It Started with Developers
Developers were the first adopters of containers for application creation. Now that containers have made their way into production environments, operations teams are starting to look deeper at what benefit they bring. Deployments are a key focus not just because the container model is so different, but also because there are automation integration points that have been previously unavailable.
Release engineers are faced with a tough question: continue to do rolling style updates as they always have or move to a red/black deployment model. Both have their pros and cons but using containers with red/black deployment methods provides
a one-two punch that operations teams are looking for.
Rolling Upgrade
In a traditional non-container environment, updates that happen on an existing system result in it being in an unknown state while the upgrade is happening. Most QA teams don't spend as much time on testing during an upgrade, instead focusing on before and after. Upgrades are fine but as time goes on, cruft is often left around. Perhaps an old config file that’s no longer needed, cache directory changes, etc.
Lets look at a code deployment with system updates in an environment that runs configuration management while trying to optimize for no downtime:
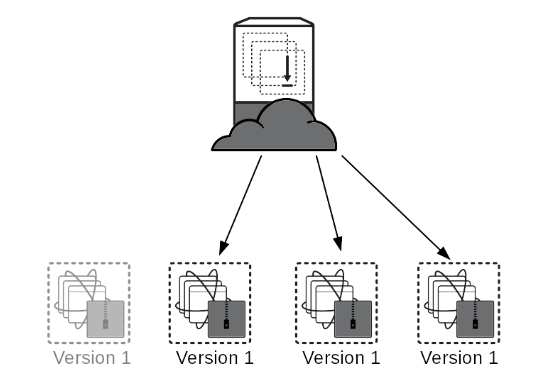 Take your running cluster and upgrade each component one by one. In this case the load balancer is pointing to every version. Select one of them and stop sending production traffic to it.
Take your running cluster and upgrade each component one by one. In this case the load balancer is pointing to every version. Select one of them and stop sending production traffic to it.
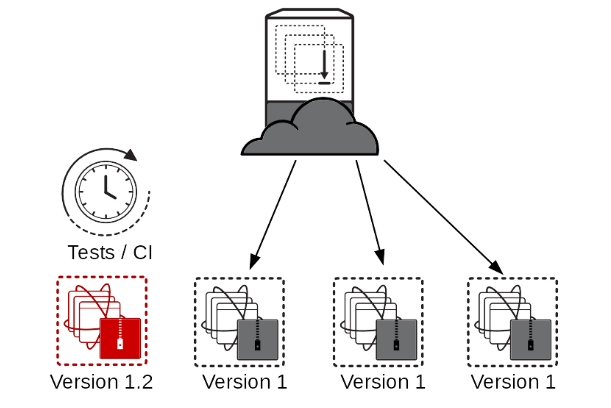 Once traffic stops, upgrade the unused cluster member then run whatever tests need to be run.
Once traffic stops, upgrade the unused cluster member then run whatever tests need to be run.
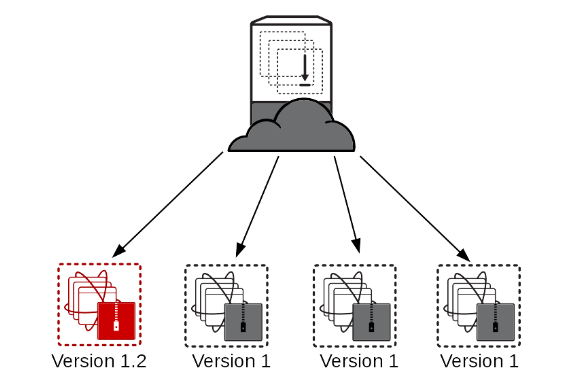 Once all tests pass, add the new member back to the load balancer and start sending production traffic to it.
Once all tests pass, add the new member back to the load balancer and start sending production traffic to it.
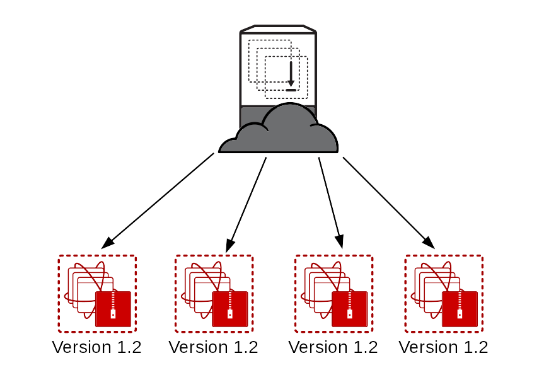 Repeat until the entire cluster is upgraded and getting production traffic.
Repeat until the entire cluster is upgraded and getting production traffic.
Depending on the size of the environment and the size of the update, this can take minutes to hours. The real risk here is deciding what to do if one of the steps fails. What do you do if configuration management hangs or if the tests don’t succeed. For large production sites who might run these updates with a skeleton crew at 2:00 am, there aren't a lot of options.
Pick up the phone and page out to the engineering manager whose team created the code or try to rollback. In a traditional RPM environment, rollbacks can be possible for those that have the old RPMs available but in practice I’ve found the rpm rollback system to be unreliable.
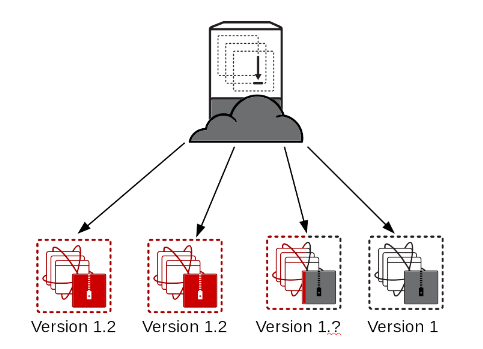 This failed upgrade is an example of a worst case scenario for deployments and likely a late night for dev and ops alike.
This failed upgrade is an example of a worst case scenario for deployments and likely a late night for dev and ops alike.
Remember, the longer it takes to go from the very first upgrade step to the very last, the higher likelihood something will go wrong because of hardware failure, user error, or something else. The better option and our next topic for those that can pull it off is red/black.
Red Black Deployments
I first learned about red/black deployment options at a technology conference from Netflix. They use this same methodology for their global infrastructure. Here is an interesting blog post about it - http://techblog.netflix.com/2013/08/deploying-netflix-api.html. The approach is fairly straight forward, create a new system and leave the old system alone. Send production traffic to the new system only after it’s up and in a known, confirmed state. The big benefit here is no changes to the ‘production’ environment happen until the new environment is confirmed good. There’s far less risk.
The drawback is the need for extra capacity to create this new environment. Using a public or private cloud provider is one way to make sure the extra capacity is there when it's needed. The basic workflow looks like this:
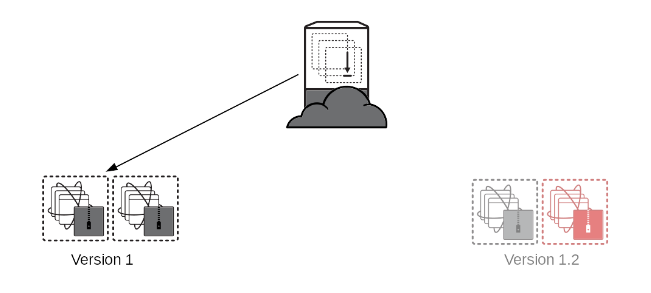 With the load balancer sending all traffic to version 1, bring up version 1.2.
With the load balancer sending all traffic to version 1, bring up version 1.2.
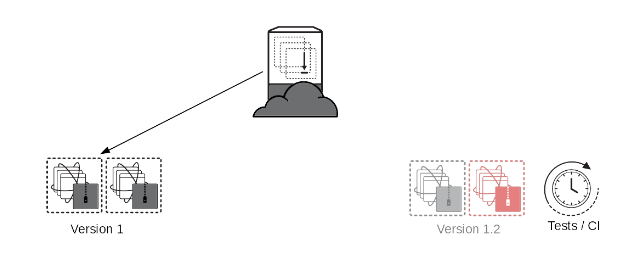 Next, do all of your testing on version 1.2 while the current production site stays unaltered.
Next, do all of your testing on version 1.2 while the current production site stays unaltered.
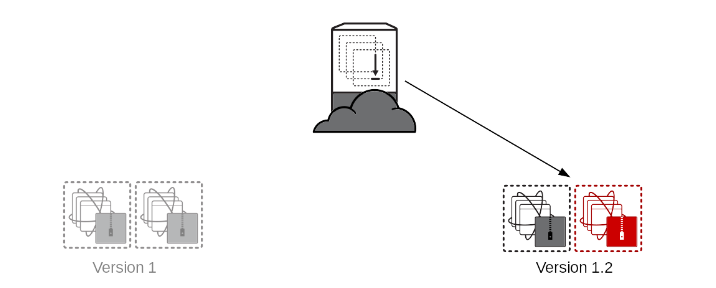 Once the tests succeed, change the load balancer to point to the new version.
Once the tests succeed, change the load balancer to point to the new version.
 Remove version 1.0 entirely and prepare to do the same thing when version 1.3 is ready.
Remove version 1.0 entirely and prepare to do the same thing when version 1.3 is ready.
Companies that are good at red/black have the process mostly automated and use the same scripts in their pre-production environments. It has a larger upfront cost but the long term payoff is huge since changes carry much lower risk. Unlike in a rolling upgrade, if something goes wrong during the deployment, stopping and deleting the new systems is always an option.
Even with the best testing, things can go wrong after deployment and a rollback may be required. Containers make this easy and we’ve brought similar tools to the operating system with Project Atomic. Red/Black deployments can be done throughout the entire stack with Atomic and Docker. This gives release engineers total control over automating their environments while giving them the ability to truly roll-back.
Comments About Continuous Delivery
Integrating a red/black deployment with a continuous delivery system provides the ultimate agile experience. Companies who have achieved this level of automation are known for doing hundreds of deployments per day. This is significantly more often than some enterprises who can only muster a deployment every couple of months. Being able to make rapid deployments and having the confidence to change, makes your IT infrastructure more valuable to your business leaders.
About the author

Mike McGrath is vice president, Core Platforms, at Red Hat where he leads the development of Red Hat Enterprise Linux and related platforms.
More like this
Data-driven automation with Red Hat Ansible Automation Platform
Ford's keyless strategy for managing 200+ Red Hat OpenShift clusters
Technically Speaking | Platform engineering for AI agents
Technically Speaking | Driving healthcare discoveries with AI
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds