OpenShift 4 brings unmatched automation to cluster installation, cluster scaling, maintenance, and security updates. In short, the experience is like a Kubernetes cluster delivered as a service, with one-click upgrades driven by a high degree of automation. This automation lets OpenShift customers run 10-plus to a 100-plus clusters without scaling their operations team linearly.
This guide aims to help cluster administrators plan out their upgrades to their OpenShift fleet and communicate best practices to harness OpenShift’s automated operations. If you would prefer to watch or listen, head on over to a recording of this guide on OpenShift.tv.
Red Hat’s goals for providing new versions of OpenShift mirror the experience you might have had with iOS, Android, or the Chrome browser. Each of these products have mechanisms to roll out new versions over time to ensure product quality and device health. For a consumer, they also have ways for you to opt in to beta releases and toggle feature flags to further control your experience testing new features.
Each OpenShift release has the following goals:
- No downtime for applications during an upgrade. Applications should be using all Kubernetes best practices for maintaining high availability.
- Ability to always roll forward if any bugs are encountered. Kubernetes API migrations are not always reversible and vary from component to component. OpenShift components are forward and backward compatible within a range of versions.
- Pause on any blocking errors without impacting the cluster, if possible. All components monitor their health, and most errors do not impact functionality. This allows an admin to do remediation or reconfigure into an acceptable configuration.
- Fully manage everything, from the OS up to the cluster control plane and cluster add-ons.
- All installations behave the same for all Day 2 operations. Clusters that are correctly user-provisioned or installer-provisioned can be upgraded in the exact same manner.
As we walk through the upgrade and release process, these goals will pop up in every facet of OpenShift. If you stopped reading now after understanding these goals, you will be successful with OpenShift as long as your apps use Kubernetes best practices for highly available apps. Many of our customers are sophisticated, and their entire business runs on OpenShift, so a deeper understanding is helpful.
Each OpenShift Release is a Collection of Operators
First, let’s understand what we mean when we talk about an OpenShift “release.” OpenShift contains a toolkit out of the box to automate the provisioning, management, and scaling of enterprise applications. This spans developers writing code, software builds and CI/CD, logging and monitoring, debugging and tracing, and more. And that does not include cluster services that make all of that possible: a container registry, storage, networking, ingress and routing, security, and much more.
Each of these capabilities is made up of multiple components that need to coordinate their configuration as well as scale independently but also upgrade together. The logic used to manage and upgrade the monitoring stack is different from logic for the container registry or Kubernetes control plane.
OpenShift uses Operators to encapsulate this specialized operational knowledge. Each Operator knows exactly what it needs to do during an upgrade, how to merge a cluster admin’s desired configuration together with best practices, and how to enable new product features safely.
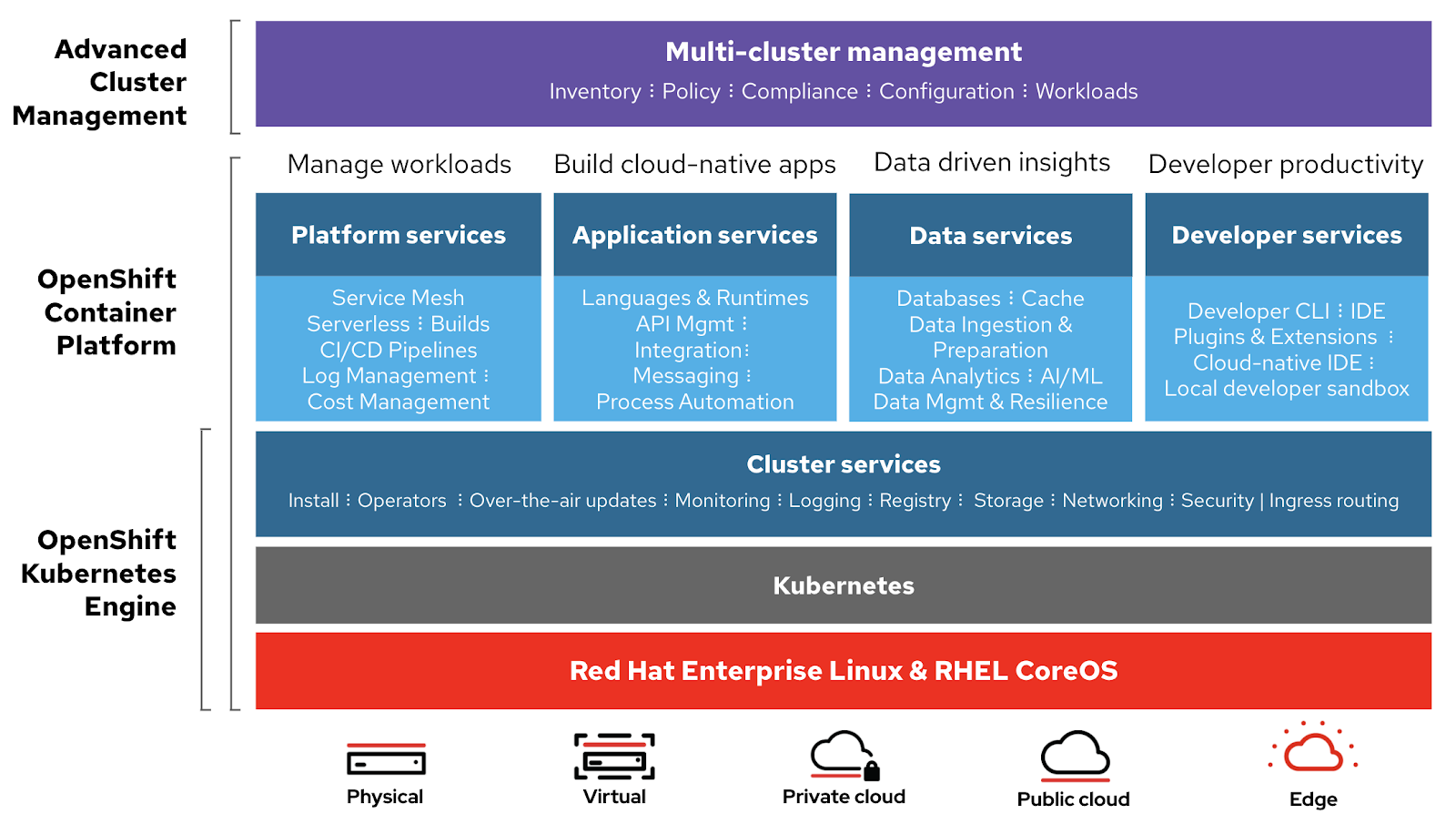
OpenShift architecture showing cluster, platform, and other app services.
OpenShift cluster admins can also configure each of these components, and the Operator merges the built-in defaults with admin desires. This works off the same desired state loop used throughout Kubernetes. This methodology is super powerful, because the cluster is always changing as workloads are started, stopped, and scaled. All of that can continue during an upgrade, because an upgrade is just another instance of a configuration change.
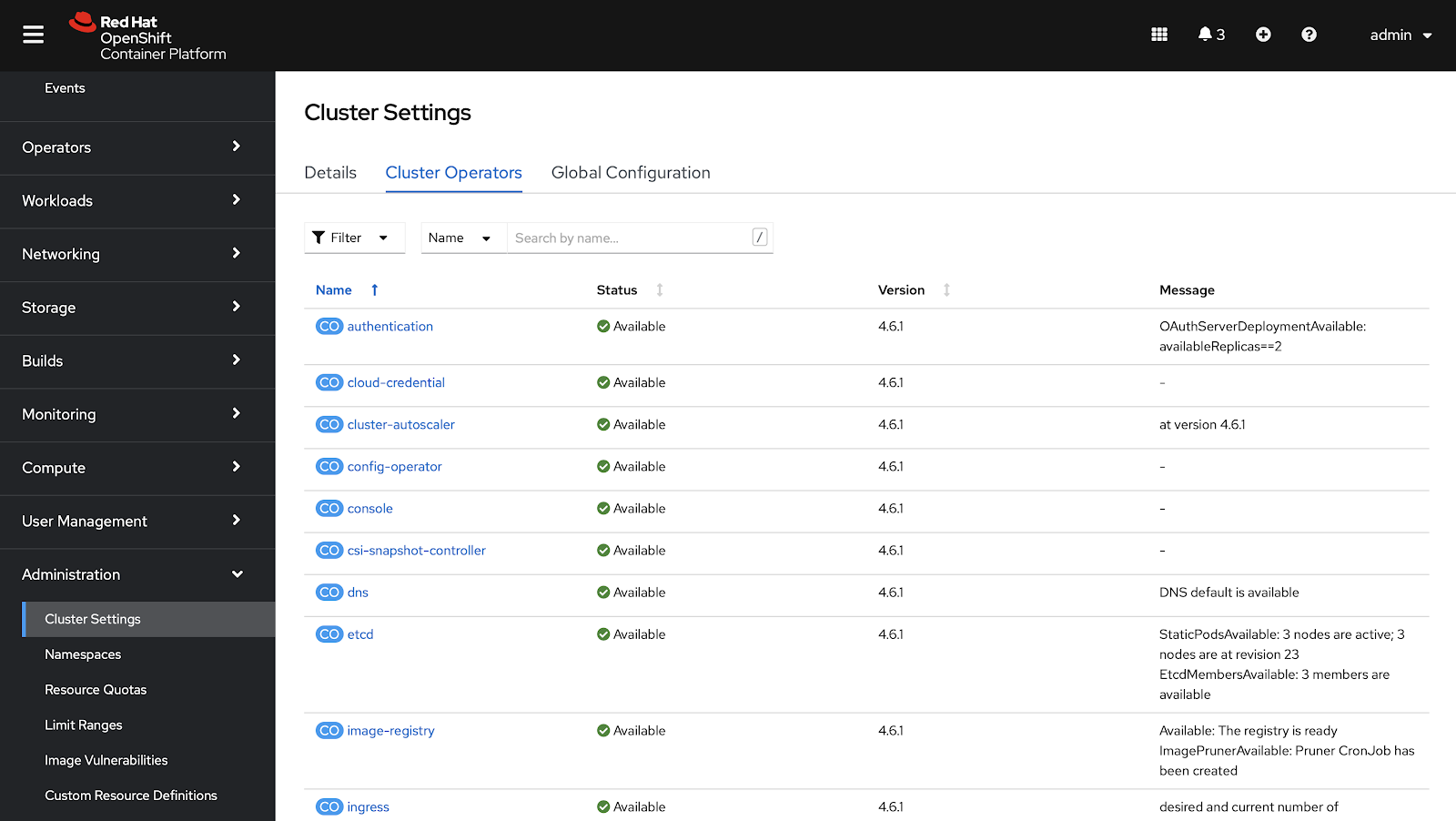
Cluster Operators list and their statuses inside of the OpenShift Console
Within the OpenShift Console’s cluster settings screen, you can see the full list of Operators that make up each OpenShift release. Each of these Operators are tested and released together to make up a specific OpenShift release. More on that below.
OpenShift Is Released Weekly Across Multiple Versions
The increased automation inside of OpenShift 4 is important because our software never sleeps. It needs to remediate failures within milliseconds. It needs to be patched as soon as new security issues are discovered.
Z-stream Releases
Ongoing security patches and bug fixes are released weekly for each supported version of OpenShift. We call this stream of updates the “z-stream” in reference to the x.y.z semantic versioning scheme.
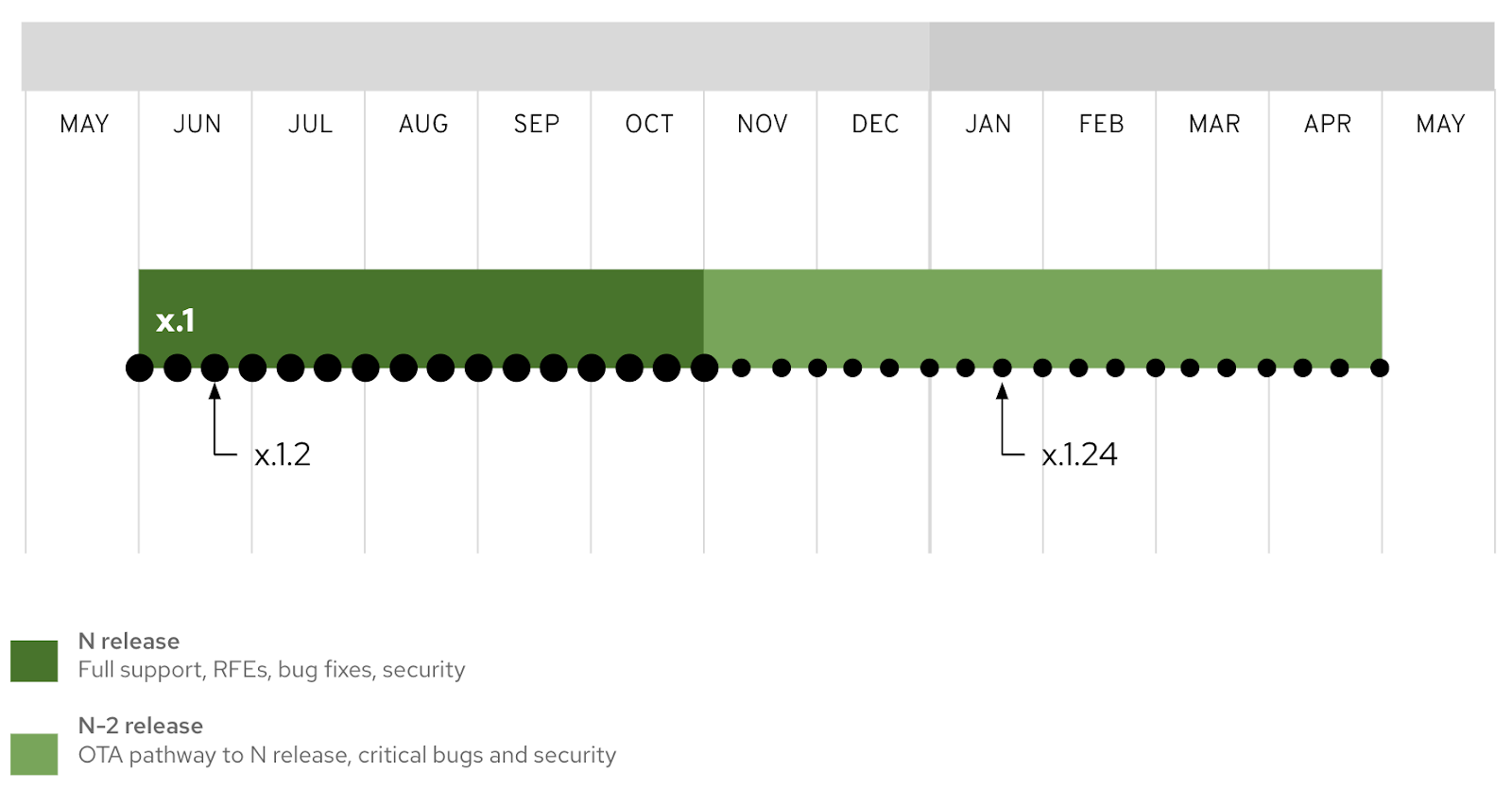
Diagram showing the typical life cycle of an OpenShift z-stream
Each z-stream upgrade is designed to be extremely safe to apply and should not change cluster behavior or break any API contracts. Our goal is to make this process so transparent that turning on automatic updates is welcomed by all of our customers.
Y-stream Releases
When you see a blog post or tweet about new OpenShift features, you are typically reading about the latest y-stream, which is a major release and a step up from a z-stream. These releases are when you get new Kubernetes versions, new capabilities in the operating system, improved automation on IaaS providers, and other expanded features.
Y-streams overlap by design, and there are two phases to each stream’s life cycle. When that y-stream is the latest release offered by Red Hat, it is the codebase where active development and bug fixes land first, in the next scheduled z-stream. In the waterfall chart below, this is the dark green bar.
Once the next y-stream of OpenShift is out, the previous two releases are in the maintenance support phase, where critical bugs and security issues are fixed. This is the lighter green bar. Bug patches for issues that exist in multiple versions will typically be fixed in all three actively supported y-streams.

Diagram showing the overlapping life cycles of OpenShift y-streams
What to Expect When Upgrading OpenShift
When you combine the goals outlined for no downtime for your apps, and all of the automation baked into the Operators, the upgrade experience boils down to a single button. Cluster admins have the ability to choose when to upgrade, and if there are multiple versions available, which one they would like to upgrade to.
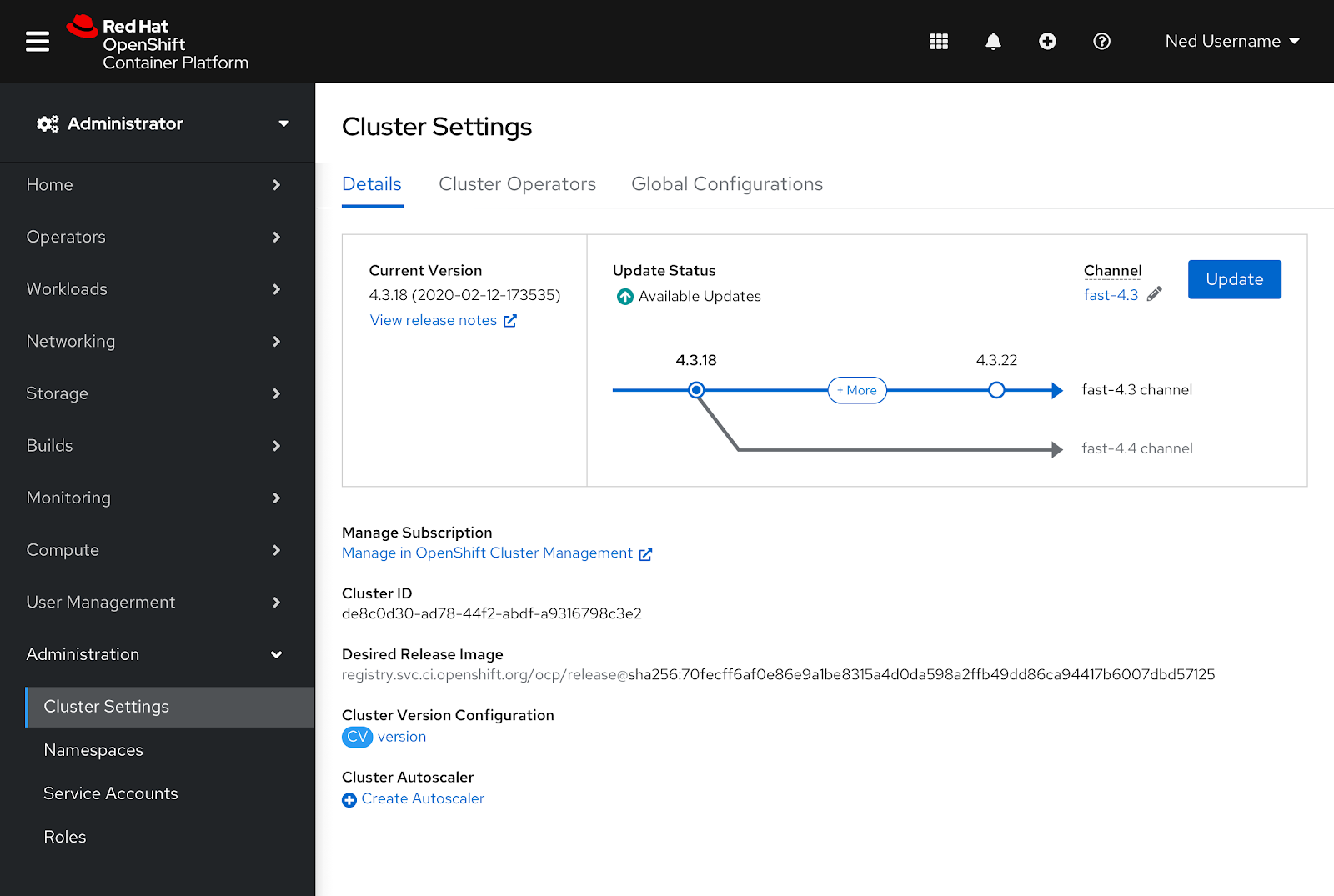
Upgrading an OpenShift cluster via the Console
The cluster understands the best version for you to upgrade to and presents that in the Console. You can also drive this via API across multiple clusters or integrate it into automation tools you already use. Red Hat understands that there is an element of trust that must be earned over time. Overall, we have seen a very high participation rate, and customers are successful upgrading with ease and stability.
Earlier we covered how the Operators that manage monitoring, logging, registry, and others each work on a desired state loop, which allows the cluster admin to configure and manage these features. Upgrading the entire cluster itself also works on a desired state loop. When you change the desired version in the Console, you are just manipulating a single field on a Kubernetes object. It looks like this:
$ oc get clusterversion
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS
version 4.6.1 True False 2d21h Cluster version is 4.6.1
$ oc get clusterversion version -o yaml
apiVersion: config.openshift.io/v1
kind: ClusterVersion
metadata:
name: version
spec:
channel: fast-4.6
clusterID: abc-123-abc-123
desiredUpdate:
force: false
image: quay.io/openshift-release-dev/ocp-release@sha256:d78292...c2b9
version: 4.6.1
upstream: https://api.openshift.com/api/upgrades_info/v1/graph
Upgrading the Control Plane
While that is easy by design, I do not want to minimize what is happening under the hood. First, OpenShift’s Cluster Version Operator (CVO) is protecting you by only offering to upgrade between versions of OpenShift that are validated and known to be high quality at the time of upgrade. When you choose to start the upgrade, new versions of all of the cluster Operators are downloaded, and their signatures checked.
Second, CVO orchestrates desired state changes to each of the Operators in a specific order, with constant health checking along the way. The control plane and etcd are upgraded first, then the OS and config of the Nodes that run the control plane, and finally, the rest of the cluster Operators. Upgrading a 3 Node Control Plane usually takes about an hour, and containers are downloaded, components are reconfigured, and Nodes are rebooted. You can watch all of this happen live in the Console. Upgrade times for the Control Plane are directly proportional to the number of Nodes.
During this time, you should still have availability of the Kubernetes API, the etcd database, and cluster ingress and routing. All of these components are highly available. Once the Control Plane is upgraded, you will see the process be marked as complete.
Upgrading Worker Nodes Across Node Pools
Worker Nodes are upgraded after the Control Plane has finished upgrading. These do not block the cluster’s upgrade process, because Nodes may come and go as autoscaling takes place, and factors outside of the cluster’s control can slow down or even block roll out of your worker nodes.
This is a good thing, of course: PodDisruptionBudgets, affinity and anti-affinity rules, resource limits, Readiness and Liveness probes, and other Kubernetes best practices keep your applications highly available and resilient to the upgrade process.
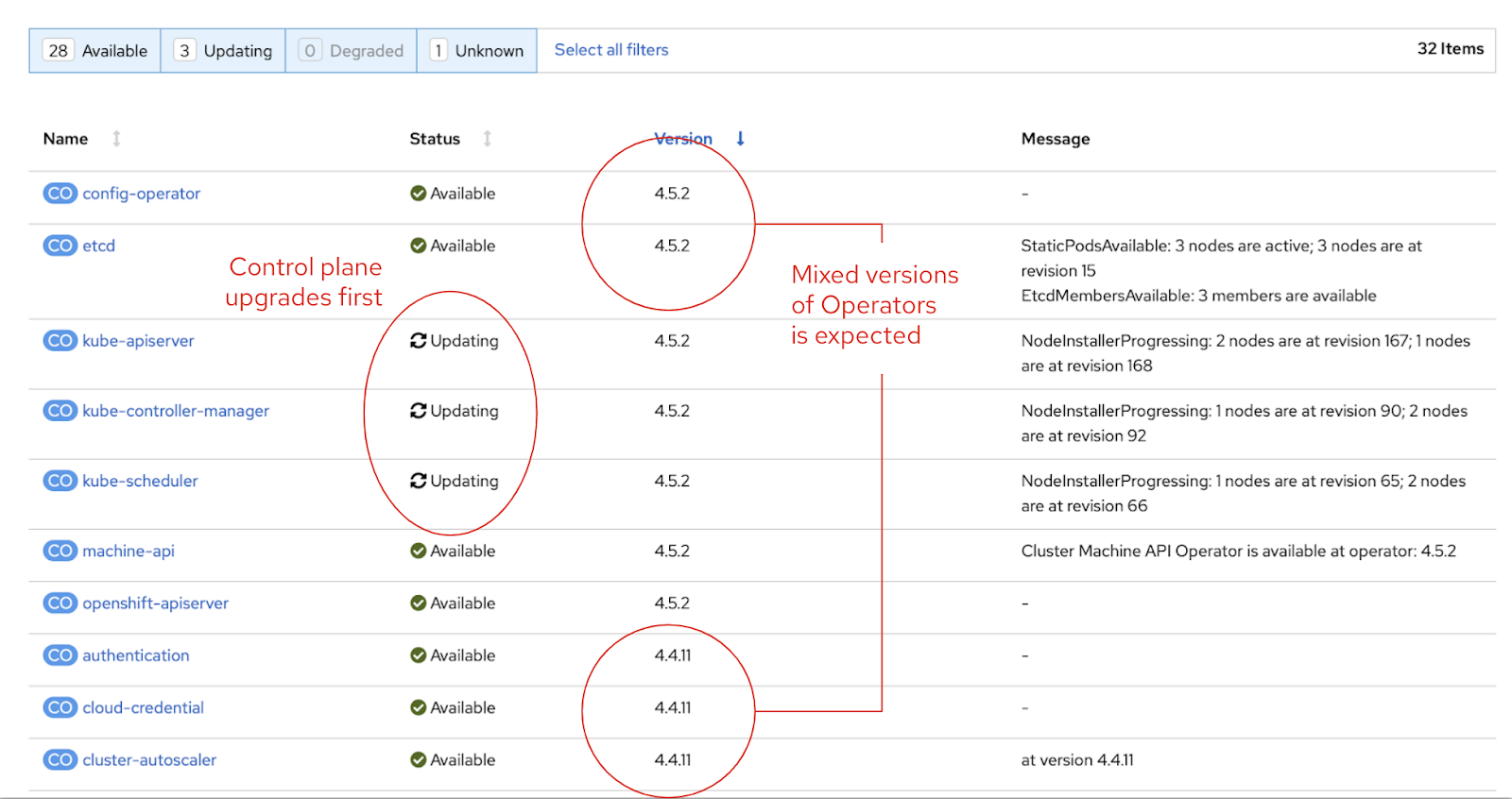
During the upgrade, cluster Operators upgrade in order and will appear as mixed versions.
Each of your configured Node Pools have a maximum number of machines that are allowed to be unavailable at the same time. The Machine Configuration Operator (MCO) will use this value to upgrade and reboot all of the Worker Nodes as quickly as possible, using signals from the workloads. During this time, Pods will be scheduled onto other Nodes as needed. Node Pools are helpful to configure certain hardware (for example, GPUs) correctly, but also to slow down (or speed up) upgrades for certain classes of your applications.
The key design goal of this process is that Node upgrades happen in place, instead of requiring a slower destroy and re-create process. This enables speedy downtime periods, typically just the time it takes for the machine to POST, versus having to do a slow network/PXE boot or wait for a cloud API to boot a new VM. This design also allows for upgrades to work in the same manner no matter what IaaS provider or platform your cluster is deployed on. Keeping upgrades consistent makes debugging easier and removes complexity.
Connected Clusters Get Smarter Over Time
Red Hat gains insight into the fleet of OpenShift clusters as they run and update, in order to protect our customers from bugs and regressions, in addition to monitoring the quality and performance of software upgrades. We consider any OpenShift cluster that connects to this Red Hat system “connected.” Read more about OpenShift’s remote health monitoring and view the Red Hat Insights info generated about your clusters.
Connected OpenShift clusters get smarter over time, for several reasons:
- Upgrade more smoothly: Connected clusters can fetch the latest upgrade graph to get them on the best path at time of update. From time to time, specific upgrade paths are blocked while investigation takes place or bugs are fixed, and connected clusters are routed around these issues. Blocked pathways have reduced about 50%, from 21 in 4.2 to single digits in 4.4 and 4.5, thanks to data from connected clusters. We will talk more about the disconnected or restricted network experience later on in this guide.
- Aid release quality: Red Hat can spot issues across the fleet (similar to iOS or Chrome), and connecting your clusters means your combination of cluster configuration + version + storage plugin + network plugin can influence this process, ultimately giving you better stability and security. Over the 4.3, 4.4, and 4.5 timeframe, bugs fixed before promotion to the stable channel have reduced by 75%.
- Faster ticket triage: Customer support cases can be sped up by having connected cluster information to fill in data that might not have been included in the case.
- Direct proactive support: If an issue is spotted with very specific combinations of configuration and version, Red Hat support can proactively reach out and prevent disaster before it impacts your business. In addition to specific issues, Red Hat watches for issues like subpar disk write performance for etcd, SDN issues, degraded monitoring and logging stacks, usage of deprecated APIs, certificate rotation failures, node clock drift, and much more.
- Subscription management: Clusters that are dynamically changing size can have automatic subscription happen through the OpenShift Cluster Manager. This makes it easy to use the right number of subscriptions without fuss.
- Fresh catalog of content: Operators, Helm charts and other certified content are regularly refreshed with new bug fixes and security patches. Connected clusters can consume this as soon as it is released.
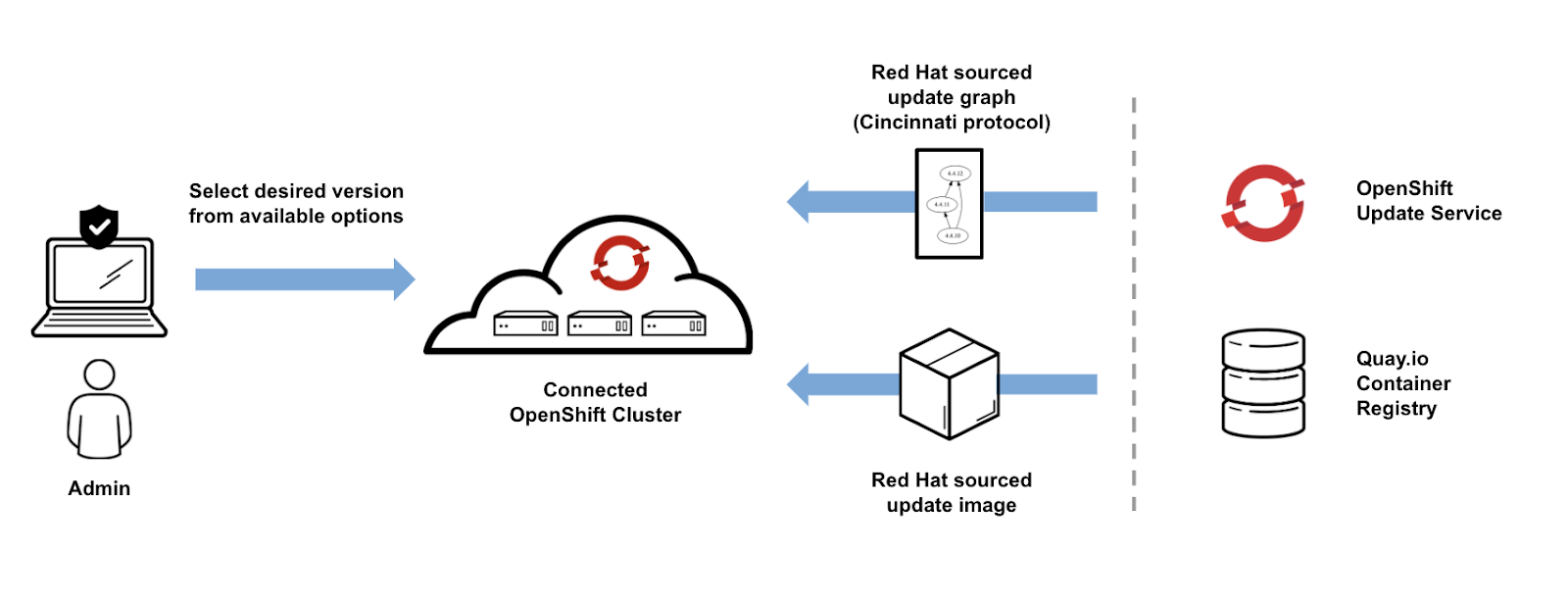
Connected clusters are given the latest set of happy paths from Red Hat
OpenShift Provides More Control Through Channels
When you install or upgrade to a y-stream of OpenShift, you have the choice of “channels” to attach that cluster to. There are three channels that you can choose from: candidate, fast, and stable.
|
Channel Name |
GA |
Description |
|
candidate-4.y |
No |
|
|
fast-4.y |
Yes |
|
|
stable-4.y |
Yes |
|
The OpenShift documentation contains more information on upgrading OpenShift and how to choose a channel.
The main takeaway from this chart is that both fast and stable channels contain the generally available and fully supported product. The difference between the two is the speed at which each version is rolled out. Data gathered from all the channels (for example, candidate, fast and stable channels) augments Red Hat automated testing and informs when releases are promoted.
This “fast before stable” behavior is why you will see no upgrade paths available on the stable channel in the period of time a new y-stream of OpenShift is released. During this time, our engineering teams are gathering data and assessing other factors, including customer tickets and experiences of Red Hat consultants embedded with customers.
Below you can see how automated testing is built into every part of the OpenShift release process, and the feedback mechanisms change as we go from pre-release to post-release.
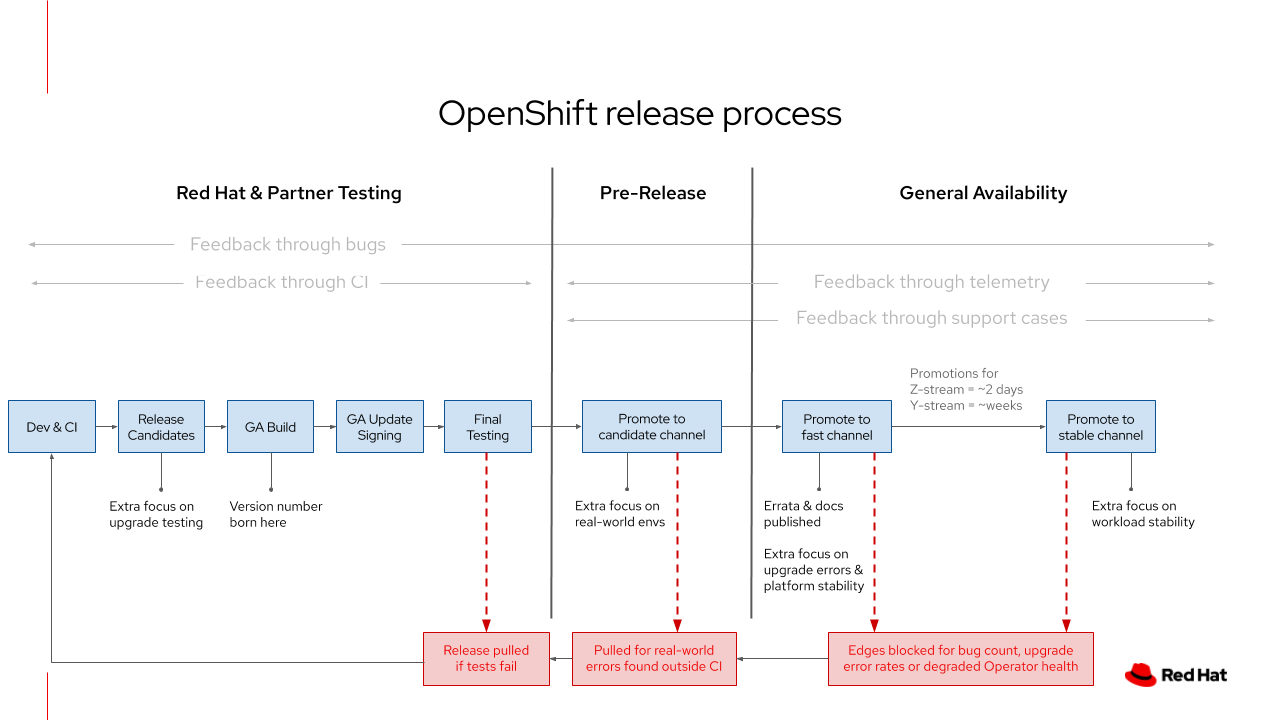
OpenShift release process and feedback cycles built within it.
Bug Fixing and Proactive Support Happens Throughout
The red boxes above highlight the three main points when an issue might be identified and what is done about it. The main question OpenShift engineers are asking themselves through this process is if this needs to block the release or if it is benign enough to fix in a follow-up z-stream. Let’s dig into each of them in more detail.
Release pulled during final testing: Before a given release even makes its way into a channel, final testing may find bugs that are critical enough to fix before it ever hits a customer cluster. At this late stage in the development cycle, this class of blockers is normally related to the internal release tooling itself, related to container signing, or other similar areas. During this time, you may see a version number born that is never released, such as 4.6.0, since OpenShift does not reuse version numbers once it leaves the build system.
Edges blocked from candidate channel: The candidate channel is focused on spotting bugs related to real world environments. It is just a fact of life that the OpenShift automation suite will not cover every possible IaaS and datacenter environment. If a systemic issue is found that impacts a large slice of the fleet, clusters can be blocked from installing this version.
Blocked from fast or stable channel: Post-release, there may be certain bugs or observed conditions that will warrant blocking one or both of these channels from upgrading to a certain version. This may be because a bug has been confirmed or occurs while an investigation is conducted.
When a release is promoted to the fast channel, there is an extra focus on upgrade related issues and general platform stability. This is the first time that a wide swath of the fleet will be upgrading to this version, especially when it is the first release of a y-stream. Bugs found here will immediately be fixed and land in a z-stream. Using the update graph, clusters will be routed around that issue.
During stable promotion, the focus switches to workload stability, as this version is run with the widest variety of applications on top of it. Almost all widespread issues will have been triaged at this point. Connected clusters are particularly helpful here, because bugs that may only impact you or a small subset of clusters can show up on our engineering team’s radar and be fixed quickly.
Switch Channels to Upgrade to a New Y-stream
The trigger to switch to a new y-stream of OpenShift is to switch your channel. Later versions of your current y-stream will automatically enable these new channels in your cluster.
Naturally, you have a choice to stay on the same channel, or you can switch to a different one when you upgrade. Once you make your choice, the cluster will check to see if there is an upgrade path from your current version to one on the new channel, and the upgrade button will appear.
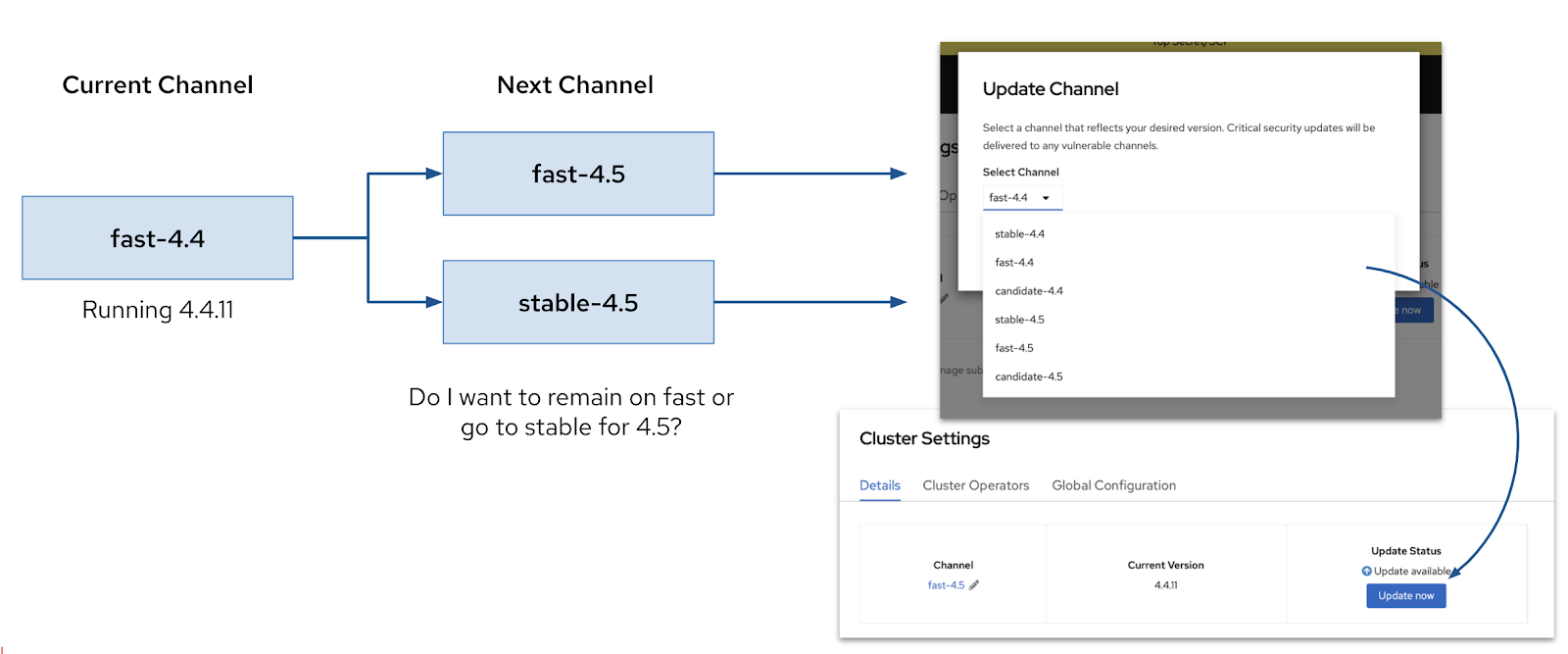
Upgrading by switching your channel in the OpenShift Console.
There have been numerous mentions of safe upgrade paths and the ability to block clusters from upgrading to specific releases. Next we will dig into how that works.
An Update Graph Provides Safe, Reliable Upgrades
How is all of this automation done safely? How does the fleet of OpenShift clusters make reliable and intelligent choices about upgrades? It is all powered by a graph database that produces “paths” through different versions. And, of course, it sometimes routes you to a specific path instead of another.
Below is a simple view of what this graph looks like. Keep in mind it is constantly changing as bugs are found, fixed, and routed around.
The versions at the top of paths show where you can start from, and the bottom versions are where you can go to.
Upgrading by switching your channel in the OpenShift Console.
Everything is more complex than it looks on the surface ... the real graph looks like this when rendered. As you can see, many versions point to many others as our automated testing, bug, and support data indicates it is safe. No need to worry;, your cluster parses all of this for you automatically.

Snapshot of the OpenShift 4.3 to 4.4 upgrade graph
Blocked Edges Proactively Keep Your Clusters Safe
The other key component of the update graph is when and how Red Hat chooses to modify it, which is called “blocking an edge.” An edge refers to the pathway between versions.
When triaging an issue, the first goal is to route around the affected version. This prevents others from hitting an issue. The second goal is to provide remediation to clusters that are already running that version.
Running on a version that has been blocked after you upgrade is not usually dangerous. Most times, you will not know that it ever happened or see any adverse effects, because the blocked edge might simply be to investigate further. Not every [cluster × platform × workload × config] hits every issue either.
Typically, bugs are fixed, and a new path is published for you to follow. Cluster admins can also force an upgrade to go through even if the cluster advises against it. Work with your support team or technical account manager to understand the impacts this may have on your cluster and its experience during the upgrade.

Example of a bug found in 4.4.11 and fixed in 4.4.12.
Threshold for Blocking Edges
The threshold for blocking a single edge can be low, and sometimes a large range of edges is blocked. The OpenShift engineering team determines this by asking ourselves a series of questions:
- Who is impacted? If we have to block upgrade edges based on this issue, which edges would need blocking?
- example: Customers upgrading from 4.y.Z to 4.y+1.z running on GCP with thousands of namespaces, approximately 5% of the subscribed fleet
- example: All customers upgrading from 4.y.z to 4.y+1.z fail approximately 10% of the time
- What is the impact? Is it serious enough to warrant blocking edges?
- example: Up to 2 minute disruption in edge routing
- example: Up to 90 seconds of API downtime
- example: etcd loses quorum and you have to restore from backup
- How involved is remediation (even moderately serious impacts might be acceptable if they are easy to mitigate)?
- example: Issue resolves itself after 5 minutes.
- example: Admin uses oc to fix things.
- example: Admin must SSH to hosts, restore from backups, or other nonstandard admin activities.
- Is this a regression (if all previous versions were also vulnerable, updating to the new, vulnerable version does not increase exposure)?
- example: No, it has always been like this; we just never noticed.
- example: Yes, from 4.y.z to 4.y+1.z Or 4.y.z to 4.y.z+1
Disconnected Clusters Have a Similar Experience But Require More Curation by Administrators
Finally, we get to the topic of disconnected clusters. This guide covered all of the parts of the connected cluster experience in order to contrast it with the disconnected/restricted network cluster.
OpenShift’s Operator model, with its desired state loop automation, means that once all of the containers and metadata are loaded into the container registry behind your firewall, you will get the same failure recovery and upgrade experience as a connected cluster.
Because all of the containers need to be moved behind your firewall, a cluster admin is taking on the responsibility of deciding what versions to upgrade from and to. This process consists of parsing the current update graph at the time you start mirroring, and understanding which outstanding bugs may impact you and which will not. If you have lengthy multiday approvals, container scanning, and other security controls, a better upgrade path may exist for you.
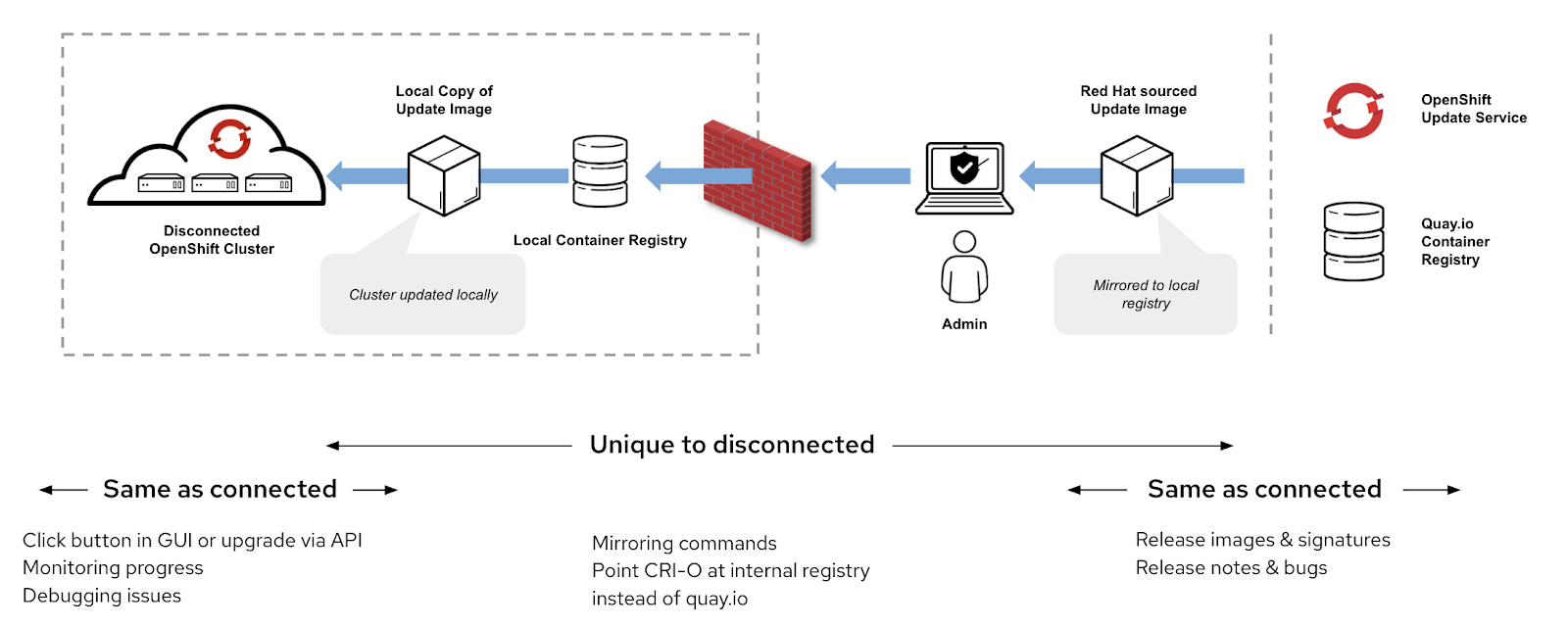
Comparing the disconnected upgrade process to a connected cluster.
The last factor you may want to understand is the longer-term roadmap for the compute, networking, and storage configuration you use with OpenShift, as it might be more efficient to delay upgrading if a later release will align with a bug fix you have been waiting for or it contains a new feature that is important to running your applications.
In the near future, customers will be able to run the OpenShift Update Service completely behind their firewall, with a customized graph. This will reduce the toil related to upgrading tens or hundreds of clusters that are disconnected.
Understanding Pinch Points and Skipping Releases
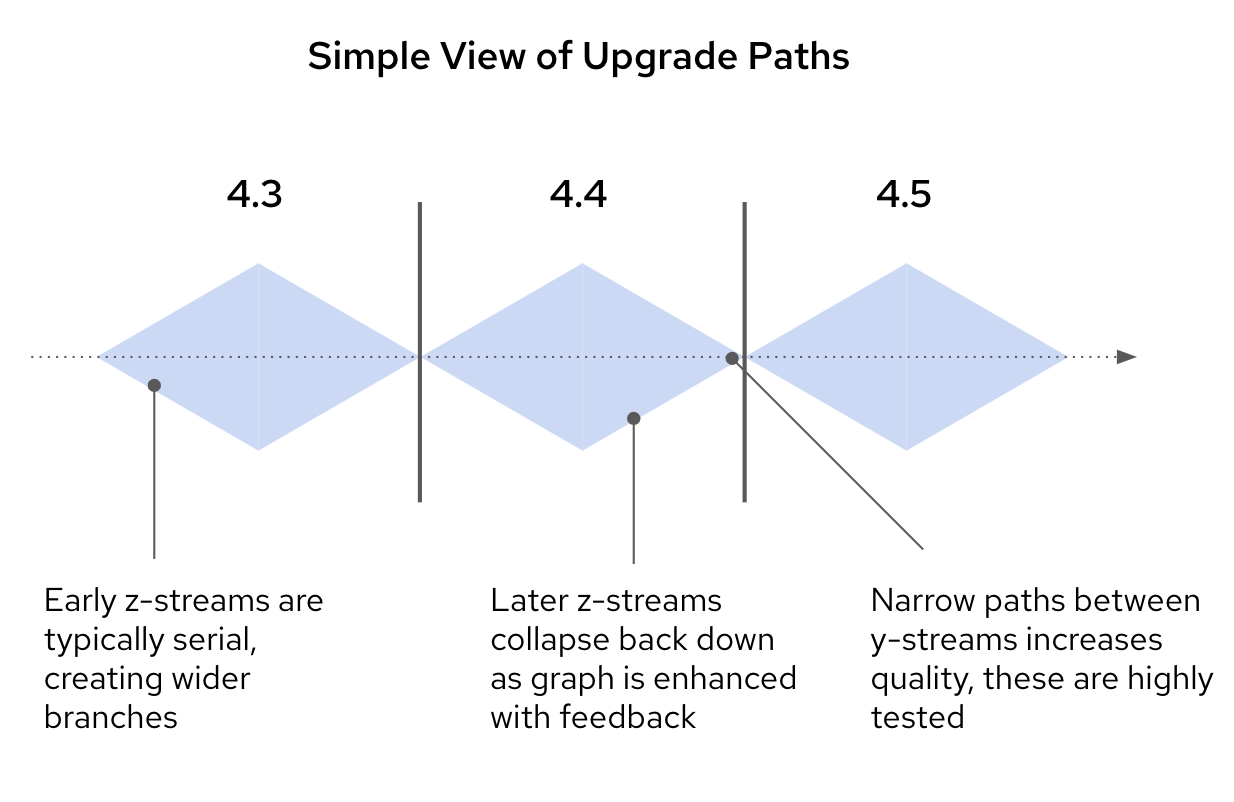
Now that we have explored all of the facets of OpenShift upgrades, let’s explore how some of these concepts come together into practice. As you monitor and upgrade your OpenShift clusters, you will come to see that natural “pinch points” form between y-streams through the normal functioning of the weekly z-streams, bug fixes, and the upgrade graph.
Early in the life cycle, the first few z-streams will naturally expand, creating more branches and a natural spread of deployed clusters as folks upgrade over a period of several weeks. You can visualize this as the side of a diamond, getting wider.
Towards the middle of the life cycle, which will be around the time a new y-stream is introduced, those pathways will collapse back down as bugs are fixed and the graph is enhanced with the feedback from connected clusters. This forms the middle of the diamond.
Upgrades between y-streams start out very narrow, sometimes only between two specific versions, in order to ensure a highly tested and safe pathway. As feedback is processed from these upgrades, and as the upgrade progresses from the fast to the stable channel, more paths will be opened up.
Comparing the disconnected upgrade process to a connected cluster.
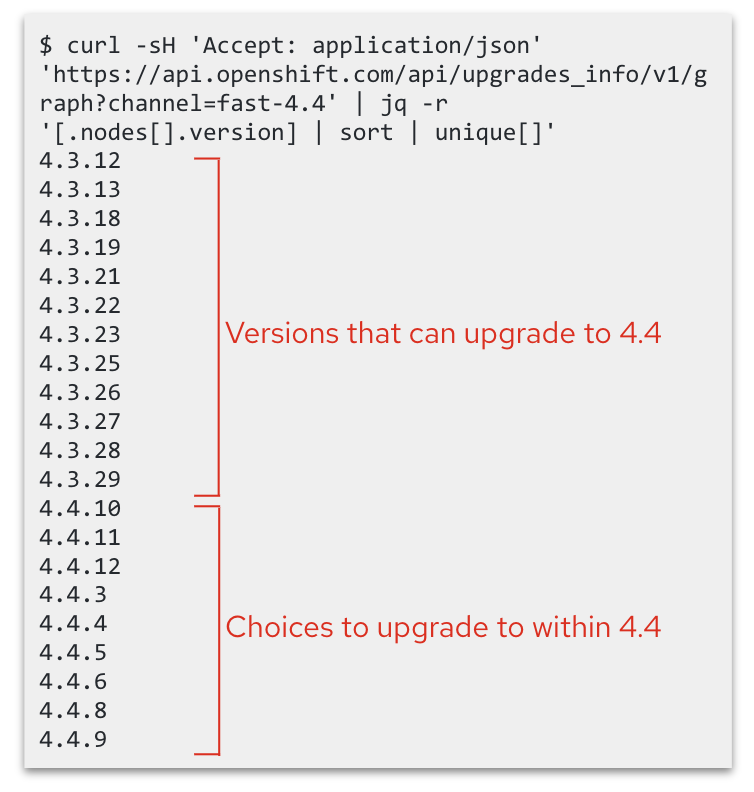
As discussed earlier, this is the simple version, with the cluster’s upgrade logic parsing a very complex graph. Below you can see how the 28th z-stream of OpenShift 4.3 accepts upgrades from most of the proceeding releases and is an ideal candidate for the initial pathway to the next y-stream, OpenShift 4.4.

Example update graph funneling through a specific OpenShift version.
Skipping Releases
Most folks reading through this guidance have one last question: “Can I skip over a y-stream completely?”
Right now, the answer is no. Yes, the upgrade graph clearly can orchestrate this behavior, and we hope to enable it in the future. As it stands today, there are too many systemic changes coming in upstream Kubernetes in order to expect this to be a realistic option.
Notable changes include many APIs migrating from beta to stable to meet the updated API graduation guidelines, the migration of the storage drives from in-tree to out-of-tree, and many smaller and more nuanced changes that Red Hat tracks as part of our upstream special interest group participation. OpenShift will orchestrate these migrations on your behalf, but these are extremely invasive changes to happen while running those migrations and keeping the cluster plus your apps fully functional. It is just too much to add skipping a major Kubernetes release into the mix.
Experience OpenShift’s Automated Operations for Yourself
Spread the word, and send a coworker a recording of this guide on OpenShift.tv. The best knowledge is gained by trying out an OpenShift upgrade yourself. Head over to https://openshift.com/try to run your own on any IaaS or datacenter gear. For best results, download an earlier version and immediately upgrade it!
About the author

Product manager & experience designer with a passion for taming technical systems. Rob Szumski has expertise in producing and shipping open source software as part of a holistic product experience.
More like this
Stop managing the past and start building IT’s future
The agentic paradox and the case for hybrid AI
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds