacenter (though the use of health checks). This configuration is also known as disaster avoidance.
Today, some companies have the expectation to implement disaster avoidance for stateful workloads.
Based on the above discussion, if one wants to deploy a stateful application in such a way that is both highly available and consistent, one needs three failure domains and in the case of DR, three datacenters.
And therein lies the two data center conundrum.
The Two Data Center Conundrum
Some companies have two datacenters. In many cases, the second datacenter was built in the last fifteen years and was a conspicuous capital investment.
Based on my observations, these datacenters are sometimes not fully symmetrical. In some cases, the second datacenter (beside being the secondary in the active/passive DR strategy) is also used to run stateless workload in an active/active manner or run some lower/non-production environments.
As these companies try to deploy stateful workloads in a highly available and consistent fashion, they will realize the limitations posed by two datacenters in this context and they will have some decisions to make:
- One may compromise on availability. This implies accepting an RTO and RPO greater than zero and an active/passive DR strategy most likely involving some manual steps.
- One may compromise on consistency. This would result in deploying an eventually consistent stateful workload.
- If both availability and consistency are needed, then a third data center is necessary. This can be achieved by building a new datacenter or using the cloud as a third datacenter.
Given how capital intensive it is to stand up a new datacenter, the last option, in which the cloud is used as a third failure domain, seems to be the most likely solution especially if there is a cloud region in proximity to existing datacenters.
Conclusions
As described, uptime and consistency requirements for stateful workloads may result in significant cost implications, such as the need to run workloads in three datacenters.
It is the hope that this article will serve as a base for discussing how to deploy a stateful workload on multiple datacenters. Some of the questions that should guide the discussion are:
- Do I need consistency: availability or both (there is a price for everything)?
- Do I need partitioning for horizontal scalability?
- Which concuns protocol is used and when?
- Which level of performance do I need?
The relative simplicity that allows for the deployment to three datacenters in the cloud is putting pressure on traditional two-data center infrastructures as well as on traditional monolithic stateful software that does not use a leader election consensus protocol. A new generation of databases and stateful software (mostly an offspring of the Google Spanner) is getting traction and soon will be ready for mainstream enterprise deployments.
About the author
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
How Red Hat OpenShift 4.22 impacts enterprise AI’s bottom line
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds